Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Een machine learning-model is een bestand dat is getraind om bepaalde typen patronen te herkennen. U traint een model over een set gegevens en u geeft het een algoritme dat gebruikt om redeneren en leren van die gegevensset. Nadat u het model hebt getraind, kunt u het gebruiken om te redeneren over gegevens die het model nooit eerder heeft gezien, en voorspellingen over die gegevens te doen.
In MLflow kan een machine learning-model meerdere modelversies bevatten. Hier kan elke versie een modeliteratie vertegenwoordigen. In dit artikel leert u hoe u met ML-modellen kunt werken om modeliteraties bij te houden en te vergelijken.
In dit artikel leert u het volgende:
- Machine Learning-modellen maken in Microsoft Fabric
- Modelversies beheren en bijhouden
- Modelprestaties vergelijken in verschillende versies
- Toepassen van modellen voor scoreberekening en inferentie
Een machine learning-model maken
U kunt een machine learning-model maken vanuit de Fabric UI of programmatisch met de MLflow-API. In MLflow gebruiken modellen een standaard verpakkingsformaat dat werkt met verschillende downstream-tools, waaronder batch-inferentie op Apache Spark. Met het formaat wordt een model opgeslagen in verschillende 'smaken' die verschillende downstreamtools kunnen begrijpen.
Een machine learning-model maken vanuit de gebruikersinterface:
- Selecteer een bestaande data science-werkruimte of maak een nieuwe werkruimte.
- Maak een nieuw item via de werkruimte of met behulp van de knop Maken:
- Werkruimte:
- Selecteer uw werkruimte.
- Selecteer Nieuw item.
- Selecteer ML-model onder Gegevens analyseren en trainen.
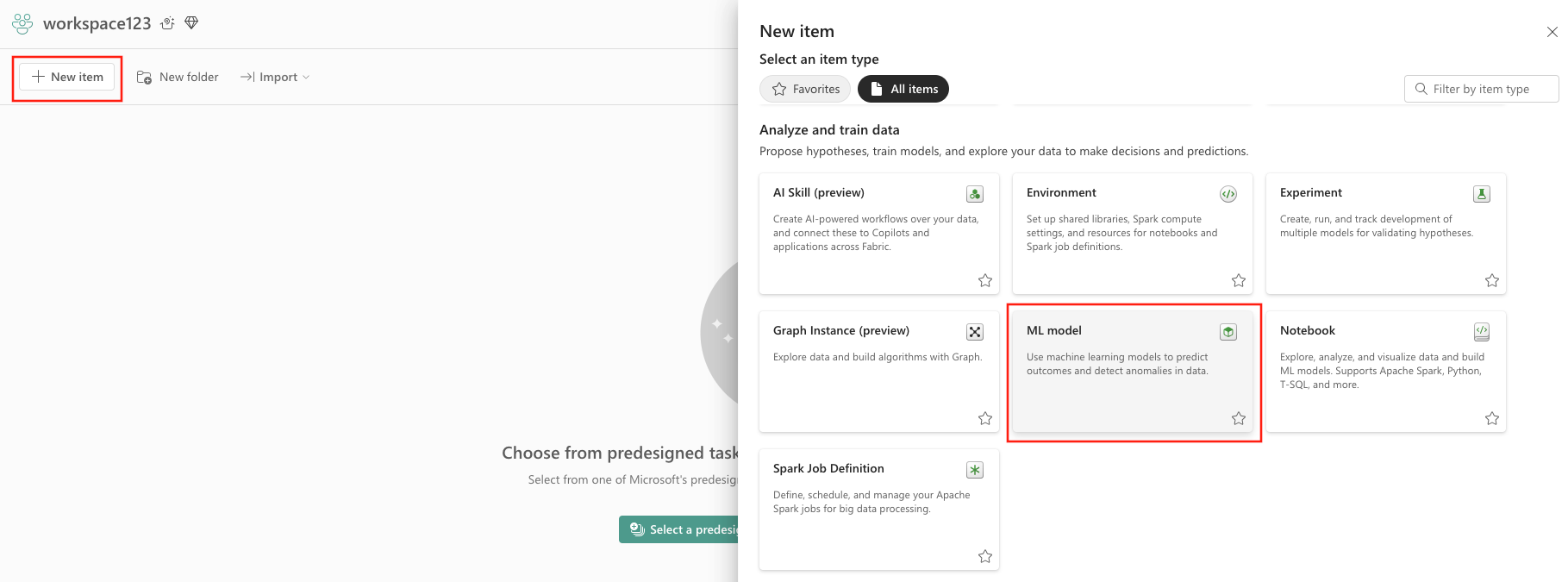
- Knop Maken:
- Selecteer Maken, die u kunt vinden in ... in het verticale menu.
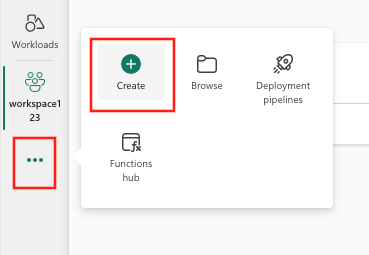
- Selecteer ML-model onder Data Science.

- Selecteer Maken, die u kunt vinden in ... in het verticale menu.
- Werkruimte:
- Nadat het model is gemaakt, kunt u modelversies toevoegen om metrische gegevens en parameters voor uitvoering bij te houden. Experimentuitvoeringen registreren of opslaan in een bestaand model.



U kunt ook rechtstreeks vanuit uw ontwerpervaring een machine learning-model maken met de mlflow.register_model() API. Als er geen geregistreerd machine learning-model met de opgegeven naam bestaat, wordt het automatisch gemaakt door de API.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Versies beheren binnen een machine learning-model
Een machine learning-model bevat een verzameling modelversies voor vereenvoudigde tracering en vergelijking. Binnen een model kan een data scientist door verschillende modelversies navigeren om de onderliggende parameters en metrische gegevens te verkennen. Gegevenswetenschappers kunnen ook vergelijkingen maken tussen modelversies om te bepalen of nieuwere modellen betere resultaten kunnen opleveren.
Note
Met MLflow 3-ondersteuning in Fabric maakt elk model dat u aanmeldt met mlflow.<flavor>.log_model(model, name="...") een LoggedModel entiteit die is gekoppeld aan de bronuitvoering, parameters, metrische gegevens, gegevenssets en omgeving. U kunt een LoggedModel openen vanaf de experimentpagina en het registreren als een nieuw ML-model of een nieuwe versie van een bestaand model. Zie MLflow 3 in Fabric Data Science voor meer informatie.
Machine Learning-modellen bijhouden
Een machine learning-modelversie vertegenwoordigt een afzonderlijk model dat is geregistreerd voor het bijhouden.
![]()
Elke modelversie bevat de volgende informatie:
| Vastgoed | Description |
|---|---|
| Aanmaakdatum | De datum en tijd waarop het model is gemaakt. |
| Runnaam | De identificatie voor de experimentuitvoering die is gebruikt om deze specifieke modelversie te maken. |
| Hyperparameters | Opgeslagen als sleutel-waardeparen. Zowel sleutels als waarden zijn tekenreeksen. |
| Metrics | Voer metrische gegevens uit die zijn opgeslagen als sleutel-waardeparen. De waarde is numeriek. |
| Modelschema/handtekening | Een beschrijving van de modelinvoer en -uitvoer. |
| Vastgelegde bestanden | Gelogde bestanden in elke indeling. U kunt bijvoorbeeld afbeeldingen, omgeving, modellen en gegevensbestanden vastleggen. |
| tags | Aangepaste metagegevens als sleutel-waardeparen die zijn gekoppeld aan uitvoeringen. Meer informatie over het toepassen van tags. |
Tags toepassen op machine learning-modellen
Met MLflow-tagging voor modelversies kunnen gebruikers aangepaste metagegevens koppelen aan specifieke versies van een geregistreerd model in het MLflow-modelregister. Deze tags, opgeslagen als sleutel-waardeparen, helpen organiseren, bijhouden en onderscheid maken tussen modelversies, waardoor het eenvoudiger is om modellevenscycli te beheren. Tags kunnen worden gebruikt om het doel, de implementatieomgeving of andere relevante informatie van het model aan te geven, waardoor het efficiënter modelbeheer en besluitvorming binnen teams wordt vergemakkelijkt.
Deze code laat zien hoe u een RandomForestRegressor-model traint met scikit-learn, het model en de parameters registreert met MLflow en het model vervolgens registreert in het MLflow-modelregister met aangepaste tags. Deze tags bieden nuttige metagegevens, zoals projectnaam, afdeling, team en projectkwartaal, waardoor het eenvoudiger is om de modelversie te beheren en bij te houden.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
Nadat u de tags hebt toegepast, kunt u deze rechtstreeks bekijken op de pagina met details van de modelversie. Bovendien kunnen tags op elk gewenst moment worden toegevoegd, bijgewerkt of verwijderd van deze pagina.

Machine Learning-modellen vergelijken en filteren
Als u de kwaliteit van machine learning-modelversies wilt vergelijken en evalueren, kunt u de parameters, metrische gegevens en metagegevens tussen geselecteerde versies vergelijken.
Machine Learning-modellen visueel vergelijken
U kunt uitvoeringen visueel vergelijken binnen een bestaand model. Met visuele vergelijking kunt u eenvoudig navigeren tussen en sorteren in meerdere versies.

Als u uitvoeringen wilt vergelijken, kunt u het volgende doen:
- Selecteer een bestaand machine learning-model dat meerdere versies bevat.
- Selecteer het tabblad Weergave en navigeer naar de lijstweergave Model . U kunt ook de optie selecteren om de modellijst rechtstreeks vanuit de detailweergave weer te geven.
- U kunt de kolommen in de tabel aanpassen. Vouw het deelvenster Kolommen aanpassen uit. Hier kunt u de eigenschappen, metrische gegevens, tags en hyperparameters selecteren die u wilt zien.
- Ten slotte kunt u meerdere versies selecteren om hun resultaten te vergelijken in het deelvenster met metrische gegevens. In dit deelvenster kunt u de grafieken aanpassen met wijzigingen in de grafiektitel, visualisatietype, X-as, Y-as en meer.
Machine Learning-modellen vergelijken met behulp van de MLflow-API
Gegevenswetenschappers kunnen MLflow ook gebruiken om te zoeken naar meerdere modellen die zijn opgeslagen in de werkruimte. Ga naar de MLflow-documentatie om andere MLflow-API's te verkennen voor modelinteractie.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Machine Learning-modellen toepassen
Zodra u een model hebt getraind op een gegevensset, kunt u dat model toepassen op gegevens die het nooit eerder heeft gezien om voorspellingen te genereren. We noemen dit modeltoepassingstechniek scoring of inferentie.
Fabric ondersteunt meerdere benaderingen voor het toepassen van uw getrainde modellen:
- Batchgewijs scoren Pas uw model op schaal toe op grote gegevenssets met behulp van Apache Spark. Dit is ideaal voor het genereren van voorspellingen over historische of geplande gegevens.
- Realtime scoren Implementeer uw model op een eindpunt voor voorspellingen op aanvraag, handig voor toepassingen die onmiddellijke resultaten nodig hebben.
Kies de aanpak die past bij uw scenario om aan de slag te gaan met het toepassen van uw modellen: