Configuratieopties om netwerklatentie met SAP-toepassingen te minimaliseren
Belangrijk
In november 2021 hebben we belangrijke wijzigingen aangebracht in de manier waarop nabijheidsplaatsingsgroepen moeten worden gebruikt met SAP-workload in zonegebonden implementaties.
SAP-toepassingen op basis van de SAP NetWeaver- of SAP S/4HANA-architectuur zijn gevoelig voor netwerklatentie tussen de SAP-toepassingslaag en de SAP-databaselaag. Deze gevoeligheid is het resultaat van de meeste bedrijfslogica die wordt uitgevoerd in de toepassingslaag. Omdat de SAP-toepassingslaag de bedrijfslogica uitvoert, geeft deze query's uit naar de databaselaag met een hoge frequentie, met een snelheid van duizenden of tienduizenden per seconde. In de meeste gevallen is de aard van deze query's eenvoudig. Ze kunnen vaak worden uitgevoerd op de databaselaag in 500 microseconden of minder.
De tijd die is besteed aan het netwerk voor het verzenden van een dergelijke query van de toepassingslaag naar de databaselaag en het ontvangen van het resultaat dat wordt teruggestuurd, heeft een grote invloed op de tijd die nodig is om bedrijfsprocessen uit te voeren. Deze gevoeligheid voor netwerklatentie is waarom u mogelijk een bepaalde minimale netwerklatentie in SAP-implementatieprojecten wilt bereiken. Zie SAP-opmerking #1100926 - Veelgestelde vragen: Netwerkprestaties voor richtlijnen voor het classificeren van de netwerklatentie.
In veel Azure-regio's is het aantal datacenters gegroeid. Tegelijkertijd gebruiken klanten, met name voor geavanceerde SAP-systemen, meer speciale VM-families, zoals Mv2 of Mv3-familie en nieuwer. Deze typen virtuele Azure-machines zijn niet altijd beschikbaar in elk van de datacenters die in een Azure-regio worden verzameld. Deze feiten kunnen mogelijkheden creëren voor het optimaliseren van netwerklatentie tussen de SAP-toepassingslaag en de SAP DBMS-laag.
Azure biedt verschillende implementatieopties voor SAP-workloads. Voor het gekozen implementatietype hebt u opties om de netwerklatentie te optimaliseren, indien nodig. Gedetailleerde informatie over elke optie wordt uitgebreid beschreven in de volgende secties in dit artikel:
Nabijheidsplaatsingsgroepen
Nabijheidsplaatsingsgroepen maken het mogelijk om verschillende VM-typen onder één netwerkstekel te groeperen, waardoor een optimale lage netwerklatentie tussen beide wordt gegarandeerd. Wanneer de eerste VM wordt geïmplementeerd in nabijheidsplaatsingsgroep, wordt die VM gebonden aan een specifieke netwerkstekel. Aangezien alle andere VM's die in dezelfde nabijheidsplaatsingsgroep worden geïmplementeerd, worden deze VM's gegroepeerd onder dezelfde netwerkstekel. Zo aantrekkelijk als dit prospect klinkt, introduceert het gebruik van de constructie ook enkele beperkingen en valkuilen:
- U kunt er niet van uitgaan dat alle azure-VM-typen beschikbaar zijn in alle Azure-datacenters of in elk netwerk. Als gevolg hiervan kan de combinatie van verschillende VM-typen binnen één nabijheidsplaatsingsgroep ernstig worden beperkt. Deze beperkingen treden op omdat de hosthardware die nodig is om een bepaald VM-type uit te voeren mogelijk niet aanwezig is in het datacenter of onder de netwerkstekel waaraan de nabijheidsplaatsingsgroep is toegewezen
- Wanneer u de grootte van onderdelen van de VM's binnen één nabijheidsplaatsingsgroep wijzigt, kunt u er niet automatisch van uitgaan dat in alle gevallen het nieuwe VM-type beschikbaar is in hetzelfde datacenter of onder de netwerkstekel waaraan de nabijheidsplaatsingsgroep is toegewezen
- Omdat Azure hardware buiten bedrijf zet, kan het afdwingen dat bepaalde VM's van een nabijheidsplaatsingsgroep in een ander Azure-datacenter of een andere netwerkstekel worden geplaatst. Lees het document Nabijheidsplaatsingsgroepen voor meer informatie over dit geval
Belangrijk
Als gevolg van de mogelijke beperkingen mogen nabijheidsplaatsingsgroepen alleen worden gebruikt:
- Indien nodig in bepaalde scenario's (zie later)
- Wanneer de netwerklatentie tussen de toepassingslaag en de DBMS-laag te hoog is en van invloed is op de workload
- Alleen op granulariteit van één SAP-systeem en niet voor een heel systeemlandschap of een compleet SAP-landschap
- Op een manier om de verschillende VM-typen en het aantal VM's binnen een nabijheidsplaatsingsgroep tot een minimum te houden
De scenario's waarin nabijheidsplaatsingsgroepen kunnen worden gebruikt om de netwerklatentie te optimaliseren:
- U wilt de kritieke resources van uw SAP-workload implementeren in verschillende beschikbaarheidszones en daarentegen moeten VM's van de toepassingslaag worden verdeeld over verschillende foutdomeinen met behulp van beschikbaarheidssets in elk van de zones. In dit geval, zoals later beschreven in het document, zijn nabijheidsplaatsingsgroepen de benodigde lijm.
- U implementeert de SAP-workload met beschikbaarheidssets. Waar de SAP-databaselaag, de SAP-toepassingslaag en ASCS/SCS-VM's zijn gegroepeerd in drie verschillende beschikbaarheidssets. In dat geval wilt u ervoor zorgen dat de beschikbaarheidssets niet worden verspreid over de volledige Azure-regio, omdat dit, afhankelijk van de Azure-regio, kan leiden tot netwerklatentie die een negatieve invloed kan hebben op de SAP-werkbelasting.
- U gebruikt nabijheidsplaatsingsgroepen om VM's samen te groeperen om de laagst mogelijke netwerklatentie te bereiken tussen de services die worden gehost in de VM's. Latentie binnen een beschikbaarheidszone voldoet bijvoorbeeld niet aan de toepassingsvereisten.
Net als bij implementatiescenario 2, in veel regio's, met name regio's zonder beschikbaarheidszones en de meeste regio's met beschikbaarheidszones, is de netwerklatentie onafhankelijk van waar de VM's worden geaccepteerd. Hoewel er enkele regio's van Azure zijn die niet voldoende goede ervaring kunnen bieden zonder de drie verschillende beschikbaarheidssets te combineren zonder gebruik te maken van nabijheidsplaatsingsgroepen.
Wat zijn nabijheidsplaatsingsgroepen?
Een Azure-nabijheidsplaatsingsgroep is een logische constructie. Wanneer een nabijheidsplaatsingsgroep is gedefinieerd, is deze gebonden aan een Azure-regio en een Azure-resourcegroep. Wanneer VM's worden geïmplementeerd, wordt naar een nabijheidsplaatsingsgroep verwezen door:
- De eerste Azure-VM die is geïmplementeerd onder een netwerkstekel met veel Azure-rekeneenheden en lage netwerklatentie. Een dergelijke netwerkstekel komt vaak overeen met één Azure-datacenter. U kunt de eerste virtuele machine beschouwen als een 'bereik-VM' die wordt geïmplementeerd in een rekenschaaleenheid op basis van Azure-toewijzingsalgoritmen die uiteindelijk worden gecombineerd met implementatieparameters.
- Alle volgende VM's die verwijzen naar de nabijheidsplaatsingsgroep, worden geïmplementeerd onder dezelfde netwerkstekel als de eerste virtuele machine.
Notitie
Als er geen hosthardware is geïmplementeerd die een specifiek VM-type kan uitvoeren onder de netwerkstekel waar de eerste VM is geplaatst, slaagt de implementatie van het aangevraagde VM-type niet. U krijgt een foutbericht met een toewijzingsfout dat aangeeft dat de VIRTUELE machine niet kan worden ondersteund binnen de perimeter van de nabijheidsplaatsingsgroep.
Als u het risico van het bovenstaande wilt verminderen, wordt u aangeraden de intentieoptie te gebruiken bij het maken van de nabijheidsplaatsingsgroep. Met de intentieoptie kunt u de VM-typen weergeven die u wilt opnemen in de nabijheidsplaatsingsgroep. Deze lijst met VM-typen wordt gebruikt om het beste datacenter te vinden dat als host fungeert voor deze VM-typen. Als een dergelijk datacenter wordt gevonden, wordt de PPG gemaakt en is het bereik voor het datacenter dat voldoet aan de VEREISTEN van de VM-SKU. Als er geen dergelijk datacentrum is gevonden, mislukt het maken van de nabijheidsplaatsingsgroep. Meer informatie vindt u in de documentatie PPG - Intentie gebruiken om VM-grootten op te geven. Houd er rekening mee dat werkelijke capaciteitssituaties niet in aanmerking worden genomen bij de controles die worden geactiveerd door de intentieoptie. Als gevolg hiervan kunnen er nog steeds toewijzingsfouten zijn die zijn geroot in onvoldoende capaciteit die beschikbaar is.
Aan één Azure-resourcegroep kunnen meerdere nabijheidsplaatsingsgroepen zijn toegewezen. Maar een nabijheidsplaatsingsgroep kan worden toegewezen aan slechts één Azure-resourcegroep.
Zie de beschikbare documentatie voor meer informatie en implementatievoorbeelden van nabijheidsplaatsingsgroepen.
Nabijheidsplaatsingsgroepen met zonegebonden implementaties
Het is belangrijk om een redelijk lage netwerklatentie te bieden tussen de SAP-toepassingslaag en de DBMS-laag. In de meeste gevallen voldoet een zonegebonden implementatie alleen aan deze vereiste. Voor een beperkte set scenario's voldoet een zonegebonden implementatie mogelijk niet aan de vereisten voor toepassingslatentie. Voor dergelijke situaties is de plaatsing van vm's zo dicht mogelijk vereist en is een redelijk lage netwerklatentie mogelijk. Er kan een Azure-nabijheidsplaatsingsgroep worden gedefinieerd voor een dergelijk SAP-systeem.
Vermijd het bundelen van verschillende SAP-productie- of niet-productiesystemen in één nabijheidsplaatsingsgroep. Vermijd bundels van SAP-systemen omdat hoe meer systemen u groepeert in een nabijheidsplaatsingsgroep, hoe hoger de kans:
- U hebt een VM-type nodig dat niet beschikbaar is onder de netwerkstekel waaraan de nabijheidsplaatsingsgroep is toegewezen.
- Deze resources van niet-domein-VM's, zoals VM's uit de M-serie, kunnen uiteindelijk niet worden uitgevoerd wanneer u het aantal VIRTUELE machines in een nabijheidsplaatsingsgroep in de loop van de tijd moet uitbreiden.
Op basis van veel verbeteringen die door Microsoft in de Azure-regio's zijn geïmplementeerd om de netwerklatentie binnen een Beschikbaarheidszone van Azure te verminderen, ziet de implementatierichtlijnen bij het gebruik van nabijheidsplaatsingsgroepen voor zonegebonden implementaties er als volgt uit:
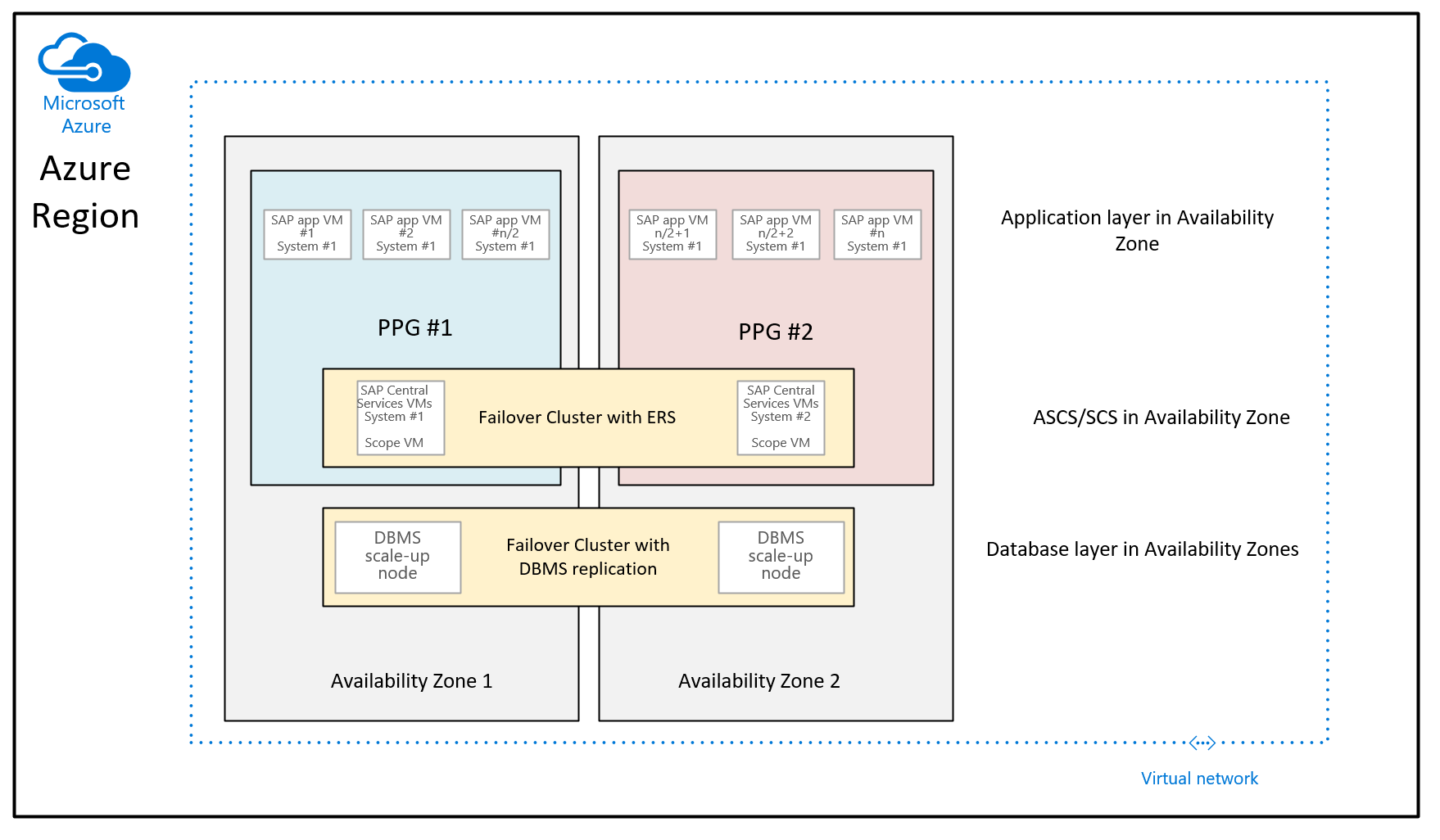
Het verschil met de aanbeveling die tot nu toe is gegeven, is dat de database-VM's in de twee zones geen deel meer uitmaken van de nabijheidsplaatsingsgroepen. De nabijheidsplaatsingsgroepen per zone zijn nu afgestemd op de implementatie van de VIRTUELE machine waarop de SAP ASCS/SCS-exemplaren worden uitgevoerd. Dit betekent ook dat voor de regio's waar beschikbaarheidszones worden verzameld door meerdere datacenters, het ASCS/SCS-exemplaar en de toepassingslaag kunnen worden uitgevoerd onder één netwerkstekel en de database-VM's kunnen worden uitgevoerd onder een andere netwerkstekel. Hoewel de netwerkverbeteringen zijn aangebracht, moet de netwerklatentie tussen de SAP-toepassingslaag en de DBMS-laag nog steeds voldoende zijn voor voldoende goede prestaties en doorvoer. Het voordeel van deze nieuwe configuratie is dat u meer flexibiliteit hebt bij het wijzigen van de grootte van VM's of het verplaatsen naar nieuwe VM-typen met de DBMS-laag of/en de toepassingslaag van het SAP-systeem.
Voor het speciale geval van het gebruik van Azure NetApp Files (ANF) voor de DBMS-omgeving en de ANF-gerelateerde nieuwe functionaliteit van azure NetApp Files-toepassingsvolumegroep voor SAP HANA en de noodzaak voor nabijheidsplaatsingsgroepen, controleert u het document NFS v4.1-volumes in Azure NetApp Files voor SAP HANA.
Nabijheidsplaatsingsgroepen met implementaties van beschikbaarheidssets
In dit geval is het doel om nabijheidsplaatsingsgroepen te gebruiken om de VM's die zijn geïmplementeerd via verschillende beschikbaarheidssets, samen te stellen. In dit gebruiksscenario gebruikt u geen beheerde implementatie in verschillende beschikbaarheidszones in een regio. In plaats daarvan wilt u het SAP-systeem implementeren met behulp van beschikbaarheidssets. Als gevolg hiervan hebt u ten minste een beschikbaarheidsset voor de DBMS-VM's, ASCS/SCS-VM's en de VM's in de toepassingslaag. Omdat u tijdens de implementatie van een VM geen beschikbaarheidsset EN een beschikbaarheidszone kunt opgeven, kunt u niet bepalen waar de VM's in de verschillende beschikbaarheidssets worden toegewezen. Dit kan ertoe leiden dat sommige Azure-regio's de netwerklatentie tussen verschillende VM's nog steeds te hoog zijn om een voldoende goede prestatie-ervaring te bieden. De resulterende architectuur ziet er dus als volgt uit:
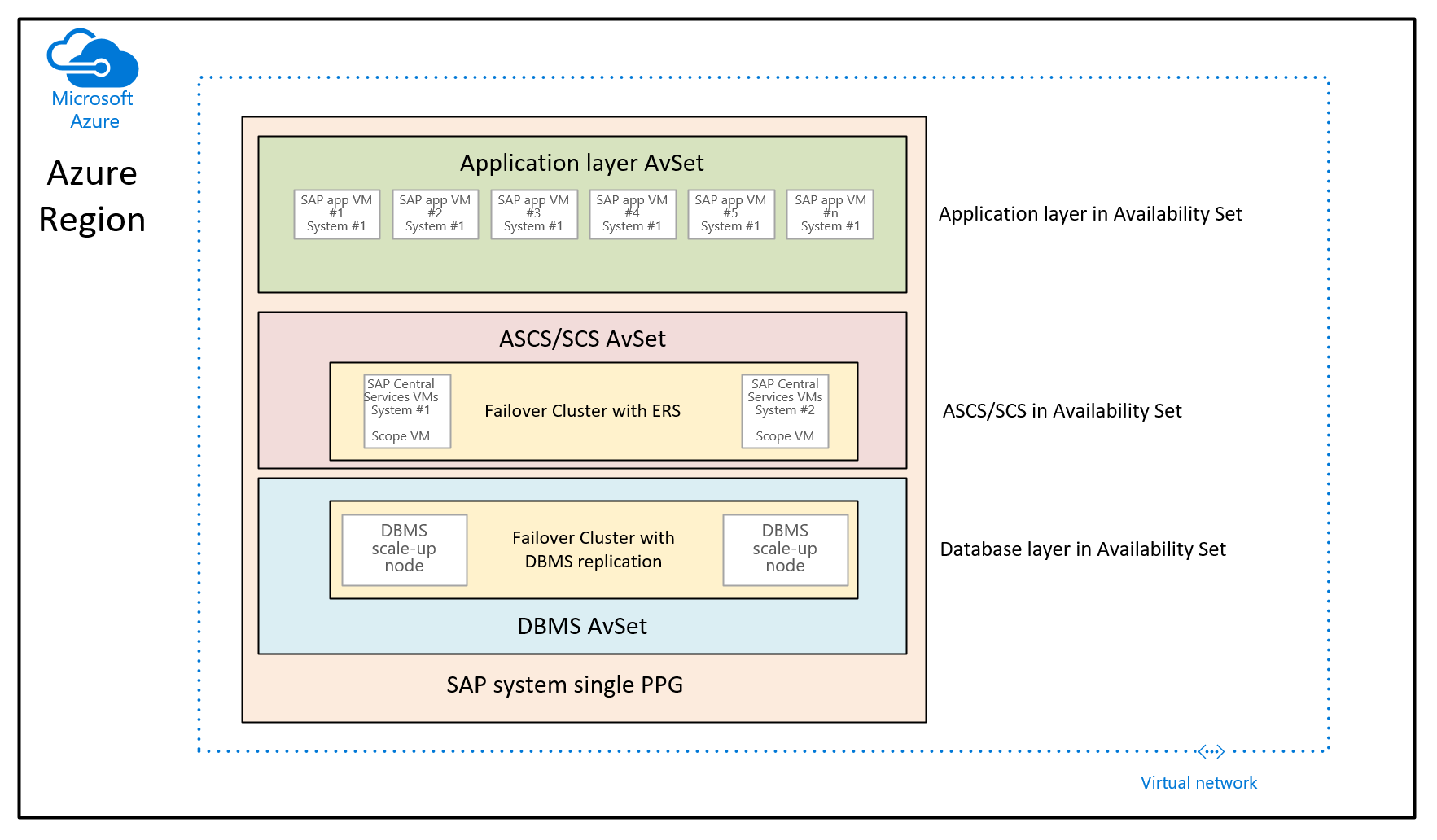
In deze afbeelding wordt één nabijheidsplaatsingsgroep toegewezen aan één SAP-systeem. Deze PPG wordt toegewezen aan de drie beschikbaarheidssets. De nabijheidsplaatsingsgroep wordt vervolgens bepaald door de eerste databaselaag-VM's te implementeren in de DBMS-beschikbaarheidsset. Met deze architectuuraanbieding worden alle VM's onder dezelfde netwerkstekel samengevoegd. Het introduceert de beperkingen die eerder in dit artikel zijn genoemd. Daarom moet de architectuur van de nabijheidsplaatsingsgroep sparse worden gebruikt.
Beschikbaarheidssets en beschikbaarheidszones combineren met nabijheidsplaatsingsgroepen
Een van de problemen bij het gebruik van beschikbaarheidszones voor SAP-systeemimplementaties is dat u de SAP-toepassingslaag niet kunt implementeren met behulp van beschikbaarheidssets binnen de specifieke beschikbaarheidszone. U wilt dat de SAP-toepassingslaag wordt geïmplementeerd in dezelfde zones als de SAP ASCS/SCS-VM's. Het verwijzen naar een beschikbaarheidszone en een beschikbaarheidsset bij het implementeren van één VIRTUELE machine is tot nu toe niet mogelijk. Maar als u alleen een VM implementeert die een beschikbaarheidszone instrueert, verliest u de mogelijkheid om ervoor te zorgen dat de VM's van de toepassingslaag worden verspreid over verschillende update- en foutdomeinen.
Door nabijheidsplaatsingsgroepen te gebruiken, kunt u deze beperking omzeilen. Dit is de implementatievolgorde:
- Maak een nabijheidsplaatsingsgroep.
- Implementeer uw anker-VM, aanbevolen de ASCS/SCS-VM te zijn door te verwijzen naar een beschikbaarheidszone.
- Maak een beschikbaarheidsset die verwijst naar de azure-nabijheidsplaatsingsgroep. (Zie de opdracht verderop in dit artikel.)
- Implementeer de VM's in de toepassingslaag door te verwijzen naar de beschikbaarheidsset en de nabijheidsplaatsingsgroep.
Belangrijk
Het is belangrijk om te begrijpen dat schijven van de toepassingslaag-VM's niet gegarandeerd worden toegewezen in dezelfde beschikbaarheidszone als de VM's worden omgeleid naar het gebruik van de nabijheidsplaatsingsgroep. Het resultaat van de implementatie die in de volgende stappen wordt weergegeven, kan zijn dat de VM's worden toegewezen in dezelfde netwerkstekel en met diezelfde beschikbaarheidszone als de anker-VM. Maar de respctive-schijven (basis-VHD en gekoppelde Azure-blokopslagschijven) worden mogelijk niet toegewezen onder dezelfde netwerkstekel of zelfs dezelfde beschikbaarheidszone. In plaats daarvan kunnen de schijven van deze VM's worden toegewezen in een van de datacenters van de specifieke regio. Hoewel de schijven van de anker-VM die zijn geïmplementeerd door een zone te definiëren, in dezelfde zone worden geïmplementeerd als de VM is geïmplementeerd.
In plaats van de eerste VM te implementeren zoals in de vorige sectie is gedemonstreerd, verwijst u naar een beschikbaarheidszone en de nabijheidsplaatsingsgroep wanneer u de VM implementeert:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Een geslaagde implementatie van deze virtuele machine zou als host fungeren voor het ASCS/SCS-exemplaar van het SAP-systeem in één beschikbaarheidszone. In dit geval worden de VM en de basis-VHD van de VIRTUELE machine en mogelijk gekoppelde Azure-blokopslagschijven toegewezen binnen dezelfde beschikbaarheidszone. Het bereik van de nabijheidsplaatsingsgroep wordt vastgezet op een van de netwerkstekels in de beschikbaarheidszone die u hebt gedefinieerd.
In de volgende stap moet u de beschikbaarheidssets maken die u wilt gebruiken voor de toepassingslaag van uw SAP-systeem.
Definieer en maak de nabijheidsplaatsingsgroep. De opdracht voor het maken van de beschikbaarheidsset vereist een extra verwijzing naar de nabijheidsplaatsingsgroep-id (niet de naam). U kunt de id van de nabijheidsplaatsingsgroep ophalen met behulp van deze opdracht:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Wanneer u de beschikbaarheidsset maakt, moet u rekening houden met aanvullende parameters wanneer u beheerde schijven gebruikt (standaard tenzij anders opgegeven) en nabijheidsplaatsingsgroepen:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
In het ideale geval moet u drie foutdomeinen gebruiken. Maar het aantal ondersteunde foutdomeinen kan per regio verschillen. In dit geval is het maximum aantal foutdomeinen dat mogelijk is voor de specifieke regio's twee. Als u vm's in de toepassingslaag wilt implementeren, moet u een verwijzing toevoegen naar de naam van uw beschikbaarheidsset en de naam van de nabijheidsplaatsingsgroep, zoals hier wordt weergegeven:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Notitie
De schijven van de vm's die in de bovenstaande beschikbaarheidsset zijn geïmplementeerd, worden niet gedwongen om te worden toegewezen in dezelfde beschikbaarheidszone als de VIRTUELE machine. Hoewel u hebt bereikt dat de vm's in de toepassingslaag worden verdeeld over verschillende foutdomeinen onder dezelfde netwerkstekel als de anker-VM wordt toegewezen, kunnen de schijven, hoewel deze ook zijn toegewezen in verschillende foutdomeinen, worden toegewezen op verschillende locaties in een regiobreed bereik.
Het resultaat van deze implementatie is:
- Een centrale services voor uw SAP-systeem die zich in een of meer specifieke beschikbaarheidszones bevinden.
- Een SAP-toepassingslaag die zich bevindt via beschikbaarheidssets in dezelfde netwerkstekel als de SAP Central-services (ASCS/SCS) VM of VM's.
Notitie
Omdat u één DBMS- en ASCS/SCS-VM's in één zone en de tweede DBMS- en ASCS/SCS-VM's in een andere zone implementeert om configuraties voor hoge beschikbaarheid te maken, hebt u een andere nabijheidsplaatsingsgroep nodig voor elk van de zones. Hetzelfde geldt voor elke beschikbaarheidsset die u gebruikt.
Configuraties van nabijheidsplaatsingsgroepen van een bestaand systeem wijzigen
Als u nabijheidsplaatsingsgroepen hebt geïmplementeerd op basis van de aanbevelingen die tot nu toe zijn gegeven en u wilt aanpassen aan de nieuwe configuratie, kunt u dit doen met de methoden die in deze artikelen worden beschreven:
- Implementeer VM's naar nabijheidsplaatsingsgroepen met behulp van Azure CLI.
- Vm's implementeren in nabijheidsplaatsingsgroepen met behulp van PowerShell.
U kunt deze opdrachten ook gebruiken voor gevallen waarin u toewijzingsfouten krijgt in gevallen waarin u niet kunt overstappen op een nieuw VM-type met een bestaande VM in de nabijheidsplaatsingsgroep.
Virtuele-machineschaalset met flexibele indeling
Om de beperkingen voor nabijheidsplaatsingsgroep te voorkomen, is het raadzaam om sap-werkbelasting te implementeren in beschikbaarheidszones met behulp van een flexibele schaalset met FD=1. Deze implementatiestrategie zorgt ervoor dat VM's die in elke zone worden geïmplementeerd, niet beperkt zijn tot één datacenter of netwerkkolom, en alle SAP-systeemonderdelen, zoals databases, ASCS/ERS en toepassingslaag, vallen binnen een zone. Wanneer alle SAP-systeemonderdelen op zoneniveau worden bereikt, moet de netwerklatentie tussen verschillende onderdelen van één SAP-systeem voldoende zijn om een goede prestaties en doorvoer te garanderen. Het belangrijkste voordeel van deze nieuwe implementatieoptie met flexibele schaalset met FD=1 is dat het meer flexibiliteit biedt bij het wijzigen van de grootte van VM's of het overschakelen naar nieuwe VM-typen voor alle lagen van het SAP-systeem. Bovendien zou de schaalset VM's toewijzen aan meerdere foutdomeinen binnen één zone, wat ideaal is voor het uitvoeren van meerdere VM's van de toepassingslaag in elke zone. Zie virtuele-machineschaalset voor SAP-werkbelastingdocument voor meer informatie.

In een niet-productie- of niet-HA-omgeving is het mogelijk om alle SAP-systeemonderdelen, waaronder de database, ASCS en toepassingslaag, binnen één zone te implementeren met behulp van een flexibele schaalset met FD=1.
Eerder aanbevolen implementatieopties
Deze sectie bevat informatie over eerder aanbevolen implementatieopties om de netwerklatentie voor SAP te optimaliseren. Met nieuwe functies en Azure-groei in de loop van de tijd mogen details in deze sectie alleen in zeldzame gevallen worden toegepast.
Nabijheidsplaatsingsgroepen voor het hele SAP-systeem met zonegebonden implementaties
Het gebruik van nabijheidsplaatsingsgroepen die we tot nu toe hebben aanbevolen, ziet er in deze afbeelding uit.

U maakt een nabijheidsplaatsingsgroep (PPG) in elk van de twee beschikbaarheidszones waarin u uw SAP-systeem hebt geïmplementeerd. Alle VM's van een bepaalde zone maken deel uit van de afzonderlijke nabijheidsplaatsingsgroep van die specifieke zone. U begint in elke zone met het implementeren van de DBMS-VM om de PPG te bepalen en vervolgens de ASCS-VM in dezelfde zone en PPG te implementeren. In een derde stap maakt u een Azure-beschikbaarheidsset, wijst u de beschikbaarheidsset toe aan de scoped PPG en implementeert u de SAP-toepassingslaag erin. Het voordeel van deze configuratie was dat alle onderdelen mooi onder dezelfde netwerkstekel zijn uitgelijnd. Het grote nadeel is dat uw flexibiliteit bij het wijzigen van het formaat van virtuele machines beperkt kan zijn.
Op basis van veel verbeteringen die door Microsoft zijn geïmplementeerd in de Azure-regio's om de netwerklatentie binnen een Beschikbaarheidszone van Azure te verminderen, bestaan de huidige implementatierichtlijnen voor zonegebonden implementaties in dit artikel.
Nabijheidsplaatsingsgroepen en HANA Large Instances
Als sommige van uw SAP-systemen afhankelijk zijn van HANA Large Instances voor de databaselaag, kunt u aanzienlijke verbeteringen in de netwerklatentie ervaren tussen de HANA Large Instances-eenheid en Azure-VM's wanneer u HANA Large Instances-eenheden gebruikt die zijn geïmplementeerd in revisie 4 rijen of stempels. Een verbetering is dat HANA Large Instances-eenheden, wanneer ze worden geïmplementeerd, worden geïmplementeerd met een nabijheidsplaatsingsgroep. U kunt die nabijheidsplaatsingsgroep gebruiken om uw VM's in de toepassingslaag te implementeren. Als gevolg hiervan worden deze VM's geïmplementeerd in hetzelfde datacenter dat als host fungeert voor uw HANA Large Instances-eenheid.
Als u wilt bepalen of uw HANA Large Instances-eenheid is geïmplementeerd in een zegel of rij van revisie 4, controleert u het artikel over azure HANA Large Instances via Azure Portal. In het overzicht van kenmerken van uw HANA Large Instances-eenheid kunt u ook de naam van de nabijheidsplaatsingsgroep bepalen omdat deze is gemaakt toen uw HANA Large Instances-eenheid werd geïmplementeerd. De naam die wordt weergegeven in het overzicht van kenmerken is de naam van de nabijheidsplaatsingsgroep waarin u de VM's in de toepassingslaag moet implementeren.
In vergelijking met SAP-systemen die alleen gebruikmaken van virtuele Azure-machines, hebt u minder flexibiliteit bij het bepalen hoeveel Azure-resourcegroepen u moet gebruiken wanneer u HANA Large Instances gebruikt. Alle HANA Large Instances-eenheden van een HANA Large Instances-tenant worden gegroepeerd in één resourcegroep, zoals beschreven in dit artikel. Tenzij u in verschillende tenants implementeert om bijvoorbeeld productie- en niet-productiesystemen of andere systemen te scheiden, worden al uw HANA Large Instances-eenheden geïmplementeerd in één HANA Large Instances-tenant. Deze tenant heeft een een-op-een-relatie met een resourcegroep. Er wordt echter een afzonderlijke nabijheidsplaatsingsgroep gedefinieerd voor elk van de afzonderlijke eenheden.
Als gevolg hiervan worden de relaties tussen Azure-resourcegroepen en nabijheidsplaatsingsgroepen voor één tenant weergegeven, zoals hier wordt weergegeven:

Volgende stappen
Raadpleeg de documentatie:
- SAP-workloads in Azure: Controlelijst voor planning en implementatie
- VM's implementeren op nabijheidsplaatsingsgroepen met behulp van Azure CLI
- VM's implementeren in nabijheidsplaatsingsgroepen met behulp van PowerShell
- Overwegingen voor DBMS-implementatie van Azure Virtual Machines voor SAP-workloads