Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure AI Document Intelligence is een Azure AI-service waarmee u geautomatiseerde gegevensverwerkingstoepassing kunt bouwen met behulp van machine learning-technologie. In deze zelfstudie leert u hoe u uw gegevens eenvoudig kunt verrijken in Azure Synapse Analytics. U gebruikt Document intelligence om formulieren en documenten te analyseren, tekst en gegevens te extraheren en een gestructureerde JSON-uitvoer te retourneren. U krijgt snel nauwkeurige resultaten die zijn afgestemd op uw specifieke inhoud zonder overmatige handmatige tussenkomst of uitgebreide expertise op het gebied van data science.
In deze zelfstudie ziet u hoe u Document Intelligence gebruikt met SynapseML om:
- Tekst en indeling extraheren uit een bepaald document
- Gegevens detecteren en extraheren uit ontvangstbevestigingen
- Gegevens detecteren en extraheren uit visitekaartjes
- Gegevens detecteren en extraheren uit facturen
- Gegevens detecteren en extraheren uit identificatiedocumenten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- Azure Synapse Analytics-werkruimte met een Azure Data Lake Storage Gen2-opslagaccount dat is geconfigureerd als de standaardopslag. U moet de bijdrager voor opslagblobgegevens zijn van het Data Lake Storage Gen2-bestandssysteem waarmee u werkt.
- Spark-pool in uw Azure Synapse Analytics-werkruimte. Zie Een Spark-pool maken in Azure Synapse voor meer informatie.
- Vooraf geconfigureerde stappen die worden beschreven in de zelfstudie Azure AI-services configureren in Azure Synapse.
Aan de slag
Open Synapse Studio en maak een nieuw notitieblok. Importeer SynapseML om aan de slag te gaan.
import synapse.ml
from synapse.ml.cognitive import *
Document intelligence configureren
Gebruik de gekoppelde documentinformatie die u hebt geconfigureerd in de stappen vóór de configuratie .
ai_service_name = "<Your linked service for Document Intelligence>"
Indeling analyseren
Tekst- en indelingsgegevens extraheren uit een bepaald document. Het invoerdocument moet van een van de ondersteunde inhoudstypen zijn: 'application/pdf', 'image/jpeg', 'image/png' of 'image/tiff'.
Voorbeeldinvoer

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Verwachte resultaten
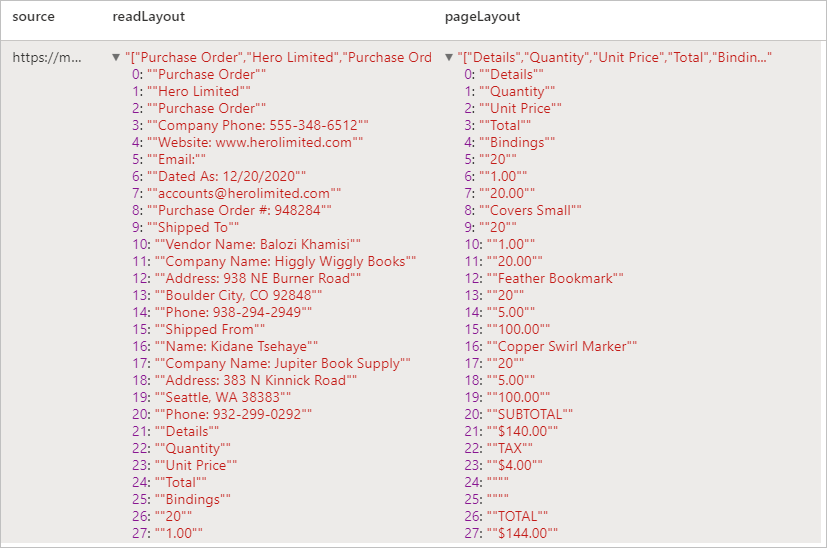
Ontvangstbewijzen analyseren
Detecteert en extraheert gegevens uit ontvangstbevestigingen met behulp van OCR (optical character recognition) en ons ontvangstmodel, zodat u eenvoudig gestructureerde gegevens kunt extraheren uit ontvangstbewijzen zoals de naam van de verkoper, het telefoonnummer van de verkoper, transactiedatum, het transactietotaal en meer.
Voorbeeldinvoer

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Verwachte resultaten
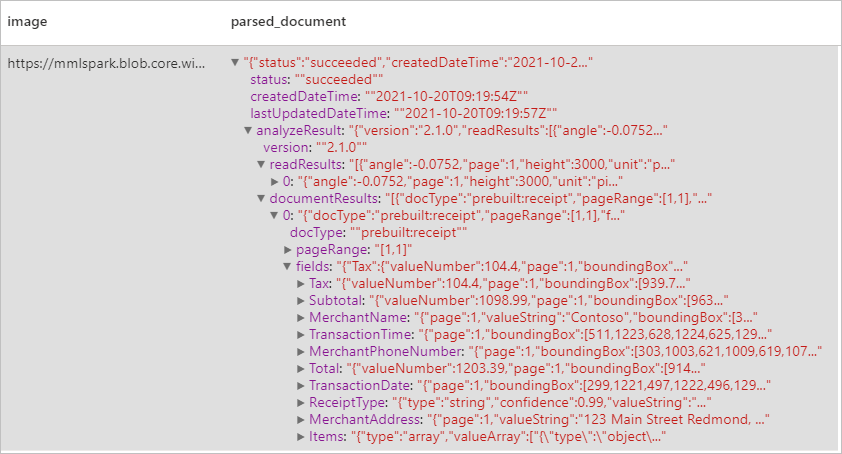
Visitekaartjes analyseren
Detecteert en extraheert gegevens uit visitekaartjes met behulp van optische tekenherkenning (OCR) en ons visitekaartjesmodel, zodat u eenvoudig gestructureerde gegevens kunt extraheren uit visitekaartjes, zoals namen van contactpersonen, bedrijfsnamen, telefoonnummers, e-mailberichten en meer.
Voorbeeldinvoer

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Verwachte resultaten
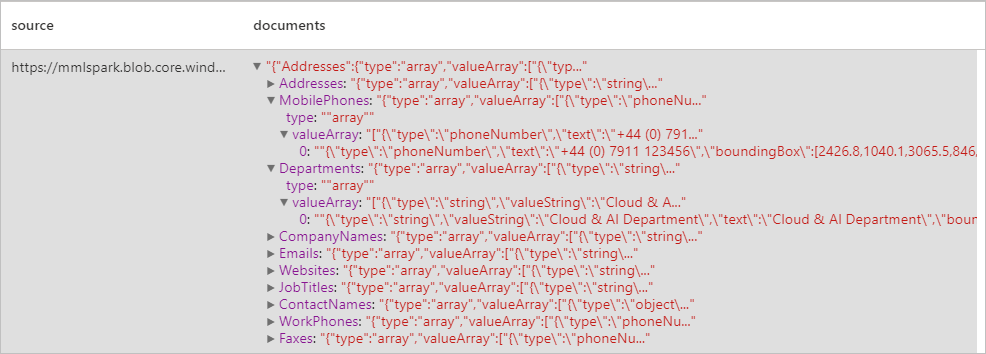
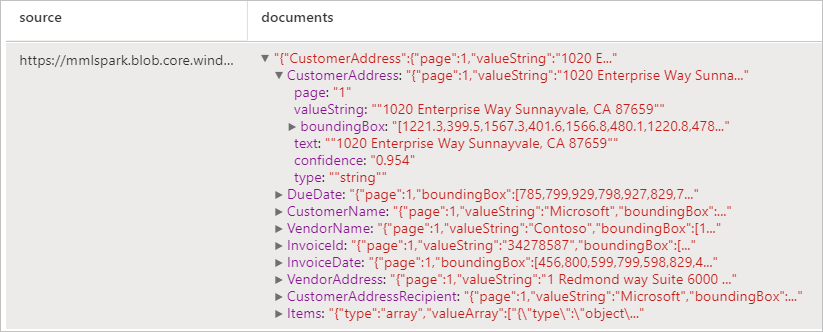
Facturen analyseren
Detecteert en extraheert gegevens uit facturen met optische tekenherkenning (OCR) en onze deep learning-modellen voor factuurbegrip, zodat u eenvoudig gestructureerde gegevens kunt extraheren uit facturen zoals klant, leverancier, factuur-id, factuurdatum, totaal, verschuldigd factuurbedrag, belastingbedrag, verzenden naar, factureren naar, regelitems en meer.
Voorbeeldinvoer
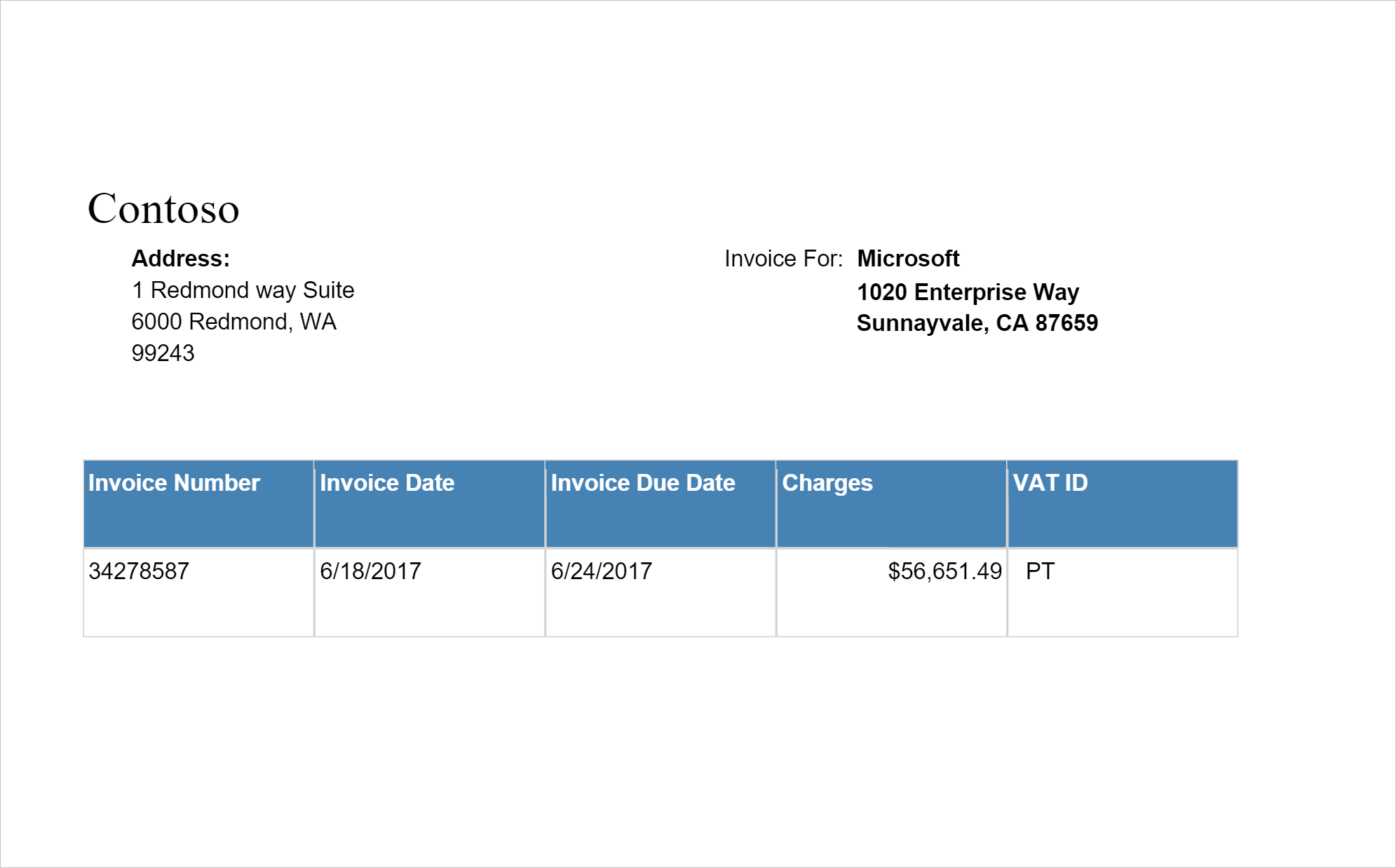
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Verwachte resultaten
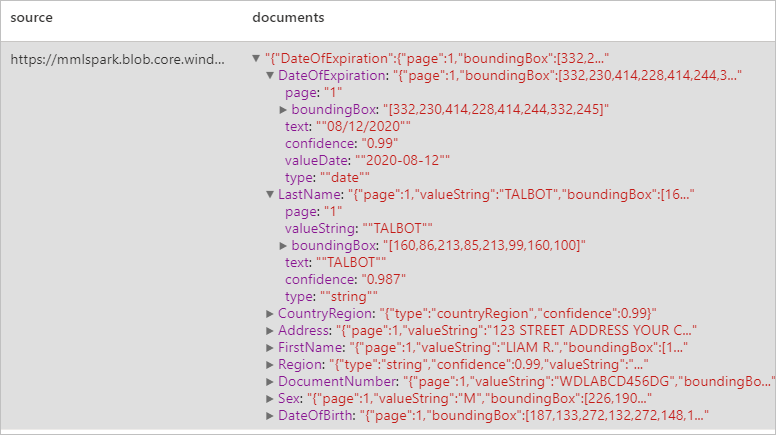
Id-documenten analyseren
Detecteert en extraheert gegevens uit identificatiedocumenten met optische tekenherkenning (OCR) en ons ID-documentmodel, zodat u eenvoudig gestructureerde gegevens kunt extraheren uit id-documenten zoals voornaam, achternaam, geboortedatum, documentnummer en meer.
Voorbeeldinvoer

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Verwachte resultaten
Resources opschonen
Om ervoor te zorgen dat de Spark-instantie wordt afgesloten, beëindigt u alle verbonden sessies (notebooks). De pool wordt afgesloten wanneer de niet-actieve tijd is bereikt die is opgegeven in de Apache Spark-pool. U kunt ook stoppen van de sessie selecteren in de statusbalk rechtsboven in het notitieblok.
