Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Een machine learning-experiment is de primaire eenheid van organisatie en controle voor alle gerelateerde machine learning-uitvoeringen. Een run komt overeen met een enkele uitvoering van de modelcode. In MLflow-is het bijhouden gebaseerd op experimenten en uitvoeringen.
Met machine learning-experimenten kunnen gegevenswetenschappers parameters, codeversies, metrische gegevens en uitvoerbestanden registreren bij het uitvoeren van hun machine learning-code. Met experimenten kunt u ook uitvoeringen visualiseren, zoeken en vergelijken, evenals uitvoeringsbestanden en metagegevens downloaden voor analyse in andere hulpprogramma's.
In dit artikel vindt u meer informatie over hoe gegevenswetenschappers kunnen communiceren met machine learning-experimenten om hun ontwikkelingsproces te organiseren en om meerdere uitvoeringen bij te houden.
Vereiste voorwaarden
Een Microsoft Fabric-abonnement ophalen. Of meld u aan voor een gratis Microsoft Fabric proefversie.
Meld u aan bij Microsoft Fabric.
Schakel over naar Fabric met behulp van de ervaringsschakelaar aan de linkerkant van de startpagina.
Een experiment maken
U kunt rechtstreeks vanuit de Fabric gebruikersinterface (UI) een machine learning-experiment maken of door code te schrijven die gebruikmaakt van de MLflow-API.
Een experiment maken met behulp van de gebruikersinterface
Een machine learning-experiment maken vanuit de gebruikersinterface:
Maak een nieuwe werkruimte of selecteer een bestaande werkruimte.
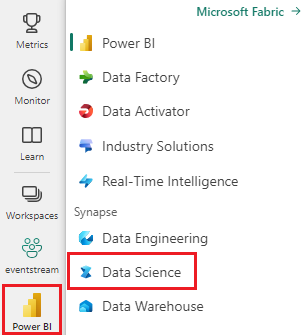
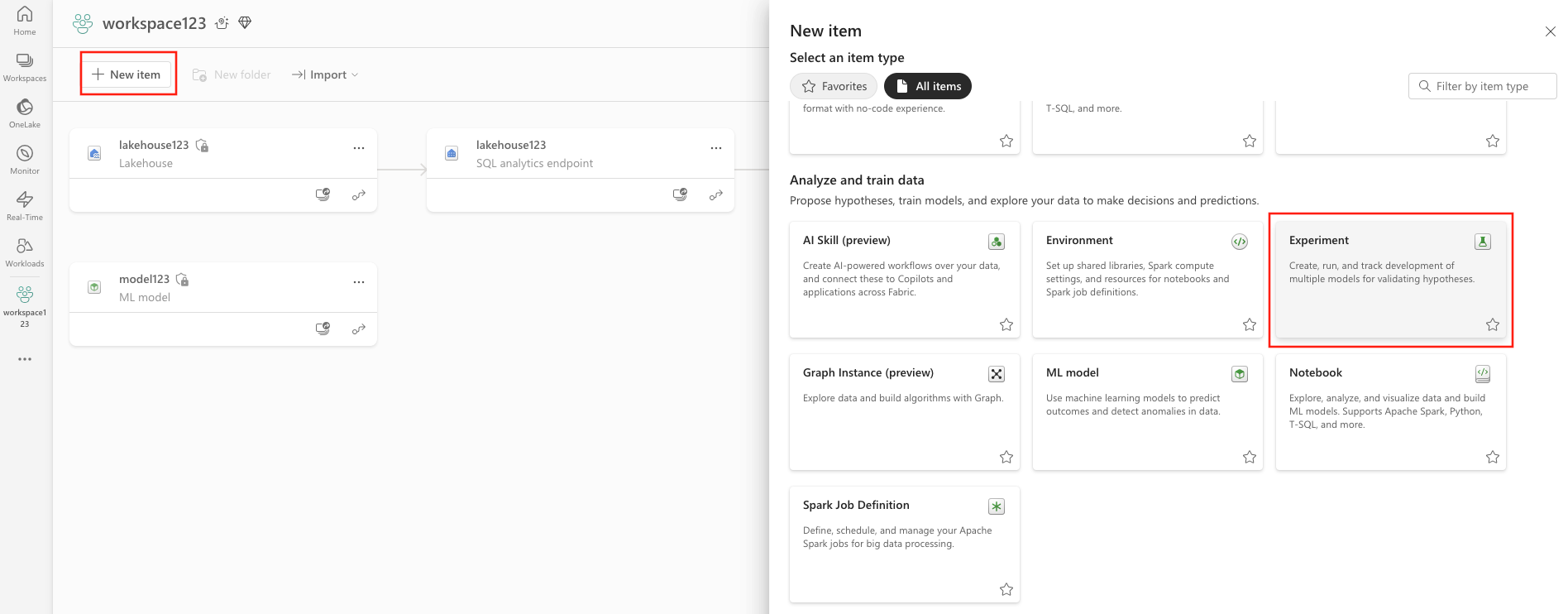
Selecteer in de linkerbovenhoek van uw werkruimte nieuw item. Selecteer Experiment onder Gegevens analyseren en trainen.
 OF
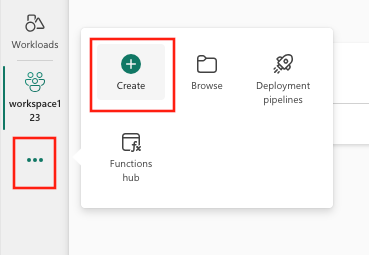
OFSelecteer Maken, die u kunt vinden in ... in het verticale menu.
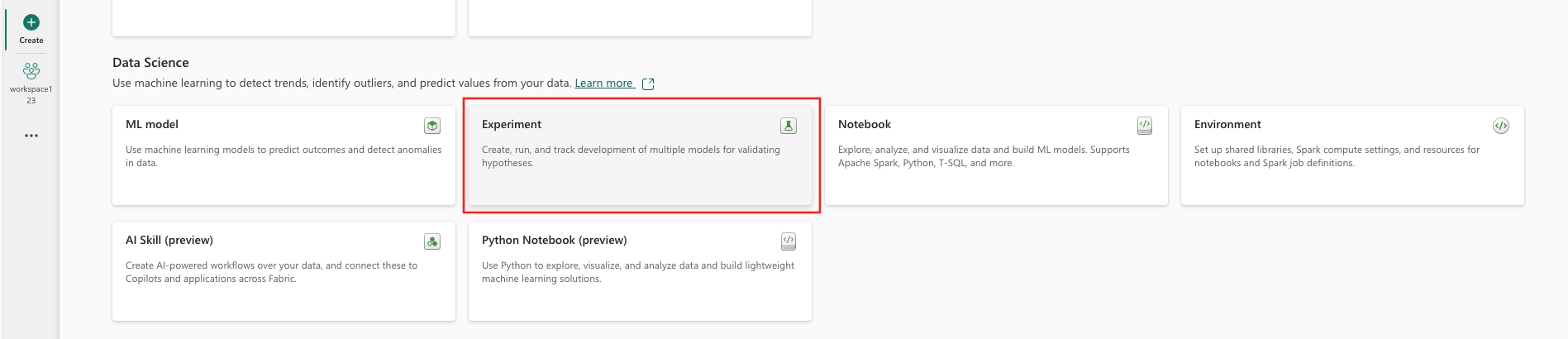
Selecteer Experiment onder Data Science.
Geef een experimentnaam op en selecteer Maken. Met deze actie maakt u een leeg experiment in uw werkruimte.



