Zelfstudie: Functionele afhankelijkheden in een semantisch model analyseren
In deze zelfstudie bouwt u voort op eerder werk dat is uitgevoerd door een Power BI-analist en opgeslagen in de vorm van semantische modellen (Power BI-gegevenssets). Door SemPy (preview) te gebruiken in de Synapse-Datawetenschap-ervaring in Microsoft Fabric, analyseert u functionele afhankelijkheden die aanwezig zijn in kolommen van een DataFrame. Deze analyse helpt bij het detecteren van problemen met niet-triviale gegevenskwaliteit om nauwkeurigere inzichten te verkrijgen.
In deze zelfstudie leert u het volgende:
- Pas domeinkennis toe om hypothesen te formuleren over functionele afhankelijkheden in een semantisch model.
- Vertrouwd raken met onderdelen van de Python-bibliotheek (SemPy) van semantische koppelingen die ondersteuning bieden voor integratie met Power BI en helpen bij het automatiseren van analyse van gegevenskwaliteit. Deze onderdelen zijn onder andere:
- FabricDataFrame- een pandas-achtige structuur die is uitgebreid met aanvullende semantische informatie.
- Handige functies voor het ophalen van semantische modellen uit een Fabric-werkruimte in uw notebook.
- Nuttige functies die de evaluatie van hypothesen over functionele afhankelijkheden automatiseren en waarmee schendingen van relaties in uw semantische modellen worden geïdentificeerd.
Vereisten
Haal een Microsoft Fabric-abonnement op. Of meld u aan voor een gratis proefversie van Microsoft Fabric.
Meld u aan bij Microsoft Fabric.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar de Synapse-Datawetenschap-ervaring.
Selecteer Werkruimten in het linkernavigatiedeelvenster om uw werkruimte te zoeken en te selecteren. Deze werkruimte wordt uw huidige werkruimte.
Download het semantische model Customer Profitability Sample.pbix uit de GitHub-opslagplaats fabric-samples en upload het naar uw werkruimte.
Volgen in het notitieblok
De notebook powerbi_dependencies_tutorial.ipynb begeleidt deze zelfstudie.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden voor zelfstudies voor gegevenswetenschap om het notebook te importeren in uw werkruimte.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Het notebook instellen
In deze sectie stelt u een notebookomgeving in met de benodigde modules en gegevens.
Installeren
SemPyvanuit PyPI met behulp van de%pipinline-installatiemogelijkheid in het notebook:%pip install semantic-linkVoer de benodigde importbewerkingen uit van modules die u later nodig hebt:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
De gegevens laden en vooraf verwerken
In deze zelfstudie wordt gebruikgemaakt van een standaard semantisch model Customer Profitability Sample.pbix. Zie het voorbeeld klantwinstgevendheid voor Power BI voor een beschrijving van het semantische model.
Laad de Power BI-gegevens in FabricDataFrames met behulp van de functie van
read_tableSemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Laad de
Statetabel in een FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Hoewel de uitvoer van deze code eruitziet als een Pandas DataFrame, hebt u in feite een gegevensstructuur geïnitialiseerd die
FabricDataFrameeen aantal nuttige bewerkingen boven op pandas ondersteunt.Controleer het gegevenstype van
customer:type(customer)De uitvoer bevestigt dat
customerhet van het typesempy.fabric._dataframe._fabric_dataframe.FabricDataFrameis.'Neem deel aan de
customerenstateDataFrames:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Functionele afhankelijkheden identificeren
Een functionele afhankelijkheid manifesteert zich als een een-op-veel-relatie tussen de waarden in twee (of meer) kolommen binnen een DataFrame. Deze relaties kunnen worden gebruikt om problemen met gegevenskwaliteit automatisch te detecteren.
Voer de functie van
find_dependenciesSemPy uit op het samengevoegde DataFrame om bestaande functionele afhankelijkheden tussen waarden in de kolommen te identificeren:dependencies = customer_state_df.find_dependencies() dependenciesVisualiseer de geïdentificeerde afhankelijkheden met behulp van de functie van
plot_dependency_metadataSemPy:plot_dependency_metadata(dependencies)
Zoals verwacht laat de grafiek met functionele afhankelijkheden zien dat de
Customerkolom bepaalde kolommen zoalsCity,Postal CodeenName.Verrassend genoeg toont de grafiek geen functionele afhankelijkheid tussen
CityenPostal Code, waarschijnlijk omdat er veel schendingen zijn in de relaties tussen de kolommen. U kunt de functie vanplot_dependency_violationsSemPy gebruiken om schendingen van afhankelijkheden tussen specifieke kolommen te visualiseren.

De gegevens voor kwaliteitsproblemen verkennen
Teken een grafiek met de visualisatiefunctie van
plot_dependency_violationsSemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
In de plot met afhankelijkheidsschendingen ziet u waarden voor
Postal Codeaan de linkerkant en waarden voorCityaan de rechterkant. Een rand verbindt eenPostal Codeaan de linkerkant met eenCityaan de rechterkant als er een rij is die deze twee waarden bevat. De randen worden geannoteerd met het aantal van dergelijke rijen. Er zijn bijvoorbeeld twee rijen met postcode 20004, één met de plaats 'North Tower' en de andere met de stad 'Washington'.Bovendien toont de plot enkele schendingen en veel lege waarden.
Bevestig het aantal lege waarden voor
Postal Code:customer_state_df['Postal Code'].isna().sum()50 rijen hebben NA voor postcode.
Rijen verwijderen met lege waarden. Zoek vervolgens afhankelijkheden met behulp van de
find_dependenciesfunctie. Let op de extra parameterverbose=1die een glimp biedt van de interne werking van SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)De voorwaardelijke entropie voor
Postal CodeenCityis 0,049. Deze waarde geeft aan dat er functionele afhankelijkheidsschendingen zijn. Voordat u de schendingen oplost, verhoogt u de drempelwaarde voor voorwaardelijke entropie van de standaardwaarde naar0.010.05, alleen om de afhankelijkheden te zien. Lagere drempelwaarden resulteren in minder afhankelijkheden (of hogere selectiviteit).Verhoog de drempelwaarde voor voorwaardelijke entropie van de standaardwaarde tot
0.010.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))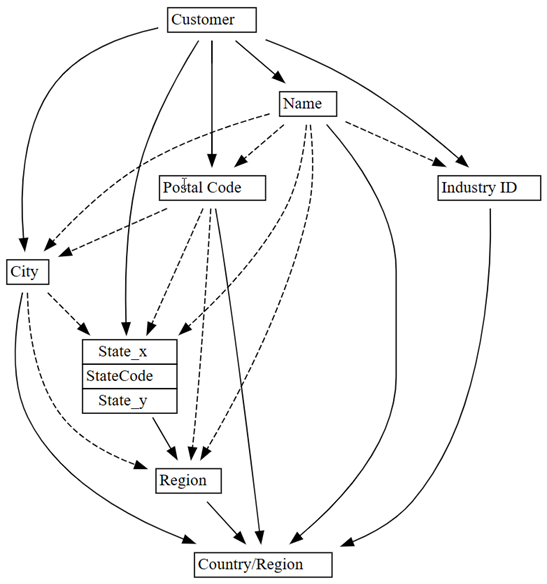
Als u domeinkennis toepast van welke entiteit waarden van andere entiteiten bepaalt, lijkt deze afhankelijkhedengrafiek nauwkeurig.
Verken meer problemen met de kwaliteit van gegevens die zijn gedetecteerd. Een gestreepte pijl wordt bijvoorbeeld samengevoegd
CityenRegion, wat aangeeft dat de afhankelijkheid alleen bij benadering is. Deze benaderingsrelatie kan betekenen dat er sprake is van een gedeeltelijke functionele afhankelijkheid.customer_state_df.list_dependency_violations('City', 'Region')Bekijk elk van de gevallen waarin een lege
Regionwaarde een schending veroorzaakt:customer_state_df[customer_state_df.City=='Downers Grove']Het resultaat toont Downers Grove city die plaatsvindt in Illinois en Nebraska. Downer's Grove is echter een stad in Illinois, niet Nebraska.
Kijk eens naar de stad F oplopend:
customer_state_df[customer_state_df.City=='Fremont']Er is een stad genaamd F oplopend in Californië. Voor Texas retourneert de zoekmachine Echter Premont, niet Fopgegeven.
Het is ook verdacht om schendingen van de afhankelijkheid tussen
NameenCountry/Region, zoals opgegeven door de stippellijn in de oorspronkelijke grafiek van afhankelijkheidsschendingen te zien (voordat de rijen met lege waarden worden verwijderd).customer_state_df.list_dependency_violations('Name', 'Country/Region')Het lijkt erop dat één klant, SDI Design aanwezig is in twee regio's: Verenigde Staten en Canada. Deze gebeurtenis is mogelijk geen semantische schending, maar kan gewoon een ongebruikelijk geval zijn. Toch is het de moeite waard om een kijkje te nemen:
Bekijk het SDI-ontwerp van de klant:
customer_state_df[customer_state_df.Name=='SDI Design']Verder onderzoek laat zien dat het eigenlijk twee verschillende klanten (uit verschillende branches) met dezelfde naam is.

Verkennende gegevensanalyse is een spannend proces en dus gegevens opschonen. Er is altijd iets dat de gegevens verbergen, afhankelijk van hoe u deze bekijkt, wat u wilt vragen, enzovoort. Semantische koppeling biedt u nieuwe hulpprogramma's die u kunt gebruiken om meer te bereiken met uw gegevens.
Gerelateerde inhoud
Bekijk andere zelfstudies voor semantische koppeling /SemPy:
- Zelfstudie: Gegevens opschonen met functionele afhankelijkheden
- Zelfstudie: Power BI-metingen extraheren en berekenen uit een Jupyter-notebook
- Zelfstudie: Relaties ontdekken in een semantisch model met behulp van een semantische koppeling
- Zelfstudie: Relaties ontdekken in de Synthea-gegevensset met behulp van een semantische koppeling
- Zelfstudie: Gegevens valideren met Behulp van SemPy en Grote Verwachtingen (GX) (preview)