Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze handleiding gebruikt u notebooks met Spark runtime om onbewerkte gegevens in uw lakehouse te transformeren en gereedmaken.
Vereisten
Voordat u begint, moet u de vorige zelfstudies in deze reeks voltooien:
- Een lakehouse maken
- Gegevens opnemen in lakehouse
- Zorg ervoor dat lakehouse-schema's zijn ingeschakeld in uw lakehouse.
Gegevens voorbereiden
In de vorige stappen van de tutorial hebt u ruwe gegevens verzameld uit de bron in de sectie Bestanden van het lakehouse. U kunt deze gegevens nu transformeren en voorbereiden voor het maken van Delta-tabellen.
Download de notebooks uit de map Lakehouse-zelfstudie Broncode.
Ga in uw browser naar uw Fabric-werkruimte in de Fabric-portal.
Selecteer Importeren>Notebook>vanaf deze computer.
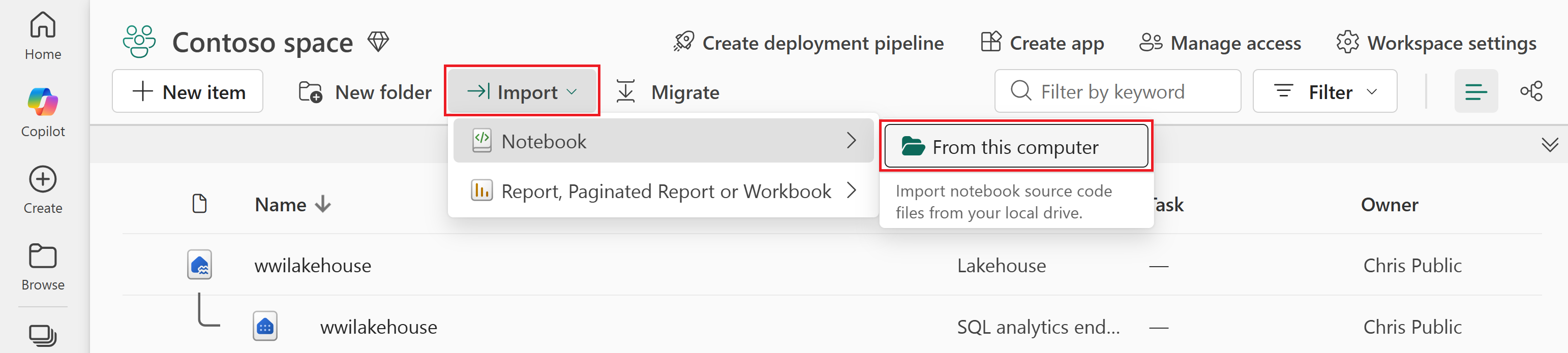
Selecteer Upload vanuit het deelvenster Importstatus dat aan de rechterkant van het scherm wordt geopend.
Selecteer alleen het notitieblok dat overeenkomt met de programmeertaal van uw voorkeur.
-
PySpark (
Prepare and transform data - PySpark.ipynb) -
Spark SQL (
Prepare and transform data - Spark SQL.ipynb)
-
PySpark (
Selecteer Openen. Er wordt een melding weergegeven die de status van de import aangeeft in de rechterbovenhoek van het browservenster.
Nadat het importeren is voltooid, gaat u naar de itemsweergave van de werkruimte om het geïmporteerde notitieblok te controleren.
