Quickstart: Gegevens opnemen met Behulp van Azure Synapse Pipelines (preview)
In deze quickstart leert u hoe u gegevens uit een gegevensbron laadt in de Azure Synapse Data Explorer-pool.
Vereisten
Een Azure-abonnement. Maak een gratis Azure-account.
Een Data Explorer-pool maken met Synapse Studio of Azure Portal
Maak een Data Explorer-database.
Selecteer Gegevens in Synapse Studio in het linkerdeelvenster.
Selecteer + (Nieuwe resource toevoegen) >Data Explorer-pool en gebruik de volgende informatie:
Instelling Voorgestelde waarde Beschrijving Poolnaam contosodataexplorer De naam van de Data Explorer-pool die moet worden gebruikt Naam TestDatabase De databasenaam moet uniek zijn binnen het cluster. Standaardretentieperiode 365 De periode (in dagen) dat de gegevens gegarandeerd beschikbaar blijven voor query's. De periode wordt gemeten vanaf het moment dat de gegevens zijn opgenomen. Standaardcacheperiode 31 De periode (in dagen) dat vaak opgevraagde gegevens beschikbaar blijven in de SSD-opslag of het RAM-geheugen in plaats van in de langetermijnopslag. Selecteer Maken om het profiel te maken. Het maakproces duurt meestal minder dan een minuut.
Een tabel maken
- Selecteer Ontwikkelen in Synapse Studio in het linkerdeelvenster.
- Selecteer + (nieuwe resource toevoegen) >KQL-script onder KQL-scripts onder KQL-scripts. In het rechterdeelvenster kunt u uw script een naam geven.
- Selecteer in het menu Verbinding maken om contosodataexplorer te selecteren.
- Selecteer TestDatabase in het menu Database gebruiken.
- Plak de volgende opdracht en selecteer Uitvoeren om de tabel te maken.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tip
Controleer of de tabel is gemaakt. Selecteer in het linkerdeelvenster Gegevens, selecteer het menu contosodataexplorer meer en selecteer Vervolgens Vernieuwen. Vouw onder contosodataexplorer Tabellen uit en zorg ervoor dat de tabel StormEvents wordt weergegeven in de lijst.
Haal de query- en gegevensopname-eindpunten op. U hebt het query-eindpunt nodig om uw gekoppelde service te configureren.
Selecteer in Synapse Studio in het linkerdeelvenster Data Explorer-pools beheren>.
Selecteer de Data Explorer-pool die u wilt gebruiken om de details ervan weer te geven.
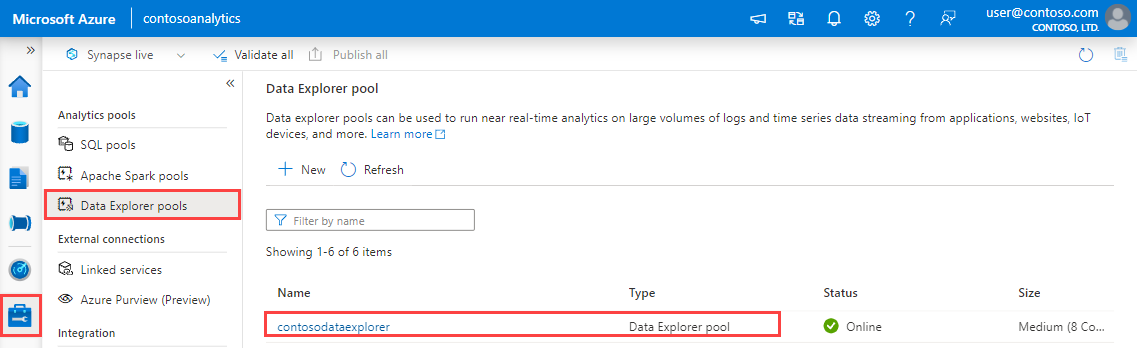
Noteer de eindpunten voor query- en gegevensopname. Gebruik het query-eindpunt als het cluster bij het configureren van verbindingen met uw Data Explorer-pool. Wanneer u SDK's configureert voor gegevensopname, gebruikt u het eindpunt voor gegevensopname.
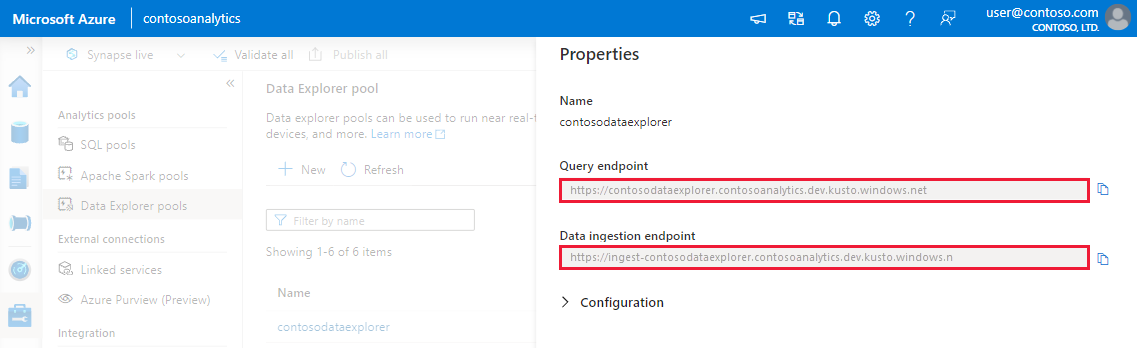
Een gekoppelde service maken
In Azure Synapse Analytics definieert u de verbindingsgegevens voor andere services in een gekoppelde service. In deze sectie maakt u een gekoppelde service voor Azure Data Explorer.
Selecteer in Synapse Studio in het linkerdeelvenster Gekoppelde services beheren>.
Selecteer + Nieuw.
Selecteer de Azure Data Explorer-service in de galerie en selecteer vervolgens Doorgaan.

Gebruik op de pagina Nieuwe gekoppelde services de volgende informatie:
Instelling Voorgestelde waarde Omschrijving Naam contosodataexplorerlinkedservice De naam voor de nieuwe gekoppelde Azure Data Explorer-service. Verificatiemethode Beheerde identiteit De verificatiemethode voor de nieuwe service. Methode voor account selecteren Handmatig invoeren De methode voor het opgeven van het query-eindpunt. Eindpunt https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Het query-eindpunt dat u eerder hebt genoteerd. Database TestDatabase De database waarin u gegevens wilt opnemen. 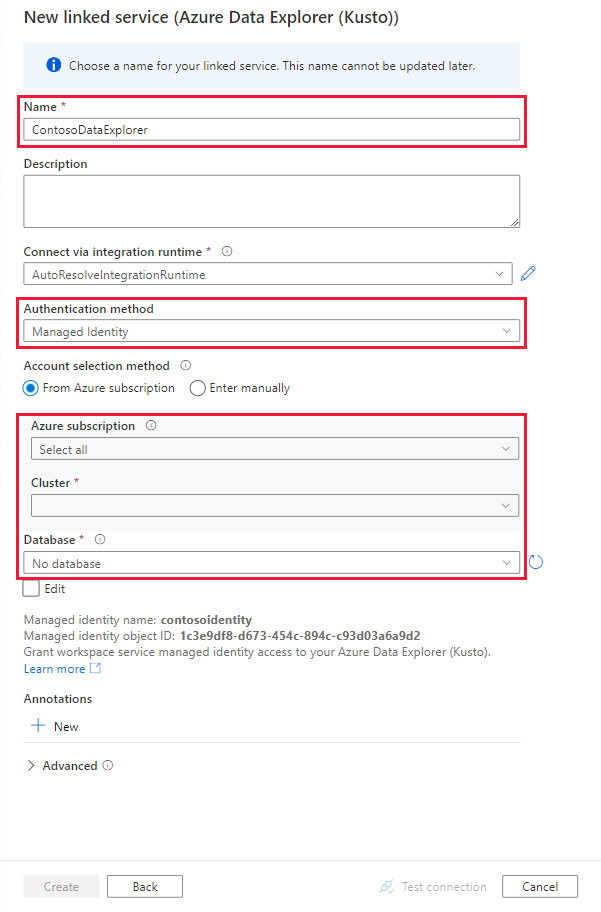
Selecteer Verbinding testen om de instellingen te valideren en selecteer vervolgens Maken.
Een pijplijn maken om gegevens op te nemen
Een pijplijn bevat de logische stroom voor het uitvoeren van een reeks activiteiten. In deze sectie maakt u een pijplijn met een kopieeractiviteit waarmee gegevens uit uw voorkeursbron worden opgenomen in een Data Explorer-pool.
Selecteer Integreren in Synapse Studio in het linkerdeelvenster.
Selecteer +>Pijplijn. In het rechterdeelvenster kunt u uw pijplijn een naam geven.
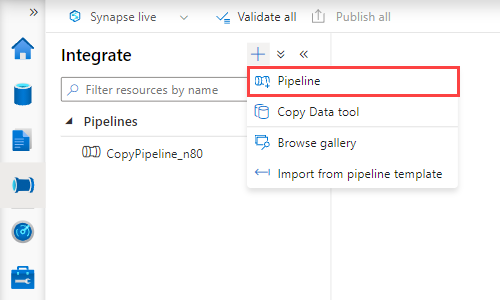
Sleep onder Activiteiten>verplaatsen en transformeren gegevens naar het pijplijncanvas kopiëren.
Selecteer de kopieeractiviteit en ga naar het tabblad Bron . Selecteer of maak een nieuwe brongegevensset als de bron waaruit u gegevens wilt kopiëren.
Ga naar het tabblad Sink . Selecteer Nieuw om een nieuwe sinkgegevensset te maken.
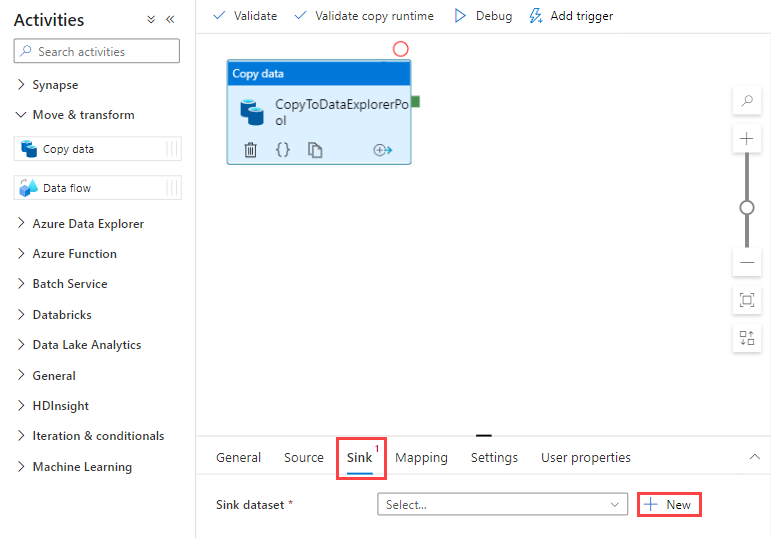
Selecteer de Azure Data Explorer-gegevensset in de galerie en selecteer vervolgens Doorgaan.
Gebruik in het deelvenster Eigenschappen instellen de volgende informatie en selecteer VERVOLGENS OK.
Instelling Voorgestelde waarde Omschrijving Naam AzureDataExplorerTable De naam voor de nieuwe pijplijn. Gekoppelde service contosodataexplorerlinkedservice De gekoppelde service die u eerder hebt gemaakt. Table StormEvents De tabel die u eerder hebt gemaakt. 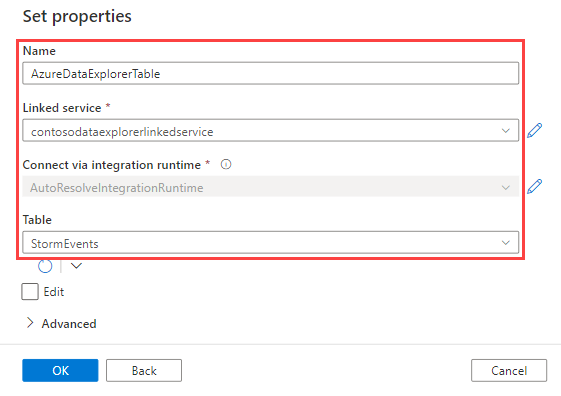
Klik in de werkbalk op Valideren om de pijplijn te valideren. U ziet het resultaat van de validatie-uitvoer voor de pijplijn aan de rechterkant van de pagina.
Fouten opsporen in de pijplijn en de pijplijn publiceren
Wanneer u klaar bent met het configureren van de pijplijn, kunt u deze uitvoeren om fouten op te sporten voordat u uw artefacten publiceert en te controleren of alles klopt.
Selecteer Fouten opsporen op de werkbalk. De status van de pijplijnuitvoering wordt weergegeven op het tabblad Uitvoer onder in het venster.
Zodra de pijplijn goed kan worden uitgevoerd, selecteert u Alles publiceren in de bovenste werkbalk. Met deze actie worden entiteiten (gegevenssets en pijplijnen) gepubliceerd die u hebt gemaakt in de Synapse Analytics-service.
Wacht totdat het bericht Successfully published wordt weergegeven. Als u meldingsberichten wilt zien, selecteert u de belknop in de rechterbovenhoek.
De pijplijn activeren en controleren
In deze sectie moet u de pijplijn die u in de vorige stap heeft gepubliceerd, handmatig activeren.
Selecteer op de werkbalk de optie Trigger toevoegen en selecteer vervolgens Nu activeren. Klik op de pagina Pijplijnuitvoering op OK.
Ga naar het tabblad Controle in de zijbalk aan de linkerkant. U ziet een pijplijn die wordt geactiveerd door een handmatige trigger.
Wanneer de uitvoering van de pijplijn is voltooid, selecteert u de koppeling onder de kolom Pijplijnnaam om de details van de uitvoering van de activiteit weer te geven of om de pijplijn opnieuw uit te voeren. Omdat er in dit voorbeeld slechts één activiteit is, ziet u slechts één vermelding in de lijst.
Selecteer de koppeling Details (pictogram van een bril) in de kolom Naam activiteit om details van de kopieerbewerking te zien. U kunt details bekijken, zoals het volume van de gegevens die uit de bron zijn gekopieerd naar de sink, de gegevensdoorvoer, de uitvoeringsstappen met de overeenkomstige duur en de gebruikte configuraties.
Als u wilt terugkeren naar de weergave met de pijplijnuitvoeringen, selecteert u de koppeling Alle pijplijnuitvoeringen bovenaan. Selecteer Vernieuwen om de lijst te vernieuwen.
Controleer of uw gegevens correct zijn geschreven in de Data Explorer-pool.