Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Invoervalidatie is een techniek voor het beveiligen van de hoofdquerylogica tegen onjuiste of onverwachte gebeurtenissen. De query wordt bijgewerkt om records expliciet te verwerken en te controleren, zodat ze de hoofdlogica niet kunnen verbreken.
Voor het implementeren van invoervalidatie voegen we twee initiële stappen toe aan een query. We zorgen er eerst voor dat het schema dat is verzonden naar de kernbedrijfslogica, overeenkomt met de verwachtingen. We classificeren vervolgens uitzonderingen en routeren desgewenst ongeldige records naar een secundaire uitvoer.
Een query met invoervalidatie wordt als volgt gestructureerd:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Als u een uitgebreid voorbeeld wilt zien van een query die is ingesteld met invoervalidatie, raadpleegt u de sectie: Voorbeeld van een query met invoervalidatie.
In dit artikel wordt uitgelegd hoe u deze techniek implementeert.
Context
Asa-taken (Azure Stream Analytics) verwerken gegevens die afkomstig zijn van streams. Streams zijn reeksen onbewerkte gegevens die worden verzonden (CSV, JSON, AVRO...). Als u wilt lezen vanuit een stream, moet een toepassing de specifieke serialisatie-indeling kennen die wordt gebruikt. In ASA moet de indeling voor gebeurtenisserialisatie worden gedefinieerd bij het configureren van een streaming-invoer.
Zodra de gegevens gedeserialiseerd zijn, moet een schema worden toegepast om deze betekenis te geven. Volgens schema bedoelen we de lijst met velden in de stroom en hun respectieve gegevenstypen. Met ASA hoeft het schema van de binnenkomende gegevens niet op invoerniveau te worden ingesteld. ASA ondersteunt in plaats daarvan systeemeigen dynamische invoerschema's . Er wordt verwacht dat de lijst met velden (kolommen) en de bijbehorende typen tussen gebeurtenissen (rijen) verandert. ASA leidt ook gegevenstypen af wanneer er geen expliciet wordt verstrekt en probeert impliciet typen te casten wanneer dat nodig is.
Dynamische schemaverwerking is een krachtige functie, sleutel voor het verwerken van stromen. Gegevensstromen bevatten vaak gegevens uit meerdere bronnen, met meerdere gebeurtenistypen, elk met een uniek schema. Om gebeurtenissen op dergelijke streams te routeren, filteren en verwerken, moet ASA ze allemaal opnemen, ongeacht hun schema.
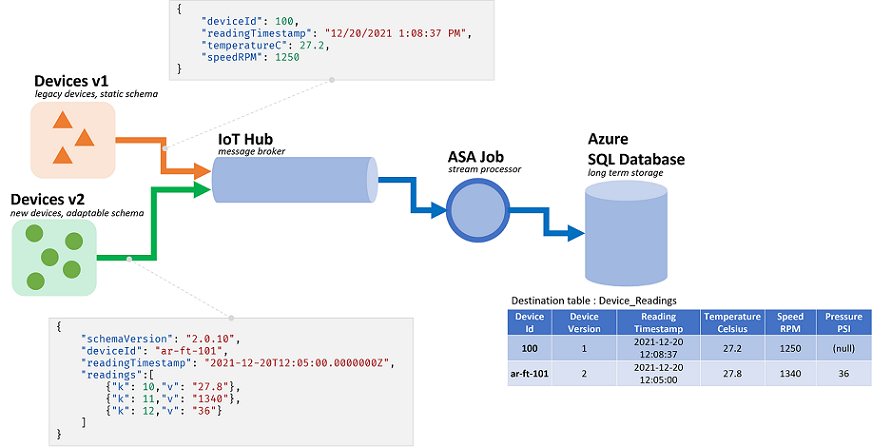
Maar de mogelijkheden die worden geboden door dynamische schemaafhandeling, hebben een potentieel nadeel. Onverwachte gebeurtenissen kunnen door de hoofdquerylogica stromen en verbreken. Als voorbeeld kunnen we AFRONDEN gebruiken voor een veld van het typeNVARCHAR(MAX). ASA zal het impliciet casten om te zweven zodat deze overeenkomt met de handtekening van ROUND. Hier verwachten we of hoop dat dit veld altijd numerieke waarden bevat. Maar wanneer we wel een gebeurtenis ontvangen waarin het veld is ingesteld "NaN"op, of als het veld volledig ontbreekt, kan de taak mislukken.
Met invoervalidatie voegen we voorlopige stappen toe aan onze query om dergelijke ongeldige gebeurtenissen te verwerken. We gebruiken voornamelijk WITH en TRY_CAST om het te implementeren.
Scenario: invoervalidatie voor onbetrouwbare gebeurtenisproducenten
We bouwen een nieuwe ASA-taak die gegevens uit één Event Hub opneemt. Zoals meestal het geval is, zijn we niet verantwoordelijk voor de gegevensproducenten. Hier zijn de producenten IoT-apparaten die door meerdere hardwareleveranciers worden verkocht.
Samen met de belanghebbenden gaan we akkoord met een serialisatie-indeling en een schema. Alle apparaten pushen dergelijke berichten naar een algemene Event Hub, invoer van de ASA-taak.
Het schemacontract wordt als volgt gedefinieerd:
| Veldnaam | Veldtype | Veldbeschrijving |
|---|---|---|
deviceId |
Geheel getal | Unieke apparaat-id |
readingTimestamp |
Datum/tijd | Berichttijd, gegenereerd door een centrale gateway |
readingStr |
String | |
readingNum |
Numeriek | |
readingArray |
Matrix van tekenreeks |
Dit geeft ons op zijn beurt het volgende voorbeeldbericht onder JSON-serialisatie:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Er is al sprake van een discrepantie tussen het schemacontract en de implementatie ervan. In de JSON-indeling is er geen gegevenstype voor datum/tijd. Het wordt verzonden als een tekenreeks (zie readingTimestamp hierboven). ASA kan het probleem eenvoudig oplossen, maar toont de noodzaak om typen te valideren en expliciet te casten. Hoe meer voor gegevens die in CSV worden geserialiseerd, omdat alle waarden vervolgens worden verzonden als tekenreeks.
Er is nog een discrepantie. ASA maakt gebruik van een eigen typesysteem dat niet overeenkomt met het binnenkomende systeem. Als ASA ingebouwde typen heeft voor gehele getallen (bigint), datum/tijd, tekenreeks (nvarchar(max)) en matrices, ondersteunt deze alleen numerieke waarden via float. Dit komt niet overeen voor de meeste toepassingen. Maar in bepaalde edge-gevallen kan het kleine afwijkingen in precisie veroorzaken. In dit geval converteren we de numerieke waarde als tekenreeks in een nieuw veld. Vervolgens gebruiken we een systeem dat ondersteuning biedt voor vaste decimalen om potentiële afwijkingen te detecteren en te corrigeren.
Terug naar onze query, hier zijn we van plan:
- Doorgeven
readingStraan een JavaScript UDF - Het aantal records in de matrix tellen
- Afronden
readingNumop de tweede decimaalpositie - De gegevens invoegen in een SQL-tabel
De doel-SQL-tabel heeft het volgende schema:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Het is een goed idee om toe te wijzen wat er met elk veld gebeurt terwijl deze de taak doorloopt:
| Veld | Invoer (JSON) | Overgenomen type (ASA) | Uitvoer (Azure SQL) | Opmerking |
|---|---|---|---|---|
deviceId |
Nummer | bigint | geheel getal | |
readingTimestamp |
tekenreeks | nvarchar(MAX) | datetime2 | |
readingStr |
tekenreeks | nvarchar(MAX) | nvarchar(200) | gebruikt door de UDF |
readingNum |
Nummer | zwevend | decimal(18,2) | af te ronden |
readingArray |
matrix(tekenreeks) | matrix van nvarchar(MAX) | geheel getal | om te worden geteld |
Vereisten
We ontwikkelen de query in Visual Studio Code met behulp van de ASA Tools-extensie . De eerste stappen van deze zelfstudie helpen u bij het installeren van de vereiste onderdelen.
In VS Code gebruiken we lokale uitvoeringen met lokale invoer/uitvoer om geen kosten in rekening te gebracht en versnellen we de foutopsporingslus. We hoeven geen Event Hub of een Azure SQL Database in te stellen.
Basisquery
Laten we beginnen met een eenvoudige implementatie, zonder invoervalidatie. We voegen deze toe in de volgende sectie.
In VS Code maken we een nieuw ASA-project
In de map maken we een nieuw JSON-bestand met de input naam data_readings.json en voegen we de volgende records toe:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Vervolgens definiëren we een lokale invoer, genaamd readings, waarnaar wordt verwezen naar het JSON-bestand dat we hierboven hebben gemaakt.
Zodra deze is geconfigureerd, ziet deze er als volgt uit:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Met voorbeeldgegevens kunnen we zien dat onze records correct zijn geladen.
We maken een nieuwe JavaScript UDF die wordt aangeroepen udfLen door met de rechtermuisknop op de Functions map te klikken en te ASA: Add Functionselecteren. De code die we gaan gebruiken, is:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
In lokale uitvoeringen hoeven we geen uitvoer te definiëren. We hoeven niet eens te gebruiken INTO , tenzij er meer dan één uitvoer is. In het .asaql bestand kunnen we de bestaande query vervangen door:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Laten we snel de query doorlopen die we hebben ingediend:
- Als u het aantal records in elke matrix wilt tellen, moeten we ze eerst uitpakken. We gebruiken CROSS APPLY en GetArrayElements() (meer voorbeelden hier)
- Hierdoor worden twee gegevenssets in de query weergegeven: de oorspronkelijke invoer en de matrixwaarden. Om ervoor te zorgen dat we geen velden combineren, definiëren we aliassen (
AS r) en gebruiken we ze overal - Vervolgens moeten we aggregeren met GROUP BY om de matrixwaarden daadwerkelijk
COUNTte berekenen - Daarvoor moeten we een tijdvenster definiëren. Omdat we er geen nodig hebben voor onze logica, is het momentopnamevenster de juiste keuze
- Hierdoor worden twee gegevenssets in de query weergegeven: de oorspronkelijke invoer en de matrixwaarden. Om ervoor te zorgen dat we geen velden combineren, definiëren we aliassen (
- We moeten ook alle
GROUP BYvelden en projecteren ze allemaal in deSELECT. Het expliciet projecteren van velden is een goede gewoonte, omdatSELECT *fouten van de invoer naar de uitvoer kunnen stromen- Als we een tijdvenster definiëren, kunnen we een tijdstempel definiëren met TIMESTAMP BY. Hier is het niet nodig om onze logica te laten werken. Voor lokale uitvoeringen, zonder dat
TIMESTAMP BYalle records worden geladen op één tijdstempel, wordt de starttijd van de uitvoering uitgevoerd.
- Als we een tijdvenster definiëren, kunnen we een tijdstempel definiëren met TIMESTAMP BY. Hier is het niet nodig om onze logica te laten werken. Voor lokale uitvoeringen, zonder dat
- We gebruiken de UDF om metingen te filteren met
readingStrminder dan twee tekens. We hadden LEN hier moeten gebruiken. We gebruiken alleen een UDF voor demonstratiedoeleinden
We kunnen een uitvoering starten en de gegevens bekijken die worden verwerkt:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Een tekenreeks | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Een andere tekenreeks | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | Een derde tekenreeks | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | A Forth-tekenreeks | 1.21 | 2 |
Nu we weten dat onze query werkt, gaan we deze testen op meer gegevens. Laten we de inhoud data_readings.json vervangen door de volgende records:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Hier ziet u de volgende problemen:
- Apparaat 1 heeft alles goed gedaan
- Apparaat 2 is vergeten een apparaat op te nemen
readingStr - Apparaat 3 verzonden
NaNals een getal - Apparaat 4 heeft een lege record verzonden in plaats van een matrix
Het uitvoeren van de taak zou nu niet goed moeten eindigen. Er wordt een van de volgende foutberichten weergegeven:
Apparaat 2 geeft ons het volgende:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Apparaat 3 geeft ons het volgende:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Apparaat 4 geeft ons het volgende:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Telkens wanneer onjuiste records van de invoer naar de hoofdquerylogica konden stromen zonder te worden gevalideerd. Nu realiseren we de waarde van invoervalidatie.
Invoervalidatie implementeren
We gaan onze query uitbreiden om de invoer te valideren.
De eerste stap van de invoervalidatie is het definiëren van de schema verwachtingen van de kernbedrijfslogica. Als we terugkijken naar de oorspronkelijke vereiste, is onze hoofdlogica het volgende:
- Doorgeven
readingStraan een JavaScript UDF om de lengte ervan te meten - Het aantal records in de matrix tellen
- Afronden
readingNumop de tweede decimaalpositie - De gegevens invoegen in een SQL-tabel
Voor elk punt kunnen we de verwachtingen vermelden:
- De UDF vereist een argument van het type tekenreeks (nvarchar(max) hier) die niet null mag zijn
GetArrayElements()vereist een argument van het type matrix of een null-waardeRoundvereist een argument van het type bigint of float, of een null-waarde- In plaats van te vertrouwen op de impliciete cast-conversie van ASA, moeten we dit zelf doen en typeconflicten in de query afhandelen
Een manier om te gaan is om de hoofdlogica aan te passen om deze uitzonderingen aan te pakken. Maar in dit geval geloven we dat onze belangrijkste logica perfect is. Laten we in plaats daarvan de binnenkomende gegevens valideren.
Laten we eerst WITH gebruiken om een invoervalidatielaag toe te voegen als eerste stap van de query. We gebruiken TRY_CAST om velden te converteren naar het verwachte type en deze in te NULL stellen op als de conversie mislukt:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Met het laatste invoerbestand dat we hebben gebruikt (de invoer met fouten), retourneert deze query de volgende set:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Een tekenreeks | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00.0000000Z | Een tekenreeks | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Een derde tekenreeks | Nan | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Een derde tekenreeks | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | A Forth-tekenreeks | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth-tekenreeks | 1.2126 | NULL |
We kunnen al twee van onze fouten zien die worden opgelost. We veranderden NaN en {} in NULL. We zijn er nu zeker van dat deze records correct worden ingevoegd in de doel-SQL-tabel.
We moeten nu bepalen hoe de records moeten worden aangepakt met ontbrekende of ongeldige waarden. Na enige discussie besluiten we records met een lege/ongeldige readingArray of ontbrekende records te weigeren readingStr.
We voegen dus een tweede laag toe die records tussen de validatie en de hoofdlogica sorteert:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Het is raadzaam om één WHERE component te schrijven voor beide uitvoerbewerkingen en in de tweede te gebruiken NOT (...) . Op die manier kunnen er geen records worden uitgesloten van zowel uitvoer als verloren.
Nu krijgen we twee uitvoer. Foutopsporing1 bevat de records die naar de hoofdlogica worden verzonden:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Een tekenreeks | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Een derde tekenreeks | NULL | ["D","E","F"] |
Foutopsporing2 bevat de records die worden geweigerd:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | A Forth-tekenreeks | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth-tekenreeks | 1.2126 | NULL |
De laatste stap is het toevoegen van onze hoofdlogica. We voegen ook de uitvoer toe die geweigerd verzamelt. Hier kunt u het beste een uitvoeradapter gebruiken die geen sterke typen afdwingt, zoals een opslagaccount.
De volledige query vindt u in de laatste sectie.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Dit geeft ons de volgende set voor SQLOutput, zonder mogelijke fout:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Een tekenreeks | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Een derde tekenreeks | NULL | 3 |
De andere twee records worden verzonden naar een BlobOutput voor menselijke beoordeling en naverwerking. Onze query is nu veilig.
Voorbeeld van query met invoervalidatie
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Invoervalidatie uitbreiden
GetType kan worden gebruikt om expliciet te controleren op een type. Het werkt goed met CASE in de projectie of WHERE op het ingestelde niveau. GetType kan ook worden gebruikt om het binnenkomende schema dynamisch te controleren op een metagegevensopslagplaats. De opslagplaats kan worden geladen via een referentiegegevensset.
Het testen van eenheden is een goede gewoonte om ervoor te zorgen dat onze query tolerant is. We bouwen een reeks tests die bestaan uit invoerbestanden en de verwachte uitvoer. Onze query moet overeenkomen met de uitvoer die wordt gegenereerd om door te geven. In ASA wordt eenheidstests uitgevoerd via de asa-streamanalytics-cicd npm-module. Testcases met verschillende onjuiste gebeurtenissen moeten worden gemaakt en getest in de implementatiepijplijn.
Ten slotte kunnen we enkele lichte integratietests uitvoeren in VS Code. We kunnen records invoegen in de SQL-tabel via een lokale uitvoering naar een live-uitvoer.
Ondersteuning krijgen
Probeer onze microsoft Q&A-vragenpagina voor Azure Stream Analytics voor meer hulp.
Volgende stappen
- CI/CD-pijplijnen en eenheidstests instellen met behulp van het npm-pakket
- Overzicht van lokale Stream Analytics-uitvoeringen in Visual Studio Code met ASA Tools
- Stream Analytics-query's lokaal testen met voorbeeldgegevens testen met behulp van Visual Studio Code
- Stream Analytics-query's lokaal testen op basis van livestreaminvoer met behulp van Visual Studio Code
- Azure Stream Analytics-taken verkennen met Visual Studio Code (preview)