Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Stream Analytics kan gegevens uitvoeren in JSON-indeling naar Azure Cosmos DB. Hiermee kunt u query's voor gegevensarchivering en lage latentie uitvoeren op ongestructureerde JSON-gegevens. In dit artikel worden enkele aanbevolen procedures beschreven voor het implementeren van deze configuratie (Stream Analytics naar Cosmos DB). Als u niet bekend bent met Azure Cosmos DB, raadpleegt u de Documentatie van Azure Cosmos DB om aan de slag te gaan.
Notitie
- Op dit moment ondersteunt Stream Analytics alleen verbinding met Azure Cosmos DB via de SQL-API. Andere Azure Cosmos DB-API's worden nog niet ondersteund. Als u Stream Analytics naar Azure Cosmos DB-accounts wijst die zijn gemaakt met andere API's, worden de gegevens mogelijk niet correct opgeslagen.
- U wordt aangeraden uw taak in te stellen op compatibiliteitsniveau 1.2 wanneer u Azure Cosmos DB als uitvoer gebruikt.
Basisbeginselen van Azure Cosmos DB als uitvoerdoel
Met de Azure Cosmos DB-uitvoer in Stream Analytics kunt u uw resultaten van streamverwerking als JSON-uitvoer naar uw Azure Cosmos DB-containers schrijven. Stream Analytics maakt geen containers in uw database. In plaats daarvan moet u ze vooraf maken. Vervolgens kunt u de factureringskosten van Azure Cosmos DB-containers beheren. U kunt de prestaties, consistentie en capaciteit van uw containers ook rechtstreeks afstemmen met behulp van de Azure Cosmos DB-API's. In de volgende secties worden enkele van de containeropties voor Azure Cosmos DB beschreven.
Consistentie, beschikbaarheid en latentie afstemmen
Om aan uw toepassingsvereisten te voldoen, kunt u met Azure Cosmos DB de database en containers verfijnen en afwegingen maken tussen consistentie, beschikbaarheid, latentie en doorvoer.
Afhankelijk van de mate van leesconsistentie die uw scenario nodig heeft voor lees- en schrijflatentie, kunt u een consistentieniveau kiezen voor uw databaseaccount. U kunt de doorvoer verbeteren door aanvraageenheden (RU's) op de container op te schalen. Azure Cosmos DB maakt ook standaard synchrone indexering mogelijk voor elke CRUD-bewerking naar uw container. Deze optie is een andere handige optie voor het beheren van schrijf-/leesprestaties in Azure Cosmos DB. Raadpleeg het artikel Wijzig uw database en de consistentieniveaus van query’s voor meer informatie.
Upserts uitgevoerd door Stream Analytics
Met Stream Analytics-integratie met Azure Cosmos DB kunt u records in uw container invoegen of bijwerken op basis van een bepaalde document-id-kolom . Deze bewerking wordt ook wel een upsert genoemd. Stream Analytics maakt gebruik van een optimistische upsert-benadering. Updates worden alleen uitgevoerd wanneer een invoegbewerking mislukt met een document-id-conflict.
Met compatibiliteitsniveau 1.0 voert Stream Analytics deze update uit als PATCH-bewerking, zodat gedeeltelijke updates voor het document worden ingeschakeld. Stream Analytics voegt nieuwe eigenschappen toe of vervangt incrementeel een bestaande eigenschap. Wijzigingen in de waarden van matrixeigenschappen in uw JSON-document resulteren echter in het overschrijven van de hele matrix. Dat wil zeggen, de array wordt niet samengevoegd.
Met 1.2 wordt het upsert-gedrag gewijzigd om het document in te voegen of te vervangen. In de latere sectie over compatibiliteitsniveau 1.2 wordt dit gedrag verder beschreven.
Als het binnenkomende JSON-document een bestaand id-veld heeft, wordt dat veld automatisch gebruikt als de kolom Document-id in Azure Cosmos DB. Eventuele volgende schrijfbewerkingen worden als zodanig verwerkt, wat leidt tot een van deze situaties:
- Unieke id's leiden tot invoegen.
- Dubbele IDs en Document-ID's die zijn ingesteld op ID leiden tot upsert.
- Dubbele id's en document-id's die niet zijn ingesteld, leiden tot een fout, na het eerste document.
Als u alle documenten wilt opslaan, inclusief documenten met een dubbele id, wijzigt u de naam van het id-veld in uw query (met behulp van het AS-trefwoord). Laat Azure Cosmos DB het id-veld maken of de id vervangen door de waarde van een andere kolom (met behulp van het AS-trefwoord of met behulp van de instelling Document-id ).
Gegevenspartitionering in Azure Cosmos DB
In Azure Cosmos DB worden partities automatisch geschaald op basis van uw workload. Daarom raden we u aan onbeperkte containers te gebruiken voor het partitioneren van uw gegevens. Wanneer Stream Analytics naar onbeperkte containers schrijft, wordt gebruikgemaakt van zoveel parallelle schrijvers als de vorige querystap of het schema voor het partitioneren van invoer.
Notitie
Azure Stream Analytics ondersteunt alleen onbeperkte containers met partitiesleutels op het hoogste niveau. Bijvoorbeeld, /region wordt ondersteund. Geneste partitiesleutels (bijvoorbeeld /region/name) worden niet ondersteund.
Afhankelijk van uw keuze van de partitiesleutel, ontvangt u mogelijk deze waarschuwing:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Het is belangrijk om een partitiesleuteleigenschap te kiezen met veel afzonderlijke waarden en waarmee u uw workload gelijkmatig over deze waarden kunt verdelen. Als een natuurlijk artefact van partitioneren worden aanvragen met dezelfde partitiesleutel beperkt door de maximale doorvoer van één partitie.
De opslaggrootte voor documenten die deel uitmaken van dezelfde partitiesleutelwaarde is beperkt tot 20 GB (de limiet voor de fysieke partitiegrootte is 50 GB). Een ideale partitiesleutel is de sleutel die vaak wordt weergegeven als een filter in uw query's en voldoende kardinaliteit heeft om ervoor te zorgen dat uw oplossing schaalbaar is.
Partitiesleutels die worden gebruikt voor Stream Analytics-query's en Azure Cosmos DB hoeven niet identiek te zijn. Volledig parallelle topologieën raden u aan invoerpartitiesleutel te gebruiken, als de partitiesleutel van de Stream Analytics-query, PartitionIdmaar dat is mogelijk niet de aanbevolen keuze voor de partitiesleutel van een Azure Cosmos DB-container.
Een partitiesleutel is ook de grens voor transacties in opgeslagen procedures en triggers voor Azure Cosmos DB. U moet de partitiesleutel kiezen, zodat documenten die samen voorkomen in transacties dezelfde partitiesleutelwaarde delen. In het artikel Partitionering in Azure Cosmos DB vindt u meer informatie over het kiezen van een partitiesleutel.
Voor vaste Azure Cosmos DB-containers kunt u met Stream Analytics niet omhoog of omlaag schalen nadat ze vol zijn. Ze hebben een bovengrens van 10 GB en 10.000 RU/s aan doorvoer. Als u de gegevens van een vaste container wilt migreren naar een onbeperkte container (bijvoorbeeld één met ten minste 1000 RU/s en een partitiesleutel), gebruikt u het hulpprogramma voor gegevensmigratie of de bibliotheek voor wijzigingenfeeds.
De mogelijkheid om naar meerdere vaste containers te schrijven, wordt afgeschaft. Het wordt afgeraden om uw Stream Analytics-taak uit te schalen.
Verbeterde doorvoer met compatibiliteitsniveau 1.2
Met compatibiliteitsniveau 1.2 ondersteunt Stream Analytics systeemeigen integratie om bulksgewijs te schrijven naar Azure Cosmos DB. Met deze integratie kunt u effectief naar Azure Cosmos DB schrijven terwijl de doorvoer wordt gemaximaliseerd en verzoeken voor throttling efficiënt worden afgehandeld.
Het verbeterde schrijfmechanisme is beschikbaar op een nieuw compatibiliteitsniveau vanwege verschillen in het upsertgedrag. Met versies voor 1.2 is het upsert-gedrag gericht op het invoegen of samenvoegen van het document. Met 1.2 wordt het upsert-gedrag gewijzigd om het document in te voegen of te vervangen.
Met niveaus vóór 1.2 maakt Stream Analytics gebruik van een aangepaste opgeslagen procedure om documenten per partitiesleutel in bulk te upserten in Azure Cosmos DB. Daar wordt een batch geschreven als een transactie. Zelfs wanneer een enkel record een tijdelijke fout (demping) ervaart, moet de hele batch opnieuw worden verwerkt. Dit gedrag maakt scenario's met zelfs een redelijke snelheidsbeperking relatief traag.
In het volgende voorbeeld ziet u twee identieke Stream Analytics-taken die worden gelezen uit dezelfde Azure Event Hubs-invoer. Beide Stream Analytics-taken zijn volledig gepartitioneerd met een passthrough-query en schrijven naar identieke Azure Cosmos DB-containers. De metrische gegevens aan de linkerkant zijn afkomstig van de taak die is geconfigureerd met compatibiliteitsniveau 1.0. Metrische gegevens aan de rechterkant worden geconfigureerd met 1.2. De partitiesleutel van een Azure Cosmos DB-container is een unieke GUID die afkomstig is van de invoergebeurtenis.
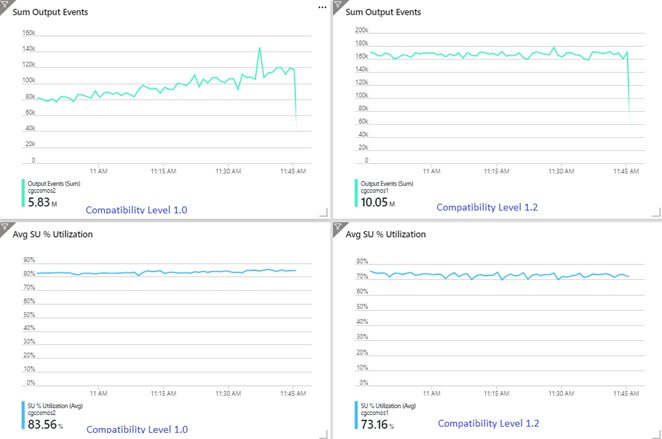
De snelheid van binnenkomende gebeurtenissen in Event Hubs is twee keer hoger dan de Azure Cosmos DB-containers (20.000 RU's) geconfigureerd zijn om te verwerken, dus een beperking wordt verwacht in Azure Cosmos DB. De taak met 1,2 schrijft echter consistent met een hogere doorvoer (uitvoer gebeurtenissen per minuut) en met een lager gemiddeld SU%-gebruik. In uw omgeving is dit verschil afhankelijk van nog enkele factoren. Deze factoren omvatten de keuze van de gebeurtenisindeling, de grootte van invoer-gebeurtenis/bericht, partitiesleutels en query's.
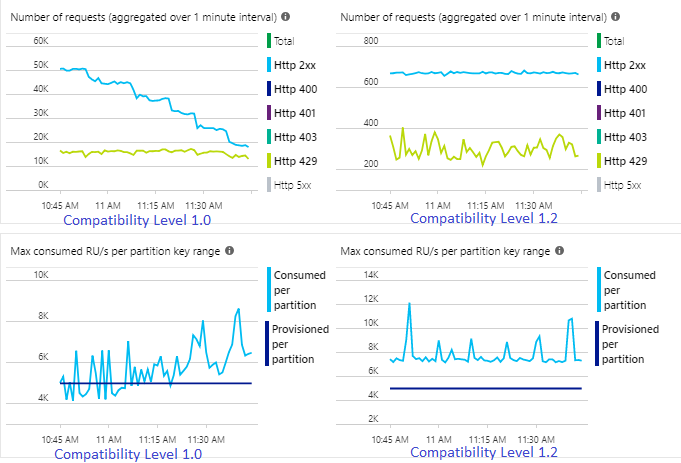
Met 1.2 is Stream Analytics intelligenter in het benutten van 100 procent van de beschikbare doorvoer in Azure Cosmos DB met minder herindieningen door beperking of snelheidsbeperking. Dit gedrag biedt een betere ervaring voor andere workloads, zoals query's die tegelijkertijd op de container worden uitgevoerd. Als u wilt zien hoe Stream Analytics wordt uitgeschaald met Azure Cosmos DB als sink voor 10.000 tot 10.000 berichten per seconde, kunt u dit Azure-voorbeeldproject proberen.
De doorvoer van Azure Cosmos DB-uitvoer is identiek aan 1.0 en 1.1. We raden u ten zeerste aan compatibiliteitsniveau 1.2 te gebruiken in Stream Analytics met Azure Cosmos DB.
Azure Cosmos DB-instellingen voor JSON-uitvoer
Als u Azure Cosmos DB gebruikt als uitvoer in Stream Analytics, wordt de volgende prompt voor informatie gegenereerd.
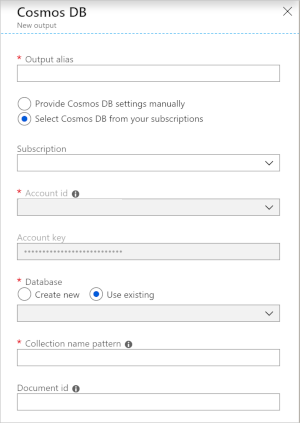
| Veld | Beschrijving |
|---|---|
| Uitvoeralias | Een alias die naar deze uitvoer in uw Stream Analytics-query verwijst. |
| Abonnement | Het Azure-abonnement. |
| Account-ID | De naam of eindpunt-URI van het Azure Cosmos DB-account. |
| Accountsleutel | De gedeelde toegangssleutel voor het Azure Cosmos DB-account. |
| Database | De naam van de Azure Cosmos DB-database. |
| Containernaam | De containernaam, zoals MyContainer. Er moet één container met de naam MyContainer bestaan. |
| Document-ID | Optioneel. De kolomnaam in uitvoergebeurtenissen die wordt gebruikt als de unieke sleutel waarop invoeg- of updatebewerkingen moeten worden gebaseerd. Als u deze leeg laat, worden alle gebeurtenissen ingevoegd, zonder bijwerkoptie. |
Nadat u de Uitvoer van Azure Cosmos DB hebt geconfigureerd, kunt u deze in de query gebruiken als doel van een INTO-instructie. Wanneer u op die manier een Azure Cosmos DB-uitvoer gebruikt, moet een partitiesleutel expliciet worden ingesteld.
De uitvoerrecord moet een hoofdlettergevoelige kolom bevatten met de naam van de partitiesleutel in Azure Cosmos DB. Voor een grotere parallellisatie vereist de instructie mogelijk een PARTITION BY-component die gebruikmaakt van dezelfde kolom.
Hier is een voorbeeldquery:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Foutafhandeling en nieuwe pogingen
Als er sprake is van een tijdelijke fout, service niet beschikbaar of bandbreedtebeperking terwijl Stream Analytics gebeurtenissen verzendt naar Azure Cosmos DB, probeert Stream Analytics de bewerking voor onbepaalde tijd opnieuw uit te voeren om de bewerking te voltooien. Maar er worden geen nieuwe pogingen gedaan voor de volgende fouten:
- Niet geautoriseerd (HTTP-foutcode 401)
- Niet Gevonden (HTTP-foutcode 404)
- Verboden (HTTP-foutcode 403)
- BadRequest (HTTP-foutcode 400)
Algemene problemen
Er wordt een unieke indexbeperking toegevoegd aan de verzameling en de uitvoergegevens van Stream Analytics schenden deze beperking. Zorg ervoor dat de uitvoergegevens van Stream Analytics niet in strijd zijn met unieke beperkingen of beperkingen verwijderen. Zie Unieke sleutelbeperkingen in Azure Cosmos DB voor meer informatie.
De
PartitionKeykolom bestaat niet.De
Idkolom bestaat niet.