Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt de optie voor compatibiliteitsniveau in Azure Stream Analytics beschreven.
Stream Analytics is een beheerde service, met regelmatige functie-updates en constante prestatieverbeteringen. De meeste runtime-updates van de service worden automatisch beschikbaar gesteld aan eindgebruikers, onafhankelijk van het compatibiliteitsniveau. Wanneer een nieuwe functionaliteit echter een wijziging introduceert in het gedrag van bestaande taken of een wijziging in de manier waarop gegevens worden gebruikt in actieve taken, introduceren we deze wijziging onder een nieuw compatibiliteitsniveau. U kunt ervoor zorgen dat uw bestaande Stream Analytics-taken worden uitgevoerd zonder grote wijzigingen door de instelling voor compatibiliteitsniveau te laten verlagen. Wanneer u klaar bent voor het nieuwste runtimegedrag, kunt u zich aanmelden door het compatibiliteitsniveau te verhogen.
Een compatibiliteitsniveau kiezen
Compatibiliteitsniveau bepaalt het runtimegedrag van een Stream Analytics-taak.
Azure Stream Analytics ondersteunt momenteel drie compatibiliteitsniveaus:
- 1.2 - Nieuw gedrag met de meest recente verbeteringen
- 1.1 - Vorig gedrag
- 1.0 - Oorspronkelijk compatibiliteitsniveau, geïntroduceerd tijdens de algemene beschikbaarheid van Azure Stream Analytics enkele jaren geleden.
Wanneer u een nieuwe Stream Analytics-taak maakt, is het een best practice om deze te maken met behulp van het meest recente compatibiliteitsniveau. Start uw taakontwerp op basis van het nieuwste gedrag om later te voorkomen dat er wijzigingen en complexiteit zijn toegevoegd.
Het compatibiliteitsniveau instellen
U kunt het compatibiliteitsniveau voor een Stream Analytics-taak instellen in Azure Portal of met behulp van de REST API-aanroep voor de taak maken.
Het compatibiliteitsniveau van de taak bijwerken in Azure Portal:
- Gebruik Azure Portal om naar uw Stream Analytics-taak te zoeken.
- Stop de taak voordat u het compatibiliteitsniveau bijwerkt. U kunt het compatibiliteitsniveau niet bijwerken als uw taak de status Actief heeft.
- Selecteer onder de kop Configureren het compatibiliteitsniveau.
- Kies de gewenste waarde voor het compatibiliteitsniveau.
- Selecteer Opslaan onder aan de pagina.
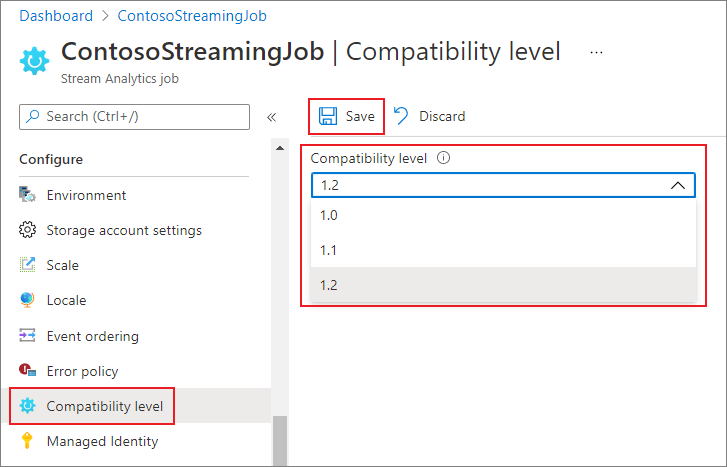
Wanneer u het compatibiliteitsniveau bijwerkt, valideert de T-compiler de taak met de syntaxis die overeenkomt met het geselecteerde compatibiliteitsniveau.
Compatibiliteitsniveau 1.2
De volgende belangrijke wijzigingen worden geïntroduceerd in compatibiliteitsniveau 1.2:
AMQP-berichtenprotocol
Niveau 1.2: Azure Stream Analytics maakt gebruik van het AMQP-berichtenprotocol (Advanced Message Queueing Protocol) om te schrijven naar Service Bus-wachtrijen en -onderwerpen. Met AMQP kunt u platformoverschrijdende, hybride toepassingen bouwen met behulp van een open standaardprotocol.
Georuimtelijke functies
Vorige niveaus: Azure Stream Analytics heeft geografieberekeningen gebruikt.
1.2-niveau: Met Azure Stream Analytics kunt u geometrisch geprojecteerde geocoördinaten berekenen. Er is geen wijziging in de signatuur van de geospatiale functies. Hun semantiek is echter iets anders, waardoor nauwkeurigere berekeningen mogelijk zijn dan voorheen.
Azure Stream Analytics biedt ondersteuning voor georuimtelijke verwijzingsgegevensindexering. Referentiegegevens met georuimtelijke elementen kunnen worden geïndexeerd voor een snellere joinberekening.
De bijgewerkte georuimtelijke functies brengen de volledige expressiviteit van de georuimtelijke indeling van WKT (Well Known Text) met zich mee. U kunt andere georuimtelijke onderdelen opgeven die eerder niet werden ondersteund met GeoJson.
Zie Updates voor georuimtelijke functies in Azure Stream Analytics – Cloud en IoT Edge voor meer informatie.
Parallelle queryuitvoering voor invoerbronnen met meerdere partities
Vorige niveaus: Voor Azure Stream Analytics-query's is het gebruik van de PARTITION BY-component vereist om queryverwerking te parallelliseren voor invoerbronpartities.
1.2-niveau: Als querylogica kan worden geparallelliseerd tussen invoerbronpartities, worden in Azure Stream Analytics afzonderlijke query-exemplaren gemaakt en worden berekeningen parallel uitgevoerd.
Systeemeigen bulk-API-integratie met Azure Cosmos DB-uitvoer
Vorige niveaus: Het upsert-gedrag was invoegen of samenvoegen.
1.2-niveau: De systeemeigen integratie van de bulk API met Azure Cosmos DB-uitvoer maximaliseert de doorvoer en verwerkt limietaanvragen efficiënt. Zie de azure Stream Analytics-uitvoer naar de azure Cosmos DB-pagina voor meer informatie.
Het upsert-gedrag is invoegen of vervangen.
DateTimeOffset bij het schrijven naar SQL-uitvoer
Vorige niveaus:Typen DateTimeOffset zijn aangepast aan UTC.
Niveau 1.2: DateTimeOffset is niet meer aangepast.
Bij een lange verwerkingstijd tijdens het schrijven naar SQL-uitvoer
Vorige niveaus: waarden zijn afgekort volgens het doeltype.
Niveau 1.2: Waarden die niet in het doeltype passen, worden verwerkt volgens het uitvoerfoutbeleid.
Serialisatie van records en matrices bij het schrijven naar SQL-uitvoer
Vorige niveaus: Records zijn geschreven als 'Record' en matrices zijn geschreven als 'Matrix'.
Niveau 1.2: Records en matrices worden geserialiseerd in JSON-indeling.
Strikte validatie van voorvoegsel van functies
Vorige niveaus: Er was geen strikte validatie van functievoorvoegsels.
Niveau 1.2: Azure Stream Analytics heeft een strikte validatie van functievoorvoegsels. Het toevoegen van een voorvoegsel aan een ingebouwde functie veroorzaakt een fout. Wordt bijvoorbeeldmyprefix.ABS(…) niet ondersteund.
Het toevoegen van een voorvoegsel aan ingebouwde aggregaties resulteert ook in een fout. Wordt bijvoorbeeld myprefix.SUM(…) niet ondersteund.
Het gebruik van het voorvoegsel 'systeem' voor door de gebruiker gedefinieerde functies resulteert in een fout.
Verbied Array en Object als sleutelkenmerken in de Azure Cosmos DB-uitvoeradapter
Vorige niveaus: matrix- en objecttypen werden ondersteund als een sleuteleigenschap.
Niveau 1.2: Matrix- en objecttypen worden niet meer ondersteund als sleuteleigenschap.
Booleaanse type deserialiseren in JSON, AVRO en PARQUET
Vorige niveaus: Azure Stream Analytics deserializeert booleaanse waarde in het type BIGINT: onwaar wordt toegewezen aan 0 en true-toewijzingen aan 1. De uitvoer maakt alleen booleaanse waarden in JSON, AVRO en PARQUET als u expliciet gebeurtenissen converteert naar BIT.
Een passthrough-query, zoals SELECT value INTO output1 FROM input1 het lezen van een JSON { "value": true } uit invoer1, schrijft bijvoorbeeld naar de uitvoer1 een JSON-waarde { "value": 1 }.
Niveau 1.2: Azure Stream Analytics deserializeert booleaanse waarde in het type BIT. Onwaar wordt toegewezen aan 0 en true wordt toegewezen aan 1. Een passthrough-query, zoals SELECT value INTO output1 FROM input1, die een JSON { "value": true } leest uit input1, zal een JSON-waarde { "value": true } schrijven naar uitvoer1. U kunt waarde casten naar het type BIT in de query zodat ze als waar en onwaar worden weergegeven in de uitvoer voor indelingen die het booleaans type ondersteunen.
Compatibiliteitsniveau 1.1
De volgende belangrijke wijzigingen worden geïntroduceerd in compatibiliteitsniveau 1.1:
Service Bus XML-indeling
1.0-niveau: Azure Stream Analytics heeft DataContractSerializer gebruikt, zodat de berichtinhoud XML-tags bevat. Voorbeeld:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
Niveau 1.1: De inhoud van het bericht bevat de stream rechtstreeks zonder extra tags. Bijvoorbeeld: { "SensorId":"1", "Temperature":64}
Persistente hoofdlettergevoeligheid voor veldnamen
1.0-niveau: veldnamen zijn gewijzigd in kleine letters bij verwerking door de Azure Stream Analytics-engine.
1.1-niveau: hoofdlettergevoeligheid wordt behouden voor veldnamen wanneer ze worden verwerkt door de Azure Stream Analytics-engine.
Notitie
Persistente hoofdlettergevoeligheid is nog niet beschikbaar voor Stream Analytics-taken die worden gehost met behulp van de Edge-omgeving. Als gevolg hiervan worden alle veldnamen geconverteerd naar kleine letters als uw taak wordt gehost op Edge.
FloatNaNDeserializationDisabled
1.0-niveau: de opdracht CREATE TABLE heeft geen gebeurtenissen gefilterd met NaN (Not-a-Number). Bijvoorbeeld Infinity, -Infinity) in een float-kolomtype omdat ze buiten het gedocumenteerde bereik voor deze getallen vallen.
1.1-niveau: MET CREATE TABLE kunt u een sterk schema opgeven. De Stream Analytics-engine valideert dat de gegevens voldoen aan dit schema. Met dit model kan de opdracht gebeurtenissen filteren met NaN-waarden.
Automatische conversie van datum/tijd-tekenreeksen naar datum/tijd-type uitschakelen bij inkomend verkeer voor JSON
1.0-niveau: De JSON-parser converteert tekenreekswaarden automatisch met datum-/tijd-/zonegegevens naar datum/tijd-type bij inkomend verkeer, zodat de waarde onmiddellijk de oorspronkelijke opmaak en tijdzonegegevens verliest. Omdat dit gebeurt bij inkomend verkeer, zelfs als dat veld niet is gebruikt in de query, wordt het geconverteerd naar UTC DateTime.
Niveau 1.1: Er is geen automatische conversie van tekenreekswaarden met datum/tijd/zone-informatie naar datum/tijd-type. Hierdoor worden tijdzonegegevens en oorspronkelijke opmaak bewaard. Als het veld NVARCHAR(MAX) echter wordt gebruikt in de query als onderdeel van een DATUM/TIJD-expressie (de functie DATEADD), wordt het geconverteerd naar het type DATETIME om de berekening uit te voeren en verliest het oorspronkelijke formulier.