Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Microsoft Fabric biedt meerdere manieren om gegevens in uw analyseomgeving te brengen. Of u nu streaminggebeurtenissen in realtime moet verwerken, operationele databases moet repliceren, batchpijplijnen moet organiseren of toegang wilt krijgen tot gegevens zonder deze te kopiëren, Fabric biedt ingebouwde mogelijkheden om elk scenario te ondersteunen.
In dit artikel worden de primaire opties voor gegevensopname en gegevensverplaatsing in Fabric beschreven. Hierin wordt het volgende behandeld:
- Real-time gegevensinvoer met Eventstreams en Eventhouse
- Batchindeling met Data Factory-pijplijnen en kopieertaak
- Bijna realtime replicatie met spiegeling
- Gegevensvirtualisatie met OneLake-snelkoppelingen
Gebruik dit overzicht om te begrijpen hoe elke benadering werkt en kies de strategie die het beste past bij uw workloadvereisten voor latentie, transformatie en operationele complexiteit.
Realtime gegevensopname
Eventstreams en Eventhouse-items in de Real-Time Intelligence-workload ondersteunen scenario's voor streaminggegevens. Eventstreams nemen realtime gebeurtenissen op en verwerken, en Eventhouses slaan deze gebeurtenissen op schaal op en doorzoeken deze gebeurtenissen. Normaal gesproken gebruikt u een Eventstream om gegevens vast te leggen en te routeren naar een Eventhouse. U kunt elke mogelijkheid ook onafhankelijk gebruiken op basis van uw vereisten. In het volgende diagram ziet u hoe realtime gegevenssets stromen naar Eventstream en Eventhouse in Fabric:
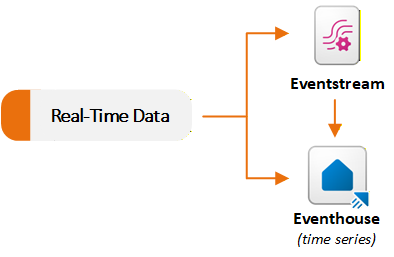
Gebeurtenissen opnemen en routeren met Eventstream
Eventstream biedt een ervaring zonder code voor het opnemen van gebeurtenissen in Fabric, het toepassen van in-streamtransformaties en het routeren van gegevens naar meerdere bestemmingen. Een Eventstream fungeert als een realtime opnamepijplijn. U maakt een Eventstream en voegt een of meer bronconnectors toe. Fabric ondersteunt veel streamingbronnen, waaronder interne Fabric-gebeurtenissen zoals Fabric-werkruimtegebeurtenissen, OneLake-bestandsgebeurtenissen en pipeline-jobgebeurtenissen.
Nadat gebeurtenissen beginnen te stromen, kunt u optionele realtime transformaties toepassen via een editor voor slepen en neerzetten. U kunt bijvoorbeeld gebeurtenissen filteren, tijdvensteraggregaties berekenen, meerdere streams samenvoegen of velden hervormen zonder code te schrijven.
U kunt de verwerkte stream verzenden naar een of meer ondersteunde bestemmingen. Eventstreams kunnen Apache Kafka-eindpunten beschikbaar maken via aangepaste eindpuntbronnen en bestemmingen. Met deze mogelijkheid kunnen Kafka-producenten gebeurtenissen streamen naar Fabric- en Kafka-consumenten om gebeurtenissen uit Fabric te gebruiken.
Eventstreams slaan geen gegevens permanent op. Ze streamen gebeurtenissen via het geheugen en sturen ze door naar geconfigureerde bestemmingen. Dit ontwerp maakt Eventstreams geschikt voor scenario's voor realtime extraheren, transformeren, laden (ETL) en voor het distribueren van streaminggegevens naar meerdere doelen. U kunt bijvoorbeeld telemetrie opnemen van IoT-sensoren (Internet of Things), gegevens in realtime filteren en aggregeren, de verfijnde stroom verzenden naar een Eventhouse voor analyse en anomaliegebeurtenissen routeren naar Activator voor waarschuwingen.
Gegevens rechtstreeks opnemen in Eventhouse
Eventhouses kunnen gegevens rechtstreeks uit meerdere bronnen opnemen. Fabric bevat een geïntegreerde Get-data ervaring in Eventhouse. De wizard maakt verbinding met bronnen zoals lokale bestanden, Azure Storage, Amazon S3, Azure Event Hubs en OneLake. U kunt gegevens in een KQL-databasetabel (Kusto Query Language) in realtime of batchmodus laden met behulp van de Eventhouse-gebruikersinterface.
U kunt ook een bestaande Eventstream in Fabric selecteren als bron. Als u bijvoorbeeld een Eventstream gebruikt waarmee gegevens worden opgenomen uit IoT Hub of Kafka, kunt u de uitvoer rechtstreeks doorsturen naar een KQL-databasetabel zonder extra configuratie.
Batchgegevensopname
Data Factory biedt de primaire ervaring voor traditionele pijplijnen voor extraheren, transformeren, laden (ETL) en extraheren, laden, transformeren (ELT). Het bevat een grote bibliotheek met connectors. Fabric Data Factory biedt een lijst met systeemeigen connectors voor on-premises en cloudgegevensarchieven, waaronder databases, SaaS-toepassingen (Software as a Service) en op bestanden gebaseerde systemen. Deze connectors helpen u verbinding te maken met vrijwel elk bronsysteem.
Gegevensverplaatsing organiseren met pijplijnen
U kunt pijplijnen bouwen die deze connectors gebruiken om gegevens te kopiëren of te verplaatsen naar OneLake of analytische opslag. Deze benadering ondersteunt:
- Ongestructureerde gegevenssets, zoals afbeeldingen, video en audio
- Semi-gestructureerde gegevenssets zoals JSON, CSV en XML
- Gestructureerde gegevenssets van ondersteunde relationele databasesystemen
In een pijplijn combineert u meerdere orkestratiecomponenten, waaronder:
- Activiteiten voor gegevensverplaatsing, zoals gegevens kopiëren en taak kopiëren
- Activiteiten voor gegevenstransformatie, zoals Dataflow Gen2, Gegevens verwijderen, Fabric Notebook en SQL-script
- Stroomactiviteiten beheren, zoals ForEach, Opzoeken, Variabele instellen en Webhook
U kunt een pijplijn op aanvraag, volgens een planning of als reactie op gebeurtenissen uitvoeren. U kunt bijvoorbeeld een pijplijn plannen om elke twee uur tijdens weekdagen uit te voeren of deze te activeren wanneer er een nieuw bestand wordt gemaakt in OneLake.
Gegevensverplaatsing vereenvoudigen met de kopieeropdracht
De kopieertaak ondersteunt meerdere patronen voor gegevenslevering, waaronder bulk kopiëren, incrementeel kopiëren en change data capture (CDC)-replicatie. U kunt de kopieertaak gebruiken om gegevens van een bron naar OneLake te verplaatsen zonder een pijplijn te maken, terwijl u nog steeds toegang hebt tot geavanceerde configuratieopties. Kopieeropdracht ondersteunt veel bronnen en bestemmingen. Het biedt meer controle dan spiegelen en minder operationele complexiteit dan het beheren van pijplijnen die gebruikmaken van de kopieeractiviteit.
Gegevens repliceren met spiegeling
Spiegeling repliceert gegevens van externe systemen nagenoeg realtime naar Fabric met een geautomatiseerde set-up. U maakt verbinding met een extern systeem, zoals Azure SQL Database, SQL Server, Oracle, SAP of Snowflake. Fabric repliceert continu gegevens of metagegevens naar OneLake. Spiegeling ondersteunt drie typen:
- Databasespiegeling repliceert volledige databases en tabellen.
- Met metagegevensspiegeling worden metagegevens zoals catalogusnamen, schema's en tabellen gesynchroniseerd in plaats van gegevens fysiek te verplaatsen. Deze benadering maakt gebruik van snelkoppelingen, zodat gegevens in het bronsysteem blijven terwijl ze nog steeds toegankelijk zijn in Fabric.
- Open mirroring maakt gebruik van de open Delta Lake-tabelindeling. Ontwikkelaars kunnen toepassingswijzigingen rechtstreeks naar een gespiegeld database-item in OneLake schrijven met behulp van openbare API's.
Fabric luistert naar wijzigingen in het bronsysteem (via wijzigingsgegevensopname of vergelijkbare methoden) en past deze wijzigingen in bijna realtime toe op de gespiegelde kopie. Het resultaat is een live, doorzoekbare gegevensset die gesynchroniseerd blijft met lage latentie, zonder complexe ETL-pijplijnen.
Spiegeling ondersteunt momenteel verschillende bronnen, waaronder Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake en SQL Server. Het ondersteunt ook gegevensbronnen van partneroplossingen die de Open Mirroring-API hebben geïmplementeerd. Gespiegelde gegevens worden opgeslagen in OneLake als up-to-date Delta-tabellen. Fabric onderhoudt deze tabellen automatisch, zodat u ze kunt gebruiken voor realtime analyses of deze kunt combineren met andere Fabric-gegevens. Deze mogelijkheid biedt ondersteuning voor scenario's voor hybride transactionele en analytische verwerking, waarbij operationele gegevens continu naar uw analyseplatform stromen.
Bij het gebruik van mirroring hoeft u geen incrementele loadpijplijnen handmatig te bouwen. Vanuit het perspectief van spiegelingskosten gebruiken rekenbewerkingen die gespiegelde databases in sync houden geen capaciteitseenheden (CA's) van uw Fabric-capaciteit. Gespiegelde gegevensopslag in OneLake is ook vrij tot de terabytelimiet in uw Infrastructuur-SKU (F64 bevat bijvoorbeeld 64 TB gratis gespiegelde databaseopslag).
Toegang tot externe gegevens met snelkoppelingen
Fabric biedt snelkoppelingen om gegevensvirtualisatie in te schakelen. Een snelkoppeling in OneLake verwijst naar gegevens die zijn opgeslagen in een extern systeem, zoals Azure Data Lake Storage Gen2, Amazon S3 of SharePoint. In plaats van gegevens te kopiëren, stellen snelkoppelingen OneLake in staat om externe bestanden als onderdeel van het geünificeerde Data Lake te verwijzen. U kunt externe gegevens opvragen of samenvoegen met lokale gegevens zonder dat u een initiële migratie hoeft uit te voeren. Deze benadering voor opname zonder kopiëren is handig wanneer vereisten voor gegevensopslaglocatie of problemen met gegevensduplicatie voorkomen dat gegevens worden verplaatst. In het volgende diagram ziet u hoe snelkoppelingen externe opslagsystemen verbinden met Fabric-items zonder gegevens te kopiëren:
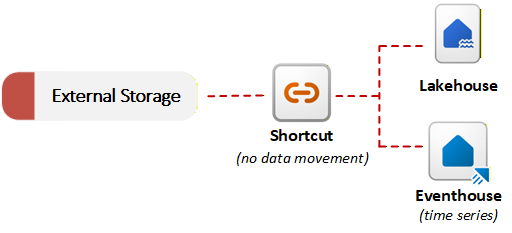
OneLake kan het gegevenstype detecteren waarnaar wordt verwezen door een snelkoppeling en bestandstransformaties of AI-transformaties toepassen zonder dat hiervoor een pijplijn of aangepaste code is vereist. In OneLake wordt de resulterende Delta-tabel automatisch gesynchroniseerd met de bron. U kunt bijvoorbeeld bestanden converteren .csv naar Delta-tabellen of sentimentanalyse op basis van AI toepassen op .txt bestanden in een map.
In combinatie met Mirroring, bieden snelkoppelingen u flexibele gegevensbenaderingspatronen. U kunt gegevens behouden met behulp van snelkoppelingen of u kunt gegevens repliceren met behulp van spiegeling. In beide gevallen zijn gegevens gereed voor Fabric-analysehulpprogramma's zonder complexe ETL.
Beslissingshandleiding: Een strategie voor gegevensverplaatsing kiezen
Microsoft Fabric biedt verschillende opties voor het overbrengen van gegevens naar Fabric, waaronder Eventstreams voor realtime verwerking, spiegeling, pijplijnen met kopieeractiviteiten, kopieertaak en snelkoppelingen. Elke optie biedt een ander evenwicht tussen controle, automatisering en operationele complexiteit.
Zie de beslissingshandleiding voor Microsoft Fabric voor hulp bij het selecteren van de juiste benadering voor uw scenario : Een strategie voor gegevensverplaatsing kiezen.