Synapse-notebooks maken, ontwikkelen en onderhouden in Azure Synapse Analytics
Een Synapse-notebook is een webinterface waarmee u bestanden kunt maken die livecode, visualisaties en verhalende tekst bevatten. Notebooks zijn een goede plek om ideeën te valideren en snelle experimenten te gebruiken om inzichten uit uw gegevens te verkrijgen. Notebooks worden ook veel gebruikt in gegevensvoorbereiding, gegevensvisualisatie, machine learning en andere big data-scenario's.
Met een Synapse-notebook kunt u het volgende doen:
- Ga zonder installatiepoging aan de slag.
- Houd gegevens veilig met ingebouwde bedrijfsbeveiligingsfuncties.
- Analyseer gegevens in onbewerkte indelingen (CSV, txt, JSON, enzovoort), verwerkte bestandsindelingen (parquet, Delta Lake, ORC, enzovoort) en SQL-gegevensbestanden in tabelvorm op basis van Spark en SQL.
- Wees productief met verbeterde ontwerpmogelijkheden en ingebouwde gegevensvisualisatie.
In dit artikel wordt beschreven hoe u notitieblokken gebruikt in Synapse Studio.
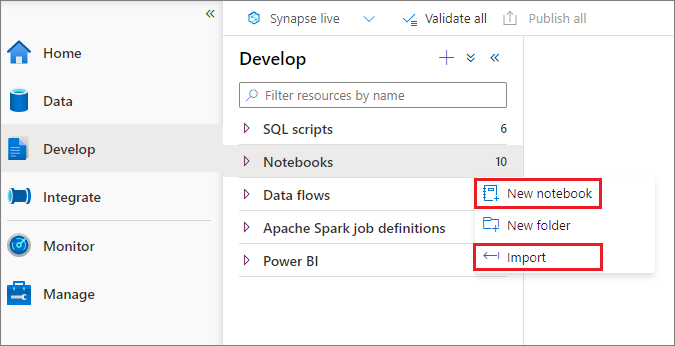
Een notebook maken
Er zijn twee manieren om een notitieblok te maken. U kunt een nieuw notitieblok maken of een bestaand notitieblok importeren in een Synapse-werkruimte vanuit de Objectverkenner. Synapse-notebooks herkennen standaard Jupyter Notebook IPYNB-bestanden.
Notebooks ontwikkelen
Notebooks bestaan uit cellen. Dit zijn afzonderlijke code- of tekstblokken die onafhankelijk of als groep kunnen worden uitgevoerd.
We bieden uitgebreide bewerkingen voor het ontwikkelen van notebooks:
- Een cel toevoegen
- Een primaire taal instellen
- Meerdere talen gebruiken
- Tijdelijke tabellen gebruiken om te verwijzen naar gegevens in verschillende talen
- IntelliSense in IDE-stijl
- Codefragmenten
- Tekstcel opmaken met werkbalkknoppen
- Celbewerking ongedaan maken/opnieuw uitvoeren
- Opmerking bij codecel
- Een cel verplaatsen
- Een cel verwijderen
- Een celinvoer samenvouwen
- Een celuitvoer samenvouwen
- Notitieblokoverzicht
Notitie
In de notebooks wordt automatisch een SparkSession voor u gemaakt, opgeslagen in een variabele met de naam spark. Er is ook een variabele voor SparkContext die wordt genoemd sc. Gebruikers hebben rechtstreeks toegang tot deze variabelen en mogen de waarden van deze variabelen niet wijzigen.
Een cel toevoegen
Er zijn meerdere manieren om een nieuwe cel aan uw notitieblok toe te voegen.
Beweeg de muisaanwijzer over de ruimte tussen twee cellen en selecteer Code of Markdown.

Gebruik aznb Sneltoetsen in de opdrachtmodus. Druk op A om een cel boven de huidige cel in te voegen. Druk op B om een cel in te voegen onder de huidige cel.
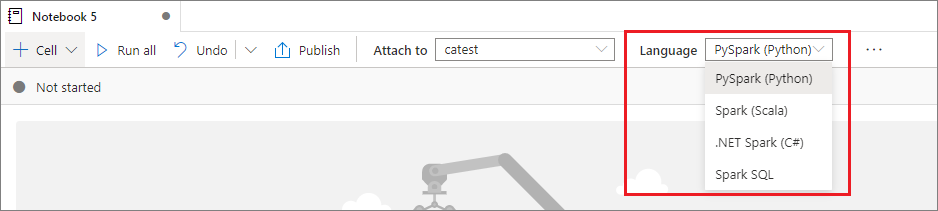
Een primaire taal instellen
Synapse-notebooks ondersteunen vier Apache Spark-talen:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
U kunt de primaire taal voor nieuwe toegevoegde cellen instellen vanuit de vervolgkeuzelijst op de bovenste opdrachtbalk.
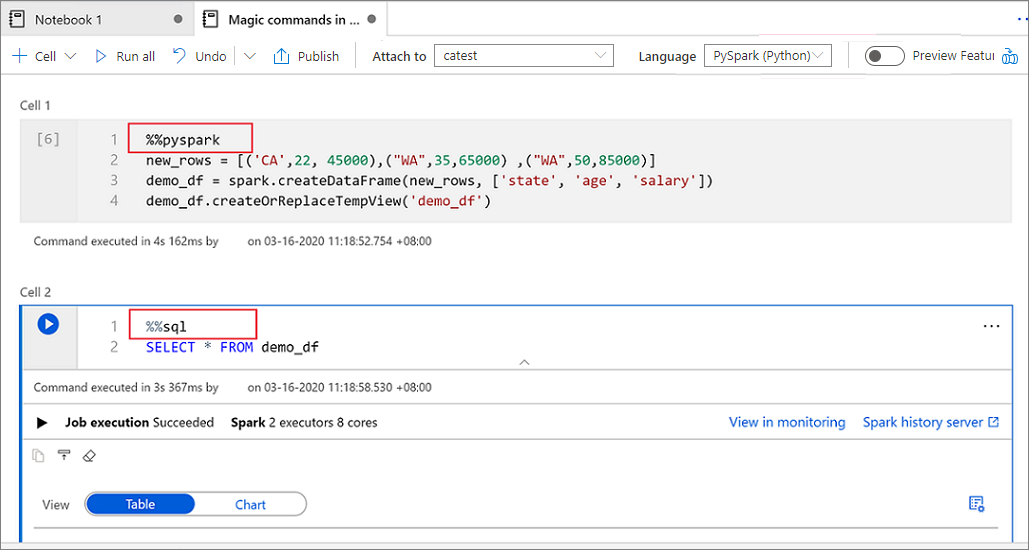
Meerdere talen gebruiken
U kunt meerdere talen in één notitieblok gebruiken door de juiste magic-opdracht voor de taal aan het begin van een cel op te geven. De volgende tabel bevat de magic-opdrachten voor het schakelen tussen celtalen.
| Magic-opdracht | Taal | Beschrijving |
|---|---|---|
| %%pyspark | Python | Voer een Python-query uit op spark-context. |
| %%spark | Scala | Voer een Scala-query uit op spark-context. |
| %%sql | SparkSQL | Voer een SparkSQL-query uit op spark-context. |
| %%csharp | .NET voor Spark C# | Voer een .NET voor Spark C#- query uit op spark-context. |
| %%sparkr | R | Voer een R-query uit op spark-context. |
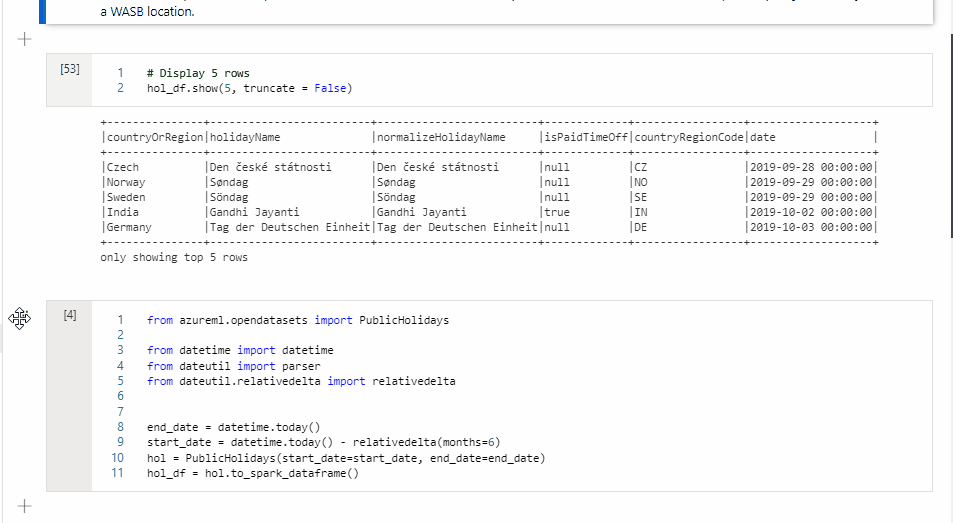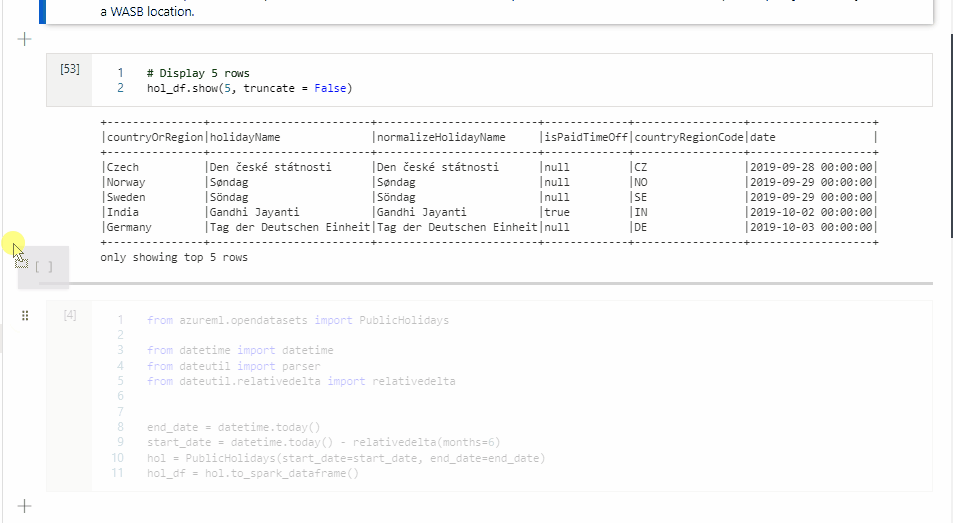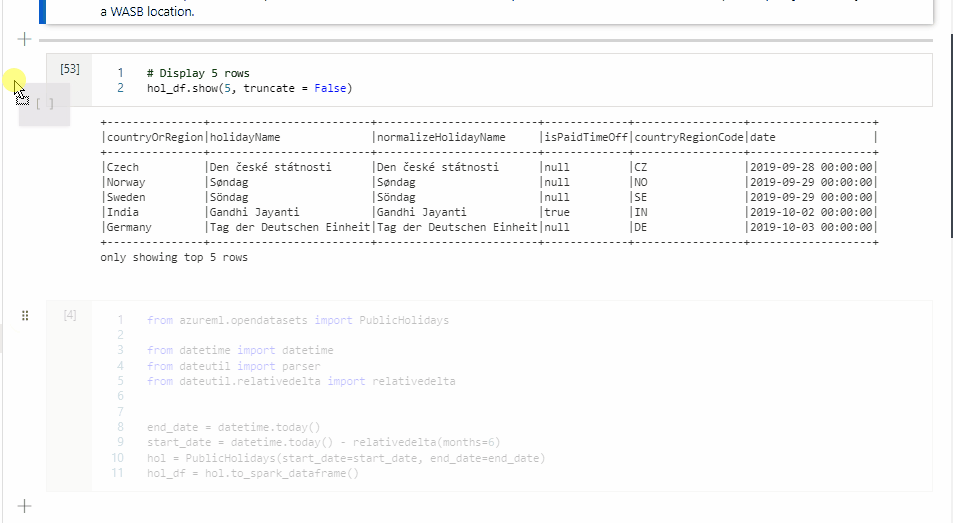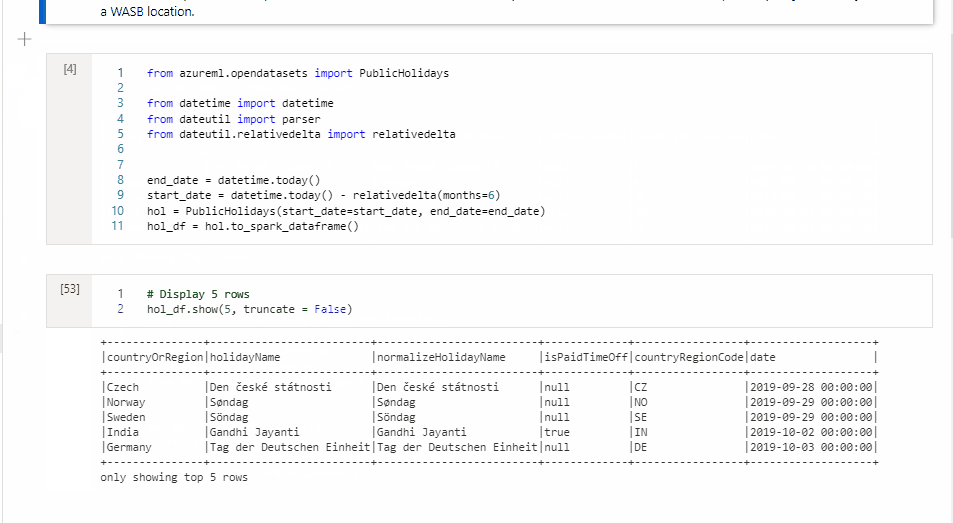
De volgende afbeelding is een voorbeeld van hoe u een PySpark-query kunt schrijven met behulp van de magic-opdracht %%pyspark of een SparkSQL-query met de magic-opdracht %%sql in een Spark(Scala) -notebook. U ziet dat de primaire taal voor het notebook is ingesteld op pySpark.
Tijdelijke tabellen gebruiken om te verwijzen naar gegevens in verschillende talen
U kunt niet rechtstreeks verwijzen naar gegevens of variabelen in verschillende talen in een Synapse-notebook. In Spark kan in verschillende talen naar een tijdelijke tabel worden verwezen. Hier volgt een voorbeeld van het lezen van een Scala DataFrame in PySpark en SparkSQL het gebruik van een Spark-tijdelijke tabel als tijdelijke oplossing.
Lees in cel 1 een DataFrame uit een SQL-poolconnector met behulp van Scala en maak een tijdelijke tabel.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )Voer in cel 2 een query uit op de gegevens met behulp van Spark SQL.
%%sql SELECT * FROM mydataframetableGebruik in cel 3 de gegevens in PySpark.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IntelliSense in IDE-stijl
Synapse-notebooks zijn geïntegreerd met de Monaco-editor om IntelliSense in IDE-stijl naar de celeditor te brengen. Met syntaxismarkering, foutmarkering en automatische voltooiing van code kunt u sneller code schrijven en problemen identificeren.
De IntelliSense-functies bevinden zich op verschillende niveaus van volwassenheid voor verschillende talen. Gebruik de volgende tabel om te zien wat er wordt ondersteund.
| Talen | Syntaxis markeren | Syntaxisfoutmarkering | Syntaxiscode voltooien | Voltooiing van variabelecode | Voltooiing van systeemfunctiecode | Voltooiing van gebruikersfunctiecode | Smart Indent | Code Folding |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| Spark (Scala) | Ja | Ja | Ja | Ja | Ja | Ja | - | Ja |
| SparkSQL | Ja | Ja | Ja | Ja | Ja | - | - | - |
| .NET voor Spark (C#) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
Notitie
Een actieve Spark-sessie is vereist om te profiteren van de variabele codevoltooiing, voltooiing van systeemfunctiecode, voltooiing van gebruikersfunctiecode voor .NET voor Spark (C#).
Codefragmenten
Synapse-notebooks bevatten codefragmenten waarmee u eenvoudiger veelgebruikte codepatronen kunt invoeren, zoals het configureren van uw Spark-sessie, het lezen van gegevens als een Spark DataFrame of het tekenen van grafieken met matplotlib, enzovoort.
Fragmenten worden weergegeven in sneltoetsen van de IDE-stijl IntelliSense in combinatie met andere suggesties. De inhoud van de codefragmenten wordt uitgelijnd met de taal van de codecel. U kunt beschikbare fragmenten zien door Fragment te typen of er worden trefwoorden weergegeven in de titel van het codefragment in de codeceleditor. Als u bijvoorbeeld lezen typt, ziet u de lijst met fragmenten voor het lezen van gegevens uit verschillende gegevensbronnen.
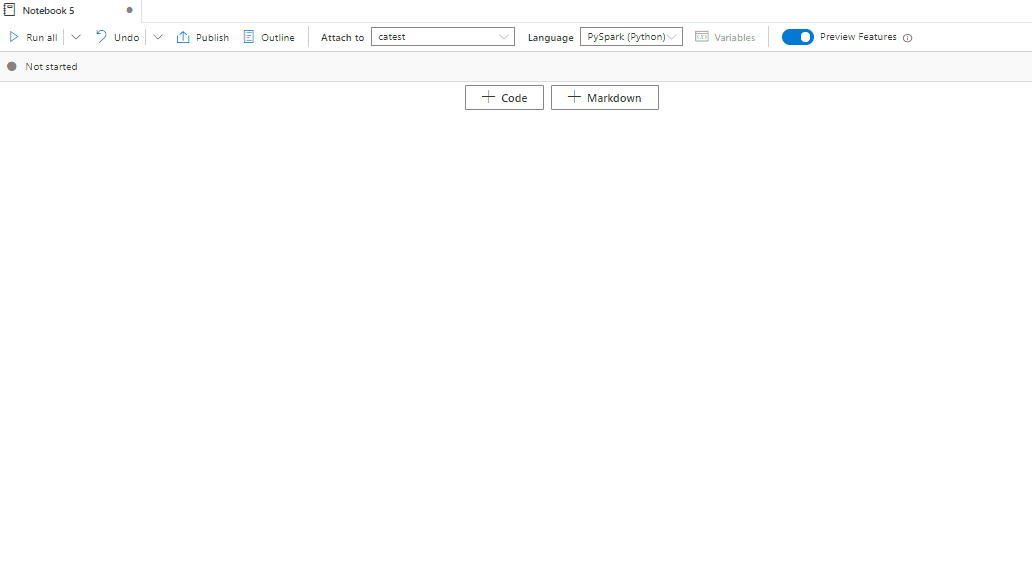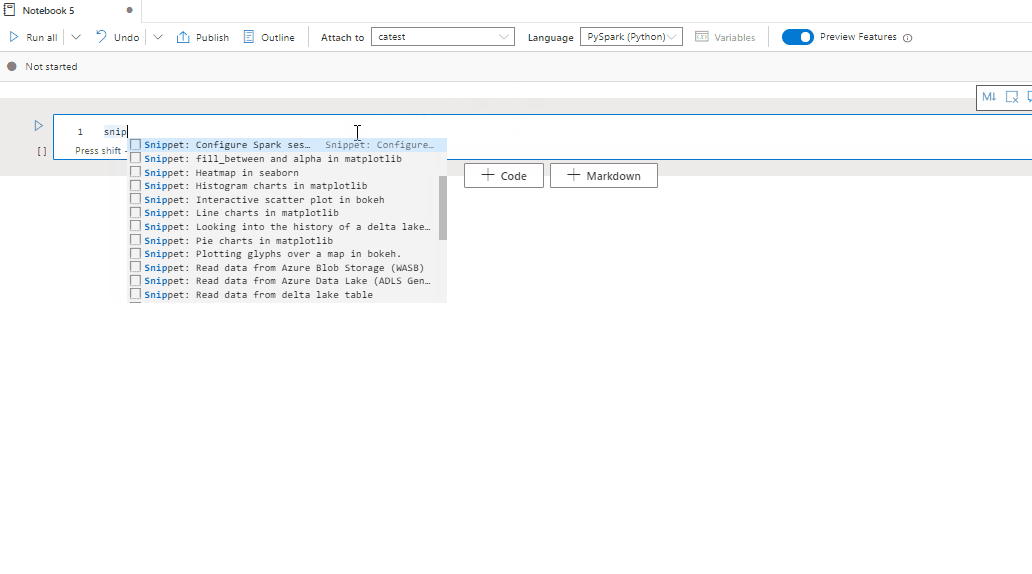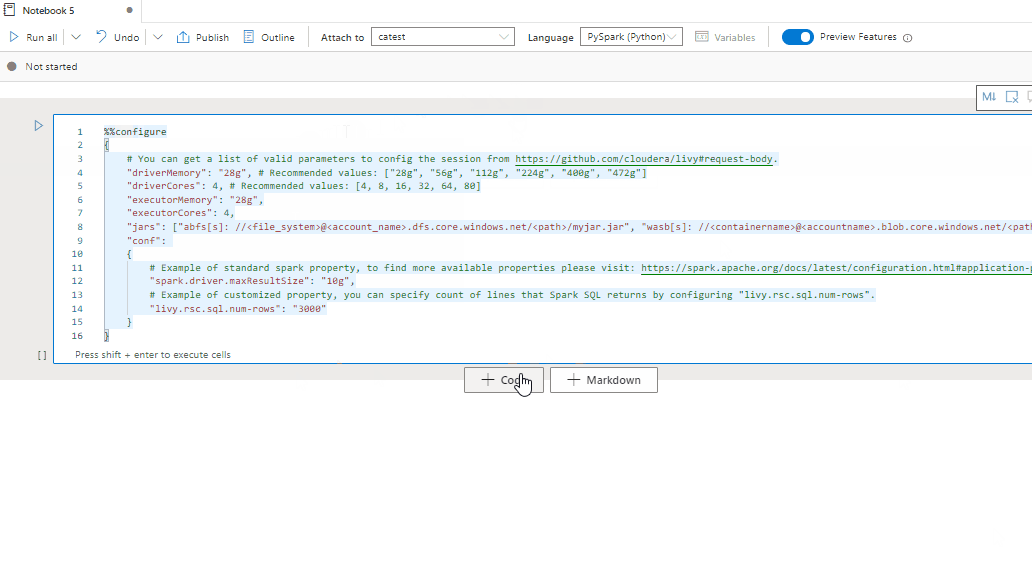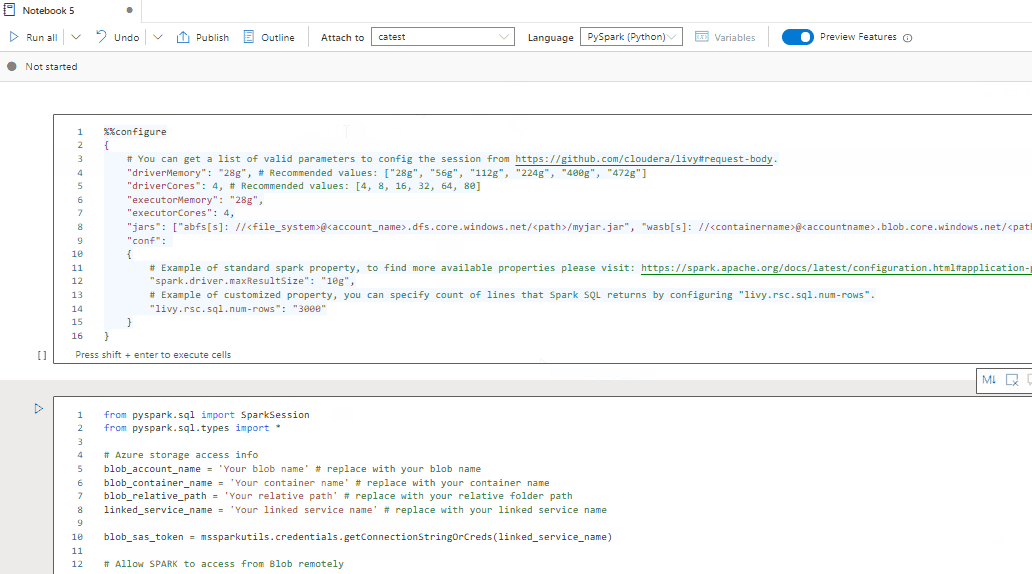
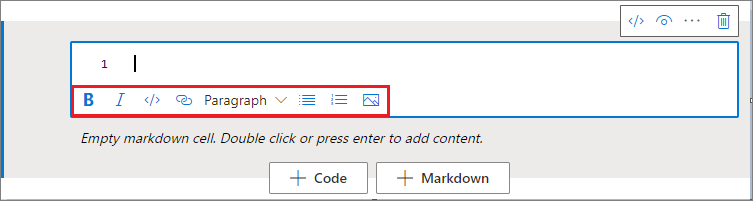
Tekstcel opmaken met werkbalkknoppen
U kunt de opmaakknoppen in de werkbalk tekstcellen gebruiken om algemene Markdown-acties uit te voeren. Dit omvat vetgedrukte tekst, cursief maken van tekst, alinea's/kopteksten door een vervolgkeuzelijst, het invoegen van code, het invoegen van niet-geordende lijst, het invoegen van een geordende lijst, het invoegen van een hyperlink en het invoegen van een afbeelding vanuit de URL.
Celbewerking ongedaan maken/opnieuw uitvoeren
Selecteer de knop Opnieuw ongedaan maken / of druk op Z / Shift+Z om de meest recente celbewerkingen in te trekken. U kunt nu de laatste tien historische celbewerkingen ongedaan maken/opnieuw uitvoeren.

Ondersteunde bewerkingen voor het ongedaan maken van cellen:
- Cel invoegen/verwijderen: u kunt de verwijderbewerkingen intrekken door Ongedaan maken te selecteren. De tekstinhoud wordt samen met de cel bewaard.
- De volgorde van de cel wijzigen.
- Schakel parameter in.
- Converteren tussen codecel en Markdown-cel.
Notitie
Tekstbewerkingen in de cel en bewerkingen voor opmerkingen in codecellen zijn niet onwerkbaar. U kunt nu de laatste tien historische celbewerkingen ongedaan maken/opnieuw uitvoeren.
Opmerking bij codecel
Selecteer de knop Opmerkingen op de werkbalk van het notitieblok om het opmerkingenvenster te openen.
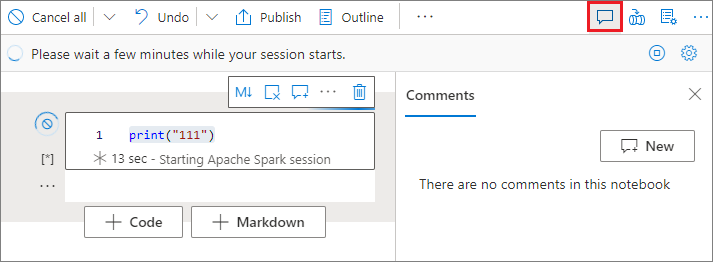
Selecteer code in de codecel, klik op Nieuw in het deelvenster Opmerkingen , voeg opmerkingen toe en klik vervolgens op de knop Opmerking plaatsen om op te slaan.
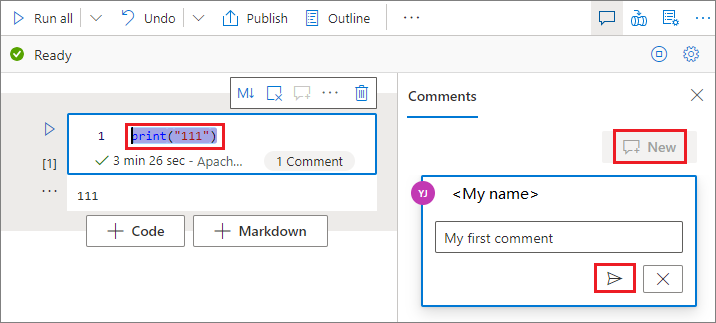
U kunt Opmerking bewerken, Thread oplossen of Thread verwijderen uitvoeren door naast uw opmerking op de knop Meer te klikken.

Een cel verplaatsen
Klik aan de linkerkant van een cel en sleep deze naar de gewenste positie.
Een cel verwijderen
Als u een cel wilt verwijderen, selecteert u de knop Verwijderen aan de rechterkant van de cel.
U kunt ook sneltoetsen gebruiken in de opdrachtmodus. Druk op Shift+D om de huidige cel te verwijderen.
Een celinvoer samenvouwen
Selecteer het beletselteken Meer opdrachten (...) op de celwerkbalk en Invoer verbergen om de invoer van de huidige cel samen te vouwen. Als u de cel wilt uitvouwen, selecteert u de optie Invoer weergeven terwijl de cel is samengevouwen.
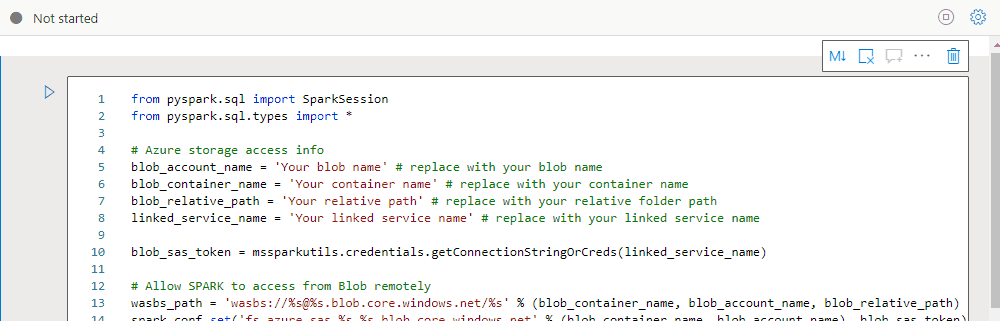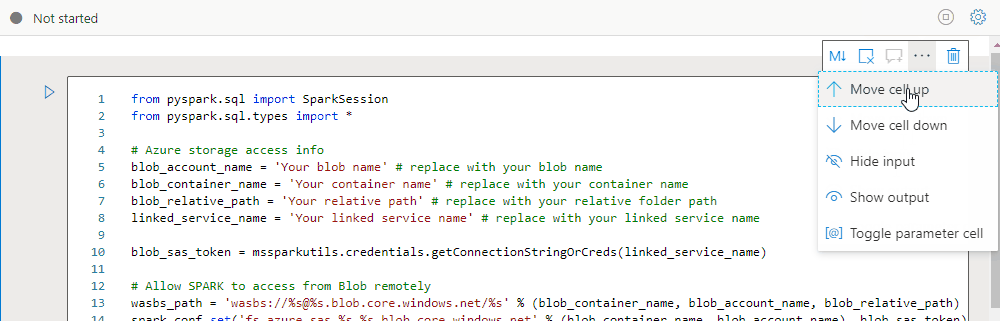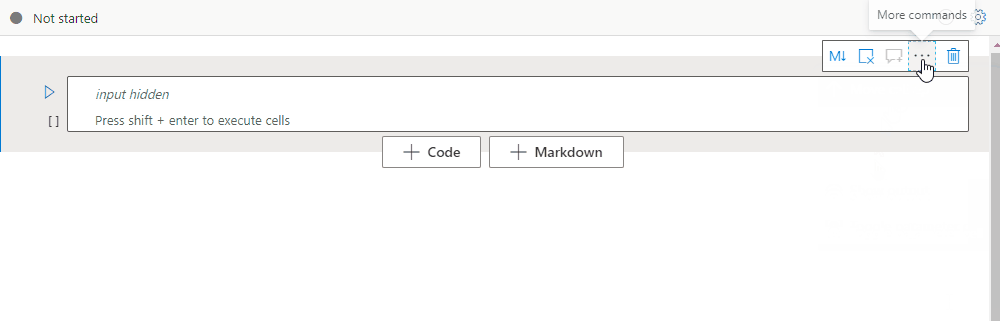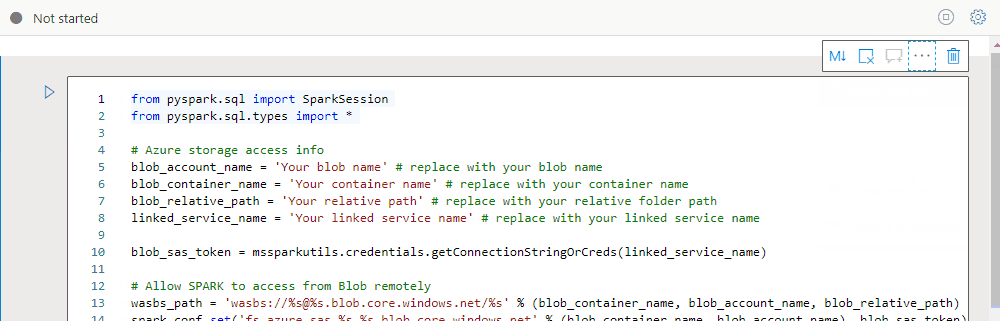
Een celuitvoer samenvouwen
Selecteer het beletselteken Meer opdrachten (...) op de celwerkbalk en Uitvoer verbergen om de uitvoer van de huidige cel samen te vouwen. Als u de cel wilt uitvouwen, selecteert u uitvoer weergeven terwijl de uitvoer van de cel is verborgen.
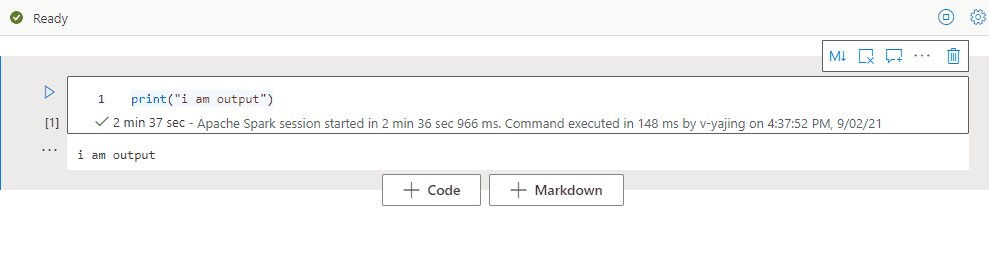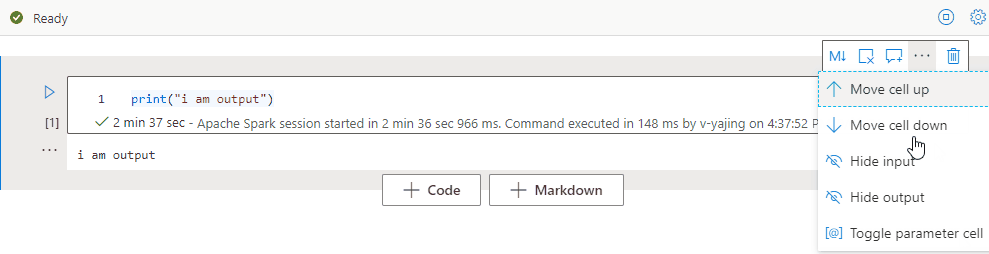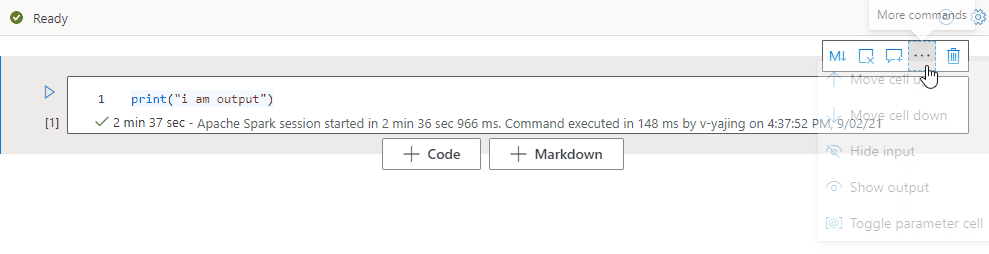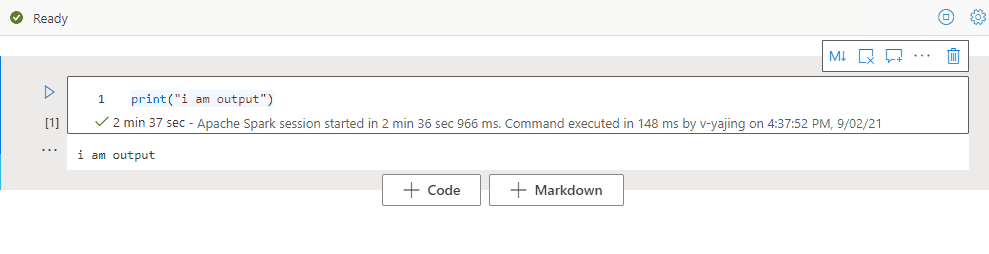
Notitieblokoverzicht
De Overzichten (Inhoudsopgave) toont de eerste markdown-koptekst van een markdown-cel in een zijbalkvenster voor snelle navigatie. De zijbalk Contouren kan worden aangepast aan het formaat en kan worden samengevouwen om het scherm zo goed mogelijk te laten passen. U kunt de knop Overzicht op de opdrachtbalk van het notitieblok selecteren om de zijbalk te openen of verbergen
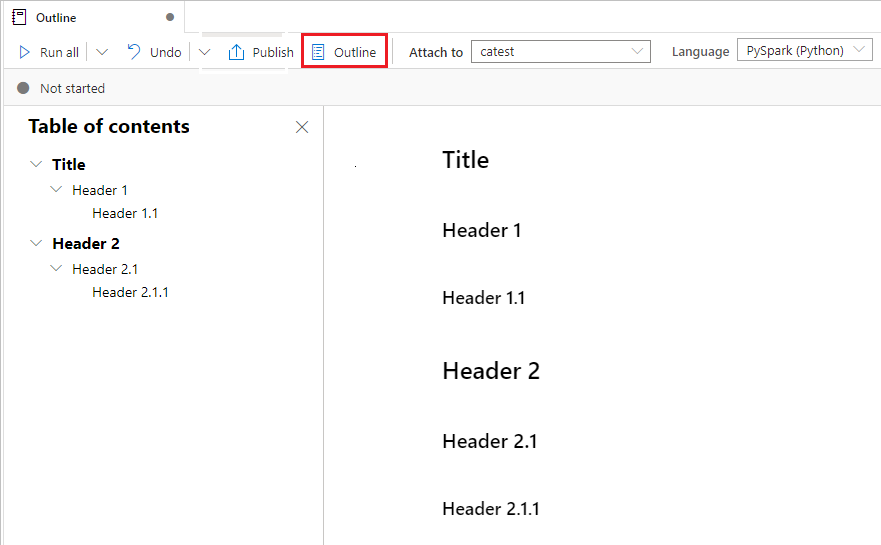
Notebooks gebruiken
U kunt de codecellen in uw notebook afzonderlijk of allemaal tegelijk uitvoeren. De status en voortgang van elke cel worden weergegeven in het notebook.
Een cel uitvoeren
Er zijn verschillende manieren om de code in een cel uit te voeren.
Beweeg de muisaanwijzer over de cel die u wilt uitvoeren en selecteer de knop Cel uitvoeren of druk op Ctrl+Enter.

Gebruik sneltoetsen in de opdrachtmodus. Druk op Shift+Enter om de huidige cel uit te voeren en selecteer de onderstaande cel. Druk op Alt+Enter om de huidige cel uit te voeren en eronder een nieuwe cel in te voegen.
Alle cellen uitvoeren
Selecteer de knop Alles uitvoeren om alle cellen in het huidige notebook achter elkaar uit te voeren.

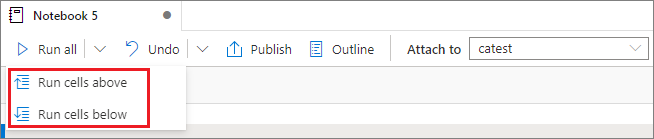
Alle cellen boven of onder uitvoeren
Vouw de vervolgkeuzelijst uit van de knop Alles uitvoeren en selecteer cellen erboven uitvoeren om alle cellen boven de huidige in volgorde uit te voeren. Selecteer Cellen uitvoeren hieronder om alle cellen onder de huidige in volgorde uit te voeren.
Alle actieve cellen annuleren
Selecteer de knop Alles annuleren om de actieve of wachtende cellen in de wachtrij te annuleren.

Naslaginformatie voor notitieblokken
U kunt de magic-opdracht gebruiken %run <notebook path> om te verwijzen naar een ander notitieblok binnen de context van het huidige notitieblok. Alle variabelen die in het verwijzingsnotitieblok zijn gedefinieerd, zijn beschikbaar in het huidige notitieblok. %run magic-opdracht ondersteunt geneste oproepen, maar ondersteunt geen recursieve aanroepen. U ontvangt een uitzondering als de instructiediepte groter is dan vijf.
Bijvoorbeeld: %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
Notebook-verwijzing werkt in zowel de interactieve modus als de Synapse-pijplijn.
Notitie
%runopdracht ondersteunt momenteel alleen om een absoluut pad of notebooknaam alleen als parameter door te geven. Relatief pad wordt niet ondersteund.%runopdracht ondersteunt momenteel alleen 4 typen parameterwaarden:int,float,bool, ,string, variabele vervangingsbewerking wordt niet ondersteund.- De notitieblokken waarnaar wordt verwezen, moeten worden gepubliceerd. U moet de notitieblokken publiceren om ernaar te verwijzen, tenzij Verwijzing naar niet-gepubliceerd notitieblok is ingeschakeld. Synapse Studio herkent de niet-gepubliceerde notebooks uit de Git-opslagplaats niet.
- Notebooks waarnaar wordt verwezen, bieden geen ondersteuning voor de instructie dat de diepte groter is dan vijf.
Variabeleverkenner
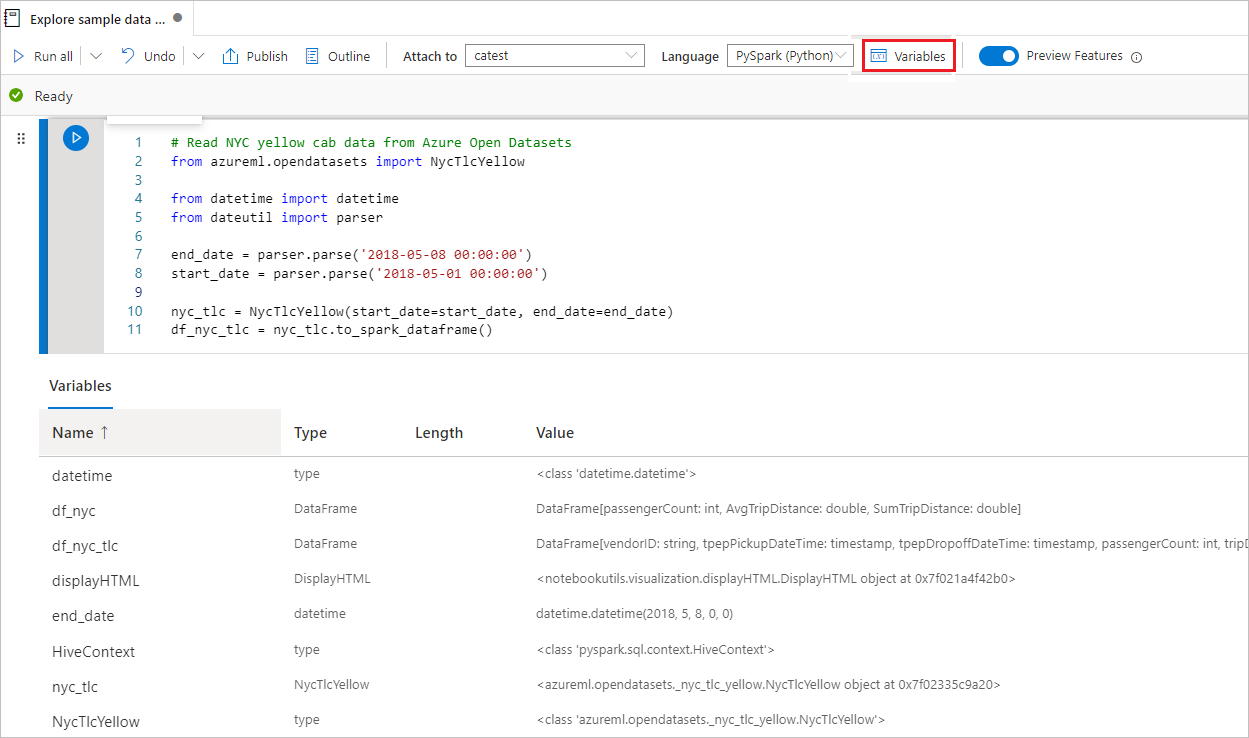
Synapse-notebook biedt een ingebouwde variabelenverkenner voor u om de lijst met de naam, het type, de lengte en de waarde van de variabelen in de huidige Spark-sessie voor PySpark-cellen (Python) te bekijken. Meer variabelen worden automatisch weergegeven wanneer ze worden gedefinieerd in de codecellen. Als u op elke kolomkop klikt, worden de variabelen in de tabel gesorteerd.
U kunt de knop Variabelen op de opdrachtbalk van het notitieblok selecteren om de variabeleverkenner te openen of te verbergen.
Notitie
Variabele verkenner biedt alleen ondersteuning voor Python.
Celstatusindicator
Onder de cel wordt een stapsgewijze uitvoeringsstatus van de cel weergegeven, zodat u de huidige voortgang kunt zien. Zodra de cel is uitgevoerd, wordt een uitvoeringssamenvatting met de totale duur en eindtijd weergegeven en daar bewaard voor toekomstig gebruik.

Voortgangsindicator voor Spark
Synapse-notebook is uitsluitend gebaseerd op Spark. Codecellen worden op afstand uitgevoerd op de serverloze Apache Spark-pool. Een Spark-taakvoortgangsindicator wordt geleverd met een realtime voortgangsbalk die u inzicht biedt in de uitvoeringsstatus van de taak. Het aantal taken per taak of fase helpt u bij het identificeren van het parallelle niveau van uw Spark-taak. U kunt ook dieper inzoomen op de Spark-gebruikersinterface van een specifieke taak (of fase) door de koppeling op de naam van de taak (of fase) te selecteren.

Configuratie van Spark-sessie
In Sessie configureren kunt u de time-outduur, het aantal en de grootte van de uitvoerders opgeven voor de huidige Spark-sessie. Als u de Spark-sessie opnieuw start, worden de configuratiewijzigingen doorgevoerd. Alle notebookvariabelen in de cache worden gewist.
U kunt ook een configuratie maken op basis van de Apache Spark-configuratie of een bestaande configuratie selecteren. Raadpleeg Apache Spark Configuration Management (Configuratiebeheer van Apache Spark) voor meer informatie.

Magic-opdracht voor spark-sessieconfiguratie
U kunt ook instellingen voor Spark-sessies opgeven via een magische opdracht %%configure. De Spark-sessie moet opnieuw worden gestart om het effect van de instellingen te maken. We raden u aan om %%configure uit te voeren aan het begin van uw notebook. Hier volgt een voorbeeld. Raadpleeg voor https://github.com/cloudera/livy#request-body een volledige lijst met geldige parameters.
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Notitie
- 'DriverMemory' en 'ExecutorMemory' worden aanbevolen om in te stellen als dezelfde waarde in %%configure, net als 'driverCores' en 'executorCores'.
- U kunt %%configure gebruiken in Synapse-pijplijnen, maar als deze niet is ingesteld in de eerste codecel, mislukt de uitvoering van de pijplijn omdat de sessie niet opnieuw kan worden gestart.
- De %%-configuratie die wordt gebruikt in mssparkutils.notebook.run wordt genegeerd, maar wordt gebruikt in %run notebook wordt gewoon uitgevoerd.
- De standaardconfiguratie-eigenschappen van Spark moeten worden gebruikt in de hoofdtekst 'conf'. We bieden geen ondersteuning voor naslaginformatie op het eerste niveau voor de Spark-configuratie-eigenschappen.
- Sommige speciale spark-eigenschappen, zoals 'spark.driver.cores', 'spark.executor.cores', 'spark.driver.memory', 'spark.executor.memory', 'spark.executor.instances' worden niet van kracht in de hoofdtekst 'conf'.
Geparameteriseerde sessieconfiguratie vanuit pijplijn
Met geparameteriseerde sessieconfiguratie kunt u de waarde in magic %%configure vervangen door parameters voor pijplijnuitvoering (Notebook-activiteit). Wanneer u de codecel %%configure voorbereidt, kunt u standaardwaarden (ook configureerbaar, 4 en 2000 in het onderstaande voorbeeld) overschrijven met een object als volgt:
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Notebook gebruikt de standaardwaarde als u een notebook rechtstreeks in de interactieve modus uitvoert of als er geen parameter wordt opgegeven die overeenkomt met 'activityParameterName' uit de activiteit Van het pijplijnnotitieblok.
Tijdens de uitvoeringsmodus van de pijplijn kunt u de instellingen voor de activiteit van de notebook-pijplijn configureren, zoals hieronder: 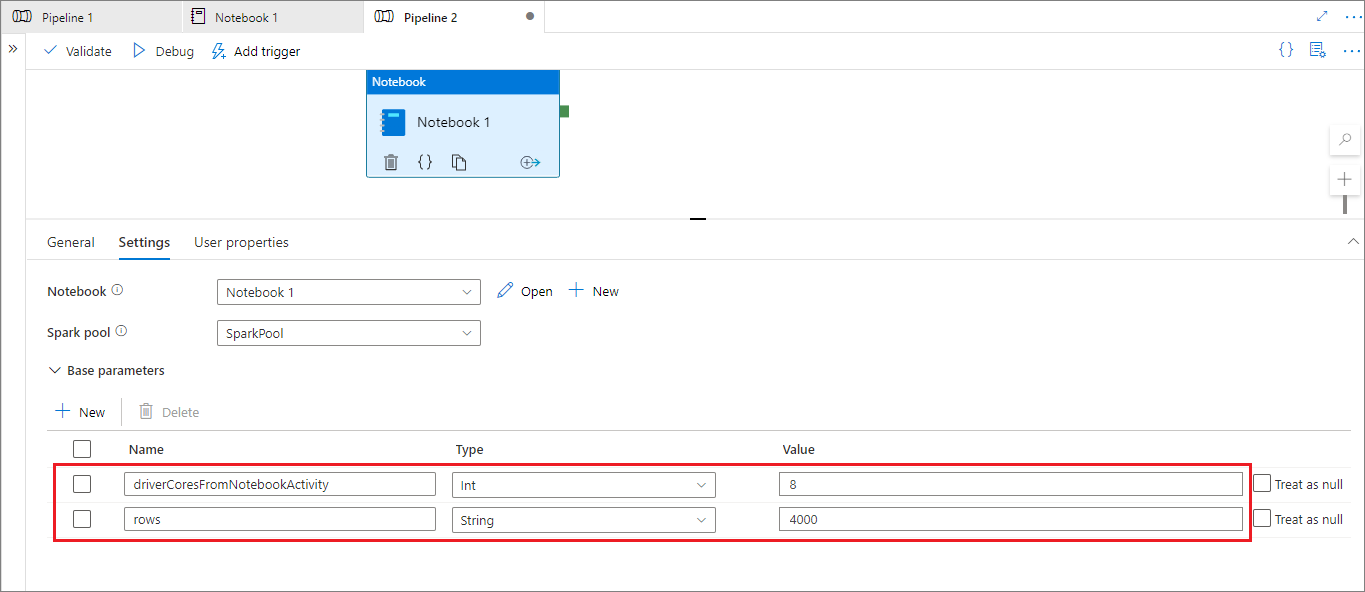
Als u de sessieconfiguratie wilt wijzigen, moet de naam van de activiteitsparameters van het notebook in de pijplijn hetzelfde zijn als activityParameterName in het notebook. Wanneer u deze pijplijn uitvoert, worden driverCores in %%configure in dit voorbeeld vervangen door 8 en worden livy.rsc.sql.num-rows vervangen door 4000.
Notitie
Als het uitvoeren van de pijplijn is mislukt vanwege het gebruik van deze nieuwe magic voor %%configure, kunt u meer foutinformatie controleren door de magic-cel %%configure uit te voeren in de interactieve modus van het notebook.
Gegevens naar een notebook overbrengen
U kunt gegevens laden uit Azure Blob Storage, Azure Data Lake Store Gen 2 en SQL-pool, zoals wordt weergegeven in de onderstaande codevoorbeelden.
Een CSV van Azure Data Lake Store Gen2 lezen als een Spark DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Een CSV van Azure Blob Storage lezen als een Spark DataFrame
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Gegevens lezen uit het primaire opslagaccount
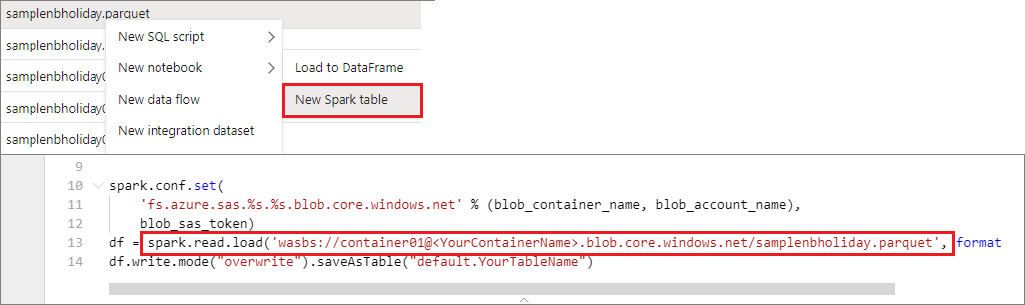
U hebt rechtstreeks toegang tot gegevens in het primaire opslagaccount. U hoeft de geheime sleutels niet op te geven. Klik in Data Explorer met de rechtermuisknop op een bestand en selecteer Nieuw notitieblok om een nieuw notitieblok weer te geven met automatisch gegenereerde gegevensextractor.
IPython-widgets
Widgets zijn veelbewogen Python-objecten die een weergave in de browser hebben, vaak als een besturingselement zoals een schuifregelaar, tekstvak, enzovoort. IPython-widgets werken alleen in de Python-omgeving. Het wordt nog niet ondersteund in andere talen (bijvoorbeeld Scala, SQL, C#).
IPython Widget gebruiken
U moet eerst de module importeren
ipywidgetsom het Jupyter Widget-framework te gebruiken.import ipywidgets as widgetsU kunt de functie op het hoogste niveau
displaygebruiken om een widget weer te geven of een expressie van het widgettype op de laatste regel van de codecel laten staan.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderVoer de cel uit. De widget wordt weergegeven in het uitvoergebied.
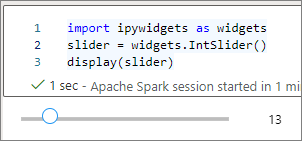
U kunt meerdere
display()aanroepen gebruiken om hetzelfde widgetexemplaar meerdere keren weer te geven, maar deze blijven gesynchroniseerd met elkaar.slider = widgets.IntSlider() display(slider) display(slider)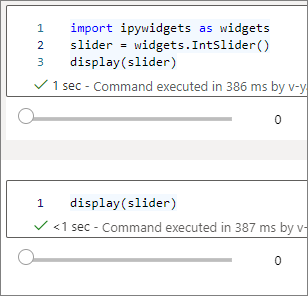
Als u twee widgets onafhankelijk van elkaar wilt weergeven, maakt u twee widgetexemplaren:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
Ondersteunde widgets
| Widgetstype | Widgets |
|---|---|
| Numerieke widgets | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Booleaanse widgets | Wisselknop, selectievakje, geldig |
| Selectiewidgets | Vervolgkeuzelijst, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Tekenreekswidgets | Tekst, tekstgebied, keuzelijst met invoervak, wachtwoord, label, HTML, HTML-wiskunde, afbeelding, knop |
| Widgets afspelen (animatie) | Datumkiezer, Kleurkiezer, Controller |
| Container-/indelingswidgets | Box, HBox, VBox, GridBox, Accordeon, Tabs, Gestapeld |
Bekende beperkingen
De volgende widgets worden nog niet ondersteund. U kunt de bijbehorende tijdelijke oplossing volgen, zoals hieronder:
Functionaliteit Tijdelijke oplossing OutputWidgetU kunt in plaats daarvan de functie gebruiken print()om tekst in stdout te schrijven.widgets.jslink()U kunt de functie gebruiken widgets.link()om twee vergelijkbare widgets te koppelen.FileUploadWidgetNog geen ondersteuning. De globale
displayfunctie van Synapse biedt geen ondersteuning voor het weergeven van meerdere widgets in één aanroep (dat wil gezegd,display(a, b)), wat verschilt van de IPython-functiedisplay.Als u een notitieblok sluit dat IPython Widget bevat, kunt u het pas zien of ermee werken als u de bijbehorende cel opnieuw uitvoert.
Notebooks opslaan
U kunt één notitieblok of alle notitieblokken in uw werkruimte opslaan.
Als u wijzigingen wilt opslaan die u hebt aangebracht in één notitieblok, selecteert u de knop Publiceren op de opdrachtbalk van het notitieblok.

Als u alle notitieblokken in uw werkruimte wilt opslaan, selecteert u de knop Alles publiceren op de opdrachtbalk van de werkruimte.

In de notebookeigenschappen kunt u configureren of u de celuitvoer wilt opnemen bij het opslaan.
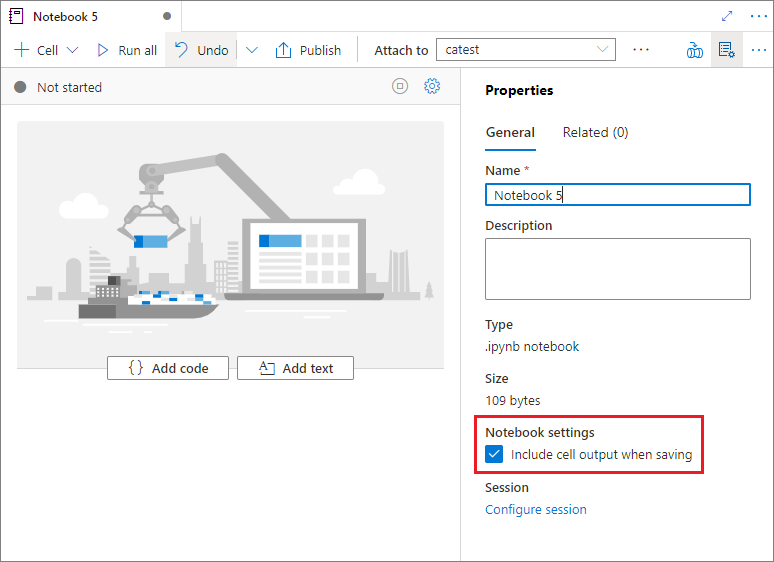
Magic-opdrachten
U kunt bekende Jupyter-magic-opdrachten gebruiken in Synapse-notebooks. Bekijk de volgende lijst als de huidige beschikbare magic-opdrachten. Vertel ons uw gebruiksvoorbeelden op GitHub , zodat we meer magic-opdrachten kunnen ontwikkelen om aan uw behoeften te voldoen.
Notitie
Alleen de volgende magic-opdrachten worden ondersteund in Synapse-pijplijn: %%pyspark, %%spark, %%csharp, %%sql.
Beschikbare regelmagie: %lsmagic, %time, %timeit, %history, %run, %load
Beschikbare celmagie: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Verwijzing naar niet-gepubliceerd notitieblok
Verwijzing naar niet-gepubliceerd notitieblok is handig als u lokaal fouten wilt opsporen, bij het inschakelen van deze functie haalt de notebookuitvoering de huidige inhoud op in de webcache. Als u een cel met een instructie voor verwijzingsnotitieblokken uitvoert, verwijst u naar de presentatienotitieblokken in de huidige notebookbrowser in plaats van naar een opgeslagen versies in het cluster. Dit betekent dat naar de wijzigingen in de notebook-editor onmiddellijk kunnen worden verwezen door andere notebooks zonder dat ze hoeven te worden gepubliceerd (livemodus) of doorgevoerd( Git-modus), kunt u door gebruik te maken van deze benadering eenvoudig voorkomen dat veelvoorkomende bibliotheken vervuild raken tijdens het ontwikkelen of foutopsporingsproces.
U kunt Verwijzing naar niet-gepubliceerd notitieblok inschakelen in het deelvenster Eigenschappen:
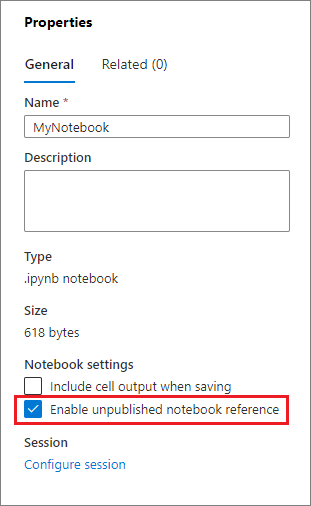
Raadpleeg de onderstaande tabel voor verschillende gevallen:
U ziet dat %run en mssparkutils.notebook.run hier hetzelfde gedrag hebben. We gebruiken %run hier als voorbeeld.
| Case | Uitschakelen | Inschakelen |
|---|---|---|
| Livemodus | ||
- Nb1 (gepubliceerd)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Gepubliceerde versie van Nb1 uitvoeren |
- Nb1 (nieuw)%run Nb1 |
Fout | Nieuwe Nb1 uitvoeren |
- Nb1 (eerder gepubliceerd, bewerkt)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Bewerkte versie van Nb1 uitvoeren |
| Git-modus | ||
- Nb1 (gepubliceerd)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Gepubliceerde versie van Nb1 uitvoeren |
- Nb1 (nieuw)%run Nb1 |
Fout | Nieuwe Nb1 uitvoeren |
- Nb1 (niet gepubliceerd, vastgelegd)%run Nb1 |
Fout | Vastgelegde Nb1 uitvoeren |
- Nb1 (eerder gepubliceerd, vastgelegd)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Vastgelegde versie van Nb1 uitvoeren |
- Nb1 (eerder gepubliceerd, nieuw in current branch)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Nieuwe Nb1 uitvoeren |
- Nb1 (Niet gepubliceerd, eerder vastgelegd, bewerkt)%run Nb1 |
Fout | Bewerkte versie van Nb1 uitvoeren |
- Nb1 (eerder gepubliceerd en doorgevoerd, bewerkt)%run Nb1 |
Gepubliceerde versie van Nb1 uitvoeren | Bewerkte versie van Nb1 uitvoeren |
Conclusie
- Als dit is uitgeschakeld, voert u de gepubliceerde versie altijd uit.
- Als deze optie is ingeschakeld, is de prioriteit: bewerkt/nieuw > vastgelegd > gepubliceerd.
Actief sessiebeheer
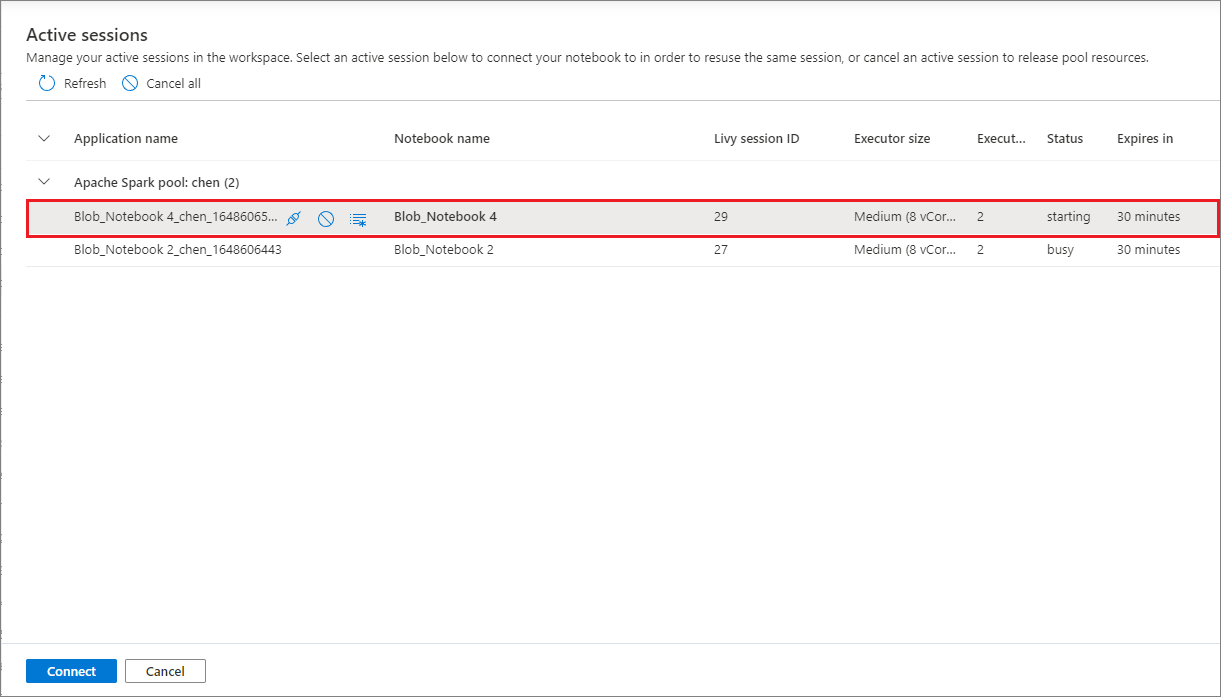
U kunt uw notebooksessies nu gemakkelijk opnieuw gebruiken zonder dat u nieuwe sessies hoeft te starten. Synapse Notebook ondersteunt nu het beheren van uw actieve sessies in de lijst Sessies beheren . U kunt alle sessies in de huidige werkruimte zien die door u zijn gestart vanuit het notitieblok.
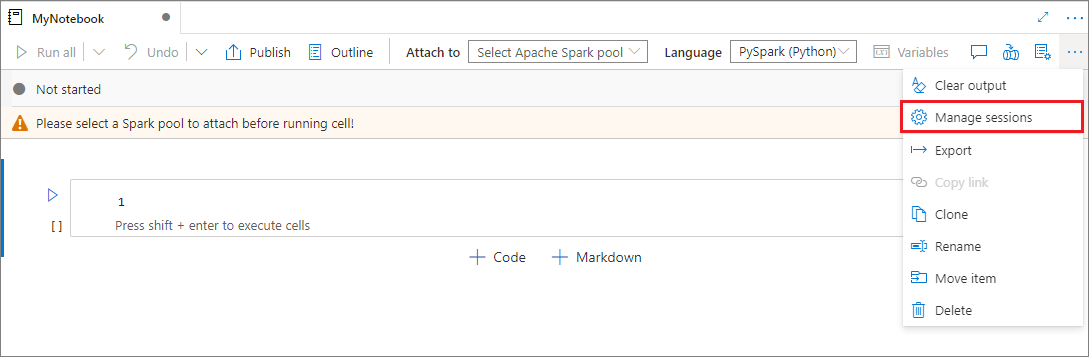
In de lijst Actieve sessies ziet u de sessiegegevens en het bijbehorende notitieblok dat momenteel aan de sessie is gekoppeld. U kunt loskoppelen met notebook, de sessie stoppen en Weergeven in bewaking van hieruit gebruiken. Bovendien kunt u het geselecteerde notitieblok eenvoudig verbinden met een actieve sessie in de lijst die is gestart vanuit een ander notitieblok. De sessie wordt losgekoppeld van het vorige notitieblok (als het niet inactief is) en vervolgens gekoppeld aan het huidige notitieblok.
Python-logboekregistratie in Notebook
U kunt Python-logboeken vinden en verschillende logboekniveaus en -indeling instellen met de onderstaande voorbeeldcode:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Een notebook integreren
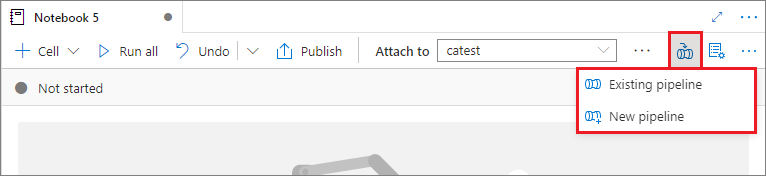
Een notebook toevoegen aan een pijplijn
Selecteer de knop Toevoegen aan pijplijn in de rechterbovenhoek om een notebook toe te voegen aan een bestaande pijplijn of om een nieuwe pijplijn te maken.
Een parametercel toewijzen
Als u uw notitieblok wilt parametriseren, selecteert u het beletselteken (...) voor toegang tot de meer opdrachten op de celwerkbalk. Selecteer vervolgens Parametercel in-/uitschakelen om de cel aan te wijzen als de parametercel.

Azure Data Factory zoekt naar de cel parameters en behandelt deze cel als standaardwaarden voor de parameters die tijdens de uitvoering zijn doorgegeven. De uitvoeringsengine voegt een nieuwe cel toe onder de parametercel met invoerparameters om de standaardwaarden te overschrijven.
Parameterswaarden toewijzen vanuit een pijplijn
Zodra u een notebook met parameters hebt gemaakt, kunt u deze uitvoeren vanuit een pijplijn met de Synapse Notebook-activiteit. Nadat u de activiteit aan uw pijplijncanvas hebt toegevoegd, kunt u de parameterswaarden instellen onder de sectie Basisparameters op het tabblad Instellingen .
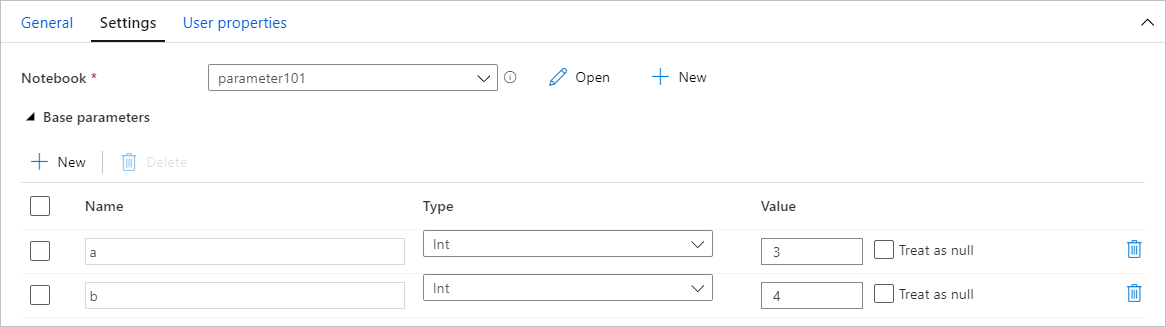
Wanneer u parameterwaarden toewijst, kunt u de pijplijnexpressietaal of systeemvariabelen gebruiken.
Sneltoetsen
Net als bij Jupyter Notebooks hebben Synapse-notebooks een modale gebruikersinterface. Het toetsenbord doet verschillende dingen, afhankelijk van de modus waarin de notebookcel zich bevindt. Synapse-notebooks ondersteunen de volgende twee modi voor een bepaalde codecel: opdrachtmodus en bewerkingsmodus.
Een cel bevindt zich in de opdrachtmodus wanneer er geen tekstcursor is die u vraagt om te typen. Wanneer een cel zich in de opdrachtmodus bevindt, kunt u het notitieblok als geheel bewerken, maar niet in afzonderlijke cellen typen. Ga naar de opdrachtmodus door te drukken
ESCof met de muis te selecteren buiten het editorgebied van een cel.
De bewerkingsmodus wordt aangegeven door een tekstcursor die u vraagt om te typen in het editorgebied. Wanneer een cel zich in de bewerkingsmodus bevindt, kunt u in de cel typen. Bewerk de bewerkingsmodus door op het editorgebied van een cel te drukken
Enterof met de muis te selecteren.
Sneltoetsen in opdrachtmodus
| Actie | Snelkoppelingen voor Synapse-notebooks |
|---|---|
| Voer de huidige cel uit en selecteer hieronder | Shift+Enter |
| De huidige cel uitvoeren en hieronder invoegen | Alt+Enter |
| Huidige cel uitvoeren | Ctrl+Enter |
| Cel boven selecteren | Omhoog |
| Selecteer de cel eronder | Buiten gebruik |
| Vorige cel selecteren | K |
| Volgende cel selecteren | J |
| Cel boven invoegen | A |
| Cel onder invoegen | B |
| Geselecteerde cellen verwijderen | Shift+D |
| Overschakelen naar de bewerkingsmodus | Enter |
Sneltoetsen in bewerkingsmodus
Met behulp van de volgende toetsaanslagsneltoetsen kunt u eenvoudiger navigeren en code uitvoeren in Synapse-notebooks in de bewerkingsmodus.
| Actie | Snelkoppelingen voor Synapse-notebooks |
|---|---|
| Cursor omhoog verplaatsen | Omhoog |
| Cursor omlaag verplaatsen | Buiten gebruik |
| Ongedaan maken | Ctrl+Z |
| Opnieuw uitvoeren | Ctrl+Y |
| Opmerking/opmerking verwijderen | Ctrl + / |
| Woord vóór verwijderen | Ctrl + Backspace |
| Woord na verwijderen | Ctrl + Delete |
| Naar het begin van de cel gaan | Ctrl +Home |
| Naar celeinde gaan | Ctrl +End |
| Eén woord naar links gaan | Ctrl + links |
| Eén woord naar rechts gaan | Ctrl+rechts |
| Alles selecteren | Ctrl+A |
| Streepje | Ctrl +] |
| Dedent | Ctrl + [ |
| Overschakelen naar de opdrachtmodus | Esc |
Volgende stappen
- Bekijk Synapse-voorbeeldnotebooks
- Quickstart: Een Apache Spark-pool maken in Azure Synapse Analytics met behulp van webhulpprogramma's
- Wat is Apache Spark in Azure Synapse Analytics?
- .NET voor Apache Spark gebruiken met Azure Synapse Analytics
- Documentatie voor .NET voor Apache Spark
- Azure Synapse Analytics