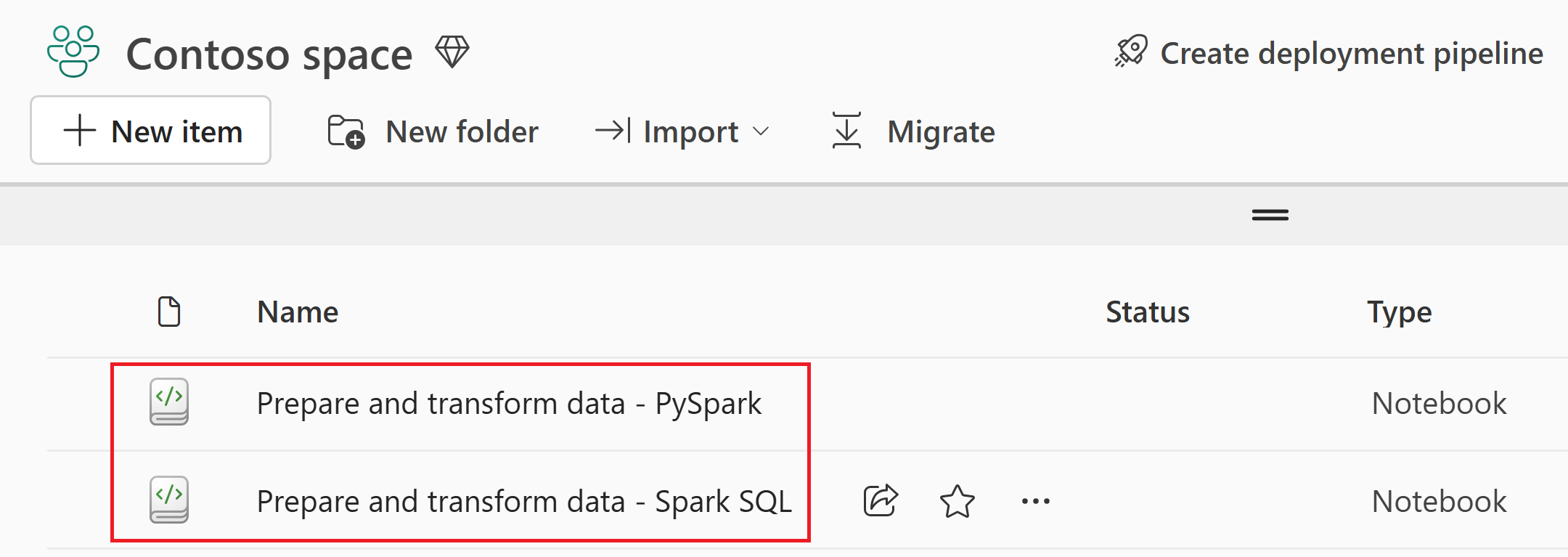
Selecteer het wwilakehouse om het te openen, zodat het notitieblok dat u vervolgens opent, eraan is gekoppeld.
Selecteer in het bovenste navigatiemenu Open notitieblok>Bestaand notitieblok.
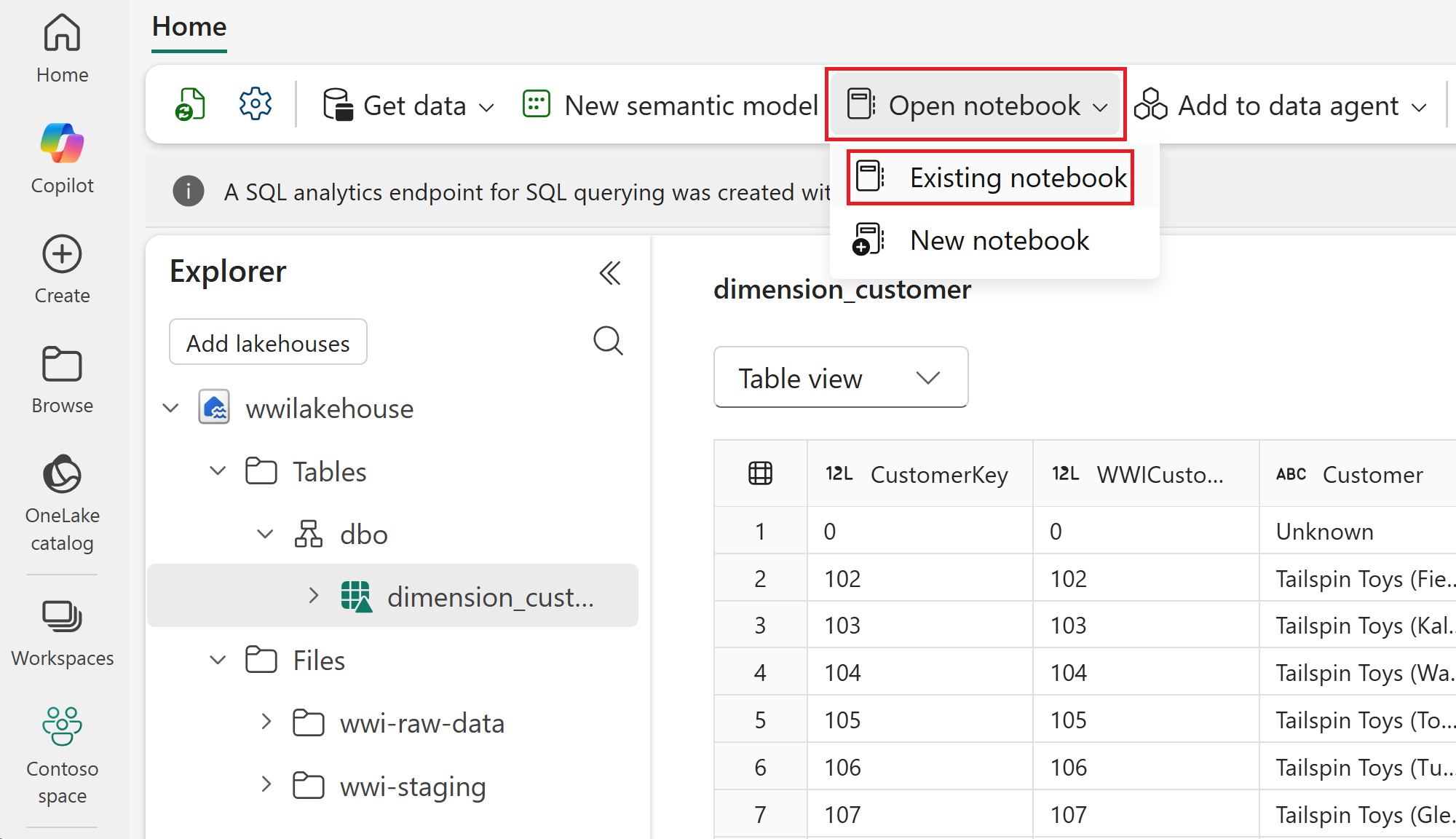
Selecteer uw geïmporteerde notebook voor PySpark of Spark SQL en selecteer Openen. Het notitieblok is al gekoppeld aan uw geopende lakehouse, zoals wordt weergegeven in de Lakehouse Explorer.



U bent nu klaar om de notebook-cellen uit te voeren die de Delta-tabellen creëren en transformeren.
Voer in de volgende secties de notebookcellen opeenvolgend uit. Als u een cel wilt uitvoeren, selecteert u het pictogram Uitvoeren dat links van de cel wordt weergegeven bij mouse-over. U kunt ook Alles uitvoeren selecteren op het bovenste lint (Start) om alle cellen op volgorde uit te voeren.
Belangrijk
Voor deze zelfstudie moeten lakehouse-schema's zijn ingeschakeld. Als schema's niet zijn ingeschakeld, werkt de code in deze zelfstudie niet zoals bedoeld.
In het geïmporteerde notitieblok ziet u zowel Pad 1 als Pad 2 secties. Voor deze zelfstudie gebruikt u Path 1 (lakehouse-schema's ingeschakeld) en negeert u Path 2 (lakehouse-schema's niet ingeschakeld).
Delta-tabellen maken
In deze sectie voert u de notebookcellen uit om Delta-tabellen te maken op basis van de onbewerkte gegevens.
De tabellen volgen een stervormig schema. Dit is een gemeenschappelijk patroon voor het ordenen van analytische gegevens:
- Een feitentabel (
fact_sale) bevat de meetbare gebeurtenissen van het bedrijf, in dit geval afzonderlijke verkooptransacties met hoeveelheden, prijzen en winst. -
Dimensietabellen (
dimension_city,dimension_customer,dimension_date,dimension_employee,dimension_stock_item) bevatten de beschrijvende kenmerken die context geven aan de feiten, zoals waar een verkoop is gebeurd, wie het heeft gemaakt en wanneer.
Selecteer op deze zelfstudiepagina het tabblad dat overeenkomt met het notitieblok dat u hebt geïmporteerd en gebruik hetzelfde tabblad voor alle stappen. De tabbladen bevinden zich in dit artikel, niet in het notitieblok.
Cel 1: Configuratie van Spark-sessie. Deze cel maakt twee Fabric-functies mogelijk die optimaliseren hoe gegevens in volgende cellen worden geschreven en gelezen. V-order optimaliseert de indeling van de parquet-bestanden voor snellere leesbewerkingen en betere compressie. Schrijfbewerkingen optimaliseren vermindert het aantal geschreven bestanden en verhoogt de grootte van afzonderlijke bestanden.
Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
Cel 2 - Feit - Verkoop. Deze cel leest onbewerkte parquet-gegevens uit
Files/wwi-raw-data/full/fact_sale_1y_full, voegt kolommen met datumonderdelen (Jaar, Kwartaal en Maand) toe en schrijftfact_saleals een Delta-tabel die is gepartitioneerd op jaar en kwartaal.Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/dbo/" + table_name)Cel 3- Dimensies. Deze cel leest de vijf dimensionale parquet-gegevenssets en schrijft ze als Delta-tabellen (
dimension_city,dimension_customer,dimension_date,dimension_employee, endimension_stock_item) onderTables/dbo/....Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/dbo/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Als u de gemaakte tabellen wilt valideren, klikt u met de rechtermuisknop op wwilakehouse lakehouse in de verkenner en selecteert u Vernieuwen. De tabellen worden weergegeven.
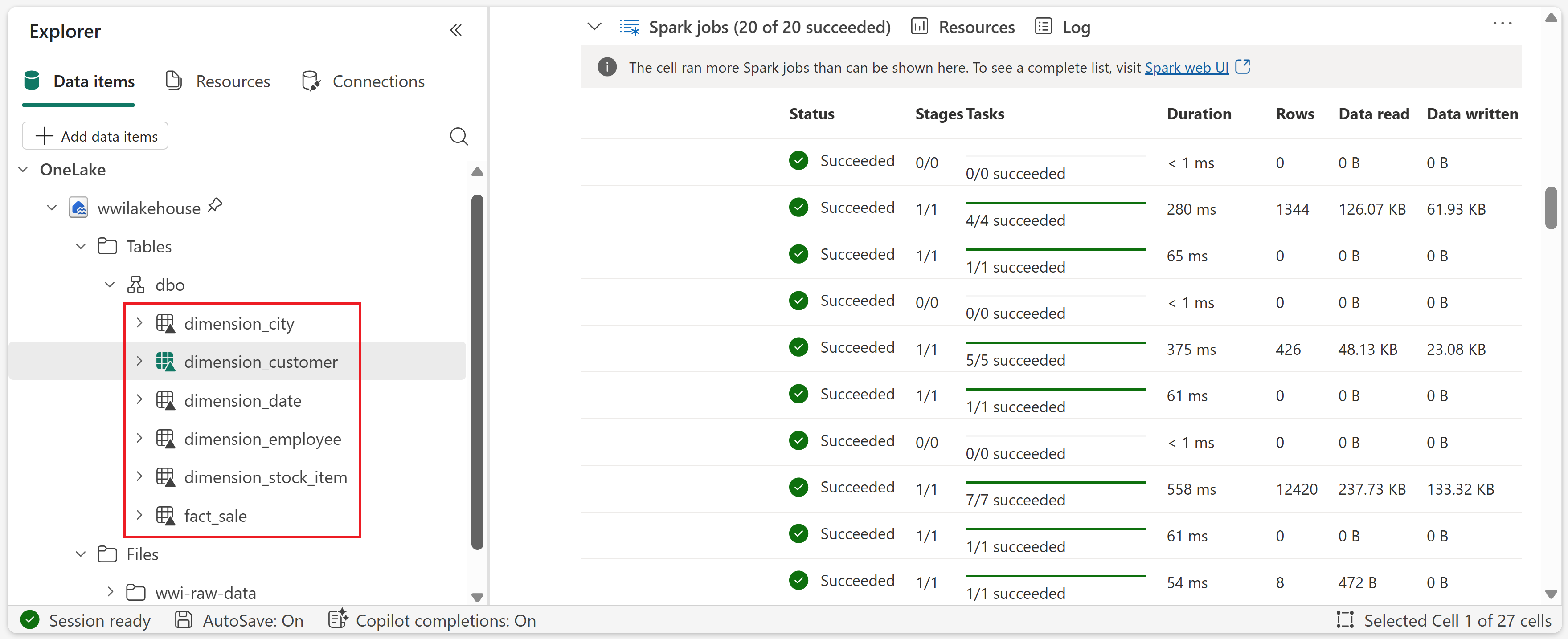

Gegevens transformeren voor zakelijke aggregaties
In deze sectie gaat u door in hetzelfde notebook en voert u de volgende cellen uit om statistische tabellen te maken van de Delta-tabellen die u in de vorige sectie hebt gemaakt.
Zorg ervoor dat het notitieblok nog steeds is gekoppeld aan wwilakehouse.
Cel 4: brontabellen laden voor transformatie (alleen PySpark). Als u het PySpark-notebook gebruikt, voert u deze cel uit om Delta-tabellen in DataFrames te laden voor de volgende aggregatiestappen.
Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
Cel 5 - Maak
aggregate_sale_by_date_city. Deze cel voegt verkoop-, datum- en plaatsgegevens samen en maakt vervolgens de statistische tabel op plaatsniveau.Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
sale_by_date_city = ( df_fact_sale.alias("sale") .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory") .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit") .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax") .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount") .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax") .withColumnRenamed("sum(Profit)", "SumOfProfit") .orderBy("date.Date", "city.StateProvince", "city.City") ) sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_city")Cel 6 - Maak
aggregate_sale_by_date_employee. In deze cel worden verkoop-, datum- en werknemersgegevens samengevoegd en wordt vervolgens de statistische tabel op werknemerniveau gemaakt.Voer deze cel uit en wacht tot deze is voltooid voordat u verdergaat met de volgende stap.
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year , DE.PreferredName, DE.Employee , SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax , SUM(FS.TaxAmount) SumOfTaxAmount , SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax , SUM(FS.Profit) SumOfProfit FROM delta.`Tables/dbo/fact_sale` FS INNER JOIN delta.`Tables/dbo/dimension_date` DD ON FS.InvoiceDateKey = DD.Date INNER JOIN delta.`Tables/dbo/dimension_employee` DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC """) sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/dbo/aggregate_sale_by_date_employee")Als u de gemaakte tabellen wilt valideren, klikt u met de rechtermuisknop op wwilakehouse lakehouse in de verkenner en selecteert u Vernieuwen. De samengevoegde tabellen worden weergegeven.

In deze handleiding worden gegevens geschreven als Delta Lake-bestanden. Fabric detecteert en registreert deze tabellen automatisch in de metastore, zodat u geen afzonderlijke CREATE TABLE instructies hoeft uit te voeren.