Omgeving instellen voor Azure AI-services voor big data
Uw omgeving instellen is de eerste stap om een pijplijn te ontwerpen voor uw gegevens. Wanneer uw omgeving klaar is, kunt u gemakkelijk en snel een voorbeeld uitvoeren.
In dit artikel voert u de volgende stappen uit om aan de slag te gaan:
Een Azure AI-servicesresource maken
Als u wilt werken met big data in Azure AI-services, maakt u eerst een Azure AI-servicesresource voor uw werkstroom. Er zijn twee hoofdtypen Azure AI-services: cloudservices die worden gehost in Azure en in containers geplaatste services die worden beheerd door gebruikers. We raden u aan om te beginnen met de eenvoudigere Azure AI-services in de cloud.
Cloudservices
Cloudgebaseerde Azure AI-services zijn intelligente algoritmen die worden gehost in Azure. Deze services zijn klaar voor gebruik zonder training. U hebt hiervoor alleen een internetverbinding nodig. U kunt resources maken voor Azure AI-services in Azure Portal of met de Azure CLI.
In een container geplaatste services (optioneel)
Als uw toepassing of workload grote gegevenssets gebruikt, een particulier netwerk nodig heeft of geen contact kan maken met de cloud, kan communicatie met cloudservices wel eens niet mogelijk zijn. In dit geval hebben containerservices van Azure AI de volgende voordelen:
Lage Verbinding maken iviteit: u kunt in containers geplaatste Azure AI-services implementeren in elke computeromgeving, zowel on-cloud als off. Als uw toepassing geen contact kan opnemen met de cloud, kunt u overwegen om in containers geplaatste Azure AI-services in uw toepassing te implementeren.
Lage latentie: omdat in containers geplaatste services geen retourcommunicatie naar/van de cloud vereisen, worden antwoorden geretourneerd met veel lagere latenties.
Privacy- en gegevensbeveiliging: u kunt in containers geplaatste services implementeren in privénetwerken, zodat gevoelige gegevens het netwerk niet verlaten.
Hoge schaalbaarheid: in containers geplaatste services hebben geen frequentielimieten en worden uitgevoerd op door gebruikers beheerde computers. U kunt Azure AI-services dus schalen zonder einde om veel grotere workloads af te handelen.
Volg deze handleiding om een in een container geplaatste Azure AI-service te maken.
Een Apache Spark-cluster maken
Apache Spark™ is een gedistribueerd computingframework dat is ontworpen voor verwerking van big data. Gebruikers kunnen werken met Apache Spark in Azure met services zoals Azure Databricks, Azure Synapse Analytics, HDInsight en Azure Kubernetes Services. Als u de Azure AI-services voor big data wilt gebruiken, moet u eerst een cluster maken. Als u al een Spark-cluster hebt, dan kunt u een voorbeeld uitproberen.
