Een lakehouse maken voor Direct Lake
In dit artikel wordt beschreven hoe u een lakehouse maakt, een Delta-tabel maakt in lakehouse en vervolgens een eenvoudig semantisch model maakt voor het lakehouse in een Microsoft Fabric-werkruimte.
Lees direct Lake-overzicht voordat u aan de slag gaat met het maken van een lakehouse voor Direct Lake.
Een lakehouse maken
Selecteer in uw Microsoft Fabric-werkruimte nieuwe>opties en selecteer vervolgens in Data-engineer ing de tegel Lakehouse.
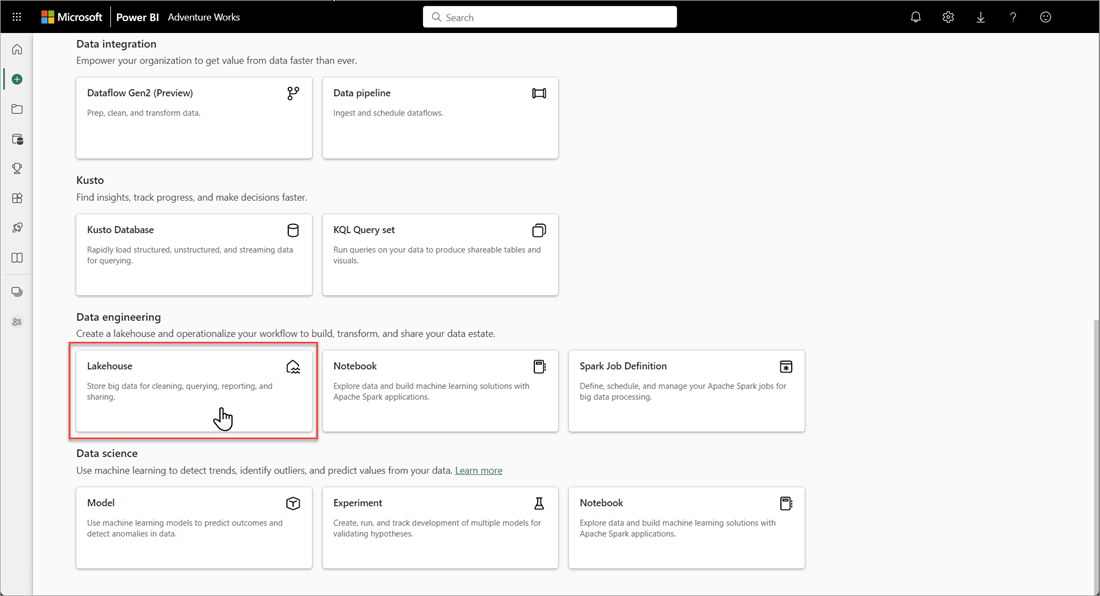
Voer in het dialoogvenster New Lakehouse een naam in en selecteer Vervolgens Maken. De naam mag alleen alfanumerieke tekens en onderstrepingstekens bevatten.
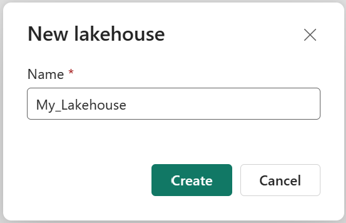
Controleer of het nieuwe lakehouse is gemaakt en wordt geopend.
Een Delta-tabel maken in het lakehouse
Nadat u een nieuw lakehouse hebt gemaakt, moet u ten minste één Delta-tabel maken, zodat Direct Lake toegang heeft tot bepaalde gegevens. Direct Lake kan bestanden met parquet-indeling lezen, maar voor de beste prestaties kunt u de gegevens het beste comprimeren met behulp van de VORDER-compressiemethode. VORDER comprimeert de gegevens met behulp van het systeemeigen compressie-algoritme van de Power BI-engine. Op deze manier kan de engine de gegevens zo snel mogelijk in het geheugen laden.
Er zijn meerdere opties voor het laden van gegevens in een lakehouse, waaronder gegevenspijplijnen en scripts. In de volgende stappen wordt PySpark gebruikt om een Delta-tabel toe te voegen aan een lakehouse op basis van een Azure Open Dataset:
Selecteer in het zojuist gemaakte Lakehouse-notitieblok openen en selecteer vervolgens Nieuw notitieblok.
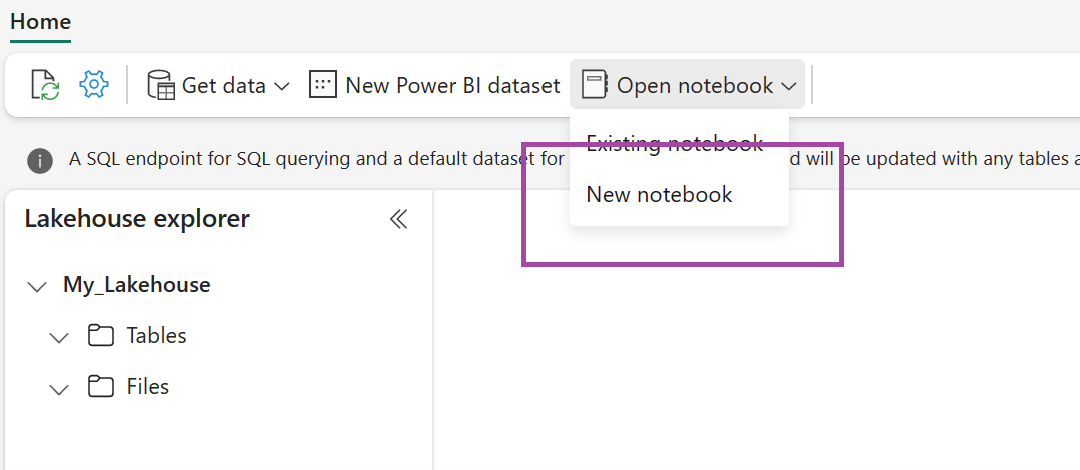
Kopieer en plak het volgende codefragment in de eerste codecel om SPARK toegang te geven tot het geopende model en druk op Shift+ Enter om de code uit te voeren.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Controleer of de code een extern blobpad uitvoert.
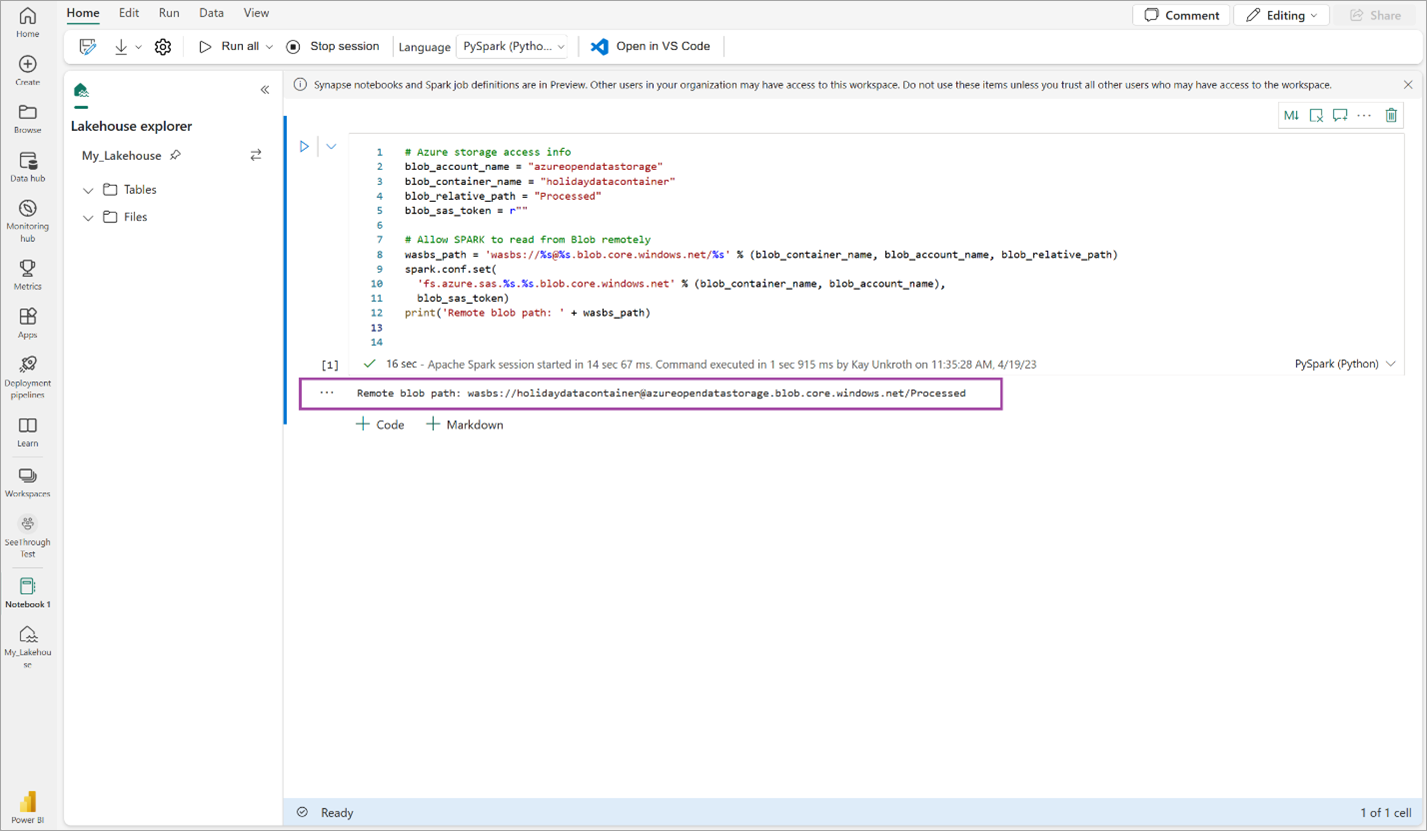