Nadat u het experiment hebt gemaakt, kunt u runs toevoegen om uitvoeringsmetrics en parameters bij te houden.
Een experiment maken met behulp van de MLflow-API
U kunt ook rechtstreeks vanuit uw ontwerpervaring een machine learning-experiment maken met behulp van de mlflow.create_experiment() of mlflow.set_experiment() API's. Vervang in de volgende code `<EXPERIMENT_NAME>` door de naam van uw experiment.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Uitvoeringen binnen een experiment beheren
Een machine learning-experiment bevat een verzameling uitvoeringen voor vereenvoudigde tracering en vergelijking. Binnen een experiment kan een data scientist door verschillende uitvoeringen navigeren en de onderliggende parameters en metrische gegevens verkennen. Gegevenswetenschappers kunnen ook uitvoeringen in een machine learning-experiment vergelijken om te bepalen welke subset van parameters een gewenste modelprestaties oplevert.
Als u de uitvoeringen voor een experiment wilt weergeven, selecteert u Uitvoerlijst in de experimentweergave.

In de lijst met uitvoeringen kunt u naar de details van een specifieke uitvoering navigeren door de naam van de uitvoering te selecteren.
Details van run bijhouden
Een machine learning-uitvoering komt overeen met één uitvoering van modelcode. U kunt de volgende informatie voor elke uitvoering bijhouden:

Elke uitvoering bevat de volgende informatie:
- Bron: Naam van het notebook die de run heeft aangemaakt.
- Geregistreerde versie: geeft aan of de uitvoering is opgeslagen als een machine learning-model.
- Begindatum: Begintijd van de uitvoering.
- Status: Voortgang van de uitvoering.
- Hyperparameters: Hyperparameters die zijn opgeslagen als sleutel-waardeparen. Zowel sleutels als waarden zijn tekenreeksen.
- Metrische gegevens: Voer metrische gegevens uit die zijn opgeslagen als sleutel-waardeparen. De waarde is numeriek.
- Uitvoerbestanden: Uitvoerbestanden in elk formaat. U kunt bijvoorbeeld afbeeldingen, omgeving, modellen en gegevensbestanden vastleggen.
- Tags: Metagegevens als sleutel-waardeparen voor runs.
De lijst met uitvoeringen weergeven
U kunt alle uitvoeringen in een experiment bekijken in de Lijstweergave Uitvoeringen. Met deze weergave kunt u recente activiteiten bijhouden, snel naar de gerelateerde Spark-toepassing gaan en filters toepassen op basis van de uitvoeringsstatus.
Uitvoeringen vergelijken en filteren
Als u de kwaliteit van uw machine learning-uitvoeringen wilt vergelijken en evalueren, kunt u de parameters, metrische gegevens en metagegevens tussen geselecteerde uitvoeringen in een experiment vergelijken.
Tags toepassen op runs
Met MLflow-taggen voor experimentuitvoeringen kunnen gebruikers aangepaste metagegevens toevoegen in de vorm van sleutel-waardeparen aan hun uitvoeringen. Deze tags helpen bij het categoriseren, filteren en zoeken naar uitvoeringen op basis van specifieke kenmerken, waardoor het eenvoudiger is om experimenten binnen het MLflow-platform te beheren en te analyseren. Gebruikers kunnen tags gebruiken om uitvoeringen te labelen met informatie zoals modeltypen, parameters of relevante id's, waardoor de algehele organisatie en traceerbaarheid van experimenten worden verbeterd.
Dit codefragment start een MLflow-uitvoering, registreert enkele parameters en metrische gegevens en voegt tags toe om te categoriseren en extra context te bieden voor de uitvoering.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
Zodra de tags zijn toegepast, kunt u de resultaten rechtstreeks vanuit de inline MLflow-widget of vanaf de pagina met uitvoeringsdetails bekijken.

Waarschuwing
Warning: Beperkingen voor het toepassen van tags op MLflow-experimentuitvoeringen in Fabric
- Niet-lege tags: labelnamen of waarden mogen niet leeg zijn. Als u een tag met een lege naam of waarde probeert toe te passen, mislukt de bewerking.
- Tagnamen: tagnamen kunnen maximaal 250 tekens lang zijn.
- Tagwaarden: Tagwaarden kunnen maximaal 5000 tekens lang zijn.
-
Namen van beperkte tags: tagnamen die beginnen met bepaalde voorvoegsels, worden niet ondersteund. Met name tagnamen die beginnen met
synapseml,mlflowoftridentzijn beperkt en worden niet geaccepteerd.
Uitvoeringen visueel vergelijken
U kunt uitvoeringen visueel vergelijken en filteren binnen een bestaand experiment. Met visuele vergelijking kunt u eenvoudig navigeren tussen meerdere uitvoeringen en ze sorteren.

Runs vergelijken:
- Selecteer een bestaand machine learning-experiment dat meerdere uitvoeringen bevat.
- Selecteer het tabblad Weergave en ga vervolgens naar de lijstweergave Uitvoeren . U kunt ook de optie selecteren om de uitvoeringslijst rechtstreeks vanuit de weergave Uitvoeringsdetails weer te geven.
- Pas de kolommen in de tabel aan door het deelvenster Kolommen aanpassen uit te vouwen. Hier kunt u de eigenschappen, metrische gegevens, tags en hyperparameters selecteren die u wilt zien.
- Vouw het deelvenster Filter uit om uw resultaten te beperken op basis van bepaalde geselecteerde criteria.
- Selecteer meerdere uitvoeringen om de resultaten te vergelijken in het deelvenster met metrische gegevens. In dit deelvenster kunt u de grafieken aanpassen door de grafiektitel, het visualisatietype, de X-as, de Y-as en meer te wijzigen.
Uitvoeringen vergelijken met behulp van de MLflow-API
Gegevenswetenschappers kunnen ook MLflow gebruiken om query's uit te voeren en te zoeken tussen uitvoeringen binnen een experiment. U kunt meer MLflow-API's verkennen voor het zoeken, filteren en vergelijken van uitvoeringen door naar de MLflow-documentatie te gaan.
Alle uitvoeringen ophalen
U kunt de MLflow-zoek-API mlflow.search_runs() gebruiken om alle uitvoeringen in een experiment op te halen door <EXPERIMENT_NAME> te vervangen met uw experimentnaam of <EXPERIMENT_ID> met uw experiment-id in de volgende code.
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Hint
U kunt in meerdere experimenten zoeken door een lijst met experiment-id's op te geven aan de experiment_ids parameter. Door een lijst met experimentnamen aan de experiment_names-parameter te geven, kan MLflow zoeken in meerdere experimenten. Dit kan handig zijn als u uitvoeringen in verschillende experimenten wilt vergelijken.
Uitvoeringen van volgorde en limiet
Gebruik de max_results-parameter van search_runs om het aantal geretourneerde runs te beperken. De order_by parameter kunt u gebruiken om de kolommen op volgorde weer te geven en kan een optionele DESC of ASC waarde bevatten. In het volgende voorbeeld wordt bijvoorbeeld de laatste uitvoering van een experiment geretourneerd.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Uitvoeringen vergelijken in een Fabric-notebook
U kunt de mlFlow-ontwerpwidget in Fabric notebooks gebruiken om MLflow-uitvoeringen bij te houden die in elke notebookcel worden gegenereerd. Met de widget kunt u uw uitvoeringen, gekoppelde metrische gegevens, parameters en eigenschappen rechtstreeks tot op het niveau van de afzonderlijke cel bijhouden.
Als u een visuele vergelijking wilt verkrijgen, kunt u ook overschakelen naar de vergelijkingsweergave Uitvoeren . In deze weergave worden de gegevens grafisch weergegeven, die helpen bij het snel identificeren van patronen of afwijkingen in verschillende uitvoeringen.

Sla de run op als machine learning-model
Zodra een uitvoering het gewenste resultaat oplevert, kunt u de uitvoering opslaan als een model voor verbeterde modeltracking en voor modelimplementatie door Opslaan als een ML-model te selecteren.

Geregistreerde modellen en traceringen (MLflow 3)
Met ondersteuning voor MLflow 3 in Fabric bevat de experimentpagina twee extra oppervlakken buiten de lijst met uitvoeringen:
- In de sectie Gelogde modellen staan alle LoggedModels die door runs in het experiment zijn geproduceerd. Elke vermelding toont de modelnaam, id, bronuitvoering, parameters en metrische gegevens. Selecteer een LoggedModel om de detailpagina te openen, vergelijk het met andere modellen of registreer het als een Fabric ML-modelitem.
- Het tabblad Traceringen toont GenAI-traceringen die zijn vastgelegd op basis van uw uitvoeringen, inclusief invoer, uitvoer, latentie, tokengebruik en de spanhiërarchie van elke aanvraag.
Zie MLflow 3 in Fabric Data Science voor meer informatie over LoggedModel en Traces.
ML-experimenten monitoren (preview)
ML-experimenten worden rechtstreeks geïntegreerd in Monitor. Deze functionaliteit is ontworpen om meer inzicht te bieden in uw Spark-toepassingen en de ML-experimenten die ze genereren, waardoor het eenvoudiger is om deze processen te beheren en fouten op te sporen.
Runs volgen via monitor
Gebruikers kunnen experimentuitvoeringen rechtstreeks vanuit de monitor volgen, zodat ze een uniforme weergave van al hun activiteiten bieden. Deze integratie omvat filteropties, zodat gebruikers zich kunnen richten op experimenten of uitvoeringen die in de afgelopen 30 dagen of andere opgegeven perioden zijn gemaakt.

Houd gerelateerde ML-experimentuitvoeringen bij vanuit je Spark-toepassing.
ML Experiment is rechtstreeks geïntegreerd in Monitor, waar u een specifieke Spark-toepassing kunt selecteren en itemmomentopnamen kunt openen. Hier vindt u een lijst met alle experimenten en uitvoeringen die door die toepassing worden gegenereerd.