Azure Databricks
Azure Databricks is een op Apache Spark gebaseerd analyseplatform dat met één klik geconfigureerd kan worden, gestroomlijnde werkstromen en een interactieve werkruimte heeft. Het wordt vaak gebruikt om samen te werken tussen gegevenswetenschappers, technici en bedrijfsanalisten. Als u de Azure AI-services voor big data in Azure Databricks wilt gebruiken, voert u de volgende stappen uit:
Installeer de opensource-bibliotheek van SynapseML (of MMLSpark-bibliotheek als u een verouderde toepassing ondersteunt):
Maak een nieuwe bibliotheek in uw databricks-werkruimte
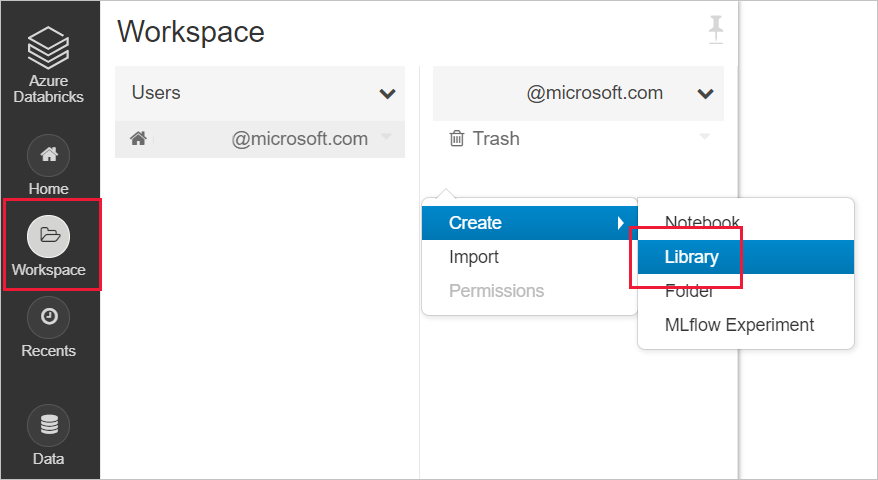
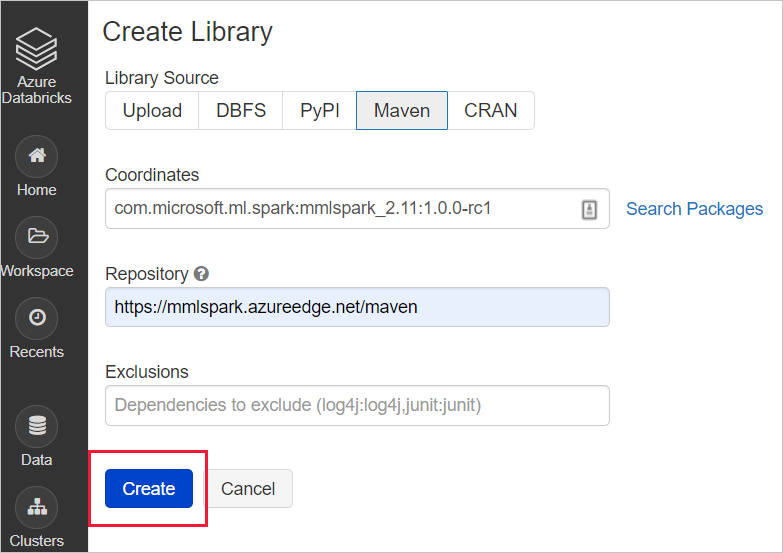
Voor SynapseML: voer de volgende maven-coördinaten coördinaten in:
com.microsoft.azure:synapseml_2.12:0.10.0Opslagplaats: standaardVoor MMLSpark (verouderd): voer de volgende maven-coördinaten coördinaten in:
com.microsoft.ml.spark:mmlspark_2.11:1.0.0-rc3Opslagplaats:https://mmlspark.azureedge.net/maven
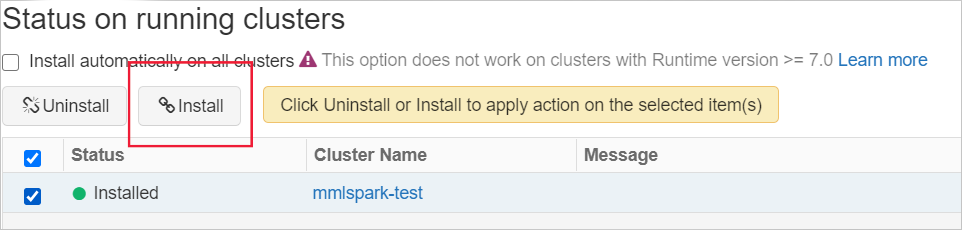
Installeer de bibliotheek op een cluster
Azure Synapse Analytics (optioneel)
U kunt Synapse Analytics ook gebruiken om een Spark-cluster te maken. Azure Synapse Analytics brengt datawarehousing voor ondernemingen en big data-analyses samen. Deze geeft u de vrijheid om op schaal gegevens op te vragen over uw voorwaarden, met behulp van serverloze on-demand of ingerichte resources. Voer de volgende stappen uit om aan de slag te gaan met Azure Synapse Analytics:
In Azure Synapse Analytics worden big data voor Azure AI-services standaard geïnstalleerd.
Azure Kubernetes Service
Als u containerservices van Azure AI gebruikt, is de Azure Kubernetes Service een populaire optie voor het implementeren van Spark naast containers.
Om aan de slag te gaan met Azure Kubernetes Service, volgt u deze stappen:
Een AKS-cluster (Azure Kubernetes Service) implementeren met behulp van de Azure-portal
Installeer de Helm-grafiek van Apache Spark 2.4.0- waarschuwing: Spark 2.4 wordt buiten gebruik gesteld en wordt niet ondersteund.
Een voorbeeld uitproberen
Nadat u uw Spark-cluster en -omgeving hebt ingesteld, kunt u een kort voorbeeld uitvoeren. In dit voorbeeld wordt ervan uitgegaan dat Azure Databricks en het mmlspark.cognitive pakket zijn. Zie Zoekfunctie toevoegen aan met AI verrijkte gegevens van Apache Spark met behulp van SynapseML voor een voorbeeld.synapseml.cognitive
Eerst kunt u een notebook maken in Azure Databricks. Gebruik voor andere Spark-clusterproviders hun notebooks of Spark Submit.
Maak een nieuw Databricks-notebook door New Notebook te kiezen in het menu Azure Databricks.

Voer in het notitieblok maken een naam in, selecteer Python als taal en selecteer het Spark-cluster dat u eerder hebt gemaakt.
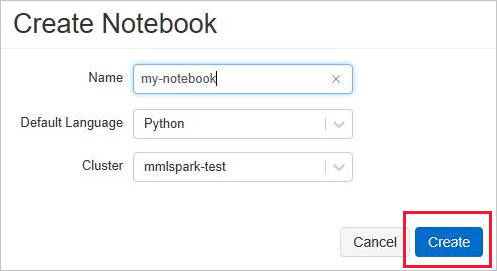
Selecteer Maken.
Plak dit codefragment in uw nieuwe notebook.
from mmlspark.cognitive import * from pyspark.sql.functions import col # Add your region and subscription key from the Language service service_key = "ADD-SUBSCRIPTION-KEY-HERE" service_region = "ADD-SERVICE-REGION-HERE" df = spark.createDataFrame([ ("I am so happy today, its sunny!", "en-US"), ("I am frustrated by this rush hour traffic", "en-US"), ("The Azure AI services on spark aint bad", "en-US"), ], ["text", "language"]) sentiment = (TextSentiment() .setTextCol("text") .setLocation(service_region) .setSubscriptionKey(service_key) .setOutputCol("sentiment") .setErrorCol("error") .setLanguageCol("language")) results = sentiment.transform(df) # Show the results in a table display(results.select("text", col("sentiment")[0].getItem("score").alias("sentiment")))Haal uw regio en abonnementssleutel op uit het menu Sleutels en eindpunt in uw taalresource in Azure Portal.
Vervang de tijdelijke aanduidingen voor regio- en abonnementssleutels in uw Databricks-notebookcode door waarden die geldig zijn voor uw resource.
Selecteer in de rechterbovenhoek van uw notebook-cel het symbool voor afspelen, of de driehoek, om het voorbeeld uit te voeren. U kunt ook Alles uitvoeren selecteren bovenaan uw notebook om alle cellen uit te voeren. De antwoorden worden weergegeven onder de cel in een tabel.
Verwachte resultaten
| sms verzenden | gevoel |
|---|---|
| Ik ben zo blij vandaag, de zon schijnt! | 0,978959 |
| I am frustrated by this rush hour traffic (Ik ben geïrriteerd vanwege het verkeer in de spits) | 0,0237956 |
| De Azure AI-services op spark aint slecht | 0,888896 |