Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit cheatsheet bevat nuttige tips en best practices voor het bouwen van toegewezen SQL-pooloplossingen (voorheen SQL DW).
In de volgende afbeelding ziet u het proces voor het ontwerpen van een datawarehouse met een toegewezen SQL-pool (voorheen SQL DW):
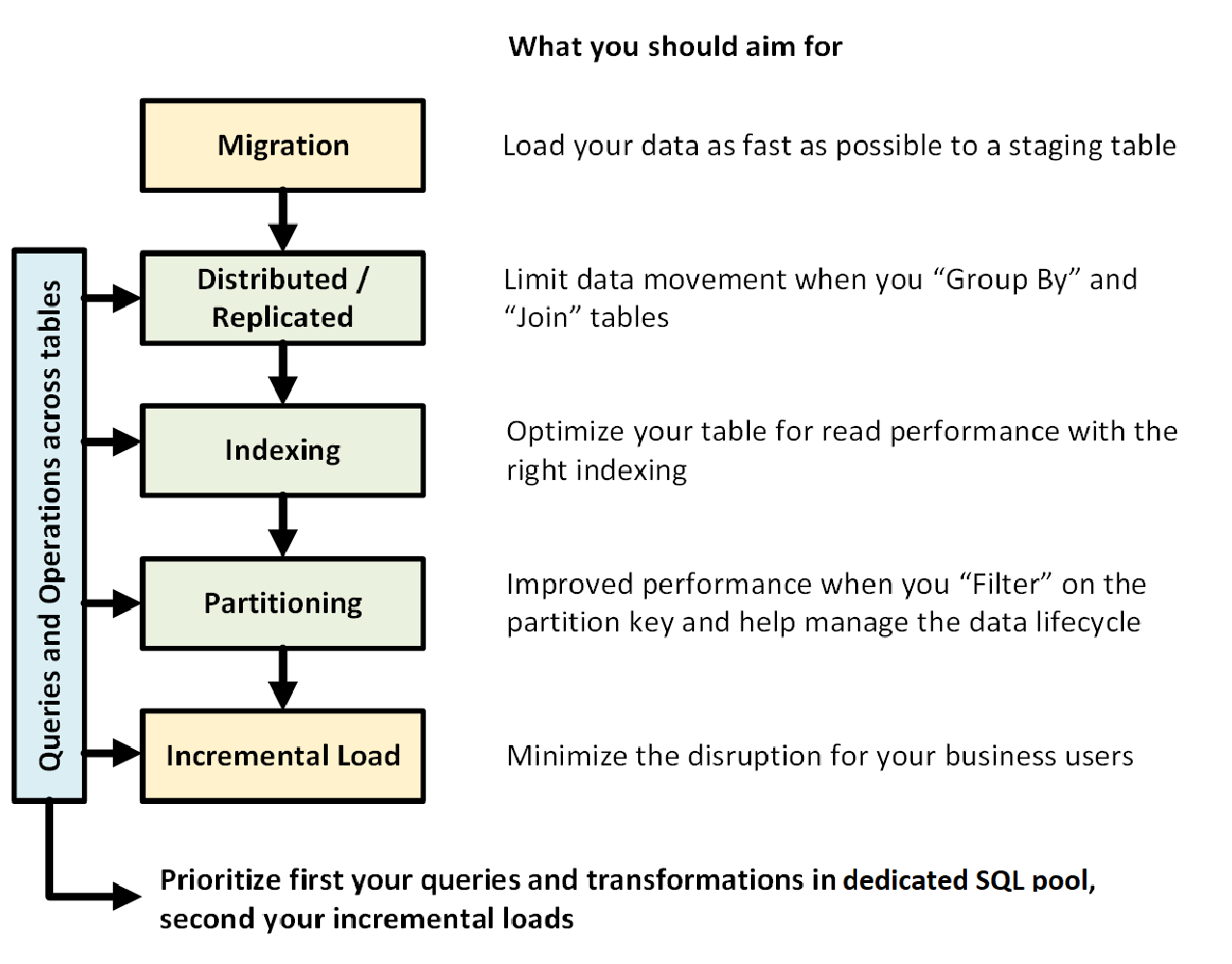
Query's en bewerkingen in tabellen
Wanneer u van tevoren weet welke primaire bewerkingen en query's moeten worden uitgevoerd in uw datawarehouse, kunt u prioriteit geven aan uw datawarehouse-architectuur voor deze bewerkingen. Deze query's en bewerkingen kunnen het volgende omvatten:
- Een of twee feitentabellen samenvoegen met dimensietabellen, de gecombineerde tabel filteren en de resultaten vervolgens toevoegen aan een datamart.
- Grote of kleine updates aanbrengen in uw verkoopgegevens.
- Alleen gegevens toevoegen aan uw tabellen.
Door de typen bewerkingen van tevoren te kennen, kunt u het ontwerp van uw tabellen optimaliseren.
Gegevensmigratie
Laad eerst uw gegevens in Azure Data Lake Storage of Azure Blob Storage. Gebruik vervolgens de COPY-instructie om uw gegevens in faseringstabellen te laden. Gebruik de volgende configuratie:
| Ontwerpen | Aanbeveling |
|---|---|
| Distributie | Round Robin |
| Indexeren | Stapel |
| Partitie | Geen |
| Hulpbronklasse | groter of extra groot |
Meer informatie over gegevensmigratie, het laden van gegevens en het ELT-proces (Extraheren, Laden en Transformeren).
Gedistribueerde of gerepliceerde tabellen
Gebruik de volgende strategieën, afhankelijk van de tabeleigenschappen:
| Typ | Uitstekend geschikt voor... | Kijk uit als... |
|---|---|---|
| Gekopieerd | * Kleine dimensietabellen in een stervormig schema met minder dan 2 GB opslagruimte na compressie (~5x compressie) | * Veel schrijftransacties bevinden zich in een tabel (zoals invoegen, upsert, verwijderen, bijwerken) * U wijzigt de inrichting van datawarehouse-eenheden (DWU) regelmatig * U gebruikt slechts 2-3 kolommen, maar uw tabel bevat veel kolommen * U indexeer een gerepliceerde tabel |
| Round Robin (standaard) | * Tijdelijke/faseringstabel * Geen duidelijke samenvoegsleutel of goede kandidaatkolom |
* Prestaties zijn traag vanwege gegevensverplaatsing |
| Hash | * Feitentabellen * Grote dimensietabellen |
* De distributiesleutel kan niet worden bijgewerkt |
Tips:
- Begin met Round Robin, maar streven naar een hash-distributiestrategie om te profiteren van een zeer parallelle architectuur.
- Zorg ervoor dat algemene hashsleutels dezelfde gegevensindeling hebben.
- Distribueer niet in varchar-formaat.
- Dimensietabellen met een gemeenschappelijke hash-sleutel naar een feitentabel met frequente joinbewerkingen kunnen hash-gedistribueerd worden.
- Gebruik sys.dm_pdw_nodes_db_partition_stats om eventuele scheefheid in de gegevens te analyseren.
- Gebruik sys.dm_pdw_request_steps om gegevensverplaatsingen achter query's te analyseren, de tijd die uitzenden en shuffle-bewerkingen duren te monitoren. Dit is handig om uw distributiestrategie te controleren.
Meer informatie over gerepliceerde tabellen en gedistribueerde tabellen.
De tabel indexeren
Indexering is handig voor het snel lezen van tabellen. Er is een unieke set technologieën die u kunt gebruiken op basis van uw behoeften:
| Typ | Uitstekend geschikt voor... | Kijk uit als... |
|---|---|---|
| Stapel | * Fasering/tijdelijke tabel * Kleine tabellen met kleine zoekacties |
* Elke zoekopdracht scant de volledige tabel |
| Geclusterde index | * Tabellen met maximaal 100 miljoen rijen * Grote tabellen (meer dan 100 miljoen rijen) met slechts 1-2 kolommen die intensief worden gebruikt |
* Wordt gebruikt in een gerepliceerde tabel * U hebt complexe query's met betrekking tot meerdere join- en Group By-bewerkingen * U voert updates uit voor de geïndexeerde kolommen: het kost geheugen |
| Geclusterd columnstore-index (CCI) (standaardinstelling) | * Grote tabellen (meer dan 100 miljoen rijen) | * Wordt gebruikt in een gerepliceerde tabel * U maakt grootschalige updatebewerkingen op uw tabel * U overdeelt de tabel: rijgroepen zijn niet verdeeld over verschillende distributieknooppunten en partities |
Tips:
- Boven op een geclusterde index wilt u mogelijk een niet-geclusterde index toevoegen aan een kolom die intensief wordt gebruikt voor filteren.
- Wees voorzichtig met het beheren van het geheugen op een tabel met CCI. Wanneer u gegevens laadt, wilt u dat de gebruiker (of de query) profiteert van een grote resourceklasse. Zorg ervoor dat u het afknippen en het maken van veel kleine, samengeperste rijgroepen vermijdt.
- Op Gen2 worden CCI-tabellen lokaal in de cache opgeslagen op de rekenknooppunten om de prestaties te maximaliseren.
- Voor CCI kunnen trage prestaties optreden door slechte compressie van uw rijgroepen. Als dit het geval is, bouwt u uw CCI opnieuw op of herorganiseert u deze. U wilt ten minste 100.000 rijen per gecomprimeerde rijgroep. Het ideale is 1 miljoen rijen in een rijgroep.
- Op basis van de frequentie en grootte van incrementele belasting wilt u automatiseren wanneer u uw indexen opnieuw ordent of herbouwt. Lente schoonmaken is altijd nuttig.
- Wees strategisch wanneer u een rijgroep wilt knippen. Hoe groot zijn de open rijgroepen? Hoeveel gegevens verwacht u in de komende dagen te laden?
Meer informatie over indexen.
Partitie
U kunt uw tabel partitioneren wanneer u een grote feitentabel hebt (meer dan 1 miljard rijen). In 99 procent van de gevallen moet de partitiesleutel zijn gebaseerd op de datum.
Met faseringstabellen waarvoor ELT is vereist, kunt u profiteren van partitionering. Het vereenvoudigt het beheer van de levenscyclus van gegevens. Wees voorzichtig met het overpartitioneren van uw feiten- of faseringstabel, met name op een geclusterde columnstore-index.
Meer informatie over partities.
Stapsgewijze lading
Als u uw gegevens incrementeel gaat laden, moet u eerst grotere resourceklassen toewijzen om uw gegevens te laden. Dit is met name belangrijk bij het laden in tabellen met geclusterde columnstore-indexen. Zie resourceklassen voor meer informatie.
We raden u aan PolyBase en ADF V2 te gebruiken voor het automatiseren van uw ELT-pijplijnen in uw datawarehouse.
Voor een grote reeks updates in uw historische gegevens kunt u overwegen een CTAS te gebruiken om de gegevens te schrijven die u in een tabel wilt bewaren in plaats van INSERT, UPDATE en DELETE te gebruiken.
Statistieken bijhouden
Het is belangrijk om statistieken bij te werken naarmate er belangrijke wijzigingen in uw gegevens optreden. Zie updatestatistieken om te bepalen of er belangrijke wijzigingen zijn opgetreden. Bijgewerkte statistieken optimaliseren uw queryplannen. Als u merkt dat het te lang duurt om al uw statistieken bij te houden, moet u selectiever zijn over welke kolommen statistieken hebben.
U kunt ook de frequentie van de updates definiëren. U kunt bijvoorbeeld datumkolommen bijwerken, waarbij nieuwe waarden dagelijks kunnen worden toegevoegd. U krijgt het meeste voordeel door statistieken te hebben over kolommen die betrokken zijn bij joins, kolommen die worden gebruikt in de WHERE-component en kolommen in GROUP BY.
Meer informatie over statistieken.
Hulpbronklasse
Resourcegroepen worden gebruikt als een manier om geheugen toe te wijzen aan query's. Als u meer geheugen nodig hebt om de query- of laadsnelheid te verbeteren, moet u hogere resourceklassen toewijzen. Aan de andere kant heeft het gebruik van grotere resourceklassen invloed op de paralleliteit. U wilt dit in overweging nemen voordat u al uw gebruikers naar een grote resourceklasse verplaatst.
Als u merkt dat query's te lang duren, kunt u controleren of uw gebruikers geen grote resourceklassen gebruiken. Grote resourceklassen verbruiken veel gelijktijdigheidssleuven. Ze kunnen ertoe leiden dat andere query's in de wachtrij worden geplaatst.
Ten slotte krijgt elke resourceklasse met behulp van Gen2 van toegewezen SQL-pool (voorheen SQL DW) 2,5 keer meer geheugen dan Gen1.
Meer informatie over het werken met resourceklassen en gelijktijdigheid.
Verlaag uw kosten
Een belangrijke functie van Azure Synapse is de mogelijkheid om rekenresources te beheren. U kunt uw toegewezen SQL-pool (voorheen SQL DW) onderbreken wanneer u deze niet gebruikt, waardoor de facturering van rekenresources wordt gestopt. U kunt middelen schalen om aan uw prestatievereisten te voldoen. Gebruik De Azure-portal of PowerShell om te onderbreken. Als u de schaal wilt aanpassen, gebruikt u Azure Portal, PowerShell, T-SQL of een REST API.
Automatisch schalen op het moment dat u wilt met Azure Functions:

Uw architectuur optimaliseren voor prestaties
We raden u aan om SQL Database en Azure Analysis Services te overwegen in een hub-en-spoke-architectuur. Deze oplossing kan isolatie van werkbelastingen bieden tussen verschillende gebruikersgroepen, terwijl ook geavanceerde beveiligingsfuncties van SQL Database en Azure Analysis Services worden gebruikt. Dit is ook een manier om uw gebruikers onbeperkte gelijktijdigheid te bieden.
Meer informatie over typische architecturen die gebruikmaken van een toegewezen SQL-pool (voorheen SQL DW) in Azure Synapse Analytics.
Implementeer uw spokes in SQL-databases vanuit een toegewezen SQL-pool (voorheen SQL DW):