Overzicht van gestructureerde en vrije documentverwerking in Microsoft Syntex
Opmerking
Tot juni 2024 kunt u gestructureerde en vrije documentverwerking en andere geselecteerde Syntex-services gratis uitproberen als u betalen per gebruik facturering hebt ingesteld. Zie Microsoft Syntex uitproberen en de services ervan verkennen voor informatie en beperkingen.
Gebruik het gestructureerde documentverwerkingsmodel (indelingsmethode) om automatisch veld- en tabelwaarden te identificeren. Dit werkt het beste voor gestructureerde of semi-gestructureerde documenten, zoals formulieren en facturen.
Gebruik het freeform-documentverwerkingsmodel (vrije-vormselectiemethode) om automatisch informatie te extraheren uit ongestructureerde en vrije documenten, zoals brieven en contracten.
Opmerking
Microsoft respecteert de privacy en het eigendom van gegevens die u gebruikt voor het trainen en verwerken van modellen in Syntex. Geen van de gegevens van uw organisatie wordt door Microsoft gebruikt of overgedragen om AI-modellen, grote taalmodellen of andere modellen te trainen. Uw gegevens blijven veilig binnen de tenant van uw organisatie. Zie Gegevensbescherming en privacy van Microsoft voor meer informatie.
Inleiding tot gestructureerde en vrije-vormmodellen
Microsoft Syntex maakt gebruik van Microsoft Power Apps AI Builder-documentverwerking (voorheen bekend als formulierverwerking) om gestructureerde en vrije documentverwerkingsmodellen te maken in SharePoint-documentbibliotheken.
U kunt AI Builder-documentverwerking gebruiken om gestructureerde of vrije documentverwerkingsmodellen te maken die gebruikmaken van machine learning-technologie om sleutel-waardeparen en tabelgegevens te identificeren en te extraheren uit gestructureerde of semi-gestructureerde documenten, zoals formulieren en facturen, en ongestructureerde of vrije documenten, zoals contracten en correspondentie.
Organisaties ontvangen vaak facturen in grote hoeveelheden uit verschillende bronnen, zoals e-mail, fax en e-mail. Het verwerken van deze documenten en het handmatig invoeren ervan in een database kan veel tijd in beslag nemen. Door AI te gebruiken om de tekst, sleutel-waardeparen en tabellen uit uw documenten te extraheren, automatiseert Syntex dit proces.
Opmerking
Zie Aan de slag met het stimuleren van acceptatie en Scenario's en use cases voor meer ideeën over het gebruik van deze modellen in uw organisatie.
U kunt bijvoorbeeld een gestructureerd documentverwerkingsmodel of een vrije vorm maken waarmee alle documenten worden geïdentificeerd die naar de documentbibliotheek worden geüpload. Vervolgens kunt u uit elk document specifieke gegevens extraheren en weergeven die voor u belangrijk zijn.
U gebruikt voorbeeldbestanden om uw model te trainen en de informatie te definiëren die u uit het formulier wilt halen. De indeling van het document wordt geleerd door het model te trainen. U hebt slechts vijf documenten nodig om aan de slag te gaan. Syntex analyseert uw voorbeeldbestanden op sleutel-waardeparen en u kunt ook handmatig de bestanden identificeren die mogelijk niet zijn gedetecteerd. Met AI Builder kunt u de nauwkeurigheid van uw model testen op uw voorbeeldbestanden.
U kunt alleen een gestructureerd of vrij documentverwerkingsmodel maken in SharePoint-documentbibliotheken waarvoor dit is ingeschakeld. Als deze optie is ingeschakeld, kunt u de optie Classificeren en extraheren in uw documentbibliotheek zien.
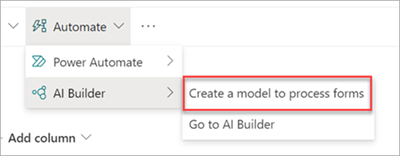
Neem contact op met uw Microsoft 365-beheerder als u deze wilt inschakelen in uw documentbibliotheek.
Vereisten en beperkingen
Zie Vereisten en beperkingen voor modellen in Microsoft Syntex voor meer informatie over vereisten die u moet overwegen bij het kiezen van dit model.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor