Automatische aggregaties
Automatische aggregaties maken gebruik van state-of-the-art machine learning (ML) om directQuery-semantische modellen continu te optimaliseren voor maximale prestaties van rapportquery's. Automatische aggregaties worden gebouwd op basis van bestaande door de gebruiker gedefinieerde aggregatiesinfrastructuur die voor het eerst is geïntroduceerd met samengestelde modellen voor Power BI. In tegenstelling tot door de gebruiker gedefinieerde aggregaties vereisen automatische aggregaties geen uitgebreide vaardigheden voor gegevensmodellering en queryoptimalisatie om te configureren en te onderhouden. Automatische aggregaties zijn zowel zelftraining als zelfoptimalisatie. Ze stellen modeleigenaren van elk vaardigheidsniveau in staat om de queryprestaties te verbeteren, waardoor snellere rapportvisualisaties voor grote modellen worden geboden.
Met automatische aggregaties:
- Rapportvisualisaties zijn sneller: een optimaal percentage rapportquery's wordt geretourneerd door een automatisch onderhouden cache voor in-memory aggregaties in plaats van back-endgegevensbronsystemen. Uitbijterquery's die niet worden geretourneerd door de cache in het geheugen, worden rechtstreeks doorgegeven aan de gegevensbron met behulp van DirectQuery.
- Evenwichtige architectuur: in vergelijking met de pure DirectQuery-modus worden de meeste queryresultaten geretourneerd door de Power BI-query-engine en in-memory aggregatiescache. De belasting van queryverwerking op gegevensbronsystemen op piekuren kan aanzienlijk worden verminderd, wat betekent dat de schaalbaarheid in de back-end van de gegevensbron aanzienlijk wordt verhoogd.
- Eenvoudige installatie: modeleigenaren kunnen automatische aggregatiestraining inschakelen en een of meer vernieuwingen voor het model plannen. Met de eerste training en vernieuwing beginnen automatische aggregaties met het maken van een framework voor aggregaties en optimale aggregaties. Het systeem tunest zichzelf automatisch in de loop van de tijd.
- Afstemmen: met een eenvoudige en intuïtieve gebruikersinterface in de modelinstellingen kunt u de prestatieverbeteringen schatten voor een ander percentage query's dat wordt geretourneerd door de cache voor in-memory aggregaties en aanpassingen aanbrengen voor nog grotere winsten. Met één schuifbalk kunt u uw omgeving eenvoudig verfijnen.
Vereisten
Ondersteunde abonnementen
Automatische aggregaties worden ondersteund voor Power BI Premium per capaciteit, Premium per gebruiker en Power BI Embedded-modellen.
Ondersteunde gegevensbronnen
Automatische aggregaties worden ondersteund voor de volgende gegevensbronnen:
- Azure SQL-database
- Toegewezen SQL-pool van Azure Synapse
- SQL Server 2019 of hoger
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Ondersteunde modi
Automatische aggregaties worden ondersteund voor DirectQuery-modusmodellen. Samengestelde modelmodellen met zowel importtabellen als DirectQuery-verbindingen worden ondersteund. Automatische aggregaties worden alleen ondersteund voor de DirectQuery-verbinding.
Bevoegdheden
Als u automatische aggregaties wilt inschakelen en configureren, moet u de eigenaar van het model zijn. Werkruimtebeheerders kunnen deze overnemen als eigenaar om instellingen voor automatische aggregaties te configureren.
Automatische aggregaties configureren
Automatische aggregaties worden geconfigureerd in model Instellingen. Configureren is eenvoudig: automatische aggregatiestraining inschakelen en een of meer vernieuwingen plannen. Voordat u automatische aggregaties voor uw model configureert, moet u dit artikel volledig lezen. Het biedt een goed inzicht in hoe automatische aggregaties werken en kan u helpen bepalen of automatische aggregaties geschikt zijn voor uw omgeving. Als u klaar bent voor stapsgewijze instructies voor het inschakelen van automatische aggregatiestraining, het configureren van een vernieuwingsschema en het afstemmen van uw omgeving, raadpleegt u Automatische aggregaties configureren.
Vergoedingen
Telkens wanneer een modelgebruiker een rapport opent of communiceert met een rapportvisualisatie, worden DAX-query's (Data Analysis Expressions) doorgegeven aan de query-engine en vervolgens aan de back-endgegevensbron als SQL-query's. De gegevensbron moet de resultaten voor elke query berekenen en retourneren. Vergeleken met importmodusmodellen die in het geheugen zijn opgeslagen, kunnen retouren van DirectQuery-gegevensbronnen zowel tijd als procesintensief zijn, waardoor vaak trage reactietijden van query's in rapportvisualisaties ontstaan.
Wanneer automatische aggregaties zijn ingeschakeld voor een DirectQuery-model, kunnen automatische aggregaties de prestaties van rapportquery's verbeteren door retouren van gegevensbronnenquery's te voorkomen. Vooraf geaggregeerde queryresultaten worden automatisch geretourneerd door een cache voor in-memory aggregaties in plaats van verzonden naar en geretourneerd door de gegevensbron. De hoeveelheid vooraf geaggregeerde gegevens in de cache voor in-memory aggregaties is een klein deel van de hoeveelheid gegevens die in feite wordt bewaard en detailtabellen in de gegevensbron. Het resultaat is niet alleen betere prestaties van rapportquery's, maar ook een lagere belasting voor back-endgegevensbronsystemen. Met automatische aggregaties worden slechts een klein deel van de rapport- en ad-hocquery's waarvoor aggregaties nodig zijn die niet zijn opgenomen in de cache in het geheugen, doorgegeven aan de back-endgegevensbron, net zoals bij de pure DirectQuery-modus.
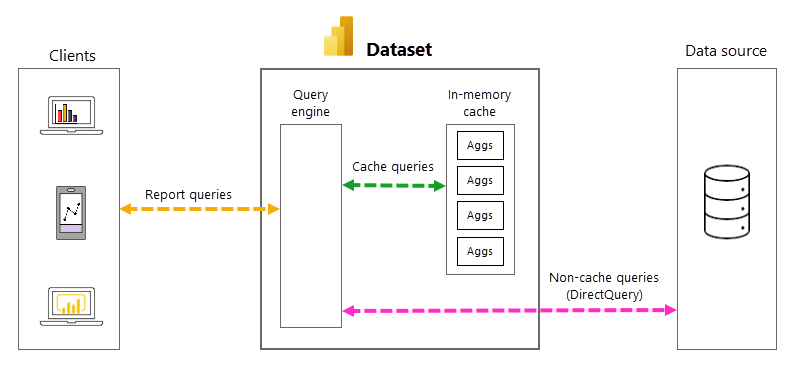
Automatisch beheer van query's en aggregaties
Hoewel automatische aggregaties de noodzaak voorkomen om door de gebruiker gedefinieerde aggregatietabellen te maken en het implementeren van een vooraf geaggregeerde gegevensoplossing aanzienlijk te vereenvoudigen, is een diepere kennis van de onderliggende processen en afhankelijkheden handig bij het begrijpen hoe automatische aggregaties werken. Power BI is afhankelijk van het volgende voor het maken en beheren van automatische aggregaties.
Querylogboek
Power BI houdt model- en gebruikersrapportquery's bij in een querylogboek. Voor elk model onderhoudt Power BI zeven dagen aan querylogboekgegevens. Querylogboekgegevens worden elke dag samengerold. Het querylogboek is beveiligd en is niet zichtbaar voor gebruikers of via het XMLA-eindpunt.
Trainingsbewerkingen
Als onderdeel van de eerste geplande vernieuwingsbewerking voor het model voor de geselecteerde frequentie (dag of week) start Power BI eerst een trainingsbewerking waarmee het querylogboek wordt geëvalueerd om ervoor te zorgen dat aggregaties in de cache van in-memory aggregaties zich aanpassen aan veranderende querypatronen. In-memory aggregatietabellen worden gemaakt, bijgewerkt of verwijderd en speciale query's worden verzonden naar de gegevensbron om te bepalen welke aggregaties moeten worden opgenomen in de cache. Berekende aggregatiegegevens worden echter niet tijdens de training in de cache in het geheugen geladen. Deze worden tijdens de volgende vernieuwingsbewerking geladen.
Als u bijvoorbeeld een dagfrequentie kiest en de geplande vernieuwingen om 04:00 uur, 9:00 uur, 2:00 en 19:00 uur, bevat alleen de vernieuwing van 4:00 uur elke dag zowel een trainingsbewerking als een vernieuwingsbewerking. De volgende geplande vernieuwingen van 9:00, 2:00 en 19:00 uur zijn alleen bewerkingen die de bestaande aggregaties in de cache bijwerken.
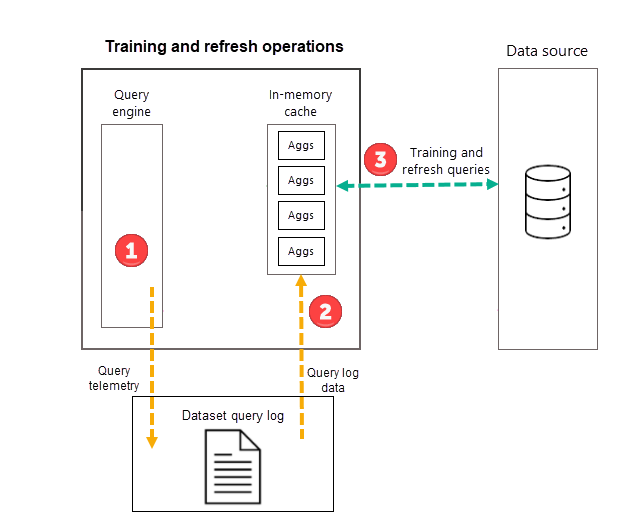
Terwijl trainingsbewerkingen eerdere query's uit het querylogboek evalueren, zijn de resultaten voldoende nauwkeurig om ervoor te zorgen dat toekomstige query's worden behandeld. Er is echter geen garantie dat toekomstige query's worden geretourneerd door de cache voor in-memory aggregaties, omdat deze nieuwe query's kunnen afwijken van die van het querylogboek. Deze query's die niet worden geretourneerd door de cache voor aggregaties in het geheugen, worden doorgegeven aan de gegevensbron met behulp van DirectQuery. Afhankelijk van de frequentie en classificatie van deze nieuwe query's, kunnen aggregaties voor deze query's worden opgenomen in de cache voor in-memory aggregaties met de volgende trainingsbewerking.
De trainingsbewerking heeft een tijdslimiet van 60 minuten. Als de training het hele querylogboek niet binnen de tijdslimiet kan verwerken, wordt een melding geregistreerd in de geschiedenis van het model vernieuwen en wordt de volgende keer dat de training wordt gestart hervat. De trainingscyclus wordt voltooid en vervangt de bestaande automatische aggregaties wanneer het hele querylogboek wordt verwerkt.
Vernieuwingsbewerkingen
Zoals eerder beschreven, voert Power BI, nadat de trainingsbewerking is voltooid als onderdeel van de eerste geplande vernieuwing voor de geselecteerde frequentie, een vernieuwingsbewerking uit waarmee nieuwe en bijgewerkte aggregatiegegevens in de cache voor in-memory aggregaties worden geladen en eventuele aggregaties worden verwijderd die niet langer hoog genoeg zijn (zoals bepaald door het trainingsalgoritmen). Alle volgende vernieuwingen voor de gekozen dag- of weekfrequentie zijn alleen vernieuwingsbewerkingen die een query uitvoeren op de gegevensbron om bestaande aggregatiegegevens in de cache bij te werken. In ons vorige voorbeeld zijn geplande vernieuwingen van 9:00, 2:00 en 17:00 geplande vernieuwingen voor die dag alleen bewerkingen.
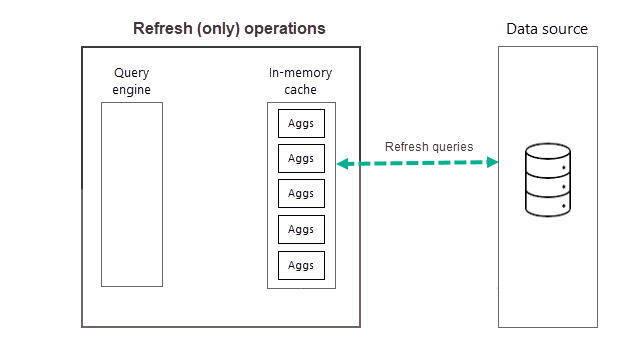
Regelmatig geplande vernieuwingen gedurende de dag (of week) zorgen ervoor dat aggregatiegegevens in de cache beter up-to-date zijn met gegevens in de back-endgegevensbron. Via model Instellingen kunt u maximaal 48 vernieuwingen per dag plannen om ervoor te zorgen dat rapportquery's die worden geretourneerd door de aggregatiecache, resultaten krijgen op basis van de meest recente vernieuwde gegevens uit de back-endgegevensbron.
Let op
Trainings- en vernieuwingsbewerkingen zijn proces- en resource-intensief voor zowel de Power BI-service als de gegevensbronsystemen. Het verhogen van het percentage query's dat gebruikmaakt van aggregaties betekent dat er meer aggregaties moeten worden opgevraagd en berekend op basis van gegevensbronnen tijdens trainings- en vernieuwingsbewerkingen, waardoor de kans op overmatig gebruik van systeemresources en mogelijk time-outs veroorzaakt. Zie Afstemmen voor meer informatie.
Training op aanvraag
Zoals eerder vermeld, kan een trainingscyclus niet worden voltooid binnen de tijdslimieten van één gegevensvernieuwingscyclus. Als u niet wilt wachten tot de volgende geplande vernieuwingscyclus die training omvat, kunt u ook automatische aggregatiestraining op aanvraag activeren door Trainen en nu vernieuwen te selecteren in het model Instellingen. Als u Train and Refresh Now gebruikt, worden zowel een trainingsbewerking als een vernieuwingsbewerking geactiveerd. Controleer de vernieuwingsgeschiedenis van het model om te zien of de huidige bewerking is voltooid voordat u zo nodig een andere trainings- en vernieuwingsbewerking op aanvraag uitvoert.
Geschiedenis vernieuwen
Elke vernieuwingsbewerking wordt vastgelegd in de vernieuwingsgeschiedenis van het model. Belangrijke informatie over elke vernieuwing wordt weergegeven, inclusief het aantal geheugenaggregaties in de cache dat wordt gebruikt voor het geconfigureerde querypercentage. Als u de vernieuwingsgeschiedenis wilt weergeven, selecteert u de vernieuwingsgeschiedenis op de pagina Instellingen model. Als u iets verder wilt inzoomen, selecteert u Details weergeven .
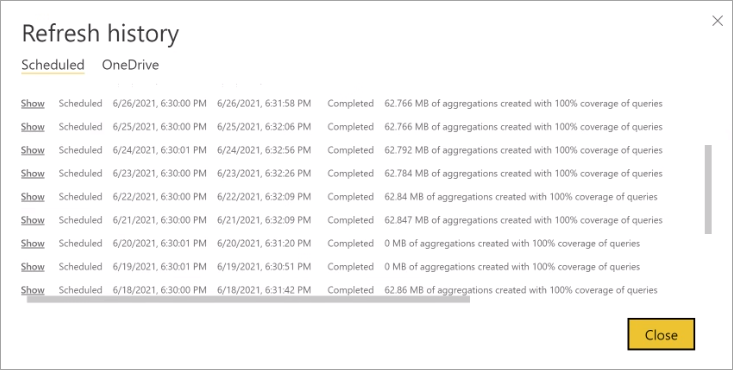
Door regelmatig de vernieuwingsgeschiedenis te controleren, kunt u ervoor zorgen dat uw geplande vernieuwingsbewerkingen binnen een acceptabele periode worden voltooid. Zorg ervoor dat vernieuwingsbewerkingen zijn voltooid voordat de volgende geplande vernieuwing begint.
Trainings- en vernieuwingsfouten
Hoewel Power BI trainings- en vernieuwingsbewerkingen uitvoert als onderdeel van de eerste geplande vernieuwing voor de dag- of weekfrequentie die u kiest, worden deze bewerkingen geïmplementeerd als afzonderlijke transacties. Als een trainingsbewerking het querylogboek niet volledig kan verwerken binnen de tijdslimieten, gaat Power BI doorgaan met het vernieuwen van de bestaande aggregaties (en reguliere tabellen in een samengesteld model) met behulp van de vorige trainingsstatus. In dit geval geeft de vernieuwingsgeschiedenis aan dat het vernieuwen is voltooid en de training het querylogboek gaat hervatten wanneer de training de volgende keer wordt gestart. Queryprestaties zijn mogelijk minder geoptimaliseerd als querypatronen van clientrapport zijn gewijzigd en aggregaties nog niet zijn aangepast, maar het bereikte prestatieniveau moet nog steeds veel beter zijn dan een puur DirectQuery-model zonder aggregaties.
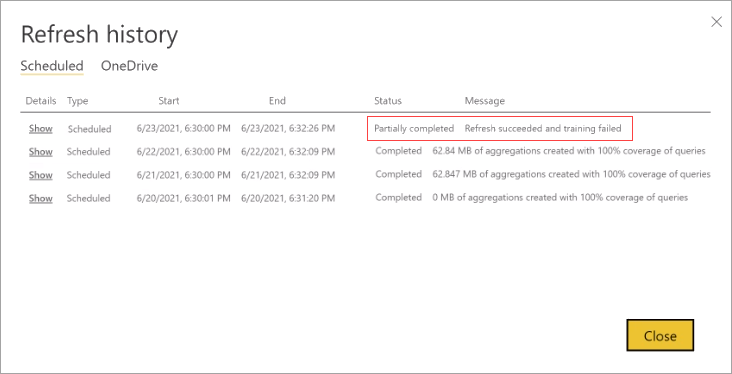
Als een trainingsbewerking te veel cycli nodig heeft om het querylogboek te verwerken, kunt u overwegen om het percentage query's te verminderen dat gebruikmaakt van de cache voor in-memory aggregaties in het model Instellingen. Dit vermindert het aantal aggregaties dat in de cache is gemaakt, maar biedt meer tijd om trainings- en vernieuwingsbewerkingen te voltooien. Zie Afstemmen voor meer informatie.
Als de training slaagt maar vernieuwen mislukt, wordt de volledige vernieuwing gemarkeerd als Mislukt omdat het resultaat een cache voor in-memory aggregaties niet beschikbaar is.
Bij het plannen van vernieuwen kunt u e-mailmeldingen opgeven als er vernieuwingsfouten zijn.
Door de gebruiker gedefinieerde en automatische aggregaties
Door de gebruiker gedefinieerde aggregaties in Power BI kunnen handmatig worden geconfigureerd op basis van verborgen samengevoegde tabellen in het model. Het configureren van door de gebruiker gedefinieerde aggregaties is vaak complex en vereist een groter niveau van gegevensmodellering en queryoptimalisatievaardigheden. Automatische aggregaties daarentegen elimineren deze complexiteit als onderdeel van een AI-gestuurd systeem. In tegenstelling tot door de gebruiker gedefinieerde aggregaties die statisch blijven, onderhoudt Power BI continu querylogboeken en van deze logboeken bepaalt querypatronen op basis van machine learning -algoritmen (ML) voorspellende modellering. Vooraf geaggregeerde gegevens worden berekend en opgeslagen in het geheugen op basis van querypatroonanalyse. Met automatische aggregaties zijn modellen zowel zelftraining als zelfoptimalisatie. Naarmate querypatronen van clientrapport veranderen, worden automatische aggregaties aangepast, prioriteren en opslaan in de cache van deze aggregaties die het vaakst worden gebruikt.
Omdat automatische aggregaties zijn gebouwd op basis van de bestaande door de gebruiker gedefinieerde aggregatiesinfrastructuur, is het mogelijk om zowel door de gebruiker gedefinieerde als automatische aggregaties samen in hetzelfde model te gebruiken. Ervaren gegevensmodelleerders kunnen aggregaties definiëren voor tabellen met Behulp van DirectQuery, Importeren (met of zonder incrementeel vernieuwen) of Dual-opslagmodi, terwijl tegelijkertijd de voordelen van meer automatische aggregaties voor query's via DirectQuery-verbindingen die niet op de door de gebruiker gedefinieerde aggregatietabellen worden geraakt. Deze flexibiliteit maakt evenwichtige architecturen mogelijk die querybelastingen kunnen verminderen en knelpunten kunnen voorkomen.
Aggregaties die zijn gemaakt in de cache in het geheugen door het trainingsalgoritme voor automatische aggregaties, worden geïdentificeerd als System aggregaties. Het trainingsalgoritmen maken en verwijderen alleen die System aggregaties als rapportagequery's worden geanalyseerd en aanpassingen worden aangebracht om de optimale aggregaties voor het model te behouden. Zowel door de gebruiker gedefinieerde als automatische aggregaties worden vernieuwd met vernieuwen. Alleen aggregaties die zijn gemaakt door automatische aggregaties en gemarkeerd als door het systeem gegenereerde aggregaties, worden opgenomen in automatische aggregatiesverwerking.
Query's opslaan in cache en automatische aggregaties
Power BI Premium biedt ook ondersteuning voor querycaching in Power BI Premium/Embedded om queryresultaten te behouden. Querycaching is een andere functie dan automatische aggregaties. Bij het opslaan van query's gebruikt Power BI Premium de lokale cacheservice om caching te implementeren, terwijl automatische aggregaties op modelniveau worden geïmplementeerd. Wanneer query's in de cache worden opgeslagen, worden query's alleen in de cache opgeslagen voor het laden van de eerste rapportpagina. Queryprestaties worden daarom niet verbeterd wanneer gebruikers met een rapport werken. Automatische aggregaties optimaliseren daarentegen de meeste rapportquery's door geaggregeerde queryresultaten vooraf in de cache op te cachen, inclusief query's die worden gegenereerd wanneer gebruikers interactie hebben met rapporten. Querycaching en automatische aggregaties kunnen beide worden ingeschakeld voor een model, maar dit is waarschijnlijk niet nodig.
Bewaken met Azure Log Analytics
Azure Log Analytics (LA) is een service in Azure Monitor die Power BI kan gebruiken om activiteitenlogboeken op te slaan. Met Azure Monitor Suite kunt u telemetriegegevens uit uw Azure- en on-premises omgevingen verzamelen, analyseren en erop reageren. Het biedt langetermijnopslag, een ad-hocqueryinterface en API-toegang om gegevensexport en integratie met andere systemen mogelijk te maken. Zie Azure Log Analytics gebruiken in Power BI voor meer informatie.
Als Power BI is geconfigureerd met een Azure LA-account, zoals beschreven in Het configureren van Azure Log Analytics voor Power BI, kunt u het slagingspercentage van uw automatische aggregaties analyseren. U kunt onder andere bepalen of rapportquery's worden beantwoord vanuit de cache in het geheugen.
Als u deze mogelijkheid wilt gebruiken, downloadt u de PBIT-sjabloon en verbindt u deze met uw Log Analytics-account, zoals beschreven in dit Power BI-blogbericht. In het rapport kunt u gegevens weergeven op drie verschillende niveaus: samenvattingsweergave, DAX-queryniveauweergave en sql-queryniveauweergave.
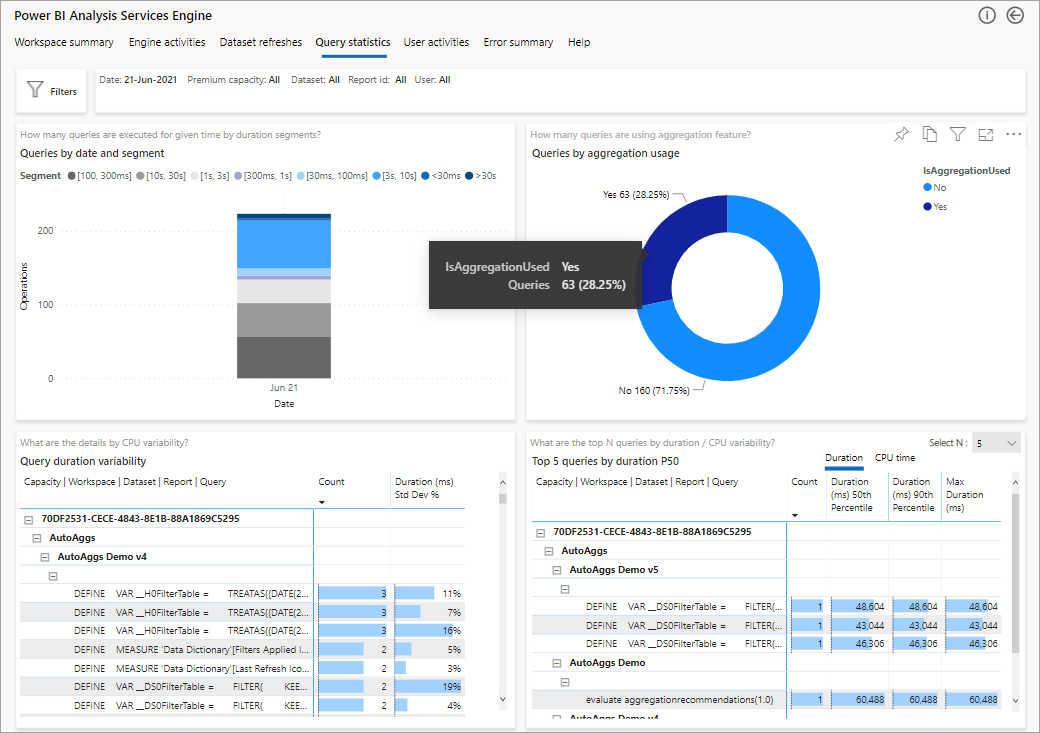
In de volgende afbeelding ziet u de overzichtspagina voor alle query's. Zoals u kunt zien, toont de gemarkeerde grafiek het percentage van de totale query's waaraan is voldaan door aggregaties versus de query's die de gegevensbron moesten gebruiken.
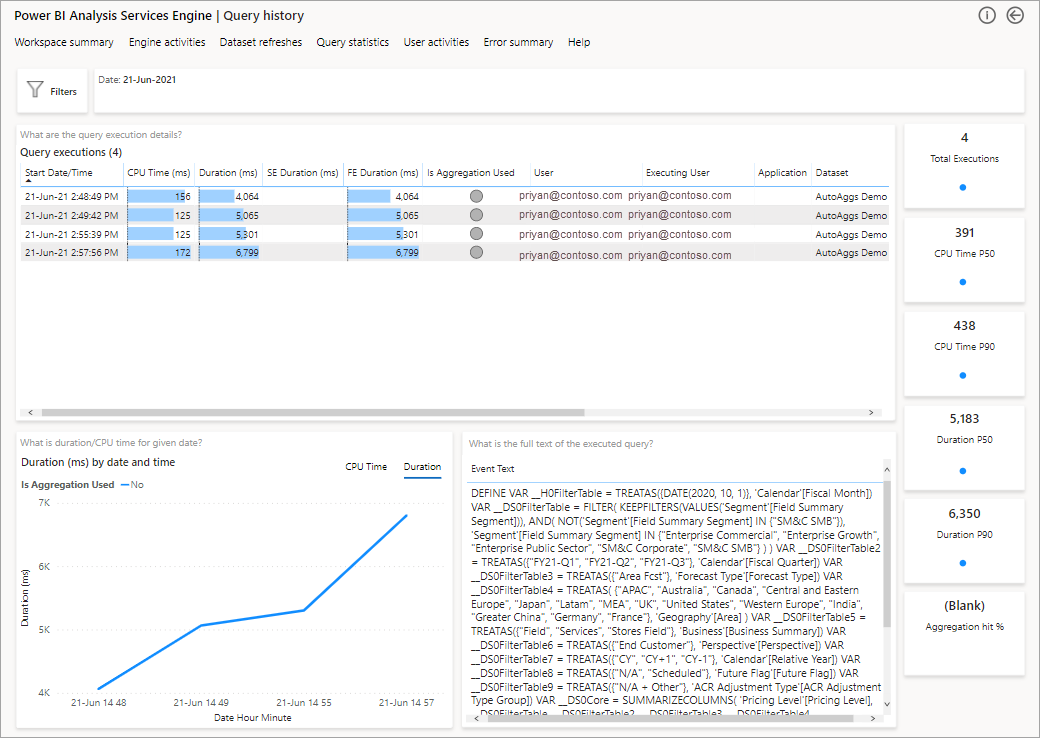
De volgende stap om dieper in te gaan op het gebruik van aggregaties op DAX-queryniveau. Klik met de rechtermuisknop op een DAX-query in de lijst (linksonder) >Drill through>Query history.
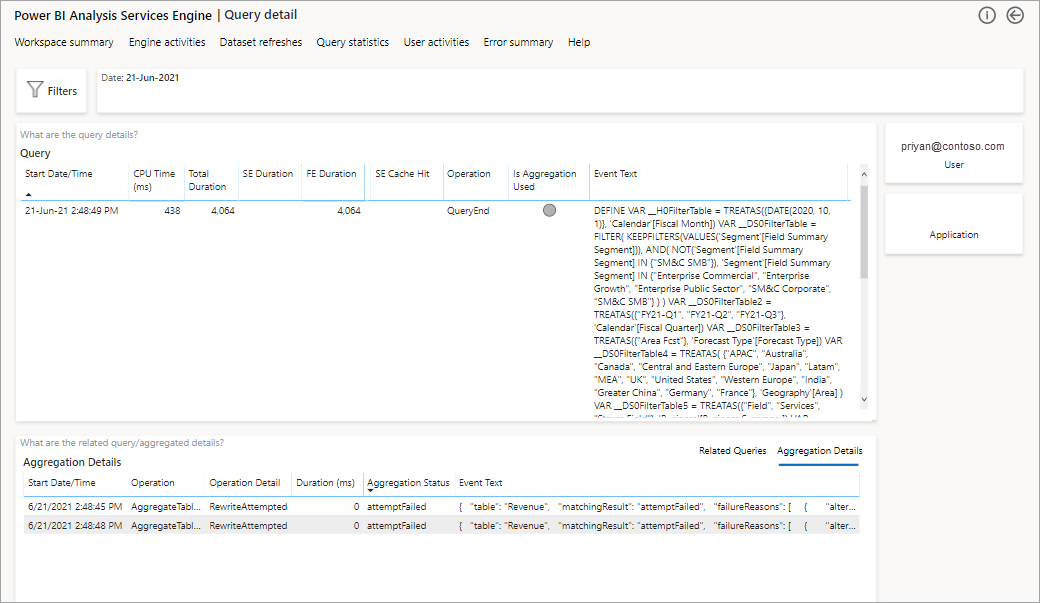
Hiermee krijgt u een lijst met alle relevante query's. Zoom in op het volgende niveau om meer aggregatiedetails weer te geven.
Levenscyclusbeheer van toepassing
Van ontwikkeling tot testen en van test tot productie hebben modellen waarvoor automatische aggregaties zijn ingeschakeld speciale vereisten voor ALM-oplossingen.
Implementatiepijplijnen
Met implementatiepijplijnen kan Power BI de modellen kopiëren met hun modelconfiguratie vanuit de huidige fase naar de doelfase. Automatische aggregaties moeten echter opnieuw worden ingesteld in de doelfase omdat de instellingen niet worden overgebracht van de huidige naar de doelfase. U kunt inhoud ook programmatisch implementeren met behulp van de REST API's voor implementatiepijplijnen. Zie Uw implementatiepijplijn automatiseren met behulp van API's en DevOps voor meer informatie over dit proces.
Aangepaste ALM-oplossingen
Als u een aangepaste ALM-oplossing gebruikt op basis van XMLA-eindpunten, moet u er rekening mee houden dat uw oplossing mogelijk door het systeem gegenereerde en door de gebruiker gemaakte aggregatietabellen kan kopiëren als onderdeel van de modelmetagegevens. U moet automatische aggregaties echter handmatig inschakelen na elke implementatiestap in de doelfase. Power BI behoudt de configuratie als u een bestaand model overschrijft.
Notitie
Als u een model uploadt of opnieuw publiceert als onderdeel van een Power BI Desktop-bestand (.pbix), gaan door het systeem gemaakte aggregatietabellen verloren als Power BI het bestaande model vervangt door alle metagegevens en gegevens in de doelwerkruimte.
Een model wijzigen
Nadat u een model hebt gewijzigd met automatische aggregaties die zijn ingeschakeld via XMLA-eindpunten, zoals het toevoegen of verwijderen van tabellen, behoudt Power BI alle bestaande aggregaties die kunnen zijn en verwijderen die niet meer nodig of relevant zijn. Queryprestaties kunnen worden beïnvloed totdat de volgende trainingsfase wordt geactiveerd.
Metagegevenselementen
Modellen waarvoor automatische aggregaties zijn ingeschakeld, bevatten unieke door het systeem gegenereerde aggregatietabellen. Aggregatiestabellen zijn niet zichtbaar voor gebruikers in rapportagehulpprogramma's. Ze zijn zichtbaar via het XMLA-eindpunt met behulp van hulpprogramma's met Analysis Services-clientbibliotheken versie 19.22.5 en hoger. Wanneer u werkt met modellen waarvoor automatische aggregaties zijn ingeschakeld, moet u uw hulpprogramma's voor gegevensmodellering en beheer upgraden naar de nieuwste versie van de clientbibliotheken. Voor SQL Server Management Studio (SSMS) moet u upgraden naar SSMS versie 18.9.2 of hoger. Eerdere versies van SSMS kunnen geen tabellen inventariseren of deze modellen scripten.
Tabellen met automatische aggregaties worden geïdentificeerd door een SystemManaged tabeleigenschap, die nieuw is voor het tabellaire objectmodel (TOM) in Analysis Services-clientbibliotheken versie 19.22.5 en hoger. In het volgende codefragment ziet u de SystemManaged eigenschap die is ingesteld true voor automatische aggregatietabellen en false voor reguliere tabellen.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Als u dit fragment uitvoert, worden automatische aggregatietabellen uitgevoerd die momenteel zijn opgenomen in het model in een console.
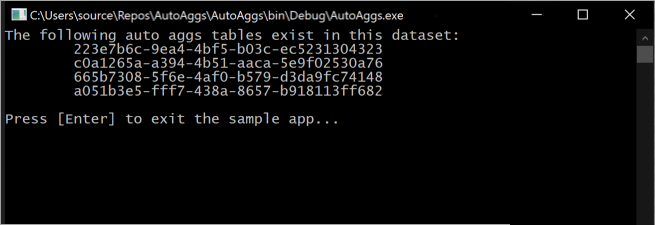
Houd er rekening mee dat aggregatiestabellen voortdurend veranderen naarmate trainingsbewerkingen bepalen welke optimale aggregaties moeten worden opgenomen in de cache voor in-memory aggregaties.
Belangrijk
Power BI beheert automatisch door het systeem gegenereerde tabelobjecten volledig. Verwijder of wijzig deze tabellen niet zelf. Als u dit doet, kunnen de prestaties verslechteren.
Power BI onderhoudt de modelconfiguratie buiten het model. De aanwezigheid van een door het systeem beheerde aggregatiestabel in een model betekent niet noodzakelijkerwijs dat het model is ingeschakeld voor automatische training voor aggregaties. Met andere woorden, als u een volledige modeldefinitie uitvoert voor een model waarvoor automatische aggregaties zijn ingeschakeld en een nieuwe kopie van het model maakt (met een andere naam/werkruimte/capaciteit), is het nieuwe resulterende model niet ingeschakeld voor automatische aggregatietraining. U moet nog steeds automatische aggregatiestraining inschakelen voor het nieuwe model in model Instellingen.
Overwegingen en beperkingen
Houd rekening met het volgende wanneer u automatische aggregaties gebruikt:
- Aggregaties bieden geen ondersteuning voor dynamische M-queryparameters.
- De SQL-query's die tijdens de eerste trainingsfase zijn gegenereerd, kunnen aanzienlijke belasting genereren voor het datawarehouse. Als de training onvolledig blijft en u kunt controleren aan de kant van het datawarehouse of de query's een time-out ondervinden, kunt u overwegen om uw datawarehouse tijdelijk op te schalen om te voldoen aan de trainingsvraag.
- Aggregaties die zijn opgeslagen in de cache voor in-memory aggregaties, worden mogelijk niet berekend op de meest recente gegevens in de gegevensbron. In tegenstelling tot pure DirectQuery en meer zoals reguliere importtabellen, is er een latentie tussen updates op de gegevensbron en aggregatiegegevens die zijn opgeslagen in de cache voor in-memory aggregaties. Hoewel er altijd enige latentie is, kan dit worden verzacht door een effectief vernieuwingsschema.
- Als u de prestaties verder wilt optimaliseren, stelt u alle dimensietabellen in op de dual-modus en laat u feitentabellen in de DirectQuery-modus staan.
- Automatische aggregaties zijn niet beschikbaar met Power BI Pro, Azure Analysis Services of SQL Server Analysis Services.
- Power BI biedt geen ondersteuning voor het downloaden van modellen waarvoor automatische aggregaties zijn ingeschakeld. Als u een Power BI Desktop-bestand (.pbix) hebt geüpload of gepubliceerd naar Power BI en vervolgens automatische aggregaties hebt ingeschakeld, kunt u het PBIX-bestand niet meer downloaden. Zorg ervoor dat u een kopie van het PBIX-bestand lokaal bewaart.
- Automatische aggregaties met externe tabellen in Azure Synapse Analytics worden niet ondersteund. U kunt externe tabellen in Synapse opsommen met behulp van de volgende SQL-query:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables - Automatische aggregaties zijn alleen beschikbaar voor modellen die gebruikmaken van verbeterde metagegevens. Als u automatische aggregaties voor een ouder model wilt inschakelen, moet u het model eerst upgraden naar verbeterde metagegevens. Zie Verbeterde modelmetagegevens gebruiken voor meer informatie.
- Schakel automatische aggregaties niet in als de DirectQuery-gegevensbron is geconfigureerd voor eenmalige aanmelding en dynamische gegevensweergaven of beveiligingsbesturingselementen gebruikt om de gegevens te beperken die een gebruiker mag openen. Automatische aggregaties zijn niet op de hoogte van deze besturingselementen op gegevensbronniveau, waardoor het onmogelijk is om ervoor te zorgen dat de juiste gegevens per gebruiker worden verstrekt. Training registreert een waarschuwing in de vernieuwingsgeschiedenis dat er een gegevensbron is gedetecteerd die is geconfigureerd voor eenmalige aanmelding en de tabellen die gebruikmaken van deze gegevensbron overgeslagen. Schakel indien mogelijk eenmalige aanmelding voor deze gegevensbronnen uit om optimaal te profiteren van de automatische aggregaties voor geoptimaliseerde queryprestaties.
- Schakel automatische aggregaties niet in als het model alleen hybride tabellen bevat om onnodige verwerkingsoverhead te voorkomen. Een hybride tabel maakt gebruik van zowel importpartities als een DirectQuery-partitie. Een veelvoorkomend scenario is incrementeel vernieuwen met realtime gegevens waarin een DirectQuery-partitie transacties ophaalt uit de gegevensbron die is opgetreden na de laatste gegevensvernieuwing. Tijdens het vernieuwen importeert Power BI echter aggregaties. Automatische aggregaties kunnen geen transacties bevatten die zijn opgetreden na de laatste gegevensvernieuwing. Tijdens de training wordt een waarschuwing vastgelegd in de vernieuwingsgeschiedenis die is gedetecteerd en hybride tabellen zijn overgeslagen.
- Berekende kolommen worden niet in aanmerking genomen voor automatische aggregaties. Als u een berekende kolom in de DirectQuery-modus gebruikt, zoals door de
COMBINEVALUESDAX-functie te gebruiken om een relatie te maken op basis van meerdere kolommen uit twee DirectQuery-tabellen, raken de bijbehorende rapportquery's niet de cache voor in-memory aggregaties. - Automatische aggregaties zijn alleen beschikbaar in de Power BI-service. Power BI Desktop maakt geen door het systeem gegenereerde aggregatietabellen.
- Als u de metagegevens van een model wijzigt waarvoor automatische aggregaties zijn ingeschakeld, kunnen queryprestaties afnemen totdat het volgende trainingsproces wordt geactiveerd. Als best practice moet u de automatische aggregaties verwijderen, de wijzigingen aanbrengen en vervolgens opnieuw trainen.
- Wijzig of verwijder door het systeem gegenereerde aggregatiestabellen niet, tenzij u automatische aggregaties hebt uitgeschakeld en het model opschoont. Het systeem neemt de verantwoordelijkheid voor het beheren van deze objecten.
Community
Power BI heeft een levendige community waar MVP's, BI-professionals en peers expertise delen in discussiegroepen, video's, blogs en meer. Als u meer wilt weten over automatische aggregaties, moet u deze andere resources uitchecken: