Uitlegtypen in Microsoft Syntex
Van toepassing op: ✓ Ongestructureerde documentverwerking
Uitleg wordt gebruikt om te helpen bij het definiëren van de informatie die u wilt labelen en extraheren in uw ongestructureerde documentverwerkingsmodellen in Microsoft Syntex. Bij het maken van een uitleg moet je een uitlegtype selecteren. In dit artikel vind je meer informatie over de verschillende uitlegtypen en hoe je deze kunt gebruiken.
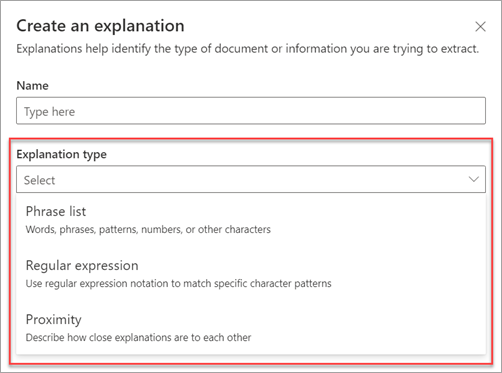
Deze uitlegtypen zijn beschikbaar:
Patroonlijst: lijst met woorden, woordgroepen, cijfers of andere tekens die u kunt gebruiken in het document of de informatie die u uit het document haalt. De tekststring verwijzende arts staat bijvoorbeeld in alle medische verwijzingsdocumenten die u identificeert. Of het telefoonnummer van de verwijzende arts uit alle medische verwijzingsdocumenten die u identificeert.
Reguliere expressie: in een reguliere expressie wordt een notatie gebruikt om patronen te matchen en zo specifieke tekenpatronen te vinden. U kunt bijvoorbeeld een reguliere expressie gebruiken om alle instanties van een e-mailadrespatroon in een verzameling documenten te zoeken.
Nabijheid: beschrijft hoe nauw de verklaringen bij elkaar liggen. Een straatnummerlijst gaat bijvoorbeeld direct vóór de lijst met straatnamen , zonder tokens ertussen (verderop in dit artikel vindt u meer informatie over tokens). Voor het type proximity moet je ten minste twee uitleggen in je model hebben, of de optie wordt uitgeschakeld.
Woordenlijst
Het uitlegtype van een woordenlijst wordt meestal gebruikt om een document te identificeren en te classificeren via je model. Zoals beschreven in het voorbeeld van het label verwijzende arts, is het een reeks woorden, woordgroepen, cijfers of tekens die consistent in de documenten staat die u identificeert.
Hoewel dit geen vereiste is, kunt u meer succes behalen met uw uitleg als het patroon dat u vastlegt zich op een consistente locatie in uw document bevindt. Het label verwijzende arts kan bijvoorbeeld consequent in de eerste alinea van het document staan. U kunt ook de optie Configureren waar zinnen voorkomen in het document in de geavanceerde instellingen gebruiken om specifieke gebieden te selecteren waar de zin zich bevindt, vooral als de kans bestaat dat het patroon op meerdere locaties in uw document voorkomt.
Als hoofdlettergevoeligheid een vereiste is bij het identificeren van je label, kun je met het woordenlijsttype in uw uitleg opgeven door het selectievakje Alleen exacte kapitalisatie in te schakelen.

Een patroonlijst is vooral handig wanneer u een uitleg maakt die informatie in verschillende indelingen identificeert en extraheert, zoals datums, telefoonnummers en creditcardnummers. Een datum kan bijvoorbeeld in veel verschillende formaten worden weergegeven (1/1/2020, 1-1-2020, 01/01/20, 01/01/2020, 1 januari 2020, enzovoort). Door een patroonlijst te definiëren, kunt u efficiënter identificeren door eventuele variaties in de gegevens vast te leggen die u probeert vast te stellen en op te halen.
Voor het voorbeeld Telefoonnummer haalt u het telefoonnummer voor elke verwijzende arts op uit alle Medische Verwijzingsdocumenten die door het model worden geïdentificeerd. Wanneer u de uitleg maakt, typt u de verschillende notaties die een telefoonnummer in uw document kan weergeven, zodat u mogelijke variaties kunt vastleggen.
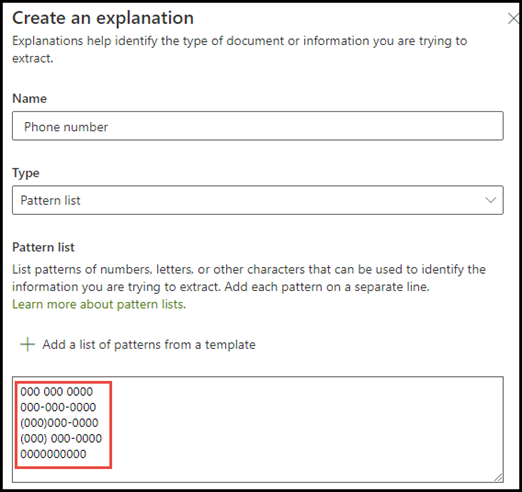
Schakel voor dit voorbeeld in Geavanceerde instellingen het selectievakje Elk cijfer van 0-9 in om elke '0'-waarde die in uw lijst met zinnen wordt gebruikt, te herkennen als een cijfer van 0 tot en met 9.

Als u een patroonlijst maakt die teksttekens bevat, selecteert u het selectievakje Willekeurige letter van a-z om aan te geven dat elk 'a'-teken dat in de patroonlijst wordt gebruikt, elk teken van 'a' tot 'z' kan zijn.
Als u bijvoorbeeld een patroonlijst Datum maakt en u ervoor wilt zorgen dat een datumnotatie wordt ondersteund zoals 1 januari 2020, moet u het volgende doen:
- Voeg 0 AAA 0000 en 00 AAA 0000 aan de patroonlijst toe.
- Zorg ervoor dat Een willekeurige letter van a-z is geselecteerd.

Als je hoofdlettereisen in je patroonlijst hebt, kun je ook het selectievakje Alleen exact hoofdlettergebruik selecteren. Als u voor het datumvoorbeeld wilt dat de eerste letter van de maand met een hoofdletter wordt geschreven, moet u:
- Voeg 0 Aaa 0000 en 00 AAA 0000 aan de patroonlijst toe.
- Zorg ervoor dat Alleen exact hoofdlettergebruikook is geselecteerd.

Opmerking
Gebruik in plaats van het handmatig maken van een uitleg voor patroonlijsten de uitlegbibliotheek voor het gebruik van vooraf gemaakte patroonlijstsjablonen voor een algemene patroonlijst, zoals datum, telefoonnummer, creditcardnummer, enzovoort.
Reguliere expressie
Met behulp van een reguliere uitlegtype voor expressies kunt u patronen maken om bepaalde tekenreeksen in documenten te zoeken en te identificeren. U kunt reguliere expressies gebruiken om snel grote hoeveelheden tekst te parseren om:
- Specifieke tekenpatronen te zoeken.
- Tekst te valideren om ervoor te zorgen dat deze overeenkomt met een vooraf gedefinieerd patroon (zoals een e-mailadres).
- Tekstsubtekenreeksen te extraheren, bewerken, vervangen of verwijderen.
Een type reguliere expressie is vooral handig wanneer u een uitleg maakt die informatie in vergelijkbare indelingen identificeert en extraheert, zoals e-mailadressen, bankrekeningnummers of URL's. Een e-mailadres, zoals megan@contoso.com, wordt bijvoorbeeld weergegeven in een bepaald patroon ('megan' is het eerste deel en 'com' is het laatste deel).
De reguliere expressie voor een e-mailadres is: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+. [A-Za-z]{2,6}.
Deze expressie bestaat uit vijf delen, in deze volgorde:
Een of meer van de volgende tekens:
a. Letters van a tot z
b. Getal tussen 0 en 9
c. Punt, onderstrepingsteken, percentage of streepje
Het @-symbool
Elk aantal van hetzelfde soort tekens als het eerste deel van het e-mailadres
Een punt
Twee tot zes letters
Een uitlegtype voor een reguliere expressie toevoegen:
Selecteer Reguliere expressie in het deelvenster Een uitleg maken onder Type uitleg.
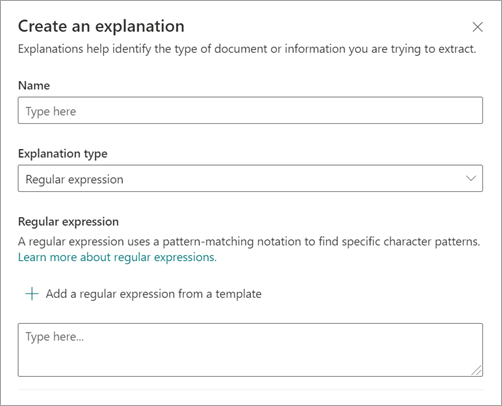
U kunt een uitdrukking typen in het tekstvak Reguliere expressie of Een reguliere uitdrukking uit een sjabloon toevoegen selecteren.
Wanneer u een reguliere expressie toevoegt met behulp van een sjabloon, worden de naam en de reguliere expressie automatisch toegevoegd aan het tekstvak. Als u bijvoorbeeld de sjabloon Email adres kiest, wordt het deelvenster Een uitleg maken ingevuld.

Beperkingen
De volgende tabel bevat opties voor inlinetekens die momenteel niet beschikbaar zijn voor gebruik in reguliere expressiepatronen.
| Optie | Status | Huidige functionaliteit |
|---|---|---|
| Hoofdlettergevoeligheid | Wordt momenteel niet ondersteund. | Alle uitgevoerde overeenkomsten zijn hoofdlettergevoelig. |
| Lijnankers | Wordt momenteel niet ondersteund. | Kan specifieke positie niet opgeven in een tekenreeks waar een overeenkomst moet voorkomen. |
Proximity
Met het Proximity-uitlegtype kan je model identificeren met behulp van hoe dichtbij een ander stukje gegevens is. Stel dat u in uw model twee verklaringen hebt gedefinieerd die zowel het huisnummer van de klant als het telefoonnummer van een label voorzien.
Je ziet ook dat de telefoonnummers van klanten altijd voor het huisnummer worden weergegeven.
Alex Wilburn
555-555-5555
One Microsoft Way
Redmond, WA 98034
Gebruik de proximity-uitleg om te bepalen hoe ver de uitleg van een telefoonnummer is zodat u het huisnummer in je documenten beter kunt identificeren.

Opmerking
Reguliere expressies kunnen momenteel niet worden gebruikt met het nabijheidsuitlegtype.
Wat zijn tokens?
Om het uitlegtype nabijheid te gebruiken, moet u weten wat een token is. Het aantal tokens is de manier waarop de nabijheidsverklaring de afstand van de ene uitleg tot de andere meet. Een token is een doorlopende reeks (geen spaties of interpunctie) van letters en cijfers.
In de volgende tabel zie je enkele voorbeelden van hoe je het aantal tokens in een woordgroep kunt vaststellen.
| Woordengroep | Aantal tokens | Uitleg |
|---|---|---|
Dog |
1 | Eén woord zonder leesteken of spatie. |
RMT33W |
1 | Een record locatornummer. Het mag cijfers en letters bevatten, maar geen leestekens. |
425-555-5555 |
5 | Een telefoonnummer. Elk leesteken bestaat uit één token, zodat 425-555-5555 5 tokens zou zijn:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Het proximity-uitlegtype configureren
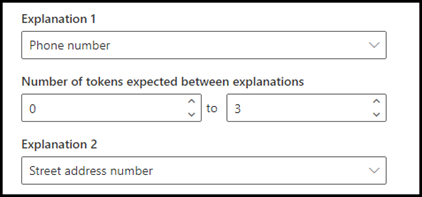
Voor het voorbeeld configureert u de nabijheidsinstelling zodanig dat u het aantal tokens kunt definiëren in de telefoonnummer-uitleg afkomstig van de huisnummer-uitleg. Je ziet dat het minimumbereik “0“ is omdat er geen tokens zijn tussen het telefoonnummer en het huisnummer.
Sommige telefoonnummers in de voorbeelddocumenten worden echter toegevoegd met (mobiel).
Wander Kuijken
111-111-1111 (mobiel)
One Microsoft Way
Redmond, WA 98034
Er zijn drie tokens in (mobiel):
| Woordengroep | Aantal tokens |
|---|---|
| ( | 1 |
| Mobiel | 2 |
| ) | 3 |
Configureer de proximity-instelling voor een bereik van 0 tot en met 3.
Configureren waar woordgroepen voorkomen in het document
Wanneer u een uitleg maakt, wordt standaard in het hele document gezocht naar het patroon dat u wilt extraheren. U kunt echter de geavanceerde instelling Waar deze woordgroepen voorkomen gebruiken om een specifieke locatie in het document te isoleren waar een woordgroep voorkomt. Deze instelling is handig in situaties waarin vergelijkbare gevallen van een patroon ergens anders in het document kunnen voorkomen en u zeker wilt weten dat de juiste is geselecteerd.
Wanneer we kijken naar ons voorbeelddocument voor medische verwijzing, wordt de verwijzende arts altijd in de eerste alinea van het document vermeld. Met de instelling Waar deze woordgroepen voorkomen kunt u in dit voorbeeld de uitleg zo configureren dat alleen in het begin van het document naar dit label wordt gezocht, of op een andere locatie waar dit kan voorkomen.
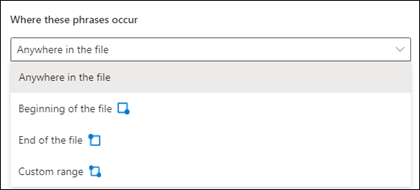
U kunt kiezen uit de volgende opties voor deze instelling:
Overal in het bestand: in het hele document wordt naar de woordgroep gezocht.
Begin van het bestand: het document wordt doorzocht vanaf het begin tot de locatie van de woordgroep.
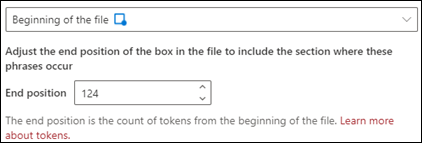
In de viewer kunt u het selectievakje handmatig aanpassen zodat de locatie van de woordgroep wordt opgenomen. De waarde eindpositie wordt bijgewerkt om het aantal tokens weer te geven dat uw geselecteerde gebied bevat. U kunt de waarde van de Eindpositie ook bijwerken om het geselecteerde gebied aan te passen.

Einde van het bestand: het document wordt vanaf het eind tot aan de locatie van het patroon doorzocht.

In de viewer kunt u het selectievakje handmatig aanpassen zodat de locatie van de woordgroep wordt opgenomen. De waarde van de beginpositie wordt bijgewerkt om het aantal tokens weer te geven dat uw geselecteerde gebied bevat. U kunt de waarde van de Beginpositie ook bijwerken om het geselecteerde gebied aan te passen.

Aangepast bereik: het document wordt binnen een opgegeven bereik doorzocht op de locatie van het patroon.
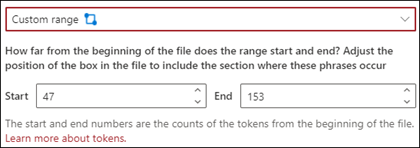
In de viewer kunt u het selectievakje handmatig aanpassen zodat de locatie van de woordgroep wordt opgenomen. Voor deze instelling moet u een Beginpositie en een Eindpositie selecteren. Deze waarden geven het aantal tokens aan vanaf het begin van het document. Hoewel u deze waarden handmatig kunt invoeren, is het eenvoudiger om het selectievakje handmatig aan te passen in de viewer.
Overwegingen bij het configureren van uitleg
Wanneer u een classificatie traint, moet u rekening houden met een aantal dingen die voorspelbaardere resultaten opleveren:
Hoe meer documenten u traint, hoe nauwkeuriger de classificatie is. Gebruik indien mogelijk meer dan vijf goede documenten en gebruik meer dan één slecht document. Als de bibliotheken waarmee u werkt verschillende documenttypen bevatten, leiden verschillende van elk type tot voorspelbare resultaten.
Het labelen van het document speelt een belangrijke rol in het trainingsproces. Ze worden samen met uitleg gebruikt om het model te trainen. Mogelijk ziet u enkele afwijkingen bij het trainen van een classificatie met documenten die niet veel inhoud bevatten. De uitleg komt mogelijk niet overeen met iets in het document, maar omdat het is gelabeld als een 'goed' document, kan het tijdens de training een overeenkomst zijn.
Bij het maken van uitleg wordt OR-logica gebruikt in combinatie met het label om te bepalen of het een overeenkomst is. Reguliere expressie die gebruikmaakt van AND-logica is mogelijk voorspelbaarder. Hier volgt een voorbeeld van een reguliere expressie die u kunt gebruiken voor echte documenten om ze te trainen. Let op: de rood gemarkeerde tekst is de zin of woordgroepen waarnaar u op zoek bent.
(?=.*network provider)(?=.*participating providers).*
Labels en uitleg werken samen en worden gebruikt bij het trainen van het model. Het is geen reeks regels die kunnen worden ontkoppeld en nauwkeurige gewichten of voorspellingen kunnen worden toegepast op elke variabele die is geconfigureerd. Hoe groter de variatie van documenten die in de training worden gebruikt, zorgt voor meer nauwkeurigheid in het model.