Automatische aggregaties configureren
Het configureren van automatische aggregaties omvat het inschakelen van training voor een ondersteund semantisch DirectQuery-model en het configureren van een of meer geplande vernieuwingen. Nadat verschillende iteraties van de trainings- en vernieuwingsbewerkingen zijn uitgevoerd, kunt u terugkeren naar semantische modelinstellingen om het percentage rapportquery's te verfijnen dat gebruikmaakt van de cache voor in-memory aggregaties. Voordat u deze stappen uitvoert, moet u de functionaliteit en beperkingen die worden beschreven in automatische aggregaties volledig begrijpen.
Inschakelen
U moet beschikken over semantische eigenaarsmachtigingen voor het model om automatische aggregaties in te schakelen. Werkruimtebeheerders kunnen machtigingen voor modeleigenaar overnemen.
Vouw in het semantische model Instellingen geplande vernieuwing en optimalisatie van prestaties uit.
Schakel de training voor automatische aggregaties over naar Aan. Als de schakeloptie grijs wordt weergegeven, controleert u of de referenties van de gegevensbron zijn geconfigureerd en of u bent aangemeld.

Geef in het vernieuwingsschema een vernieuwingsfrequentie en tijdzone op. Als de besturingselementen voor vernieuwen zijn uitgeschakeld, controleert u de configuratie van de gegevensbron, inclusief gatewayverbinding (indien nodig) en referenties voor de gegevensbron.
Selecteer Nog een keer toevoegen en geef een of meer vernieuwingen op.
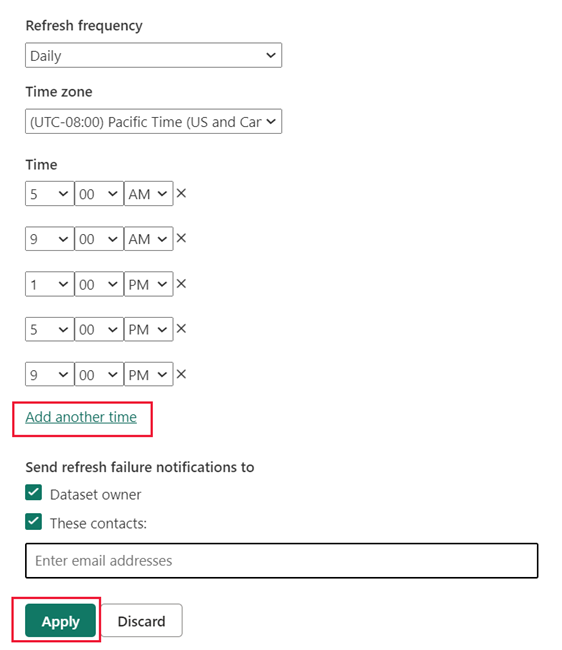
U moet ten minste één vernieuwing plannen. De eerste vernieuwing voor de frequentie die u selecteert, omvat zowel een trainingsbewerking als een vernieuwing waarmee nieuwe en bijgewerkte aggregaties in de cache in het geheugen worden geladen. Plan meer vernieuwingen om ervoor te zorgen dat rapportquery's die de cache voor aggregaties raken, resultaten krijgen die het meest worden gesynchroniseerd met de back-endgegevensbron. Zie Vernieuwingsbewerkingen voor meer informatie.
Selecteer Toepassen.
Trainen en vernieuwen op aanvraag
De eerste geplande vernieuwingsbewerking voor de gekozen frequentie omvat een trainingsbewerking. Als deze trainingsbewerking niet binnen de tijdslimiet van 60 minuten is voltooid, worden aggregaties in de cache niet geladen of bijgewerkt door de volgende vernieuwingsbewerking. De volgende trainingsbewerking wordt pas uitgevoerd als de eerste vernieuwingsbewerking van de gekozen frequentie wordt uitgevoerd.
In dergelijke gevallen kunt u handmatig een of meer trainings- en vernieuwingsbewerkingen op aanvraag uitvoeren om de training volledig te voltooien en aggregaties in de cache te laden of te vernieuwen. Wanneer u bijvoorbeeld de vernieuwingsgeschiedenis controleert, als de eerste geplande trainings- en vernieuwingsbewerking voor de dag (frequentie) niet binnen de tijdslimiet is voltooid en u niet wilt wachten op de geplande vernieuwing van de volgende dag die een trainingsbewerking bevat die moet worden uitgevoerd, kunt u een of meer on-demand train- en vernieuwingsbewerkingen uitvoeren om het gegevensquerylogboek (trainen) volledig te verwerken en aggregaties in de cache te laden (vernieuwen).
Als u een on-demand trein- en vernieuwingsbewerking wilt uitvoeren, selecteert u Nu trainen en vernieuwen. Zorg ervoor dat u de vernieuwingsgeschiedenis in de gaten houdt om ervoor te zorgen dat de trainingsbewerking op aanvraag is voltooid. Als dat niet het probleem is, voert u een andere train- en vernieuwingsbewerking uit totdat de training is voltooid en worden aggregaties geladen of vernieuwd in de cache.
Het uitvoeren van Train and Refresh Now kan handig zijn voor het verfijnen van het percentage rapportquery's dat aggregaties uit de cache in het geheugen gebruikt. Door een on-demand trein uit te voeren en nu te vernieuwen, kunt u sneller bepalen of de nieuwe percentageinstelling de trainingsbewerking binnen de tijdslimiet kan voltooien.
Houd er rekening mee dat trainings- en vernieuwingsbewerkingen, ongeacht of gepland of on-demand proces- en resource-intensief zijn voor zowel de gegevensbron als power BI. Kies een tijdstip waarop resources het minst worden beïnvloed.
Fine-tuning
Zowel door de gebruiker gedefinieerde als door het systeem gegenereerde aggregatiestabellen maken deel uit van het model, dragen bij aan de modelgrootte en zijn onderhevig aan bestaande beperkingen voor power BI-modelgrootte. De verwerking van aggregaties verbruikt ook resources en heeft invloed op de vernieuwingsduur van het model. Een optimale configuratie zorgt voor een evenwicht tussen het bieden van vooraf geaggregeerde resultaten van de cache voor in-memory aggregaties voor de meest gebruikte rapportquery's, terwijl het accepteren van tragere resultaten voor uitschieter- en ad-hocquery's in ruil voor snellere trainings- en vernieuwingstijden en een verminderde belasting van systeembronnen.
Het percentage aanpassen
Standaard is de cache-instelling voor aggregaties waarmee het percentage rapportquery's wordt bepaald dat aggregaties uit de cache in het geheugen worden gebruikt, 75%. Als u het percentage verhoogt, wordt een groter aantal rapportquery's hoger gerangschikt en daarom worden aggregaties voor deze query's opgenomen in de cache voor in-memory aggregaties. Hoewel een hoger percentage kan betekenen dat meer query's worden beantwoord vanuit de cache in het geheugen, kan dit ook langere trainings- en vernieuwingstijden betekenen. Als u zich echter aanpast aan een lager percentage, kan dit leiden tot kortere trainings- en vernieuwingstijden en minder resourcegebruik, maar de prestaties van de rapportvisualisatie kunnen afnemen omdat er minder rapportquery's worden beantwoord door de cache voor in-memory aggregaties, omdat deze rapportquery's in plaats daarvan naar de gegevensbron moeten afronden.
Voordat het systeem de optimale aggregaties kan bepalen die moeten worden opgenomen in de cache, moet het eerst weten welke rapportquerypatronen het vaakst worden gebruikt. Zorg ervoor dat u verschillende iteraties van de trainings-/vernieuwingsbewerkingen toestaat voordat u het percentage query's aanpast dat gebruikmaakt van de aggregatiecache. Dit geeft het trainingsalgoritmen de tijd om rapportquery's gedurende een bredere periode te analyseren en dienovereenkomstig aan te passen. Als u bijvoorbeeld vernieuwingen voor de dagelijkse frequentie hebt gepland, kunt u een volledige week wachten. Gebruikersrapportagepatronen op sommige dagen van de week kunnen afwijken van andere.
Het percentage aanpassen
Vouw in het semantische model Instellingen geplande vernieuwing en optimalisatie van prestaties uit.
Gebruik in de querydekking het percentage query's aanpassen dat de schuifregelaar voor geaggregeerde caches gebruikt om het percentage naar de gewenste waarde te verhogen of te verlagen. Wanneer u het percentage aanpast, biedt de grafiek Lift lift van queryprestaties geschatte reactietijden voor query's.
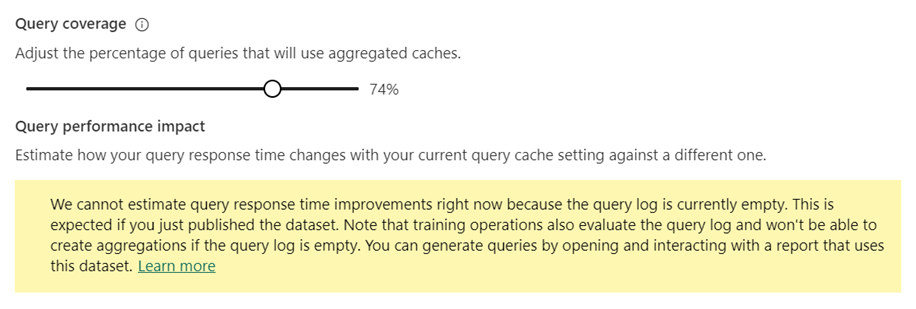
Selecteer Nu trainen en vernieuwen of Toepassen.
Impact van queryprestaties schatten
De liftgrafiek voor queryprestaties biedt geschatte uitvoeringstijden voor rapportquery's als een functie van het percentage query's dat gebruikmaakt van aggregaties in de cache. In de grafiek wordt in eerste instantie 0.0 weergegeven voor alle metrische gegevens totdat ten minste één trainings-/vernieuwingsbewerking wordt uitgevoerd. Na een eerste trainings-/vernieuwingsbewerking kan de grafiek u helpen bepalen of het percentage query's dat gebruikmaakt van de cache voor in-memory aggregaties, het antwoord van query's verder kan verbeteren.
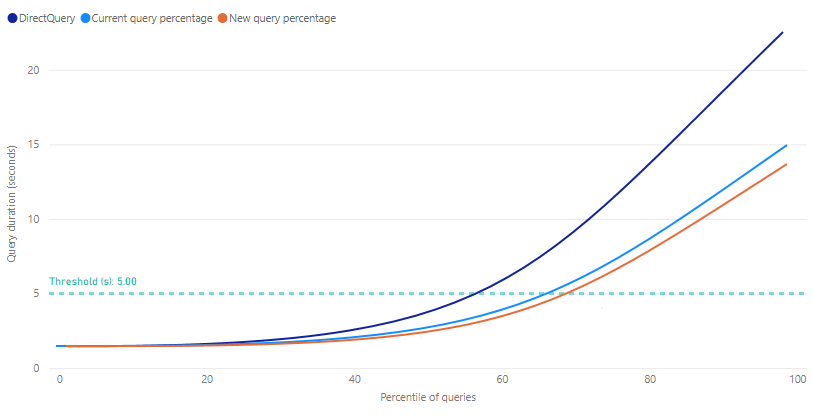
Drempelwaarde wordt weergegeven als een markeringslijn in het liftdiagram en geeft de reactietijd van de doelquery voor uw rapporten aan. Vervolgens kunt u het percentage query's dat de cache voor aggregaties gebruikt, verfijnen om een nieuw querypercentage te bepalen dat voldoet aan de gewenste drempelwaarde.
Metrische gegevens voor
DirectQuery : een geschatte duur in seconden voor een rapportquery die is verzonden naar en geretourneerd vanuit de gegevensbron met behulp van DirectQuery. Query's die niet kunnen worden beantwoord door de cache voor in-memory aggregaties, vallen doorgaans binnen deze schatting.
Huidig querypercentage : een geschatte duur in seconden voor rapportquery's die zijn beantwoord vanuit de cache voor aggregaties in het geheugen, op basis van de percentageinstelling voor de meest recente trainings-/vernieuwingsbewerking.
Nieuw querypercentage : een geschatte duur in seconden voor rapportquery's die zijn beantwoord vanuit de cache voor in-memory aggregaties voor het zojuist geselecteerde percentage. Wanneer de schuifregelaar percentage wordt gewijzigd, weerspiegelt deze metrische waarde de mogelijke wijziging.
Uitschakelen
U moet machtigingen voor modeleigenaar hebben om automatische aggregaties uit te schakelen. Werkruimtebeheerders kunnen machtigingen voor modeleigenaar overnemen.
Schakel automatische aggregatiestraining uit om uit te schakelen.
Wanneer u training uitschakelt, wordt u gevraagd om automatische aggregatietabellen te verwijderen.
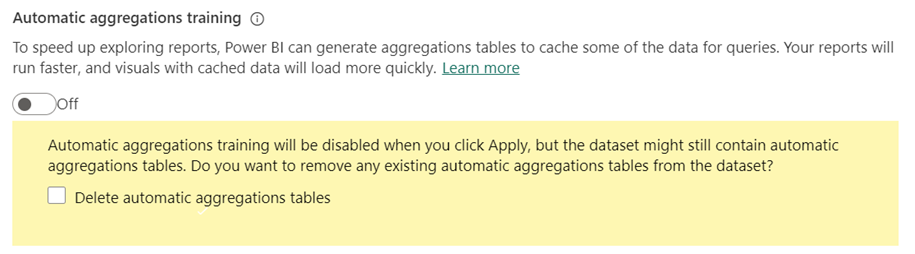
Als u ervoor kiest om bestaande automatische aggregatietabellen niet te verwijderen, blijven de tabellen in het model staan en blijven ze vernieuwd. Omdat de training echter is uitgeschakeld, worden er geen nieuwe aggregaties aan toegevoegd. Power BI blijft de bestaande tabellen gebruiken om zo mogelijk geaggregeerde queryresultaten op te halen.
Als u ervoor kiest om de tabellen te verwijderen, wordt het model teruggezet naar de oorspronkelijke staat zonder automatische aggregaties.
Selecteer Toepassen.
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor