Naast Oracle-migratie implementeert u een modern datawarehouse in Microsoft Azure
Dit artikel is deel zeven van een zevendelige reeks met richtlijnen voor het migreren van Oracle naar Azure Synapse Analytics. De focus van dit artikel ligt op best practices voor het implementeren van moderne datawarehouses.
Meer dan datawarehouse-migratie naar Azure
Een belangrijke reden om uw bestaande datawarehouse te migreren naar Azure Synapse Analytics is het gebruik van een wereldwijd veilige, schaalbare, goedkope, cloudeigen analytische database met betalen per gebruik. Met Azure Synapse kunt u uw gemigreerde datawarehouse integreren met het volledige analytische ecosysteem van Microsoft Azure om te profiteren van andere Microsoft-technologieën en uw gemigreerde datawarehouse te moderniseren. Deze technologieën omvatten:
Azure Data Lake Storage voor kosteneffectieve gegevensopname, fasering, opschoning en transformatie. Data Lake Storage kunt de datawarehousecapaciteit vrijmaken die wordt ingenomen door snel groeiende faseringstabellen.
Azure Data Factory voor gezamenlijke IT- en selfservicegegevensintegratie met connectors voor cloud- en on-premises gegevensbronnen en streaminggegevens.
Common Data Model voor het delen van consistente vertrouwde gegevens in meerdere technologieën, waaronder:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Microsoft ISV-partners
Microsoft data science-technologieën, waaronder:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark as a Service)
- Jupyter Notebooks
- RStudio
- ML.NET
- .NET voor Apache Spark, waarmee gegevenswetenschappers Azure Synapse gegevens kunnen gebruiken om machine learning-modellen op schaal te trainen.
Azure HDInsight voor het verwerken van grote hoeveelheden gegevens en het samenvoegen van big data met Azure Synapse gegevens door een logisch datawarehouse te maken met PolyBase.
Azure Event Hubs, Azure Stream Analytics en Apache Kafka om live streaminggegevens van Azure Synapse te integreren.
De groei van big data heeft geleid tot een acute vraag naar machine learning om aangepaste, getrainde machine learning-modellen mogelijk te maken voor gebruik in Azure Synapse. Met machine learning-modellen kunnen analyses in databases op schaal in batch, op gebeurtenisgestuurde basis en op aanvraag worden uitgevoerd. De mogelijkheid om te profiteren van in-database analytics in Azure Synapse van meerdere BI-hulpprogramma's en toepassingen garandeert ook consistente voorspellingen en aanbevelingen.
Daarnaast kunt u Azure Synapse integreren met hulpprogramma's van Microsoft-partners in Azure om de time-to-value te verkorten.
Laten we eens kijken hoe u kunt profiteren van technologieën in het analytische ecosysteem van Microsoft om uw datawarehouse te moderniseren nadat u naar Azure Synapse bent gemigreerd.
Offloaden van gegevensfasering en ETL-verwerking naar Data Lake Storage en Data Factory
Digitale transformatie heeft een belangrijke uitdaging voor ondernemingen gecreëerd door het genereren van een stortvloed aan nieuwe gegevens voor vastleggen en analyseren. Een goed voorbeeld zijn transactiegegevens die zijn gemaakt door OLTP-systemen (Online Transactional Processing) te openen voor toegang vanaf mobiele apparaten. Veel van deze gegevens vinden hun weg naar datawarehouses en OLTP-systemen zijn de belangrijkste bron. Nu klanten de transactiesnelheid bepalen in plaats van werknemers, neemt het volume van gegevens in faseringstabellen van datawarehouses snel toe.
Met de snelle toestroom van gegevens in de onderneming, samen met nieuwe gegevensbronnen zoals Internet of Things (IoT), moeten bedrijven manieren vinden om etl-verwerking van gegevensintegratie op te schalen. Een methode is het offloaden van opname, gegevensopschoning, transformatie en integratie met een data lake en daar gegevens op schaal te verwerken, als onderdeel van een datawarehouse-moderniseringsprogramma.
Zodra u uw datawarehouse naar Azure Synapse hebt gemigreerd, kan Microsoft uw ETL-verwerking moderniseren door gegevens op te nemen en te faseren in Data Lake Storage. Vervolgens kunt u uw gegevens op schaal opschonen, transformeren en integreren met behulp van Data Factory voordat u ze parallel in Azure Synapse laadt met PolyBase.
Voor ELT-strategieën kunt u overwegen om ELT-verwerking te offloaden naar Data Lake Storage om eenvoudig te schalen naarmate uw gegevensvolume of frequentie toeneemt.
Microsoft Azure Data Factory
Azure Data Factory is een hybride gegevensintegratieservice voor betalen per gebruik voor zeer schaalbare ETL- en ELT-verwerking. Data Factory biedt een webinterface voor het bouwen van pijplijnen voor gegevensintegratie zonder code. Met Data Factory kunt u het volgende doen:
Bouw schaalbare pijplijnen voor gegevensintegratie zonder code.
Eenvoudig gegevens op schaal verkrijgen.
Alleen betalen voor wat u gebruikt.
Verbinding maken met on-premises, cloud- en SaaS-gegevensbronnen.
Gegevens in de cloud en on-premises op schaal opnemen, verplaatsen, opschonen, transformeren, integreren en analyseren.
Naadloos pijplijnen ontwerpen, bewaken en beheren die zowel on-premises als in de cloud gegevensarchieven omvatten.
Uitschalen van betalen per gebruik inschakelen in overeenstemming met de groei van klanten.
U kunt deze functies gebruiken zonder code te schrijven, of u kunt aangepaste code toevoegen aan Data Factory-pijplijnen. In de volgende schermopname ziet u een voorbeeld van een Data Factory-pijplijn.

Tip
Met Data Factory kunt u schaalbare pijplijnen voor gegevensintegratie bouwen zonder code.
Implementeer data factory-pijplijnontwikkeling vanaf verschillende locaties, waaronder:
Microsoft Azure Portal.
Microsoft Azure PowerShell.
Programmatisch vanuit .NET en Python met behulp van een SDK voor meerdere talen.
Arm-sjablonen (Azure Resource Manager).
REST API's.
Tip
Data Factory kan verbinding maken met on-premises, cloud- en SaaS-gegevens.
Ontwikkelaars en gegevenswetenschappers die liever code schrijven, kunnen eenvoudig Data Factory-pijplijnen maken in Java, Python en .NET met behulp van de SDK's (Software Development Kits) die beschikbaar zijn voor deze programmeertalen. Data Factory-pijplijnen kunnen hybride gegevenspijplijnen zijn omdat ze verbinding kunnen maken, opnemen, opschonen, transformeren en analyseren in on-premises datacenters, Microsoft Azure, andere clouds en SaaS-aanbiedingen.
Nadat u Data Factory-pijplijnen hebt ontwikkeld voor het integreren en analyseren van gegevens, kunt u deze pijplijnen wereldwijd implementeren en plannen dat ze in batch worden uitgevoerd, ze op aanvraag als een service aanroepen of in realtime uitvoeren op gebeurtenisgestuurde basis. Een Data Factory-pijplijn kan ook worden uitgevoerd op een of meer uitvoeringsengines en de uitvoering bewaken om de prestaties te garanderen en fouten bij te houden.
Tip
In Azure Data Factory regelen pijplijnen de integratie en analyse van gegevens. Data Factory is hoogwaardige software voor gegevensintegratie gericht op IT-professionals en heeft mogelijkheden voor het wrangling van gegevens voor zakelijke gebruikers.
Gebruiksvoorbeelden
Data Factory ondersteunt meerdere gebruiksvoorbeelden, zoals:
Gegevens uit gegevensbronnen in de cloud en on-premises voorbereiden, integreren en verrijken om uw gemigreerde datawarehouse en datamarts op Microsoft Azure Synapse te vullen.
Gegevens uit gegevensbronnen in de cloud en on-premises voorbereiden, integreren en verrijken om trainingsgegevens te produceren voor gebruik bij de ontwikkeling van machine learning-modellen en bij het opnieuw trainen van analytische modellen.
Orcheer gegevensvoorbereiding en -analyse om voorspellende en prescriptieve analytische pijplijnen te maken voor het verwerken en analyseren van gegevens in batch, zoals sentimentanalyses. Reageer op de resultaten van de analyse of vul uw datawarehouse met de resultaten.
Gegevens voorbereiden, integreren en verrijken voor gegevensgestuurde bedrijfstoepassingen die worden uitgevoerd in de Azure-cloud op operationele gegevensarchieven zoals Azure Cosmos DB.
Tip
Bouw trainingsgegevenssets in gegevenswetenschap om machine learning-modellen te ontwikkelen.
Gegevensbronnen
Met Data Factory kunt u connectors gebruiken uit zowel cloud- als on-premises gegevensbronnen. Agentsoftware, ook wel een zelf-hostende Integration Runtime genoemd, heeft veilig toegang tot on-premises gegevensbronnen en biedt ondersteuning voor veilige, schaalbare gegevensoverdracht.
Gegevens transformeren met behulp van Azure Data Factory
Binnen een Data Factory-pijplijn kunt u elk type gegevens uit deze bronnen opnemen, opschonen, transformeren, integreren en analyseren. Gegevens kunnen gestructureerd, semi-gestructureerd zijn, zoals JSON of Avro, of ongestructureerd.
Zonder code te schrijven, kunnen professionele ETL-ontwikkelaars Data Factory-toewijzingsgegevensstromen gebruiken om gegevens te filteren, splitsen, samenvoegen, opzoeken, draaien, draaien, depivot opheffen, sorteren, samenvoegen en aggregeren. Daarnaast ondersteunt Data Factory surrogaatsleutels, meerdere opties voor schrijfverwerking, zoals invoegen, upsert, bijwerken, tabelrecreatie en tabelafkapping, en verschillende typen doelgegevensarchieven, ook wel sinks genoemd. ETL-ontwikkelaars kunnen ook aggregaties maken, waaronder tijdreeksaggregaties waarvoor een venster moet worden geplaatst op gegevenskolommen.
Tip
Professionele ETL-ontwikkelaars kunnen Data Factory-toewijzingsgegevensstromen gebruiken om gegevens op te schonen, te transformeren en te integreren zonder code te hoeven schrijven.
U kunt toewijzingsgegevensstromen uitvoeren die gegevens transformeren als activiteiten in een Data Factory-pijplijn. Indien nodig kunt u meerdere toewijzingsgegevensstromen in één pijplijn opnemen. Op deze manier kunt u de complexiteit beheren door uitdagende gegevenstransformatie- en integratietaken op te delen in kleinere toewijzingsgegevensstromen die kunnen worden gecombineerd. En u kunt aangepaste code toevoegen wanneer dat nodig is. Naast deze functionaliteit bieden data factory-toewijzingsgegevensstromen de mogelijkheid om het volgende te doen:
Definieer expressies om gegevens op te schonen en te transformeren, aggregaties te berekenen en gegevens te verrijken. Met deze expressies kunt u bijvoorbeeld functie-engineering uitvoeren op een datumveld om het veld op te splitsen in meerdere velden om trainingsgegevens te maken tijdens de ontwikkeling van het machine learning-model. U kunt expressies maken op basis van een uitgebreide set functies, waaronder wiskundige, tijdelijke functies, splitsen, samenvoegen van tekenreeksen, voorwaarden, patroonovereenkomst, vervangen en vele andere functies.
Schemadrift automatisch verwerken, zodat pijplijnen voor gegevenstransformatie kunnen voorkomen dat ze worden beïnvloed door schemawijzigingen in gegevensbronnen. Deze mogelijkheid is met name belangrijk voor het streamen van IoT-gegevens, waarbij schemawijzigingen zonder kennisgeving kunnen plaatsvinden als apparaten worden bijgewerkt of wanneer metingen worden gemist door gatewayapparaten die IoT-gegevens verzamelen.
Partitioneer gegevens om transformaties parallel op schaal uit te voeren.
Controleer streaminggegevens om de metagegevens weer te geven van een stroom die u wilt transformeren.
Tip
Data Factory ondersteunt de mogelijkheid om schemawijzigingen in binnenkomende gegevens automatisch te detecteren en te beheren, zoals in streaminggegevens.
In de volgende schermopname ziet u een voorbeeld van een data factory-toewijzingsgegevensstroom.

Data engineers kunnen de gegevenskwaliteit profileeren en de resultaten van afzonderlijke gegevenstransformaties bekijken door foutopsporingsmogelijkheid in te schakelen tijdens de ontwikkeling.
Tip
Data Factory kan ook gegevens partitioneren om ETL-verwerking op schaal uit te voeren.
Indien nodig kunt u de transformationele en analytische functionaliteit van Data Factory uitbreiden door een gekoppelde service toe te voegen die uw code bevat in een pijplijn. Een Azure Synapse Notebook van een Spark-pool kan bijvoorbeeld Python-code bevatten die gebruikmaakt van een getraind model om de gegevens te beoordelen die zijn geïntegreerd door een toewijzingsgegevensstroom.
U kunt geïntegreerde gegevens en eventuele resultaten van analyses in een Data Factory-pijplijn opslaan in een of meer gegevensarchieven, zoals Data Lake Storage-, Azure Synapse- of Hive-tabellen in HDInsight. U kunt ook andere activiteiten aanroepen om te reageren op inzichten die zijn geproduceerd door een analytische pijplijn van Data Factory.
Tip
Data Factory-pijplijnen zijn uitbreidbaar omdat u met Data Factory uw eigen code kunt schrijven en deze kunt uitvoeren als onderdeel van een pijplijn.
Spark gebruiken om gegevensintegratie te schalen
Tijdens runtime maakt Data Factory intern gebruik van Azure Synapse Spark-pools, de Spark as a Service-aanbieding van Microsoft, om gegevens op te schonen en te integreren in de Azure-cloud. U kunt gegevens met een hoge snelheid, zoals klikstroomgegevens, op schaal opschonen, integreren en analyseren. Het is de bedoeling van Microsoft om ook Data Factory-pijplijnen uit te voeren op andere Spark-distributies. Naast het uitvoeren van ETL-taken in Spark, kan Data Factory Pig-scripts en Hive-query's aanroepen voor toegang tot en transformatie van gegevens die zijn opgeslagen in HDInsight.
Selfservice voor gegevensvoorbereiding en ETL-verwerking van Data Factory koppelen met behulp van wrangling-gegevensstromen
Met data-wrangling kunnen zakelijke gebruikers, ook wel bekend als citizen data integrators en data engineers, gebruikmaken van het platform om gegevens op schaal visueel te ontdekken, verkennen en voorbereiden zonder code te schrijven. Deze Data Factory-functie is eenvoudig te gebruiken en is vergelijkbaar met Microsoft Excel Power Query- of Microsoft Power BI-gegevensstromen, waarbij zakelijke selfservicegebruikers een gebruikersinterface in spreadsheetstijl gebruiken met vervolgkeuzelijsttransformaties om gegevens voor te bereiden en te integreren. In de volgende schermopname ziet u een voorbeeld van een Data Factory-wrangling-gegevensstroom.

In tegenstelling tot Excel en Power BI gebruiken data factory-wrangling-gegevensstromen Power Query om M-code te genereren en deze vervolgens om te zetten in een enorm parallelle Spark-taak in het geheugen voor uitvoering op cloudschaal. Met de combinatie van het toewijzen van gegevensstromen en het wrangling van gegevensstromen in Data Factory kunnen professionele ETL-ontwikkelaars en zakelijke gebruikers samenwerken om gegevens voor een gemeenschappelijk zakelijk doel voor te bereiden, te integreren en te analyseren. In het voorgaande diagram van data factory-toewijzingsgegevensstromen ziet u hoe zowel Data Factory- als Azure Synapse Spark-poolnotebooks kunnen worden gecombineerd in dezelfde Data Factory-pijplijn. De combinatie van het toewijzen en wrangling van gegevensstromen in Data Factory helpt IT- en zakelijke gebruikers op de hoogte te blijven van de gegevensstromen die elk heeft gemaakt, en ondersteunt hergebruik van gegevensstromen om heruitvinding te minimaliseren en productiviteit en consistentie te maximaliseren.
Tip
Data Factory ondersteunt zowel het wrangling van gegevensstromen als het toewijzen van gegevensstromen, zodat zakelijke gebruikers en IT-gebruikers gegevens gezamenlijk kunnen integreren op een gemeenschappelijk platform.
Gegevens en analyses koppelen in analytische pijplijnen
Naast het opschonen en transformeren van gegevens, kan Data Factory gegevensintegratie en analyses combineren in dezelfde pijplijn. U kunt Data Factory gebruiken om zowel gegevensintegratie- als analytische pijplijnen te maken. De laatste is een uitbreiding van de eerste pijplijn. U kunt een analytisch model in een pijplijn plaatsen om een analytische pijplijn te maken die schone, geïntegreerde gegevens voor voorspellingen of aanbevelingen genereert. Vervolgens kunt u direct reageren op de voorspellingen of aanbevelingen of deze opslaan in uw datawarehouse om nieuwe inzichten en aanbevelingen te bieden die kunnen worden weergegeven in BI-hulpprogramma's.
Als u uw gegevens batchgewijs wilt beoordelen, kunt u een analytisch model ontwikkelen dat u als een service aanroept binnen een Data Factory-pijplijn. U kunt analytische modellen zonder code ontwikkelen met Azure Machine Learning-studio of met de Azure Machine Learning SDK met behulp van Azure Synapse Spark-poolnotebooks of R in RStudio. Wanneer u Spark machine learning-pijplijnen uitvoert op Azure Synapse Spark-poolnotebooks, vindt analyse op schaal plaats.
U kunt geïntegreerde gegevens en eventuele analytische pijplijnen van Data Factory opslaan in een of meer gegevensarchieven, zoals Data Lake Storage-, Azure Synapse- of Hive-tabellen in HDInsight. U kunt ook andere activiteiten aanroepen om te reageren op inzichten die zijn geproduceerd door een analytische pijplijn van Data Factory.
Een lake-database gebruiken om consistente vertrouwde gegevens te delen
Een belangrijk doel van het instellen van gegevensintegratie is de mogelijkheid om gegevens eenmaal te integreren en deze overal opnieuw te gebruiken, niet alleen in een datawarehouse. U kunt bijvoorbeeld geïntegreerde gegevens gebruiken in gegevenswetenschap. Hergebruik voorkomt heruitvinding en zorgt voor consistente, algemeen begrepen gegevens die iedereen kan vertrouwen.
Common Data Model beschrijft kerngegevensentiteiten die kunnen worden gedeeld en opnieuw kunnen worden gebruikt in de hele onderneming. Om hergebruik te bereiken, stelt Common Data Model een set algemene gegevensnamen en definities vast die logische gegevensentiteiten beschrijven. Voorbeelden van algemene gegevensnamen zijn klant, account, product, leverancier, orders, Betalingen en retouren. IT- en zakelijke professionals kunnen software voor gegevensintegratie gebruiken om algemene gegevensassets te maken en op te slaan om het hergebruik ervan te maximaliseren en overal consistentie te stimuleren.
Azure Synapse biedt branchespecifieke databasesjablonen om gegevens in de lake te standaardiseren. Lake-databasesjablonen bieden schema's voor vooraf gedefinieerde bedrijfsgebieden, waardoor gegevens op een gestructureerde manier in een lake-database kunnen worden geladen. De kracht komt wanneer u software voor gegevensintegratie gebruikt om algemene gegevensassets voor lake-databases te maken, wat resulteert in het zelf beschrijven van vertrouwde gegevens die kunnen worden gebruikt door toepassingen en analytische systemen. U kunt algemene gegevensassets maken in Data Lake Storage met behulp van Data Factory.
Tip
Data Lake Storage is gedeelde opslag die ten grondslag ligt aan Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark en HDInsight.
Power BI, Azure Synapse Spark, Azure Synapse en Azure Machine Learning kunnen gebruikmaken van algemene gegevensassets. In het volgende diagram ziet u hoe een lake-database kan worden gebruikt in Azure Synapse.
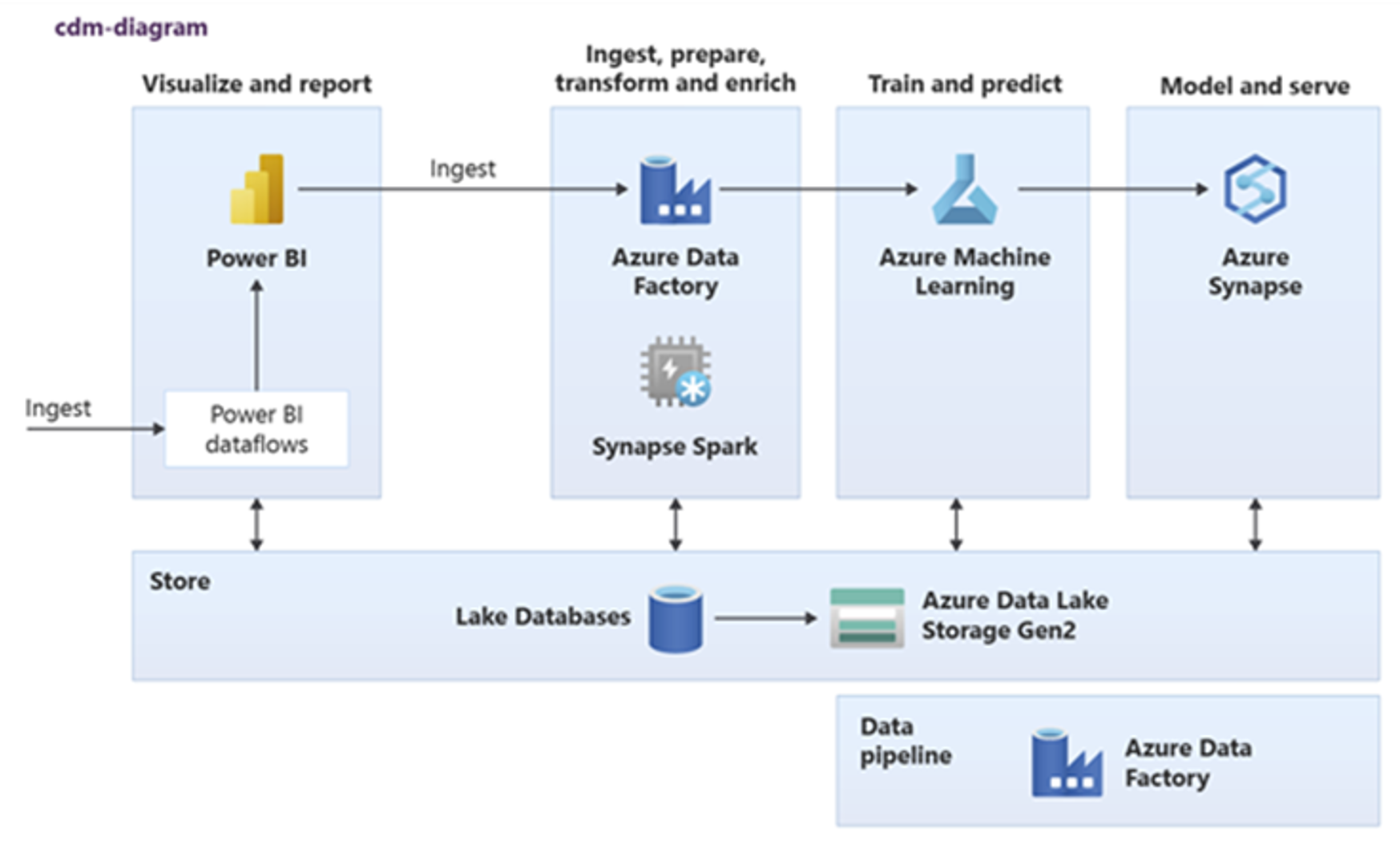
Tip
Gegevens integreren om logische lake-database-entiteiten te maken in gedeelde opslag om het hergebruik van algemene gegevensassets te maximaliseren.
Integratie met Data Science-technologieën van Microsoft in Azure
Een andere belangrijke doelstelling bij het moderniseren van een datawarehouse is het produceren van inzichten voor concurrentievoordeel. U kunt inzichten verkrijgen door uw gemigreerde datawarehouse te integreren met Data Science-technologieën van Microsoft en derden in Azure. In de volgende secties worden machine learning- en data science-technologieën beschreven die door Microsoft worden aangeboden om te zien hoe ze kunnen worden gebruikt met Azure Synapse in een moderne datawarehouse-omgeving.
Microsoft-technologieën voor gegevenswetenschap in Azure
Microsoft biedt een reeks technologieën die ondersteuning bieden voor geavanceerde analyse. Met deze technologieën kunt u voorspellende analytische modellen bouwen met behulp van machine learning of ongestructureerde gegevens analyseren met behulp van deep learning. De technologieën omvatten:
Azure Machine Learning Studio
Azure Machine Learning
Azure Synapse Spark-poolnotebooks
ML.NET (API, CLI of ML.NET Model Builder voor Visual Studio)
.NET voor Apache Spark
Gegevenswetenschappers kunnen RStudio (R) en Jupyter Notebooks (Python) gebruiken om analytische modellen te ontwikkelen, of ze kunnen frameworks zoals Keras of TensorFlow gebruiken.
Tip
Ontwikkel machine learning-modellen met behulp van een benadering zonder/weinig code of met behulp van programmeertalen zoals Python, R en .NET.
Azure Machine Learning Studio
Azure Machine Learning-studio is een volledig beheerde cloudservice waarmee u voorspellende analyses kunt bouwen, implementeren en delen met behulp van een webinterface met slepen en neerzetten. In de volgende schermopname ziet u de gebruikersinterface van Azure Machine Learning-studio.

Azure Machine Learning
Azure Machine Learning biedt een SDK en services voor Python waarmee u snel gegevens kunt voorbereiden en machine learning-modellen kunt trainen en implementeren. U kunt Azure Machine Learning gebruiken in Azure-notebooks met behulp van Jupyter Notebook, met opensource-frameworks, zoals PyTorch, TensorFlow, scikit-learn of Spark MLlib, de machine learning-bibliotheek voor Spark. Azure Machine Learning biedt een AutoML-functie waarmee automatisch meerdere algoritmen worden getest om de meest nauwkeurige algoritmen te identificeren om de modelontwikkeling te versnellen.
Tip
Azure Machine Learning biedt een SDK voor het ontwikkelen van machine learning-modellen met behulp van verschillende opensource-frameworks.
U kunt Azure Machine Learning ook gebruiken om machine learning-pijplijnen te bouwen die de end-to-end-werkstroom beheren, programmatisch schalen in de cloud en modellen implementeren in zowel de cloud als de rand. Azure Machine Learning bevat werkruimten. Dit zijn logische ruimten die u programmatisch of handmatig kunt maken in de Azure Portal. Deze werkruimten bewaren rekendoelen, experimenten, gegevensarchieven, getrainde machine learning-modellen, Docker-installatiekopieën en geïmplementeerde services allemaal op één plek, zodat teams kunnen samenwerken. U kunt Azure Machine Learning in Visual Studio gebruiken met de Visual Studio voor AI-extensie.
Tip
Organiseer en beheer gerelateerde gegevensarchieven, experimenten, getrainde modellen, Docker-installatiekopieën en geïmplementeerde services in werkruimten.
Azure Synapse Spark-poolnotebooks
Een Azure Synapse Spark-pool notebook is een voor Azure geoptimaliseerde Apache Spark-service. Met Azure Synapse Spark-poolnotebooks:
Data engineers kunnen schaalbare gegevensvoorbereidingstaken bouwen en uitvoeren met behulp van Data Factory.
Gegevenswetenschappers kunnen machine learning-modellen op schaal bouwen en uitvoeren met behulp van notebooks die zijn geschreven in talen zoals Scala, R, Python, Java en SQL om resultaten te visualiseren.
Tip
Azure Synapse Spark een dynamisch schaalbare Spark as a Service-aanbieding van Microsoft is, biedt Spark schaalbare uitvoering van gegevensvoorbereiding, modelontwikkeling en uitvoering van geïmplementeerde modellen.
Taken die worden uitgevoerd in Azure Synapse Spark-poolnotebooks kunnen gegevens op schaal ophalen, verwerken en analyseren uit Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight en streaminggegevensservices zoals Apache Kafka.
Tip
Azure Synapse Spark toegang heeft tot gegevens in een reeks gegevensarchieven van microsoft voor analytische ecosystemen in Azure.
Azure Synapse Spark-poolnotebooks ondersteunen automatisch schalen en automatische beëindiging om de totale eigendomskosten (TCO) te verlagen. Gegevenswetenschappers kunnen het opensource-framework van MLflow gebruiken om de levenscyclus van machine learning te beheren.
ML.NET
ML.NET is een opensource- platformoverschrijdend machine learning-framework voor Windows, Linux en macOS. Microsoft heeft ML.NET gemaakt zodat .NET-ontwikkelaars bestaande hulpprogramma's, zoals ML.NET Model Builder voor Visual Studio, kunnen gebruiken om aangepaste machine learning-modellen te ontwikkelen en deze te integreren in hun .NET-toepassingen.
Tip
Microsoft heeft de machine learning-mogelijkheid uitgebreid naar .NET-ontwikkelaars.
.NET voor Apache Spark
.NET voor Apache Spark breidt spark-ondersteuning uit van R, Scala, Python en Java naar .NET en is bedoeld om Spark toegankelijk te maken voor .NET-ontwikkelaars in alle Spark-API's. Hoewel .NET voor Apache Spark momenteel alleen beschikbaar is op Apache Spark in HDInsight, is Microsoft van plan .NET voor Apache Spark beschikbaar te maken op Azure Synapse Spark-poolnotebooks.
Azure Synapse Analytics gebruiken met uw datawarehouse
Als u machine learning-modellen wilt combineren met Azure Synapse, kunt u het volgende doen:
Gebruik machine learning-modellen in batch of in realtime op streaminggegevens om nieuwe inzichten te produceren en voeg deze inzichten toe aan wat u al weet in Azure Synapse.
Gebruik de gegevens in Azure Synapse om nieuwe voorspellende modellen te ontwikkelen en te trainen voor implementatie elders, zoals in andere toepassingen.
Implementeer machine learning-modellen, inclusief modellen die elders zijn getraind, in Azure Synapse om gegevens in uw datawarehouse te analyseren en nieuwe bedrijfswaarde te stimuleren.
Tip
Train, test, evalueer en voer machine learning-modellen op schaal uit op Azure Synapse Spark-poolnotebooks met behulp van gegevens in Azure Synapse.
Gegevenswetenschappers kunnen RStudio, Jupyter Notebooks en Azure Synapse Spark-poolnotebooks samen met Azure Machine Learning gebruiken om machine learning-modellen te ontwikkelen die op schaal worden uitgevoerd op Azure Synapse Spark-poolnotebooks met behulp van gegevens in Azure Synapse. Gegevenswetenschappers kunnen bijvoorbeeld een model zonder supervisie maken om klanten te segmenteren om verschillende marketingcampagnes te stimuleren. Gebruik machine learning onder supervisie om een model te trainen om een specifiek resultaat te voorspellen, zoals het voorspellen van de neiging van een klant tot verloop, of om de volgende beste aanbieding voor een klant aan te bevelen om de waarde te verhogen. In het volgende diagram ziet u hoe Azure Synapse kunnen worden gebruikt voor Azure Machine Learning.
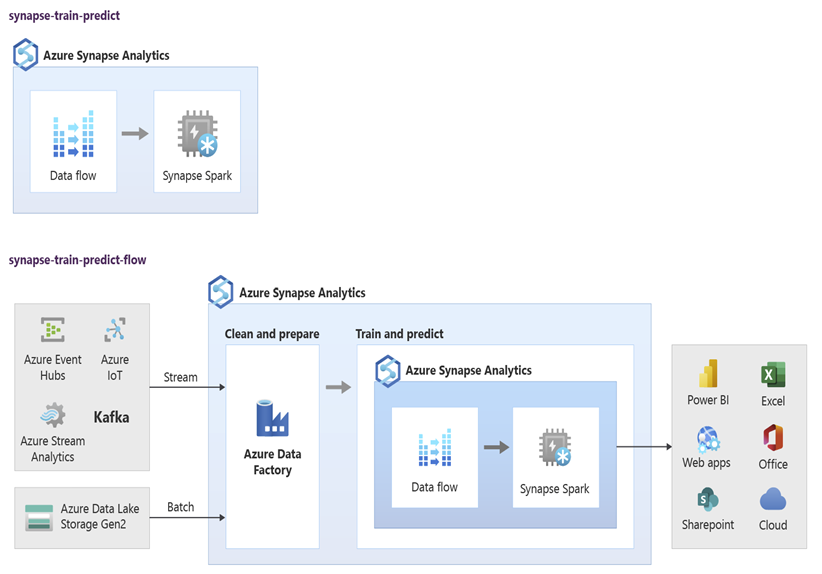
In een ander scenario kunt u sociaal netwerk opnemen of websitegegevens bekijken in Data Lake Storage en vervolgens de gegevens op schaal voorbereiden en analyseren in een Azure Synapse Spark-poolnotebook met behulp van verwerking in natuurlijke taal om het gevoel van klanten over uw producten of merk te beoordelen. Vervolgens kunt u deze scores toevoegen aan uw datawarehouse. Door big data-analyses te gebruiken om inzicht te hebben in het effect van negatieve sentimenten op de productverkoop, voegt u toe aan wat u al weet in uw datawarehouse.
Tip
Maak nieuwe inzichten met behulp van machine learning in Azure in batch of in realtime en voeg toe aan wat u in uw datawarehouse weet.
Live streamen van gegevens integreren in Azure Synapse Analytics
Wanneer u gegevens analyseert in een modern datawarehouse, moet u streaminggegevens in realtime kunnen analyseren en deze combineren met historische gegevens in uw datawarehouse. Een voorbeeld is het combineren van IoT-gegevens met product- of assetgegevens.
Tip
Integreer uw datawarehouse met streaminggegevens van IoT-apparaten of clickstreams.
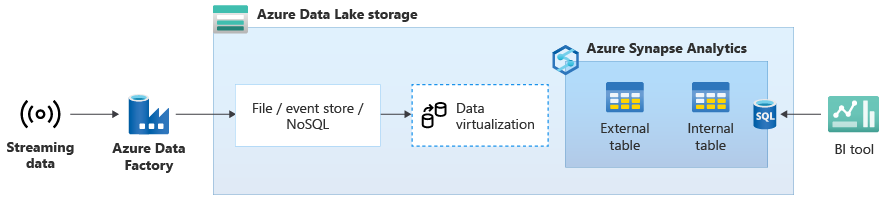
Zodra u uw datawarehouse naar Azure Synapse hebt gemigreerd, kunt u livestreaming van gegevensintegratie introduceren als onderdeel van een moderniseringsoefening voor het datawarehouse door gebruik te maken van de extra functionaliteit in Azure Synapse. Hiervoor neemt u streaminggegevens op via Event Hubs, andere technologieën zoals Apache Kafka of mogelijk uw bestaande ETL-hulpprogramma als het de streaminggegevensbronnen ondersteunt. Sla de gegevens op in Data Lake Storage. Maak vervolgens een externe tabel in Azure Synapse met behulp van PolyBase en richt deze op de gegevens die naar Data Lake Storage worden gestreamd, zodat uw datawarehouse nu nieuwe tabellen bevat die toegang bieden tot de realtime streaminggegevens. Voer een query uit op de externe tabel alsof de gegevens zich in het datawarehouse bevinden met behulp van standaard T-SQL van een BI-hulpprogramma dat toegang heeft tot Azure Synapse. U kunt de streaminggegevens ook koppelen aan andere tabellen met historische gegevens om weergaven te maken die live streaminggegevens koppelen aan historische gegevens, zodat zakelijke gebruikers gemakkelijker toegang hebben tot de gegevens.
Tip
Neem streaminggegevens op in Data Lake Storage van Event Hubs of Apache Kafka en krijg toegang tot de gegevens uit Azure Synapse met behulp van externe PolyBase-tabellen.
In het volgende diagram is een realtime datawarehouse op Azure Synapse geïntegreerd met streaminggegevens in Data Lake Storage.
Een logisch datawarehouse maken met PolyBase
Met PolyBase kunt u een logisch datawarehouse maken om gebruikerstoegang tot meerdere analytische gegevensarchieven te vereenvoudigen. Veel bedrijven hebben naast hun datawarehouses de afgelopen jaren gebruikgemaakt van 'geoptimaliseerde' analytische gegevensarchieven. De analytische platforms in Azure zijn onder andere:
Data Lake Storage met Azure Synapse Spark-poolnotebook (Spark as a Service) voor big data-analyse.
HDInsight (Hadoop as a Service), ook voor big data-analyse.
NoSQL Graph-databases voor grafiekanalyse, wat kan worden uitgevoerd in Azure Cosmos DB.
Event Hubs en Stream Analytics, voor realtime analyse van gegevens in beweging.
Mogelijk hebt u niet-Microsoft-equivalenten van deze platforms of een MDM-systeem (Master Data Management) dat moet worden geopend voor consistente vertrouwde gegevens over klanten, leveranciers, producten, activa en meer.
Tip
PolyBase vereenvoudigt de toegang tot meerdere onderliggende analytische gegevensarchieven in Azure voor toegankelijkheid voor zakelijke gebruikers.
Deze analytische platforms zijn ontstaan vanwege de explosie van nieuwe gegevensbronnen binnen en buiten de onderneming en de vraag van zakelijke gebruikers om de nieuwe gegevens vast te leggen en te analyseren. De nieuwe gegevensbronnen zijn onder andere:
Door de machine gegenereerde gegevens, zoals IoT-sensorgegevens en clickstream-gegevens.
Door mensen gegenereerde gegevens, zoals gegevens van sociale netwerken, beoordeling van websitegegevens, inkomende e-mail van klanten, afbeeldingen en video.
Andere externe gegevens, zoals openbare overheidsgegevens en weergegevens.
Deze nieuwe gegevens gaan verder dan de gestructureerde transactiegegevens en belangrijkste gegevensbronnen die doorgaans datawarehouses voeden en omvatten vaak:
- Semi-gestructureerde gegevens, zoals JSON, XML of Avro.
- Ongestructureerde gegevens, zoals tekst, spraak, afbeelding of video, die ingewikkelder zijn om te verwerken en te analyseren.
- Gegevens met een hoog volume, gegevens met hoge snelheid of beide.
Als gevolg hiervan zijn nieuwe complexere soorten analyses ontstaan, zoals verwerking van natuurlijke taal, graafanalyse, deep learning, streaming-analyse of complexe analyse van grote hoeveelheden gestructureerde gegevens. Dit soort analyses vinden doorgaans niet plaats in een datawarehouse, dus het is niet verrassend om verschillende analytische platforms te zien voor verschillende typen analytische workloads, zoals wordt weergegeven in het volgende diagram.
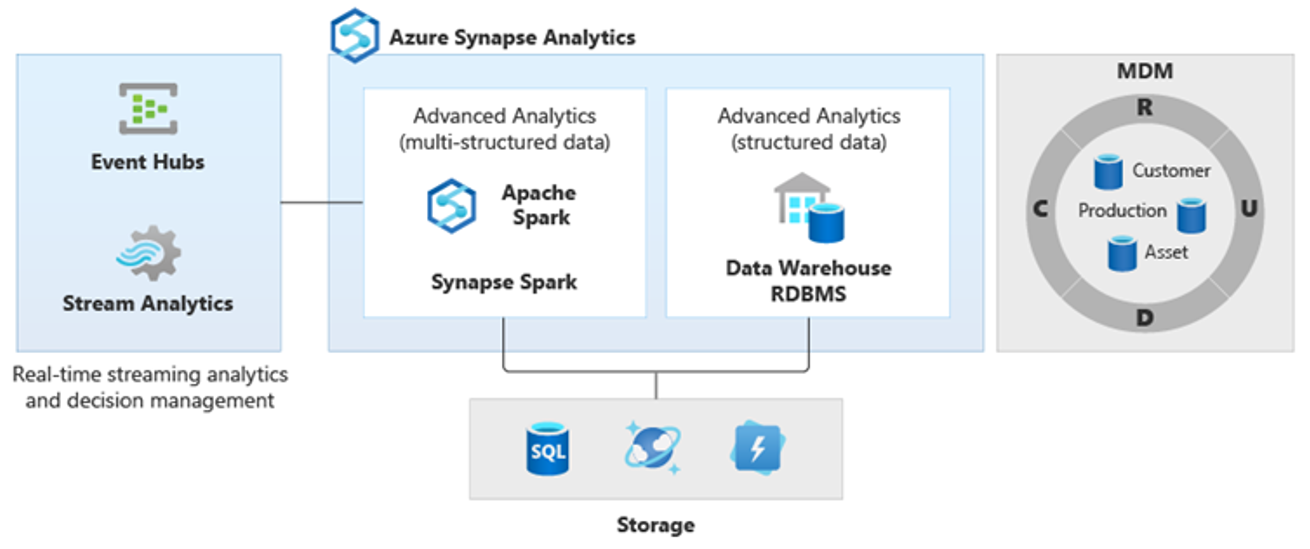
Tip
De mogelijkheid om gegevens in meerdere analytische gegevensarchieven eruit te laten zien alsof ze zich allemaal in één systeem bevinden en deze koppelen aan Azure Synapse staat bekend als een logische datawarehouse-architectuur.
Omdat deze platforms nieuwe inzichten opleveren, is het normaal dat u de nieuwe inzichten moet combineren met wat u al weet in Azure Synapse, wat PolyBase mogelijk maakt.
Met PolyBase-gegevensvirtualisatie binnen Azure Synapse kunt u een logisch datawarehouse implementeren waarin gegevens in Azure Synapse worden gekoppeld aan gegevens in andere Azure- en on-premises analytische gegevensarchieven, zoals HDInsight, Azure Cosmos DB, of streaminggegevens die vanuit Stream Analytics of Event Hubs naar Data Lake Storage stromen. Deze aanpak verlaagt de complexiteit voor gebruikers die toegang hebben tot externe tabellen in Azure Synapse en niet hoeven te weten dat de gegevens die ze openen, zijn opgeslagen in meerdere onderliggende analytische systemen. In het volgende diagram ziet u een complexe datawarehousestructuur die toegankelijk is via relatief eenvoudigere maar nog steeds krachtige UI-methoden.
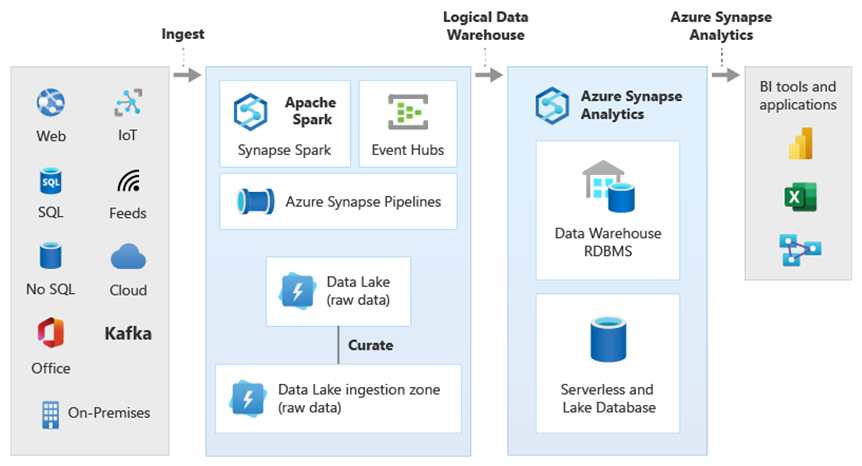
In het diagram ziet u hoe andere technologieën in het analytische ecosysteem van Microsoft kunnen worden gecombineerd met de mogelijkheid van de logische datawarehouse-architectuur in Azure Synapse. U kunt bijvoorbeeld gegevens opnemen in Data Lake Storage en de gegevens cureren met behulp van Data Factory om vertrouwde gegevensproducten te maken die logische gegevensentiteiten van Microsoft Lake-databases vertegenwoordigen. Deze vertrouwde, algemeen begrepen gegevens kunnen vervolgens worden gebruikt en opnieuw worden gebruikt in verschillende analytische omgevingen, zoals Azure Synapse, Azure Synapse Spark-poolnotebooks of Azure Cosmos DB. Alle inzichten die in deze omgevingen worden geproduceerd, zijn toegankelijk via een logische datawarehouse-gegevensvirtualisatielaag die mogelijk wordt gemaakt door PolyBase.
Tip
Een logische datawarehouse-architectuur vereenvoudigt de toegang van zakelijke gebruikers tot gegevens en voegt nieuwe waarde toe aan wat u al in uw datawarehouse weet.
Conclusies
Nadat u uw datawarehouse naar Azure Synapse hebt gemigreerd, kunt u profiteren van andere technologieën in het analytische ecosysteem van Microsoft. Op deze wijze moderniseert u niet alleen uw datawarehouse, maar brengt u inzichten die zijn geproduceerd in andere analytische gegevensarchieven van Azure in een geïntegreerde analytische architectuur.
U kunt uw ETL-verwerking uitbreiden om gegevens van elk type op te nemen in Data Lake Storage en vervolgens de gegevens op schaal voorbereiden en integreren met behulp van Data Factory om vertrouwde, algemeen begrepen gegevensassets te produceren. Deze assets kunnen worden gebruikt door uw datawarehouse en worden geopend door gegevenswetenschappers en andere toepassingen. U kunt realtime en batchgeoriënteerde analytische pijplijnen bouwen en machine learning-modellen maken om in batch, in realtime op streaminggegevens en on-demand als een service uit te voeren.
U kunt PolyBase of COPY INTO om verder te gaan dan uw datawarehouse gebruiken om de toegang tot inzichten van meerdere onderliggende analytische platforms in Azure te vereenvoudigen. Hiervoor maakt u holistische geïntegreerde weergaven in een logisch datawarehouse die ondersteuning bieden voor toegang tot streaming, big data en traditionele datawarehouse-inzichten vanuit BI-hulpprogramma's en -toepassingen.
Door uw datawarehouse te migreren naar Azure Synapse, kunt u profiteren van het uitgebreide analytische microsoft-ecosysteem dat wordt uitgevoerd in Azure om nieuwe waarde in uw bedrijf te creëren.