Gegevensmigratie, ETL en laden voor Oracle-migraties
Dit artikel is deel twee van een zevendelige reeks met richtlijnen voor het migreren van Oracle naar Azure Synapse Analytics. De focus van dit artikel ligt op best practices voor ETL en belastingmigratie.
Overwegingen voor gegevensmigratie
Er zijn veel factoren om rekening mee te houden bij het migreren van gegevens, ETL en laden van een verouderd Oracle-datawarehouse en datamarts naar Azure Synapse.
Eerste beslissingen over gegevensmigratie vanuit Oracle
Wanneer u een migratie plant vanuit een bestaande Oracle-omgeving, moet u rekening houden met de volgende gegevensgerelateerde vragen:
Moeten ongebruikte tabelstructuren worden gemigreerd?
Wat is de beste migratiebenadering om risico's en impact voor gebruikers te minimaliseren?
Bij het migreren van datamarts: fysiek blijven of virtueel gaan?
In de volgende secties worden deze punten besproken in de context van een migratie vanuit Oracle.
Ongebruikte tabellen migreren?
Het is zinvol om alleen tabellen te migreren die in gebruik zijn. Tabellen die niet actief zijn, kunnen worden gearchiveerd in plaats van gemigreerd, zodat de gegevens indien nodig in de toekomst beschikbaar zijn. U kunt het beste metagegevens en logboekbestanden van het systeem gebruiken in plaats van documentatie om te bepalen welke tabellen in gebruik zijn, omdat de documentatie verouderd kan zijn.
Oracle-systeemcatalogustabellen en -logboeken bevatten informatie die kan worden gebruikt om te bepalen wanneer een bepaalde tabel voor het laatst is geopend. Deze tabel kan op zijn beurt worden gebruikt om te bepalen of een tabel in aanmerking komt voor migratie.
Als u een licentie voor het Oracle Diagnostic Pack hebt, hebt u toegang tot actieve sessiegeschiedenis, die u kunt gebruiken om te bepalen wanneer een tabel voor het laatst is geopend.
Tip
In oudere systemen is het niet ongebruikelijk dat tabellen na verloop van tijd overbodig worden. Deze hoeven in de meeste gevallen niet te worden gemigreerd.
Hier volgt een voorbeeldquery die zoekt naar het gebruik van een specifieke tabel binnen een bepaald tijdvenster:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
Het uitvoeren van deze query kan enige tijd duren als u meerdere query's hebt uitgevoerd.
Wat is de beste migratiebenadering om risico's en gevolgen voor gebruikers te minimaliseren?
Deze vraag komt vaak naar boven omdat bedrijven mogelijk de impact van wijzigingen op het datawarehouse-gegevensmodel willen verlagen om de flexibiliteit te verbeteren. Bedrijven zien vaak een kans om hun gegevens verder te moderniseren of te transformeren tijdens een ETL-migratie. Deze benadering brengt een hoger risico met zich mee omdat er meerdere factoren tegelijk worden gewijzigd, waardoor het moeilijk is om de resultaten van het oude systeem te vergelijken met het nieuwe. Het aanbrengen van wijzigingen in het gegevensmodel kan ook van invloed zijn op upstream- of downstream ETL-taken naar andere systemen. Vanwege dit risico is het beter om na de datawarehouse-migratie het ontwerp op deze schaal te herontwerpen.
Zelfs als een gegevensmodel opzettelijk wordt gewijzigd als onderdeel van de algehele migratie, is het raadzaam om het bestaande model as-is te migreren naar Azure Synapse, in plaats van het opnieuw te ontwerpen op het nieuwe platform. Deze aanpak minimaliseert het effect op bestaande productiesystemen en profiteert van de prestaties en elastische schaalbaarheid van het Azure-platform voor eenmalige herinrichtingstaken.
Tip
Migreer het bestaande model in eerste instantie ongewijzigd, zelfs als een wijziging in het gegevensmodel in de toekomst is gepland.
Datamartmigratie: fysiek blijven of virtueel gaan?
In verouderde Oracle-datawarehouse-omgevingen is het gebruikelijk om veel datamarts te maken die zijn gestructureerd om goede prestaties te bieden voor ad-hoc selfservicequery's en rapporten voor een bepaalde afdeling of bedrijfsfunctie binnen een organisatie. Een datamart bestaat doorgaans uit een subset van het datawarehouse die geaggregeerde versies van de gegevens bevat in een vorm waarmee gebruikers eenvoudig query's kunnen uitvoeren op die gegevens met snelle reactietijden. Gebruikers kunnen gebruiksvriendelijke queryhulpprogramma's gebruiken, zoals Microsoft Power BI, dat zakelijke gebruikersinteracties met datamarts ondersteunt. De vorm van de gegevens in een datamart is over het algemeen een dimensionale gegevensmodel. Datamarts worden onder andere gebruikt om de gegevens in een bruikbare vorm beschikbaar te maken, zelfs als het onderliggende gegevensmodel van het warehouse iets anders is, zoals een gegevenskluis.
U kunt afzonderlijke datamarts gebruiken voor afzonderlijke bedrijfseenheden binnen een organisatie om robuuste systemen voor gegevensbeveiliging te implementeren. Beperk de toegang tot specifieke datamarts die relevant zijn voor gebruikers en verwijder, verdoezel of anonimiseer gevoelige gegevens.
Als deze datamarts worden geïmplementeerd als fysieke tabellen, hebben ze extra opslagresources en verwerking nodig om ze regelmatig te bouwen en te vernieuwen. Bovendien zijn de gegevens in de mart alleen zo up-to-date als de laatste vernieuwingsbewerking en zijn ze mogelijk niet geschikt voor zeer vluchtige gegevensdashboards.
Tip
Het virtualiseren van datamarts kan besparen op opslag- en verwerkingsresources.
Met de komst van goedkopere schaalbare MPP-architecturen, zoals Azure Synapse, en hun inherente prestatiekenmerken, kunt u datamart-functionaliteit bieden zonder de mart te instantiëren als een set fysieke tabellen. Een methode is om de datamarts effectief te virtualiseren via SQL-weergaven naar het hoofddatawarehouse. Een andere manier is om de datamarts te virtualiseren via een virtualisatielaag met behulp van functies zoals weergaven in Azure of virtualisatieproducten van derden . Deze aanpak vereenvoudigt of elimineert de noodzaak van extra opslag- en aggregatieverwerking en vermindert het totale aantal databaseobjecten dat moet worden gemigreerd.
Er is nog een potentieel voordeel van deze aanpak. Door de aggregatie- en joinlogica binnen een virtualisatielaag te implementeren en hulpprogramma's voor externe rapportage te presenteren via een gevirtualiseerde weergave, wordt de verwerking die nodig is om deze weergaven te maken, naar het datawarehouse gepusht. Het datawarehouse is over het algemeen de beste plek om joins, aggregaties en andere gerelateerde bewerkingen uit te voeren op grote gegevensvolumes.
De belangrijkste drivers voor het implementeren van een virtuele datamart via een fysieke datamart zijn:
Meer flexibiliteit: een virtuele datamart is eenvoudiger te wijzigen dan fysieke tabellen en de bijbehorende ETL-processen.
Lagere totale eigendomskosten: een gevirtualiseerde implementatie vereist minder gegevensarchieven en kopieën van gegevens.
Afschaffing van ETL-taken voor het migreren en vereenvoudigen van de datawarehouse-architectuur in een gevirtualiseerde omgeving.
Prestaties: hoewel fysieke datamarts in het verleden beter presteerden, implementeren virtualisatieproducten nu intelligente cachingtechnieken om dit verschil te beperken.
Tip
De prestaties en schaalbaarheid van Azure Synapse maken virtualisatie mogelijk zonder dat dit ten koste gaat van de prestaties.
Gegevensmigratie vanuit Oracle
Inzicht in uw gegevens
Als onderdeel van de migratieplanning moet u in detail begrijpen hoeveel gegevens moeten worden gemigreerd, omdat dit van invloed kan zijn op beslissingen over de migratiebenadering. Gebruik systeemmetagegevens om de fysieke ruimte te bepalen die in beslag wordt genomen door de onbewerkte gegevens in de tabellen die moeten worden gemigreerd. In deze context betekent onbewerkte gegevens de hoeveelheid ruimte die wordt gebruikt door de gegevensrijen in een tabel, exclusief overhead zoals indexen en compressie. De grootste feitentabellen bevatten doorgaans meer dan 95% van de gegevens.
Deze query geeft u de totale databasegrootte in Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
De databasegrootte is gelijk aan de grootte van (data files + temp files + online/offline redo log files + control files). De totale grootte van de database omvat gebruikte ruimte en vrije ruimte.
De volgende voorbeeldquery geeft een uitsplitsing van de schijfruimte die wordt gebruikt door tabelgegevens en indexen:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Daarnaast biedt het Microsoft-databasemigratieteam veel resources, waaronder de Oracle Inventory Script Artifacts. Het hulpprogramma Oracle Inventory Script Artifacts bevat een PL/SQL-query die toegang heeft tot Oracle-systeemtabellen en een telling van objecten biedt op schematype, objecttype en status. Het hulpprogramma biedt ook een ruwe schatting van onbewerkte gegevens in elk schema en de grootte van tabellen in elk schema, waarbij de resultaten worden opgeslagen in een CSV-indeling. Een inbegrepen rekenmachine-spreadsheet gebruikt de CSV als invoer en biedt groottegegevens.
Voor elke tabel kunt u een nauwkeurige schatting maken van de hoeveelheid gegevens die moet worden gemigreerd door een representatieve steekproef van de gegevens, zoals een miljoen rijen, te extraheren naar een niet-gecomprimeerd, met scheidingsteken gescheiden ASCII-gegevensbestand. Gebruik vervolgens de grootte van dat bestand om een gemiddelde onbewerkte gegevensgrootte per rij op te halen. Vermenigvuldig ten slotte die gemiddelde grootte met het totale aantal rijen in de volledige tabel om een onbewerkte gegevensgrootte voor de tabel te geven. Gebruik die onbewerkte gegevensgrootte in uw planning.
SQL-query's gebruiken om gegevenstypen te zoeken
Door een query uit te voeren op de statische oracle-gegevenswoordenlijstweergave DBA_TAB_COLUMNS , kunt u bepalen welke gegevenstypen in een schema worden gebruikt en of een van deze gegevenstypen moet worden gewijzigd. Gebruik SQL-query's om de kolommen in een Oracle-schema te vinden met gegevenstypen die niet rechtstreeks zijn toegewezen aan gegevenstypen in Azure Synapse. Op dezelfde manier kunt u query's gebruiken om het aantal exemplaren te tellen van elk Oracle-gegevenstype dat niet rechtstreeks aan Azure Synapse is toegewezen. Door de resultaten van deze query's te gebruiken in combinatie met de vergelijkingstabel voor gegevenstypen, kunt u bepalen welke gegevenstypen moeten worden gewijzigd in een Azure Synapse omgeving.
Als u de kolommen met gegevenstypen wilt vinden die niet zijn toegewezen aan gegevenstypen in Azure Synapse, voert u de volgende query uit nadat u hebt vervangen door <owner_name> de relevante eigenaar van uw schema:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Gebruik de volgende query om het aantal niet-toe te wijzen gegevenstypen te tellen:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft biedt SQL Server Migration Assistant (SSMA) voor Oracle om de migratie van datawarehouses vanuit verouderde Oracle-omgevingen te automatiseren, inclusief het toewijzen van gegevenstypen. U kunt ook Azure Database Migration Services gebruiken om een migratie te plannen en uit te voeren vanuit omgevingen zoals Oracle. Externe leveranciers bieden ook hulpprogramma's en services voor het automatiseren van migratie. Als een ETL-hulpprogramma van derden al in gebruik is in de Oracle-omgeving , kunt u dat hulpprogramma gebruiken om vereiste gegevenstransformaties te implementeren. In de volgende sectie wordt de migratie van bestaande ETL-processen besproken.
Overwegingen voor ETL-migratie
Eerste beslissingen over Oracle ETL-migratie
Voor ETL-/ ELT-verwerking maken verouderde Oracle-datawarehouses vaak gebruik van aangepaste scripts, ETL-hulpprogramma's van derden of een combinatie van benaderingen die in de loop van de tijd zijn ontwikkeld. Wanneer u een migratie naar Azure Synapse plant, bepaalt u de beste manier om de vereiste ETL/ELT-verwerking in de nieuwe omgeving te implementeren en tegelijkertijd kosten en risico's te minimaliseren.
Tip
Plan de aanpak van ETL-migratie van tevoren en maak waar nodig gebruik van Azure-faciliteiten.
In het volgende stroomdiagram wordt één benadering samengevat:
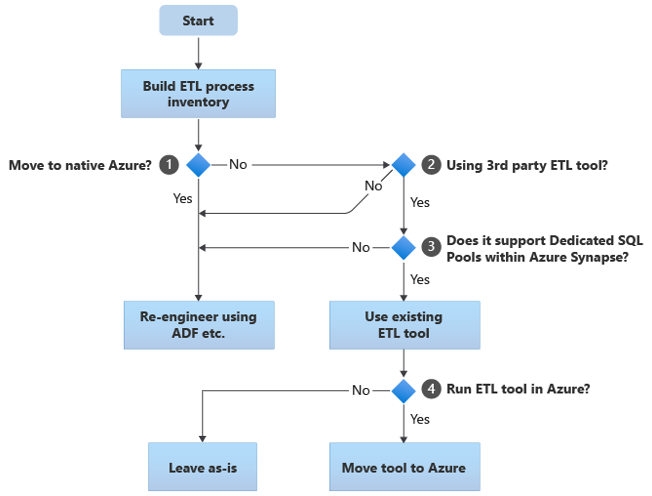
Zoals wordt weergegeven in het stroomdiagram, bestaat de eerste stap altijd uit het samenstellen van een inventaris van ETL-/ELT-processen die moeten worden gemigreerd. Met de standaard ingebouwde Azure-functies hoeven sommige bestaande processen mogelijk niet te worden verplaatst. Voor planningsdoeleinden is het belangrijk dat u de schaal van de migratie begrijpt. Bekijk vervolgens de vragen in de beslissingsstructuur van het stroomdiagram:
Wilt u overstappen op systeemeigen Azure? Uw antwoord is afhankelijk van of u migreert naar een volledig azure-systeemeigen omgeving. Als dat zo is, raden we u aan de ETL-verwerking opnieuw te ontwerpen met behulp van pijplijnen en activiteiten in Azure Data Factory- of Azure Synapse-pijplijnen.
Gebruikt u een ETL-hulpprogramma van derden? Als u niet overstapt op een volledig systeemeigen Azure-omgeving, controleert u of er al een bestaand ETL-hulpprogramma van derden in gebruik is. In de Oracle-omgeving kan het zijn dat sommige of alle ETL-verwerkingen worden uitgevoerd door aangepaste scripts die gebruikmaken van Oracle-specifieke hulpprogramma's, zoals Oracle SQL Developer, Oracle SQL*Loader of Oracle Data Pump. De aanpak in dit geval is om opnieuw te engineeren met behulp van Azure Data Factory.
Ondersteunen de derden toegewezen SQL-pools binnen Azure Synapse? Overweeg of er veel wordt geïnvesteerd in vaardigheden in het ETL-hulpprogramma van derden, of dat bestaande werkstromen en planningen dat hulpprogramma gebruiken. Als dat het zo is, bepaalt u of het hulpprogramma Azure Synapse als doelomgeving efficiënt kan ondersteunen. Idealiter bevat het hulpprogramma systeemeigen connectors die azure-faciliteiten zoals PolyBase of COPY INTO kunnen gebruiken voor het efficiënt laden van gegevens. Maar zelfs zonder systeemeigen connectors is er over het algemeen een manier om externe processen aan te roepen, zoals PolyBase of
COPY INTO, en toepasselijke parameters door te geven. Gebruik in dit geval bestaande vaardigheden en werkstromen, met Azure Synapse als de nieuwe doelomgeving.Als u Oracle Data Integrator (ODI) gebruikt voor ELT-verwerking, hebt u ODI-kennismodules nodig voor Azure Synapse. Als deze modules niet beschikbaar zijn in uw organisatie, maar u wel ODI hebt, kunt u ODI gebruiken om platte bestanden te genereren. Deze platte bestanden kunnen vervolgens worden verplaatst naar Azure en worden opgenomen in Azure Data Lake Storage voor het laden in Azure Synapse.
ETL-hulpprogramma's uitvoeren in Azure? Als u besluit een bestaand ETL-hulpprogramma van derden te behouden, kunt u dat hulpprogramma uitvoeren in de Azure-omgeving (in plaats van op een bestaande on-premises ETL-server) en data factory de algehele indeling van de bestaande werkstromen laten afhandelen. Beslis daarom of u het bestaande hulpprogramma in de huidige staat wilt laten uitvoeren of het naar de Azure-omgeving wilt verplaatsen om kosten-, prestatie- en schaalbaarheidsvoordelen te behalen.
Tip
Overweeg etl-hulpprogramma's in Azure uit te voeren om gebruik te maken van prestaties, schaalbaarheid en kostenvoordelen.
Bestaande Oracle-specifieke scripts opnieuw ontwerpen
Als sommige of alle bestaande ETL/ELT-verwerkingen van Oracle-magazijnen worden verwerkt door aangepaste scripts die gebruikmaken van Oracle-specifieke hulpprogramma's, zoals Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader of Oracle Data Pump, moet u deze scripts opnieuw coderen voor de Azure Synapse omgeving. En als ETL-processen zijn geïmplementeerd met behulp van opgeslagen procedures in Oracle, moet u deze processen opnieuw coderen.
Sommige elementen van het ETL-proces zijn eenvoudig te migreren, bijvoorbeeld door eenvoudig gegevens bulksgewijs vanuit een extern bestand in een faseringstabel te laden. Het kan zelfs mogelijk zijn om deze onderdelen van het proces te automatiseren, bijvoorbeeld met behulp van Azure Synapse COPY INTO of PolyBase in plaats van SQL*Loader. Andere onderdelen van het proces die willekeurige complexe SQL- en/of opgeslagen procedures bevatten, nemen meer tijd in beslag om opnieuw te ontwerpen.
Tip
De inventaris van ETL-taken die moeten worden gemigreerd, moet scripts en opgeslagen procedures bevatten.
Een manier om Oracle SQL te testen op compatibiliteit met Azure Synapse is door een aantal representatieve SQL-instructies uit een join van Oracle v$active_session_history vast te leggen en v$sql op te halen sql_texten deze query's vervolgens vooraf te laten gaan door EXPLAIN. Uitgaande van een gelijkgestemd gemigreerd gegevensmodel in Azure Synapse, voert u deze EXPLAIN instructies uit in Azure Synapse. Elke incompatibele SQL geeft een fout. U kunt deze informatie gebruiken om de schaal van de heroderende taak te bepalen.
Tip
Gebruik EXPLAIN om te zoeken naar incompatibiliteit van SQL.
In het ergste geval kan handmatig opnieuw worden genummerd. Er zijn echter producten en services beschikbaar van Microsoft-partners om te helpen bij het opnieuw ontwerpen van Oracle-specifieke code.
Tip
Partners bieden producten en vaardigheden om te helpen bij het opnieuw ontwikkelen van Oracle-specifieke code.
Bestaande ETL-hulpprogramma's van derden gebruiken
In veel gevallen wordt het bestaande verouderde datawarehousesysteem al ingevuld en onderhouden door een ETL-product van derden. Zie Azure Synapse Analytics-gegevensintegratiepartners voor een lijst met huidige Microsoft-gegevensintegratiepartners voor Azure Synapse.
De Oracle-community maakt vaak gebruik van verschillende populaire ETL-producten. In de volgende alinea's worden de populairste ETL-hulpprogramma's voor Oracle-magazijnen besproken. U kunt al deze producten uitvoeren op een VM in Azure en ze gebruiken om Azure-databases en -bestanden te lezen en te schrijven.
Tip
Maak gebruik van investeringen in bestaande hulpprogramma's van derden om kosten en risico's te verminderen.
Gegevens laden vanuit Oracle
Beschikbare opties bij het laden van gegevens uit Oracle
Wanneer u zich voorbereidt op het migreren van gegevens vanuit een Oracle-datawarehouse, bepaalt u hoe gegevens fysiek worden verplaatst van de bestaande on-premises omgeving naar Azure Synapse in de cloud en welke hulpprogramma's worden gebruikt om de overdracht en het laden uit te voeren. Houd rekening met de volgende vragen, die in de volgende secties worden besproken.
Extraheert u de gegevens naar bestanden of verplaatst u deze rechtstreeks via een netwerkverbinding?
Organiseert u het proces vanuit het bronsysteem of vanuit de Azure-doelomgeving?
Welke hulpprogramma's gebruikt u om het migratieproces te automatiseren en te beheren?
Gegevens overdragen via bestanden of een netwerkverbinding?
Zodra de databasetabellen die moeten worden gemigreerd, zijn gemaakt in Azure Synapse, kunt u de gegevens die deze tabellen vullen, vanuit het verouderde Oracle-systeem verplaatsen naar de nieuwe omgeving. Er zijn twee basismethoden:
Bestandsuitpakken: pak de gegevens uit de Oracle-tabellen uit naar bestanden met platte scheidingstekens, normaal gesproken in CSV-indeling. U kunt tabelgegevens op verschillende manieren extraheren:
- Gebruik standaard Oracle-hulpprogramma's zoals SQL*Plus, SQL Developer en SQLcl.
- Gebruik Oracle Data Integrator (ODI) om platte bestanden te genereren.
- Gebruik de Oracle-connector in Data Factory om Oracle-tabellen parallel te verwijderen om het laden van gegevens door partities mogelijk te maken.
- Gebruik een ETL-hulpprogramma van derden .
Zie de bijlage bij het artikel voor voorbeelden van het extraheren van Oracle-tabelgegevens.
Deze benadering vereist ruimte om de geëxtraheerde gegevensbestanden te landen. De ruimte kan lokaal zijn in de Oracle-brondatabase als er voldoende opslagruimte beschikbaar is, of extern in Azure Blob Storage. De beste prestaties worden bereikt wanneer een bestand lokaal wordt geschreven, omdat dit netwerkoverhead voorkomt.
Om de vereisten voor opslag en netwerkoverdracht te minimaliseren, comprimeert u de geëxtraheerde gegevensbestanden met behulp van een hulpprogramma zoals gzip.
Verplaats de platte bestanden na extractie naar Azure Blob Storage. Microsoft biedt verschillende opties voor het verplaatsen van grote hoeveelheden gegevens, waaronder:
- AzCopy voor het verplaatsen van bestanden via het netwerk naar Azure Storage.
- Azure ExpressRoute voor het verplaatsen van bulkgegevens via een particuliere netwerkverbinding.
- Azure Data Box voor het verplaatsen van bestanden naar een fysiek opslagapparaat dat u naar een Azure-datacenter verzendt om deze te laden.
Zie Gegevens overdragen van en naar Azure voor meer informatie.
Direct extraheren en laden via het netwerk: de Azure-doelomgeving verzendt een aanvraag voor gegevensextractatie, normaal gesproken via een SQL-opdracht, naar het verouderde Oracle-systeem om de gegevens te extraheren. De resultaten worden via het netwerk verzonden en rechtstreeks in Azure Synapse geladen, zonder dat u de gegevens in tussenliggende bestanden hoeft te plaatsen. De beperkende factor in dit scenario is normaal gesproken de bandbreedte van de netwerkverbinding tussen de Oracle-database en de Azure-omgeving. Voor uitzonderlijk grote gegevensvolumes is deze aanpak mogelijk niet praktisch.
Tip
Inzicht in de gegevensvolumes die moeten worden gemigreerd en de beschikbare netwerkbandbreedte, omdat deze factoren van invloed zijn op de beslissing over de migratiebenadering.
Er is ook een hybride benadering waarbij beide methoden worden gebruikt. U kunt bijvoorbeeld de methode voor directe netwerkextracting gebruiken voor kleinere dimensietabellen en voorbeelden van de grotere feitentabellen om snel een testomgeving te bieden in Azure Synapse. Voor historische feitentabellen met grote volumes kunt u de methode voor het uitpakken en overdragen van bestanden gebruiken met behulp van Azure Data Box.
Wilt u een indeling maken vanuit Oracle of Azure?
De aanbevolen aanpak bij het overstappen op Azure Synapse is het extraheren en laden van gegevens uit de Azure-omgeving met behulp van SSMA of Data Factory. Gebruik de bijbehorende hulpprogramma's, zoals PolyBase of COPY INTO, voor het efficiënt laden van gegevens. Deze aanpak profiteert van ingebouwde Azure-mogelijkheden en vermindert de inspanning om herbruikbare pijplijnen voor gegevensbelasting te bouwen. U kunt pijplijnen voor het laden van metagegevens gebruiken om het migratieproces te automatiseren.
De aanbevolen aanpak minimaliseert ook de prestatietreffer in de bestaande Oracle-omgeving tijdens het laden van gegevens, omdat het beheer- en laadproces wordt uitgevoerd in Azure.
Bestaande hulpprogramma's voor gegevensmigratie
Gegevenstransformatie en -verplaatsing is de basisfunctie van alle ETL-producten. Als een hulpprogramma voor gegevensmigratie al in gebruik is in de bestaande Oracle-omgeving en Azure Synapse als doelomgeving ondersteunt, kunt u overwegen om dat hulpprogramma te gebruiken om gegevensmigratie te vereenvoudigen.
Zelfs als er geen bestaand ETL-hulpprogramma bestaat, bieden Azure Synapse Analytics-partners voor gegevensintegratie ETL-hulpprogramma's om de taak van gegevensmigratie te vereenvoudigen.
Als u ten slotte een ETL-hulpprogramma wilt gebruiken, kunt u overwegen om dat hulpprogramma in de Azure-omgeving uit te voeren om te profiteren van azure-cloudprestaties, schaalbaarheid en kosten. Met deze aanpak worden ook resources vrijgemaakt in het Oracle-datacenter.
Samenvatting
Samenvattend zijn onze aanbevelingen voor het migreren van gegevens en bijbehorende ETL-processen van Oracle naar Azure Synapse:
Plan vooraf om een geslaagde migratie te garanderen.
Stel zo snel mogelijk een gedetailleerde inventaris op van gegevens en processen die moeten worden gemigreerd.
Gebruik systeemmetagegevens en logboekbestanden om een nauwkeurig inzicht te krijgen in het gebruik van gegevens en processen. Vertrouw niet op documentatie, omdat deze mogelijk verouderd is.
Inzicht in de gegevensvolumes die moeten worden gemigreerd en de netwerkbandbreedte tussen het on-premises datacenter en Azure-cloudomgevingen.
Overweeg het gebruik van een Oracle-exemplaar in een Virtuele Azure-machine als opstap voor het offloaden van migratie vanuit de verouderde Oracle-omgeving.
Gebruik standaard ingebouwde Azure-functies om de migratieworkload te minimaliseren.
Identificeer en begrijp de meest efficiënte hulpprogramma's voor het extraheren en laden van gegevens in zowel Oracle- als Azure-omgevingen. Gebruik de juiste hulpprogramma's in elke fase van het proces.
Gebruik Azure-faciliteiten, zoals Data Factory, om het migratieproces te organiseren en te automatiseren terwijl de impact op het Oracle-systeem wordt geminimaliseerd.
Bijlage: Voorbeelden van technieken voor het extraheren van Oracle-gegevens
U kunt verschillende technieken gebruiken om Oracle-gegevens te extraheren wanneer u van Oracle naar Azure Synapse migreert. In de volgende secties ziet u hoe u Oracle-gegevens kunt extraheren met oracle SQL Developer en de Oracle-connector in Data Factory.
Oracle SQL Developer gebruiken voor gegevensextractie
U kunt de Oracle SQL Developer-gebruikersinterface gebruiken om tabelgegevens te exporteren naar een groot aantal indelingen, waaronder CSV, zoals wordt weergegeven in de volgende schermafbeelding:

Andere exportopties zijn JSON en XML. U kunt de gebruikersinterface gebruiken om een set tabelnamen toe te voegen aan een 'winkelwagen' en vervolgens de export toepassen op de hele set in de winkelwagen:

U kunt ook Oracle SQL Developer Command Line (SQLcl) gebruiken om Oracle-gegevens te exporteren. Deze optie ondersteunt automatisering met behulp van een shellscript.
Voor relatief kleine tabellen kan deze techniek handig zijn als u problemen ondervindt bij het extraheren van gegevens via een directe verbinding.
De Oracle-connector in Azure Data Factory gebruiken voor parallel kopiëren
U kunt de Oracle-connector in Data Factory gebruiken om grote Oracle-tabellen parallel te verwijderen. De Oracle-connector biedt ingebouwde gegevenspartitionering om gegevens parallel uit Oracle te kopiëren. U vindt de opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.

Zie Parallel kopiëren vanuit Oracle voor informatie over het configureren van de Oracle-connector voor parallel kopiëren.
Zie de handleiding Copy-activiteit prestaties en schaalbaarheid voor meer informatie over de prestaties en schaalbaarheid van data factory-kopieeractiviteiten.
Volgende stappen
Zie het volgende artikel in deze reeks voor meer informatie over beveiligingstoegangsbewerkingen: Beveiliging, toegang en bewerkingen voor Oracle-migraties.