Kopieer en plak de volgende code in de volgende cel en druk op Shift+Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Controleer of de code het DataFrame-schema heeft uitgevoerd.
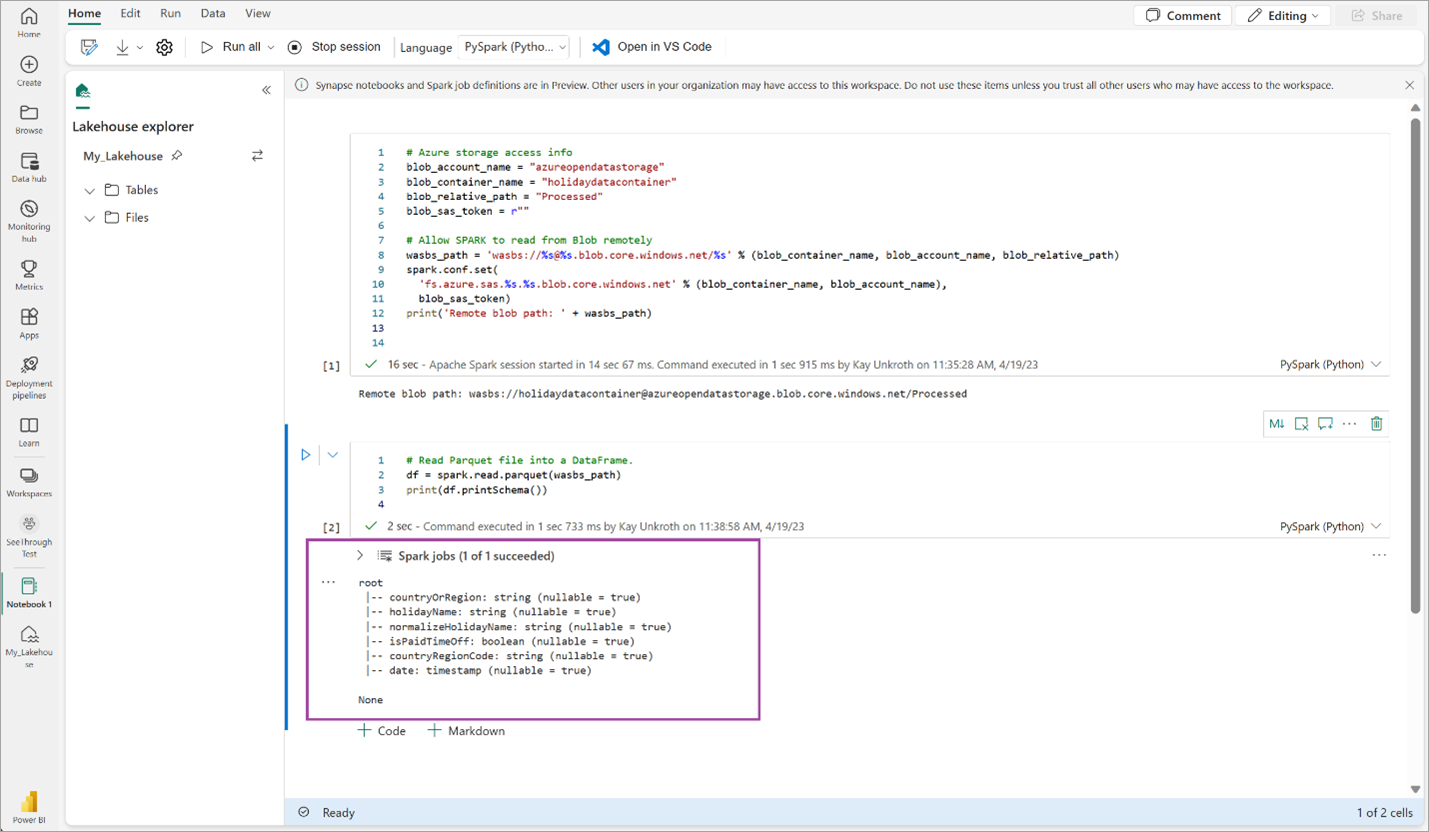
Kopieer en plak de volgende regels in de volgende cel en druk op Shift+Enter. De eerste instructie maakt de VORDER-compressiemethode mogelijk en de volgende instructie slaat het DataFrame op als een Delta-tabel in het lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Controleer of alle SPARK-taken zijn voltooid. Vouw de lijst met SPARK-taken uit om meer details weer te geven.
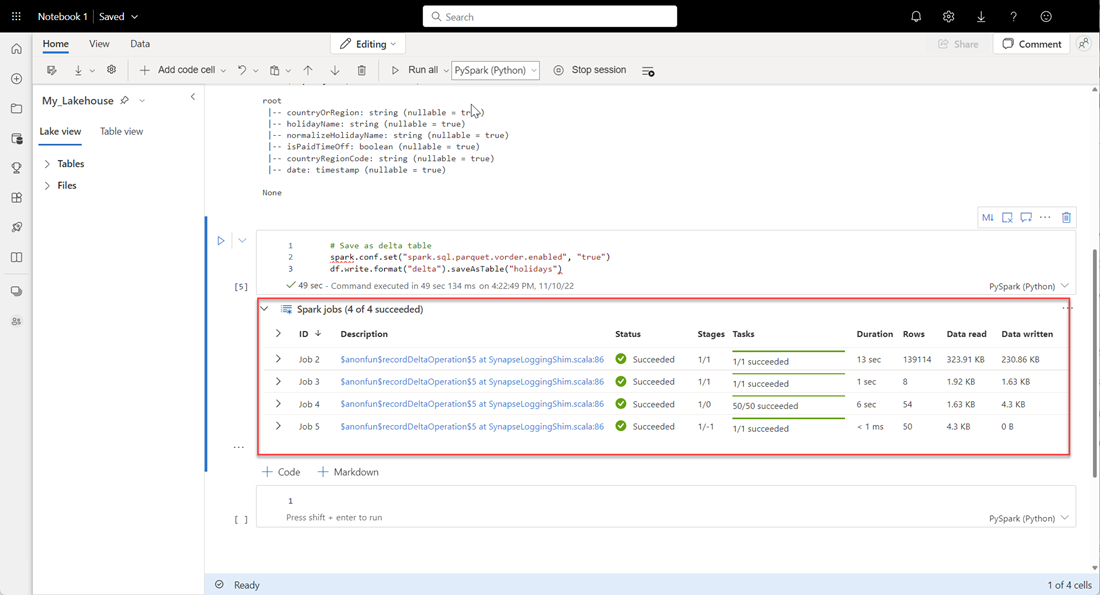
Als u wilt controleren of een tabel is gemaakt, selecteert u in het linkerbovenhoekgebied naast Tabellen het beletselteken (...), selecteert u Vernieuwen en vouwt u vervolgens het knooppunt Tabellen uit.
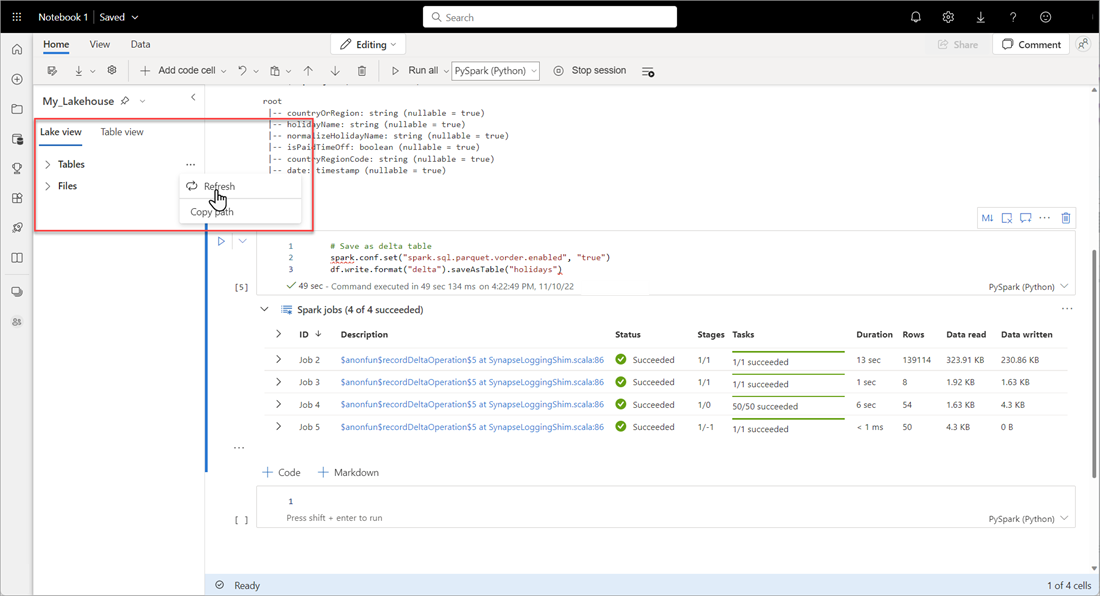
Gebruik dezelfde methode als hierboven of andere ondersteunde methoden om meer Delta-tabellen toe te voegen voor de gegevens die u wilt analyseren.
Een eenvoudig Direct Lake-model maken voor uw lakehouse
Selecteer in uw lakehouse het nieuwe semantische model en selecteer vervolgens in het dialoogvenster de tabellen die u wilt opnemen.
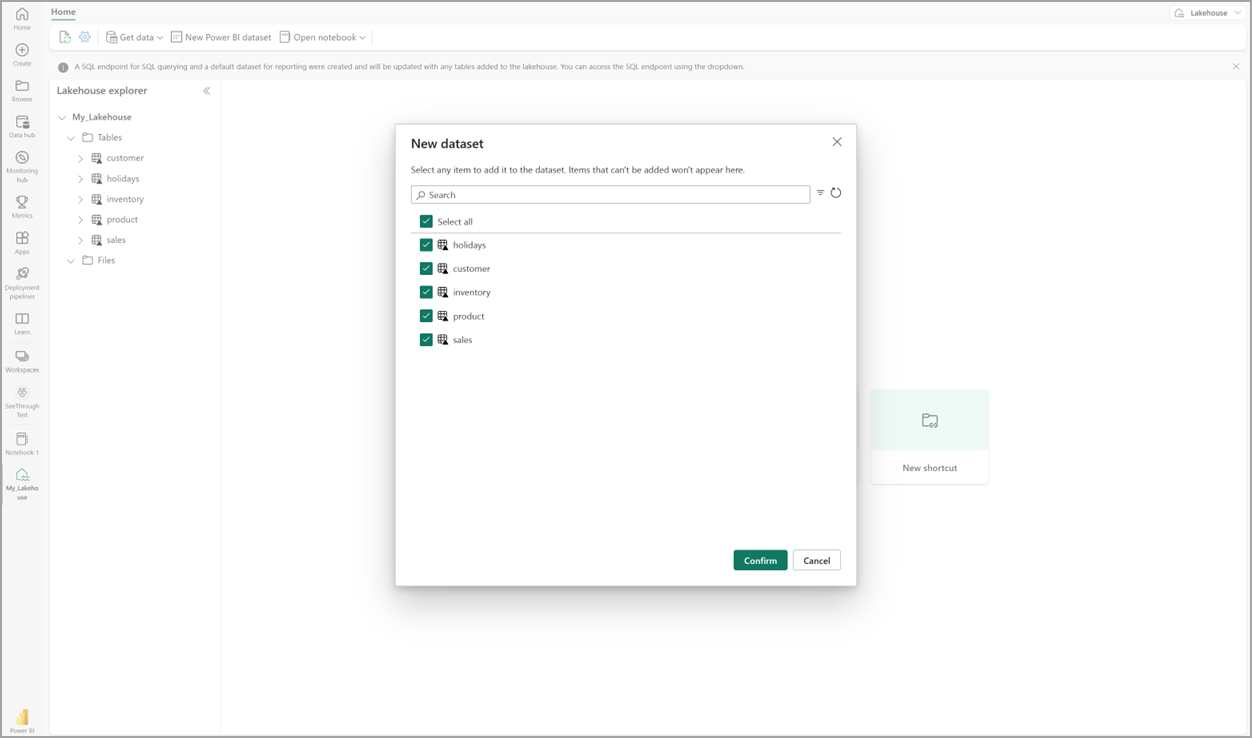
Selecteer Bevestigen om het Direct Lake-model te genereren. Het model wordt automatisch opgeslagen in de werkruimte op basis van de naam van uw lakehouse en opent vervolgens het model.
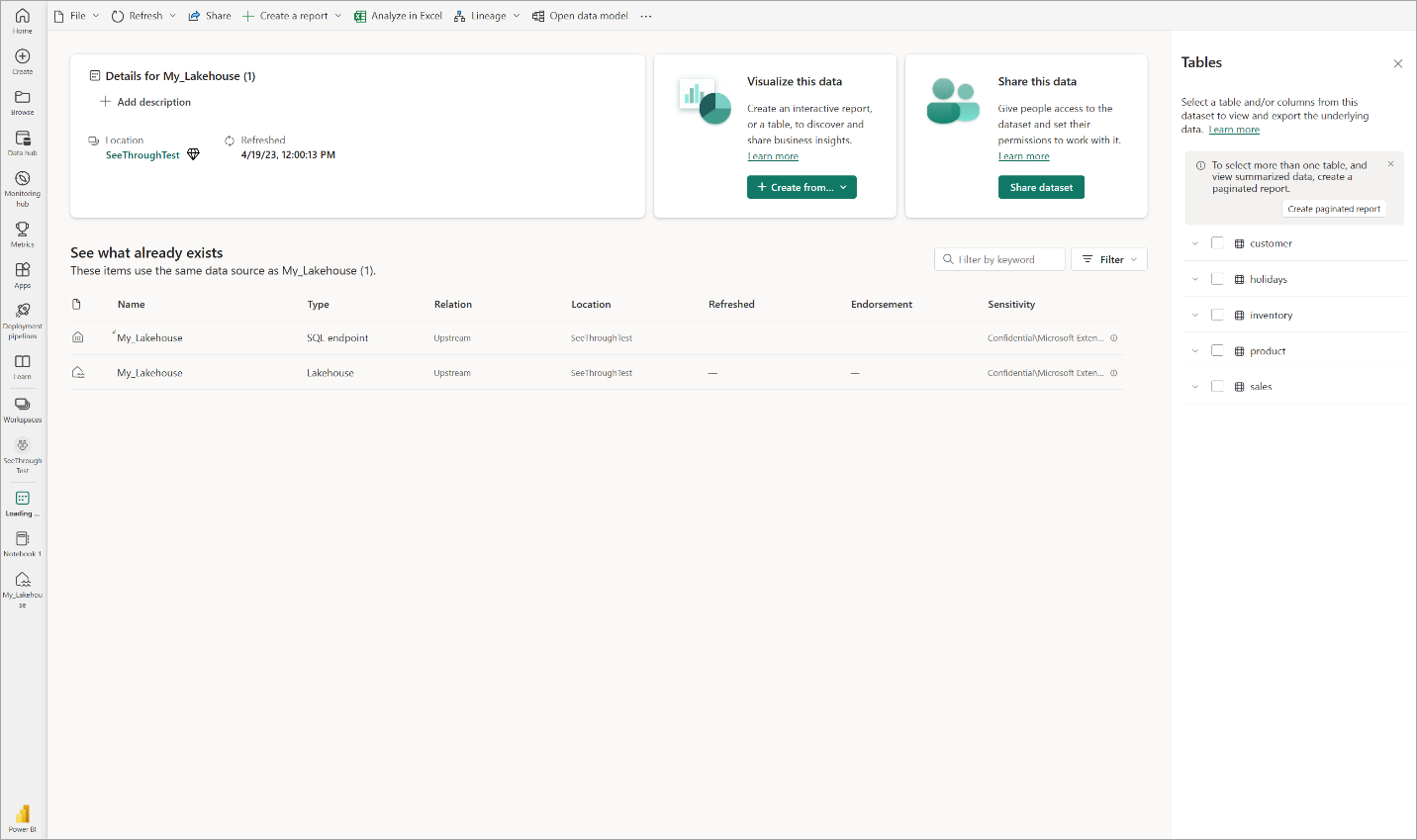
Selecteer Gegevensmodel openen om de webmodelleringservaring te openen, waar u tabelrelaties en DAX-metingen kunt toevoegen.
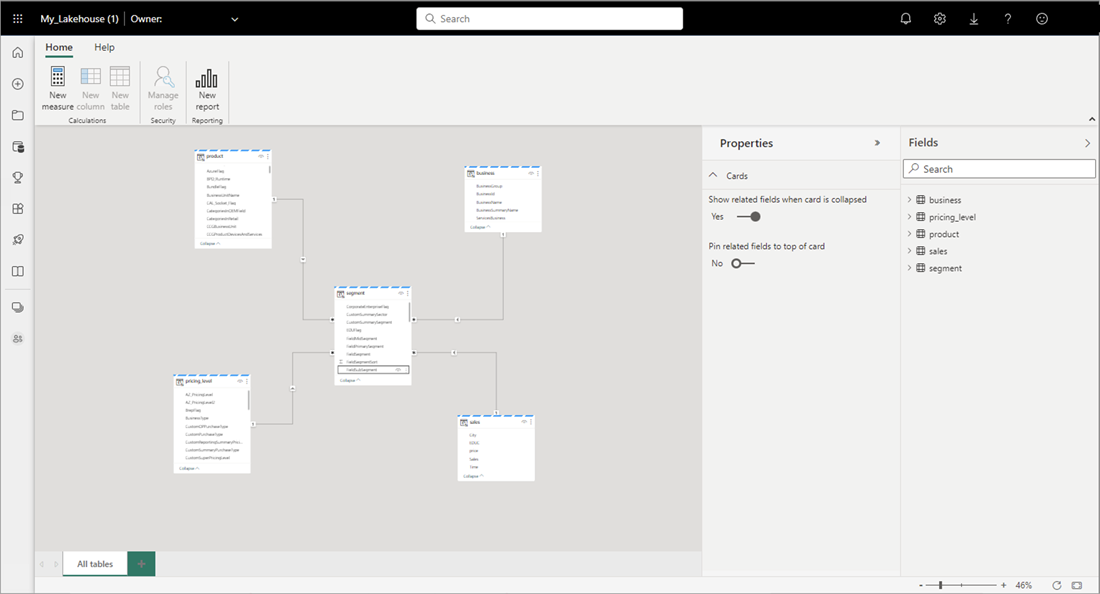
Wanneer u klaar bent met het toevoegen van relaties en DAX-metingen, kunt u vervolgens rapporten maken, een samengesteld model maken en query's uitvoeren op het model via XMLA-eindpunten op ongeveer dezelfde manier als elk ander model.
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor