Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: ✅ Warehouse in Microsoft Fabric
In dit artikel worden de migratiemethoden van datawarehousing in toegewezen SQL-pools van Azure Synapse Analytics naar Microsoft Fabric Warehouse beschreven.
Hint
Zie Migratieplanning: toegewezen SQL-pools van Azure Synapse Analytics naar Fabric Data Warehousevoor meer informatie over strategie en planning van uw migratie.
Een geautomatiseerde ervaring voor migratie vanuit toegewezen SQL-pools van Azure Synapse Analytics is beschikbaar met behulp van de Fabric Migration Assistant voor datawarehouse-ondersteuning. De rest van dit artikel bevat meer handmatige migratiestappen.
Deze tabel bevat informatie over gegevensschema's (DDL), databasecode (DML) en gegevensmigratiemethoden. Verderop in dit artikel gaan we verder in op elk scenario, gekoppeld aan de kolom Optie .
| Optienummer | Optie | Wat het doet | Vaardigheid/voorkeur | Scenariobeschrijving |
|---|---|---|---|---|
| 1 | Data Factory | Schema (DDL-conversie) Gegevensextract Gegevensopname |
ADF/Pijplijn | Alles vereenvoudigd in één schema (DDL) en gegevensmigratie. Aanbevolen voor dimensietabellen. |
| 2 | Data Factory met partitie | Schema (DDL-conversie) Gegevensextract Gegevensopname |
ADF/Pijplijn | Partitioneringsopties gebruiken om parallel lezen/schrijven te verhogen, wat tien keer de doorvoer biedt in vergelijking met optie 1 en wordt aanbevolen voor feitentabellen. |
| 3 | Data Factory met versnelde codering | Schema (DDL-conversie) | ADF/Pijplijn | Converteer en migreer eerst het schema (DDL), gebruik vervolgens CETAS om gegevens te extraheren en COPY/Data Factory om gegevens in te voeren, voor optimale algehele invoerprestaties. |
| 4 | Versnelde code voor opgeslagen procedures | Schema (DDL-conversie) Gegevensextract Codebeoordeling |
T-SQL | SQL-gebruiker die IDE gebruikt met gedetailleerdere controle over de taken waaraan ze willen werken. Gebruik COPY/Data Factory om gegevens op te nemen. |
| 5 | SQL Database Project-extensie voor Visual Studio Code | Schema (DDL-conversie) Gegevensextract Codebeoordeling |
SQL Project | SQL Database Project voor implementatie met de integratie van optie 4. Gebruik COPY of Data Factory om gegevens op te nemen. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Gegevensextract | T-SQL | Kosteneffectieve en krachtige gegevensextractie naar Azure Data Lake Storage (ADLS) Gen2. Gebruik COPY/Data Factory om gegevens op te nemen. |
| 7 | Migreren met behulp van dbt | Schema (DDL-conversie) database code (DML) conversie |
dbt | Bestaande dbt-gebruikers kunnen de dbt Fabric-adapter gebruiken om hun DDL en DML te converteren. Vervolgens moet u gegevens migreren met behulp van andere opties in deze tabel. |
Een workload kiezen voor de eerste migratie
Wanneer u besluit waar u wilt beginnen met de toegewezen SQL-pool van Synapse naar het migratieproject fabricwarehouse, kiest u een werkbelastinggebied waar u het volgende kunt doen:
- De levensvatbaarheid van de migratie naar Fabric Warehouse bewijzen door snel de voordelen van de nieuwe omgeving te bieden. Begin klein en eenvoudig, bereid u voor op meerdere kleine migraties.
- Geef uw interne technische medewerkers de tijd om relevante ervaring te krijgen met de processen en hulpprogramma's die ze gebruiken wanneer ze migreren naar andere gebieden.
- Maak een sjabloon voor verdere migraties die specifiek zijn voor de Synapse-bronomgeving en de hulpprogramma's en processen die u hierbij kunt helpen.
Hint
Maak een inventaris van objecten die moeten worden gemigreerd en documenteer het migratieproces van begin tot eind, zodat het kan worden herhaald voor andere toegewezen SQL-pools of -workloads.
Het volume van gemigreerde gegevens in een eerste migratie moet groot genoeg zijn om de mogelijkheden en voordelen van de Fabric Warehouse-omgeving te demonstreren, maar niet te groot om snel waarde te demonstreren. Een grootte in het bereik van 1-10 terabyte is typisch.
Migratie met Fabric Data Factory
In deze sectie bespreken we de opties die Data Factory gebruiken voor de persona met weinig code/geen code die bekend zijn met Azure Data Factory en Synapse Pipeline. Deze sleep-en-neerzet optie biedt een eenvoudige stap om de DDL te converteren en de gegevens te migreren.
Fabric Data Factory kan de volgende taken uitvoeren:
- Converteer het schema (DDL) naar de syntaxis van fabricwarehouse.
- Maak het schema (DDL) in Fabric Warehouse.
- Migreer de gegevens naar Fabric Warehouse.
Optie 1. Schema/gegevensmigratie - Kopiëren-Wizard en ForEach-Kopieeractiviteit
Deze methode gebruikt Data Factory Copy Assistant om verbinding te maken met de toegewezen SQL-brongroep, de DDL-syntaxis van de toegewezen SQL-pool te converteren naar Fabric en gegevens te kopiëren naar Fabric Warehouse. U kunt een of meer doeltabellen selecteren (voor TPC-DS gegevensset zijn er 22 tabellen). Het genereert de ForEach om door de lijst van tabellen te lopen die in de gebruikersinterface (UI) zijn geselecteerd en 22 parallelle Copy Activity-draadprocessen te starten.
- 22 SELECT-query's (één voor elke geselecteerde tabel) zijn gegenereerd en uitgevoerd in de toegewezen SQL-pool.
- Zorg ervoor dat u de juiste DWU en resourceklasse hebt om toe te staan dat de query's die worden gegenereerd, worden uitgevoerd. Voor dit geval hebt u minimaal DWU1000 met
staticrc10nodig om maximaal 32 query's mogelijk te maken, zodat 22 ingediende query's afgehandeld kunnen worden. - Gegevens direct kopiëren van de dedicated SQL pool naar de Fabric Warehouse met Data Factory vereist staging. Het opnameproces bestond uit twee fasen.
- De eerste fase bestaat uit het extraheren van de gegevens uit de toegewezen SQL-pool in ADLS en wordt fasering genoemd.
- De tweede fase bestaat uit het inladen van de gegevens uit het staginggebied in Fabric Warehouse. De meeste timing voor gegevensinvoer bevindt zich in de uitvoeringsfase. Kortom, fasering heeft een enorme invloed op opnameprestaties.
Aanbevolen gebruik
Met behulp van de wizard Kopiëren om een ForEach te genereren, kunt u DDL eenvoudig converteren en de geselecteerde tabellen uit de toegewezen SQL-pool in één stap naar Fabric Warehouse opnemen.
Ondanks dat is het niet optimaal voor de totale doorvoer. De vereiste voor het gebruik van fasering, de noodzaak om lezen en schrijven voor de stap Bron naar fase te parallelliseren zijn de belangrijkste factoren voor de prestatielatentie. Het is raadzaam deze optie alleen te gebruiken voor dimensietabellen.
Optie 2. DDL/Gegevensmigratie - Pijplijn met partitieoptie
Als u de doorvoer wilt verbeteren om grotere feitentabellen te laden met behulp van een Fabric-pijplijn, wordt aangeraden de Kopieeractiviteit te gebruiken voor elke feitentabel met de partitieoptie. Dit biedt de beste prestaties voor de kopieeractiviteit.
U kunt de fysieke partitionering van de brontabel gebruiken, indien beschikbaar. Als tabel geen fysieke partitionering heeft, moet u de partitiekolom opgeven en min/max-waarden opgeven om dynamische partitionering te gebruiken. In de volgende schermopname geven de opties voor de pijplijnbron een dynamisch bereik van partities op op basis van de ws_sold_date_sk kolom.
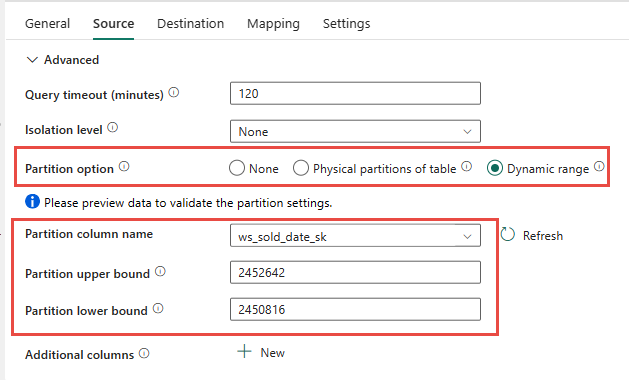
Hoewel het gebruik van partities de doorvoer tijdens de faseringsfase kan verhogen, moeten er overwegingen worden gemaakt om de juiste aanpassingen door te voeren.
- Afhankelijk van uw partitiebereik kan het mogelijk alle gelijktijdigheidssleuven gebruiken, omdat er meer dan 128 query's in de toegewezen SQL-pool kunnen worden gegenereerd.
- U moet schalen tot een minimum van DWU6000 zodat alle query's kunnen worden uitgevoerd.
- Voor de TPC-DS-tabel
web_saleszijn er bijvoorbeeld 163 query's verzonden naar de toegewezen SQL-pool. Op DWU6000 werden 128 query's uitgevoerd terwijl 35 query's in de wachtrij werden geplaatst. - Dynamische partitie selecteert automatisch de bereik-partitie. In dit geval is er een bereik van 11 dagen voor elke SELECT-query die is verzonden naar de toegewezen SQL-pool. Bijvoorbeeld:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Aanbevolen gebruik
Voor feitentabellen is het raadzaam om Data Factory te gebruiken met partitioneringsoptie om de doorvoer te verhogen.
De toegenomen geparallelliseerde leesbewerkingen vereisen echter dat een toegewezen SQL-pool wordt geschaald naar een hogere DWU, zodat de extractquery's kunnen worden uitgevoerd. Door gebruik te maken van partitionering, wordt de snelheid tien keer verbeterd ten opzichte van een partitieoptie zonder partitie. U kunt de DWU verhogen om extra doorvoer te krijgen via rekenresources, maar de toegewezen SQL-pool heeft maximaal 128 actieve query's toegestaan.
Voor meer informatie over Synapse DWU to Fabric-toewijzing raadpleegt u Blog: Toegewezen SQL-pools van Azure Synapse toewijzen aan Fabric Data Warehouse-rekenkracht.
Optie 3. DDL-migratie - Kopieerwizard voor elke kopieeractiviteit
De twee vorige opties zijn geweldige opties voor gegevensmigratie voor kleinere databases. Maar als u een hogere doorvoer nodig hebt, raden we een alternatieve optie aan:
- Pak de gegevens uit de toegewezen SQL-pool uit naar ADLS, waardoor de overhead van de prestatiestap wordt beperkt.
- Gebruik Data Factory of de opdracht COPY om de gegevens op te nemen in Fabric Warehouse.
Aanbevolen gebruik
U kunt Data Factory blijven gebruiken om uw schema (DDL) te converteren. Met de wizard Kopiëren kunt u de specifieke tabel of alle tabellen selecteren. Hiermee worden het schema en de gegevens in één stap gemigreerd, waarbij het schema zonder rijen wordt geëxtraheerd, met behulp van de onwaarvoorwaarde, TOP 0 in de query-instructie.
In het volgende codevoorbeeld wordt de schemamigratie (DDL) behandeld met Data Factory.
Codevoorbeeld: Schemamigratie (DDL) met Data Factory
U kunt Fabric Pipelines gebruiken om eenvoudig te migreren via uw DDL (schema's) voor tabelobjecten uit elke azure SQL Database-bron of toegewezen SQL-pool. Deze pijplijn wordt gemigreerd via het schema (DDL) voor de toegewezen SQL-pooltabellen van de bron naar Fabric Warehouse.
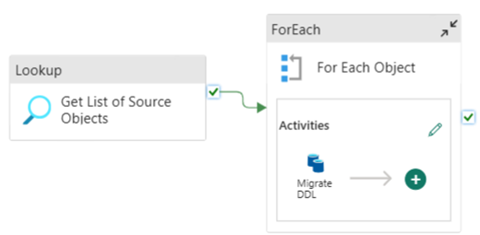
Pijplijnontwerp: parameters
Deze pijplijn accepteert een parameter SchemaName, waarmee u kunt opgeven welke schema's moeten worden gemigreerd. Het dbo schema is de standaardinstelling.
Voer in het veld Standaardwaarde een door komma's gescheiden lijst met tabelschema's in die aangeven welke schema's moeten worden gemigreerd: 'dbo','tpch' om twee schema's op te geven, dbo en tpch.
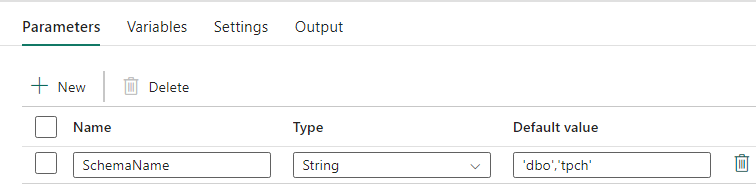
Pijplijnontwerp: Opzoekactiviteit
Maak een opzoekactiviteit en stel de verbinding in zodat deze verwijst naar uw brondatabase.
Op het tabblad Instellingen :
Stel het gegevensarchieftype in op Extern.
Verbinding is uw toegewezen SQL-pool van Azure Synapse. Verbindingstype is Azure Synapse Analytics.
Gebruik query is ingesteld op Query.
Het queryveld moet worden gebouwd met behulp van een dynamische expressie, zodat de parameter SchemaName kan worden gebruikt in een query die een lijst met doelbrontabellen retourneert. Selecteer Query en selecteer Dynamische inhoud toevoegen.
Deze expressie in de LookUp-activiteit genereert een SQL-instructie om een query uit te voeren op de systeemweergaven om een lijst met schema's en tabellen op te halen. Verwijst naar de parameter SchemaName om filteren op SQL-schema's mogelijk te maken. De uitvoer hiervan is een matrix van SQL-schema en -tabellen die worden gebruikt als invoer in de ForEach-activiteit.
Gebruik de volgende code om een lijst met alle gebruikerstabellen met hun schemanaam te retourneren.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
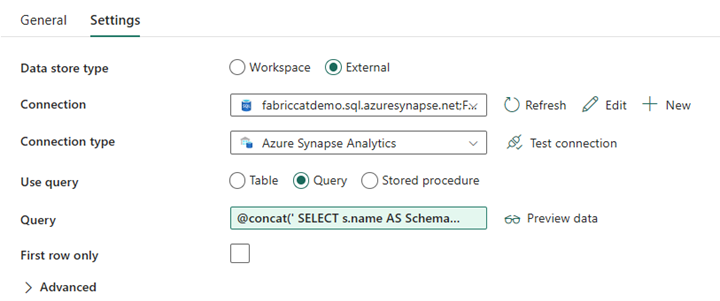
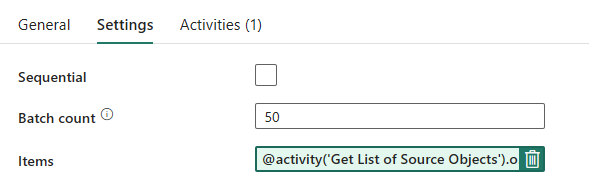
Pijplijnontwerp: ForEach-lus
Configureer voor de ForEach-lus de volgende opties op het tabblad Instellingen :
- Schakel sequentiële functie uit om meerdere iteraties gelijktijdig uit te voeren.
- Stel batchaantal in op
50, waardoor het maximum aantal gelijktijdige iteraties wordt beperkt. - Het veld Items moet dynamische inhoud gebruiken om te verwijzen naar de uitvoer van de lookup-activiteit. Gebruik het volgende codefragment:
@activity('Get List of Source Objects').output.value
Pijplijnontwerp: Kopieeractiviteit binnen de ForEach-lus
Voeg in de ForEach-activiteit een kopieeractiviteit toe. Deze methode maakt gebruik van de Dynamische Expressietaal binnen pijplijnen om alleen het schema zonder gegevens naar een Fabric Warehouse te migreren.
Op het tabblad Bron :
- Stel het gegevensarchieftype in op Extern.
- Verbinding is uw toegewezen SQL-pool van Azure Synapse. Verbindingstype is Azure Synapse Analytics.
- Stel Use Query in naar Query.
- Plak in het veld Query de query voor dynamische inhoud en gebruik deze expressie die nul rijen retourneert, alleen het tabelschema:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Op het tabblad Bestemming :
- Stel het type van datastore in op Werkruimte.
- Het type gegevensarchieftype voor de Werkruimte is Data Warehouse en het Data Warehouse is ingesteld op de Fabric Warehouse.
- De schema- en tabelnaam van de doeltabel worden gedefinieerd met dynamische inhoud.
- Schema verwijst naar het veld van de huidige iteratie, SchemaName met het fragment:
@item().SchemaName - Tabel verwijst naar TableName met het codefragment:
@item().TableName
- Schema verwijst naar het veld van de huidige iteratie, SchemaName met het fragment:

Pijplijnontwerp: Afvoer
Voor Sink wijs je naar je Warehouse en verwijs je naar het bron-schema en de tabelnaam.
Zodra u deze pijplijn hebt uitgevoerd, ziet u dat uw datawarehouse is gevuld met elke tabel in uw bron, met het juiste schema.
Migratie met behulp van opgeslagen procedures in toegewezen SQL-pool van Synapse
Deze optie maakt gebruik van opgeslagen procedures om de Fabric-migratie uit te voeren.
U kunt de codevoorbeelden ophalen bij microsoft/fabric-migratie op GitHub.com. Deze code wordt gedeeld als open source, dus u kunt gerust bijdragen aan samenwerking en de community helpen.
Wat Migration Stored Procedures kunnen doen:
- Converteer het schema (DDL) naar de syntaxis van fabricwarehouse.
- Maak het schema (DDL) in Fabric Warehouse.
- Extraheer gegevens uit de toegewezen SQL-pool van Synapse naar ADLS.
- Markeer de niet-ondersteunde Infrastructuursyntaxis voor T-SQL-codes (opgeslagen procedures, functies, weergaven).
Aanbevolen gebruik
Dit is een uitstekende optie voor degenen die:
- Bekend met T-SQL.
- U wilt een geïntegreerde ontwikkelomgeving gebruiken, zoals SQL Server Management Studio (SSMS).
- Meer gedetailleerde controle over de taken waaraan ze willen werken.
U kunt de specifieke opgeslagen procedure uitvoeren voor de DDL-conversie (schema), gegevensextract of T-SQL-code-evaluatie.
Voor de gegevensmigratie moet u COPY INTO of Data Factory gebruiken om de gegevens op te nemen in Fabric Warehouse.
Migreren met behulp van SQL-databaseprojecten
Microsoft Fabric Data Warehouse wordt ondersteund in de SQL Database Projects-extensie die beschikbaar is in Visual Studio Code.
Deze extensie is beschikbaar in Visual Studio Code. Deze functie maakt mogelijkheden mogelijk voor broncodebeheer, databasetests en schemavalidatie.
Zie Broncodebeheer met Warehouse voor meer informatie over broncodebeheer voor magazijnen in Microsoft Fabric, waaronder Git-integratie- en implementatiepijplijnen.
Aanbevolen gebruik
Dit is een uitstekende optie voor degenen die liever SQL Database Project gebruiken voor hun implementatie. Met deze optie zijn de opgeslagen procedures voor infrastructuurmigratie in het SQL Database-project geïntegreerd om een naadloze migratie-ervaring te bieden.
Een SQL Database-project kan het volgende doen:
- Converteer het schema (DDL) naar de syntaxis van fabricwarehouse.
- Maak het schema (DDL) in Fabric Warehouse.
- Extraheer gegevens uit de toegewezen SQL-pool van Synapse naar ADLS.
- Markeer niet-ondersteunde syntaxis voor T-SQL-codes (opgeslagen procedures, functies, weergaven).
Voor de gegevensmigratie gebruikt u vervolgens COPY INTO of Data Factory om de gegevens op te nemen in Fabric Warehouse.
Het Microsoft Fabric CAT-team heeft een set PowerShell-scripts verstrekt voor het afhandelen van de extractie, het maken en implementeren van schema (DDL) en databasecode (DML) via een SQL Database-project. Zie microsoft/fabric-migratie op GitHub.com voor een overzicht van het gebruik van het SQL Database-project met onze nuttige PowerShell-scripts.
Zie Aan de slag met de extensie SQL Database Projects en een databaseproject maken vanaf de opdrachtregel voor meer informatie over SQL Database Projects.
Migratie van gegevens met CETAS
De opdracht T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) biedt de meest rendabele en optimale methode voor het extraheren van gegevens uit toegewezen Synapse SQL-pools naar Azure Data Lake Storage (ADLS) Gen2.
Wat CETAS kan doen:
- Gegevens extraheren in ADLS.
- Voor deze optie moeten gebruikers het schema (DDL) in Fabric Warehouse maken voordat ze de gegevens opnemen. Overweeg de opties in dit artikel om het schema (DDL) te migreren.
De voordelen van deze optie zijn:
- Er wordt slechts één query per tabel verzonden op basis van de toegewezen SQL-brongroep van Synapse. Hiermee worden niet alle gelijktijdigheidsplaatsen gebruikt en blokkeren ze dus niet de gelijktijdige productie-ETL/query's van klanten.
- Schalen naar DWU6000 is niet vereist, aangezien er slechts één gelijktijdigheidsslot wordt gebruikt voor elke tabel, zodat klanten lagere DWU's kunnen gebruiken.
- Het extract wordt parallel uitgevoerd op alle rekenknooppunten en dit is de sleutel tot verbetering van de prestaties.
Aanbevolen gebruik
Gebruik CETAS om de gegevens te extraheren naar ADLS als Parquet-bestanden. Parquet-bestanden bieden het voordeel van efficiënte gegevensopslag met kolomcompressie die minder bandbreedte in beslag neemt om over het netwerk te gaan. Bovendien, omdat Fabric de gegevens opslaat in Delta Parquet-formaat, is het opnemen van gegevens 2,5 keer sneller vergeleken met een tekstbestandindeling, omdat er tijdens de opname geen overhead bij de conversie naar het Delta-formaat is.
CeTAS-doorvoer verhogen:
- Voeg parallelle CETAS-bewerkingen toe, waardoor het gebruik van gelijktijdigheidssloten wordt verhoogd en er meer doorvoer mogelijk is.
- Schaal de DWU in de toegewezen SQL-pool van Synapse.
Migratie via dbt
In deze sectie bespreken we de dbt-optie voor klanten die al dbt gebruiken in hun huidige toegewezen SQL-poolomgeving van Synapse.
Wat dbt kan doen:
- Converteer het schema (DDL) naar de syntaxis van fabricwarehouse.
- Maak het schema (DDL) in Fabric Warehouse.
- Databasecode (DML) omzetten naar Fabric-syntaxis.
Het dbt-framework genereert DDL- en DML-scripts (SQL-scripts) op elk gewenst moment met elke uitvoering. Met modelbestanden die worden uitgedrukt in SELECT-instructies, kan de DDL/DML direct worden vertaald naar elk doelplatform door het profiel (verbindingsreeks) en het adaptertype te wijzigen.
Aanbevolen gebruik
Het dbt-framework is een code-first aanpak. De gegevens moeten worden gemigreerd met behulp van opties die worden vermeld in dit document, zoals CETAS of COPY/Data Factory.
Met de dbt-adapter voor Microsoft Fabric Data Warehouse kunnen de bestaande dbt-projecten die zijn gericht op verschillende platforms, zoals toegewezen Synapse SQL-pools, Snowflake, Databricks, Google Big Query of Amazon Redshift, worden gemigreerd naar een Fabric Warehouse met een eenvoudige configuratiewijziging.
Zie Zelfstudie: Dbt instellen voor Fabric Data Warehouse om aan de slag te gaan met een dbt-project dat gericht is op Fabric Warehouse. Dit document bevat ook een optie om te schakelen tussen verschillende magazijnen/platforms.
Gegevensopname in Fabric Warehouse
Voor opname in Fabric Warehouse gebruikt u COPY INTO of Fabric Data Factory, afhankelijk van uw voorkeur. Beide methoden zijn de aanbevolen en best presterende opties, omdat ze een equivalente prestatiedoorvoer hebben, gezien de vereiste dat de bestanden al zijn geëxtraheerd naar Azure Data Lake Storage (ADLS) Gen2.
Verschillende factoren waarmee u rekening moet houden, zodat u uw proces kunt ontwerpen voor maximale prestaties:
- Met Fabric is er geen sprake van resourceconflicten bij het gelijktijdig laden van meerdere tabellen van ADLS naar Fabric Warehouse. Als gevolg hiervan is er geen prestatievermindering bij het laden van parallelle threads. De maximale verwerkingscapaciteit wordt alleen beperkt door de rekenkracht van uw Fabric-capaciteit.
- Het beheer van fabricworkloads biedt scheiding van resources die zijn toegewezen voor belasting- en querytaken. Er is geen conflicten tussen resources terwijl query's en het laden van gegevens tegelijkertijd worden uitgevoerd.
Verwante inhoud
- Fabric Migration Assistant voor Gegevensmagazijn
- Een magazijn maken in Microsoft Fabric
- Prestatierichtlijnen voor Fabric Data Warehouse
- Beveiliging voor datawarehousing in Microsoft Fabric
- Blog: Toegewezen SQL-pools van Azure Synapse toewijzen aan Fabric Data Warehouse-rekenkracht
- Overzicht van Migratie van Microsoft Fabric