Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Microsoft Fabric Data Warehouse is een relationeel warehouse op ondernemingsniveau op data lake-basis, met een architectuur die klaar is voor de toekomst, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensopslag, begin dan met Fabric Data Warehouse. Bestaande dediceerde SQL-poolworkloads kunnen upgraden naar Fabric voor toegang tot nieuwe mogelijkheden in data science, realtime analyses en rapportage.
Een externe tabel verwijst naar gegevens in Hadoop, Azure Storage-blob of Azure Data Lake Storage (ADLS).
U kunt externe tabellen gebruiken om gegevens uit bestanden te lezen of gegevens naar bestanden te schrijven in Azure Storage. Met Azure Synapse SQL kunt u externe tabellen gebruiken om externe gegevens te lezen met behulp van een toegewezen SQL-pool of een serverloze SQL-pool.
Afhankelijk van het type externe gegevensbron kunt u twee typen externe tabellen gebruiken:
- Externe Hadoop-tabellen die u kunt gebruiken voor het lezen en exporteren van gegevens in verschillende gegevensindelingen, zoals CSV, Parquet en ORC. Externe Hadoop-tabellen zijn beschikbaar in toegewezen SQL-pools, maar zijn niet beschikbaar in serverloze SQL-pools.
- Systeemeigen externe tabellen die u kunt gebruiken voor het lezen en exporteren van gegevens in verschillende gegevensindelingen, zoals CSV en Parquet. Systeemeigen externe tabellen zijn beschikbaar in serverloze SQL-pools en in toegewezen SQL-pools. Het schrijven/exporteren van gegevens met CETAS en de systeemeigen externe tabellen is alleen beschikbaar in de serverloze SQL-pool, maar niet in de toegewezen SQL-pools.
De belangrijkste verschillen tussen Hadoop en systeemeigen externe tabellen:
| Externe tabeltype | Hadoop | Native |
|---|---|---|
| Toegewezen SQL-pool | Beschikbaar | Alleen parket |
| Serverloze SQL-pool | Niet beschikbaar | Beschikbaar |
| Ondersteunde indelingen | Gescheiden/CSV, Parquet, ORC, Hive RC en RC | Serverloze SQL-pool: gescheiden/CSV, Parquet en Delta Lake Toegewezen SQL-pool: Parquet |
| Verwijdering van mappartitie | Nee | Partitieuitschakeling is alleen beschikbaar in de gepartitioneerde tabellen die zijn gemaakt in Parquet- of CSV-indelingen die worden gesynchroniseerd vanuit Apache Spark-pools. U kunt externe tabellen maken in gepartitioneerde mappen in Parquet, maar de partitioneringskolommen zijn niet toegankelijk en genegeerd, terwijl de partitieverwijdering niet wordt toegepast. Maak geen externe tabellen in Delta Lake-mappen omdat ze niet worden ondersteund. Gebruik gepartitioneerde Delta-weergaven als u een query wilt uitvoeren op gepartitioneerde Delta Lake-gegevens. |
| Bestandsverwijdering (predicaat pushdown) | Nee | Ja in serverloze SQL-pool. Voor de tekenreeks pushdown moet u collatie gebruiken op de Latin1_General_100_BIN2_UTF8 kolommen om pushdown in te schakelen. Zie de ondersteuning voor databasesortering voor Synapse SQL in Azure Synapse Analytics voor meer informatie over sorteringen. |
| Aangepaste indeling voor locatie | Nee | Ja, wildcards gebruiken, zoals /year=*/month=*/day=* voor Parquet- of CSV-formaten. Aangepaste mappaden zijn niet beschikbaar in Delta Lake. In de serverloze SQL-pool kunt u ook recursieve jokertekens /logs/** gebruiken om te verwijzen naar Parquet- of CSV-bestanden in een submap onder de map waarnaar wordt verwezen. |
| Recursieve scan van mappen | Ja | Ja. In serverloze SQL-pools moet aan het einde van het locatiepad worden opgegeven /** . In toegewezen pool worden de mappen altijd recursief gescand. |
| Opslagverificatie | Opslagtoegangssleutel (SAK), Microsoft Entra passthrough, beheerde identiteit, aangepaste toepassing Microsoft Entra-identiteit | Shared Access Signature (SAS), Microsoft Entra passthrough, Beheerde identiteit, Aangepaste toepassing Microsoft Entra-identiteit. |
| Kolomtoewijzing | Ordinaal: de kolommen in de definitie van de externe tabel worden op positie toegewezen aan de kolommen in de onderliggende Parquet-bestanden. | Serverloze pool: volgens naam. De kolommen in de definitie van de externe tabel worden toegewezen aan de kolommen in de onderliggende Parquet-bestanden door overeenkomende kolomnamen. Toegewezen pool: rangschikkering. De kolommen in de definitie van de externe tabel worden op positie toegewezen aan de kolommen in de onderliggende Parquet-bestanden. |
| CETAS (exporteren/transformeren) | Ja | CETAS met de systeemeigen tabellen als doel werkt alleen in de serverloze SQL-pool. U kunt de toegewezen SQL-pools niet gebruiken om gegevens te exporteren met behulp van systeemeigen tabellen. |
Notitie
De systeemeigen externe tabellen zijn de aanbevolen oplossing in de pools waar ze algemeen beschikbaar zijn. Als u toegang nodig hebt tot externe gegevens, gebruikt u altijd de systeemeigen tabellen in serverloze of toegewezen pools. Gebruik de Hadoop-tabellen alleen als u toegang nodig hebt tot bepaalde typen die niet worden ondersteund in systeemeigen externe tabellen (bijvoorbeeld ORC, RC) of als de systeemeigen versie niet beschikbaar is.
Externe tabellen in een toegewezen SQL-pool en een serverloze SQL-pool
U kunt externe tabellen gebruiken om het volgende te doen:
- Query's uitvoeren op Azure Blob Storage en ADLS Gen2 met Transact-SQL-instructies.
- Sla queryresultaten op in bestanden in Azure Blob Storage of Azure Data Lake Storage met behulp van CETAS met Synapse SQL.
- Importeer gegevens uit Azure Blob Storage en Azure Data Lake Storage en sla deze op in een toegewezen SQL-pool (alleen Hadoop-tabellen in toegewezen pool).
Notitie
Wanneer u deze gebruikt met de instructie CREATE TABLE AS SELECT , importeert u gegevens uit een externe tabel in een tabel in de toegewezen SQL-pool.
Als de prestaties van externe Hadoop-tabellen in de toegewezen pools niet voldoen aan uw prestatiedoelen, kunt u overwegen externe gegevens in de datawarehouse-tabellen te laden met behulp van de COPY-instructie.
Raadpleeg PolyBase gebruiken om gegevens vanuit Azure Blob Storage te laden voor een zelfstudie over het laden van gegevens.
U kunt externe tabellen maken in Synapse SQL-pools via de volgende stappen:
- CREATE EXTERNAL DATA SOURCE om te verwijzen naar een externe Azure-opslag en geef de referentie op die moet worden gebruikt voor toegang tot de opslag.
- CREATE EXTERNAL FILE FORMAT om het formaat van CSV- of Parquet-bestanden te beschrijven.
- CREATE EXTERNAL TABLE bovenop de bestanden die op de gegevensbron zijn geplaatst met dezelfde bestandsindeling.
Verwijdering van mappartitie
De systeemeigen externe tabellen in Synapse-pools kunnen de bestanden negeren die zijn geplaatst in de mappen die niet relevant zijn voor de query's. Als uw bestanden zijn opgeslagen in een maphiërarchie (bijvoorbeeld - /year=2020/month=03/day=16) en de waarden voor year, month, en day worden weergegeven als de kolommen, worden de queries die filters bevatten, zoals year=2020, alleen gelezen van de submappen die zich binnen de year=2020 map bevinden. De bestanden en mappen die in andere mappen (year=2021 of year=2022) worden geplaatst, worden in deze query genegeerd. Deze verwijdering wordt partitie-verwijdering genoemd.
De verwijdering van de mappartitie is beschikbaar in de systeemeigen externe tabellen die worden gesynchroniseerd vanuit de Synapse Spark-pools. Als u een gepartitioneerde gegevensset hebt en u de partitieuitschakeling wilt gebruiken met de externe tabellen die u maakt, gebruikt u de gepartitioneerde weergaven in plaats van de externe tabellen.
Bestandsverwijdering
Sommige gegevensindelingen, zoals Parquet en Delta, bevatten bestandsstatistieken voor elke kolom (bijvoorbeeld min/max-waarden voor elke kolom). De query's die gegevens filteren, lezen niet de bestanden waarin de vereiste kolomwaarden niet bestaan. De query verkent eerst min/max-waarden voor de kolommen die in het querypredicaat worden gebruikt om de bestanden te vinden die niet de vereiste gegevens bevatten. Deze bestanden worden genegeerd en verwijderd uit het queryplan.
Deze techniek staat ook bekend als filter-predicate pushdown en kan de prestaties van uw query's verbeteren. Filter pushdown is beschikbaar in de serverloze SQL-pools voor de indelingen Parquet en Delta. Als u filterpushdown wilt toepassen voor de stringtypen, gebruikt u het VARCHAR-type met de Latin1_General_100_BIN2_UTF8 collatie. Zie de ondersteuning voor databasesortering voor Synapse SQL in Azure Synapse Analytics voor meer informatie over sorteringen.
Beveiliging
De gebruiker moet gemachtigd zijn SELECT voor een externe tabel om de gegevens te kunnen lezen.
Externe tabellen kunnen toegang krijgen tot de onderliggende Azure-opslag met de database-brede referentie die in de gegevensbron is gedefinieerd, volgens de volgende regels:
- Een gegevensbron zonder referenties stelt externe tabellen in staat om toegang te krijgen tot openbaar beschikbare bestanden in Azure Storage.
- Gegevensbron kan een referentie hebben die externe tabellen in staat stelt alleen toegang te krijgen tot de bestanden in Azure Storage met behulp van een SAS-token of de Managed Identity van de werkruimte. Zie voor voorbeelden het artikel Opslagbestanden opslagtoegangsbeheer ontwikkelen.
Opmerkingen
Om een betrouwbare uitvoering van query's te garanderen, moeten de bronbestanden en mappen waarnaar wordt verwezen door externe tabellen, ongewijzigd blijven gedurende de duur van de bewerking.
- Het wijzigen, verwijderen of vervangen van eventuele bestanden of mappen waarnaar wordt verwezen terwijl de query wordt uitgevoerd, kan leiden tot fouten of leiden tot inconsistente resultaten.
- Controleer voordat u een query uitvoert op externe tabellen in een toegewezen SQL-pool of alle brongegevens stabiel zijn en niet worden gewijzigd tijdens de uitvoering.
Voorbeeld van CREATE EXTERNAL DATA SOURCE
In het volgende voorbeeld wordt een externe Hadoop-gegevensbron gemaakt in een toegewezen SQL-pool voor ADLS Gen2 die verwijst naar de openbare gegevensset in New York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
In het volgende voorbeeld wordt een externe gegevensbron voor ADLS Gen2 gemaakt die verwijst naar de openbaar beschikbare Gegevensset new York:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Voorbeeld voor CREATE EXTERNAL FILE FORMAT
In het volgende voorbeeld wordt een externe bestandsindeling gemaakt voor volkstellingsbestanden:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Voorbeeld van CREATE EXTERNAL TABLE
In het volgende voorbeeld wordt een externe tabel gemaakt. Hiermee wordt de eerste rij geretourneerd:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Externe tabellen maken en hierop query's uitvoeren via een bestand in Azure Data Lake
Met data Lake-verkenningsmogelijkheden van Synapse Studio kunt u nu een externe tabel maken en er query's op uitvoeren met behulp van synapse SQL-pool met een rechtermuisknop op het bestand. De mogelijkheid om vanuit het ADLS Gen2-opslagaccount met één klik externe tabellen te maken wordt alleen ondersteund voor Parquet-bestanden.
Vereisten
U moet toegang hebben tot de werkruimte met ten minste de
Storage Blob Data Contributortoegangsrol voor het ADLS Gen2-account of toegangsbeheerlijsten (ACL) waarmee u query's kunt uitvoeren op de bestanden.U moet ten minste machtigingen hebben om een externe tabel te maken en externe tabellen op te vragen in de Synapse SQL-pool (toegewezen of serverloos).
Selecteer in het deelvenster Gegevens het bestand waaruit u de externe tabel wilt maken:

Er wordt een dialoogvenster geopend. Selecteer toegewezen SQL-pool of serverloze SQL-pool, geef de tabel een naam en selecteer Script openen:
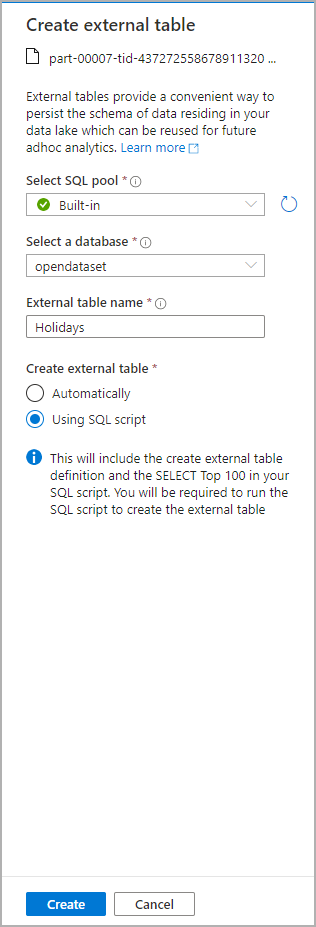
Het SQL-script wordt automatisch gegenereerd, waarbij het schema wordt afgeleid van het bestand:

Voer het script uit. Het script voert automatisch een SELECT TOP 100 *:

De externe tabel is nu gemaakt. U kunt nu rechtstreeks vanuit het deelvenster Gegevens een query uitvoeren op de externe tabel.
Gerelateerde inhoud
Zie het CETAS-artikel voor het opslaan van queryresultaten in een externe tabel in Azure Storage. U kunt ook beginnen met het uitvoeren van query's op externe tabellen van Apache Spark voor Azure Synapse.