Grote semantische modellen in Power BI Premium
Semantische Power BI-modellen kunnen gegevens opslaan in een zeer gecomprimeerde cache in het geheugen voor geoptimaliseerde queryprestaties, waardoor snelle interactiviteit van gebruikers mogelijk is. Met Premium-capaciteiten kunnen grote semantische modellen buiten de standaardlimiet worden ingeschakeld met de instelling opslagindeling voor grote semantische modellen. Wanneer deze optie is ingeschakeld, wordt de grootte van het semantische model beperkt door de Premium-capaciteitsgrootte of de maximale grootte die door de beheerder is ingesteld.
Grote semantische modellen kunnen worden ingeschakeld voor alle Premium P-SKU's, Embedded A-SKU's en met PPU (Premium Per User). De grote semantische modelgroottelimiet in Premium is vergelijkbaar met Azure Analysis Services, wat betreft de beperkingen van de grootte van het gegevensmodel.
Hoewel het vereist is dat semantische modellen groter worden dan 10 GB, heeft het inschakelen van de instelling voor opslagindelingen voor grote semantische modellen andere voordelen. Als u van plan bent om hulpprogramma's op basis van XMLA-eindpunten te gebruiken voor schrijfbewerkingen voor semantische modellen, moet u de instelling inschakelen, zelfs voor semantische modellen die u niet per se als een groot semantisch model zou karakteriseren. Wanneer deze functie is ingeschakeld, kan de opslagindeling voor grote semantische modellen de prestaties van XMLA-schrijfbewerkingen verbeteren.
Grote semantische modellen in de service hebben geen invloed op de uploadgrootte van het Power BI Desktop-model, die nog steeds beperkt is tot 10 GB. In plaats daarvan kunnen semantische modellen groter worden dan die limiet in de service bij vernieuwen.
Belangrijk
Power BI Premium biedt wel ondersteuning voor grote semantische modellen. Schakel de optie opslagindeling voor grote semantische modellen in om semantische modellen te gebruiken in Power BI Premium die groter zijn dan de standaardlimiet.
Notitie
Grote semantische modellen in Power BI Premium zijn niet beschikbaar in de Power BI-service voor Amerikaanse Overheids doD-klanten. Zie de beschikbaarheid van Power BI-functies voor Amerikaanse overheidsklanten voor meer informatie over welke functies beschikbaar zijn en welke niet.
Grote semantische modellen inschakelen
In de stappen hier wordt beschreven hoe u grote semantische modellen inschakelt voor een nieuw model dat naar de service is gepubliceerd. Voor bestaande semantische modellen is alleen stap 3 nodig.
Een model maken in Power BI Desktop. Als uw semantische model groter wordt en geleidelijk meer geheugen verbruikt, moet u incrementeel vernieuwen configureren.
Publiceer het model als een semantisch model naar de service.
Vouw in de semantische instellingen van het servicemodel >>de opslagindeling voor grote semantische modellen uit, stel de schuifregelaar in op Aan en selecteer vervolgens Toepassen.

Roep een vernieuwing aan om historische gegevens te laden op basis van het beleid voor incrementeel vernieuwen. Het laden van de geschiedenis kan enige tijd duren voordat de geschiedenis is vernieuwd. Volgende vernieuwingen moeten sneller zijn, afhankelijk van uw beleid voor incrementeel vernieuwen.
Standaardopslagindeling instellen
In ondersteunde regio's kunnen alle nieuwe semantische modellen die zijn gemaakt in een werkruimte die is toegewezen aan een Premium-capaciteit, standaard de grote semantische modelopslagindeling hebben ingeschakeld. Als de regio geen ondersteuning biedt voor grote semantische modellen, is de hieronder beschreven optie voor opslag van grote semantische modellen uitgeschakeld. U kunt zien welke regio's worden ondersteund in de sectie Beschikbaarheid van regio's.
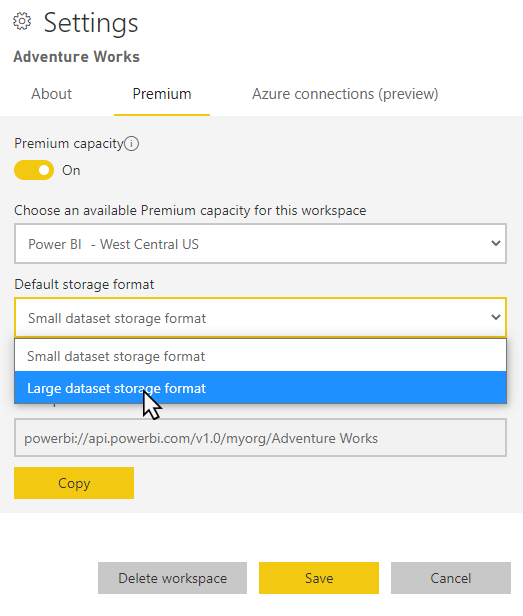
Selecteer Instellingen>Premium in de werkruimte.
Selecteer in de standaardopslagindeling grote semantische modelopslagindeling en selecteer opslaan.
Inschakelen met PowerShell
U kunt ook een grote semantische modelopslagindeling inschakelen met behulp van PowerShell. U moet capaciteitsbeheerders- en werkruimtebeheerdersbevoegdheden hebben om de PowerShell-cmdlets uit te voeren.
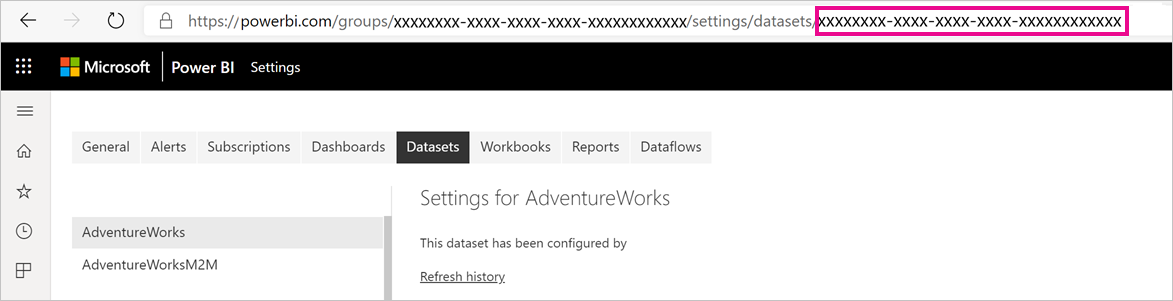
Zoek de semantische model-id (GUID). Op het tabblad Semantische modellen voor de werkruimte, onder de semantische modelinstellingen, ziet u de id in de URL.
Installeer de MicrosoftPowerBIMgmt-module vanuit een PowerShell-beheerdersprompt .
Install-Module -Name MicrosoftPowerBIMgmtVoer de volgende cmdlets uit om u aan te melden en de semantische modelopslagmodus te controleren.
Login-PowerBIServiceAccount (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorageHet antwoord moet het volgende zijn. De opslagmodus is ABF (Analysis Services-back-upbestand), wat de standaardinstelling is.
Id StorageMode -- ----------- <Semantic model ID> AbfVoer de volgende cmdlets uit om de opslagmodus in te stellen. Het kan enkele seconden duren om te converteren naar Premium-bestanden.
Set-PowerBIDataset -Id <Semantic model ID> -TargetStorageMode PremiumFiles (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorageHet antwoord moet het volgende zijn. De opslagmodus is nu ingesteld op Premium-bestanden.
Id StorageMode -- ----------- <Semantic model ID> PremiumFiles
U kunt de status van semantische modelconversies naar en van Premium-bestanden controleren met behulp van de cmdlet Get-PowerBIWorkspaceMigrationStatus .
Semantische modelverwijdering
Semantische modelverwijdering is een Premium-functie waarmee de som van semantische modelgrootten aanzienlijk groter is dan het geheugen dat beschikbaar is voor de aangeschafte SKU-grootte van de capaciteit. Eén semantisch model is nog steeds beperkt tot de geheugenlimieten van de SKU. Power BI maakt gebruik van dynamisch geheugenbeheer om inactieve semantische modellen uit het geheugen te verwijderen. Semantische modellen worden verwijderd, zodat Power BI andere semantische modellen kan laden om gebruikersquery's aan te pakken.
Notitie
Als u moet wachten totdat een verwijderd semantisch model opnieuw wordt geladen, kan er een merkbare vertraging optreden.
Belasting op aanvraag
Belasting op aanvraag is standaard ingeschakeld voor grote semantische modellen en kan de laadtijd van verwijderde semantische modellen aanzienlijk verbeteren. Met belasting op aanvraag krijgt u de volgende voordelen tijdens volgende query's en vernieuwingen:
Relevante gegevenspagina's worden op aanvraag geladen (in het geheugen gepaginad).
Verwijderde semantische modellen worden snel beschikbaar gesteld voor query's.
Laadoppervlakken op aanvraag bevatten aanvullende DMV-informatie (Dynamic Management View) die kan worden gebruikt om gebruikspatronen te identificeren en inzicht te hebben in de status van uw modellen. U kunt bijvoorbeeld de statistieken Temperatuur en Laatst geopend voor elke kolom in het semantische model controleren door de volgende DMV-query uit te voeren vanuit SQL Server Management Studio (SSMS):
Select * from SYSTEMRESTRICTSCHEMA ($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS, [DATABASE_NAME] = '<Semantic model Name>')
Grootte van semantisch model controleren
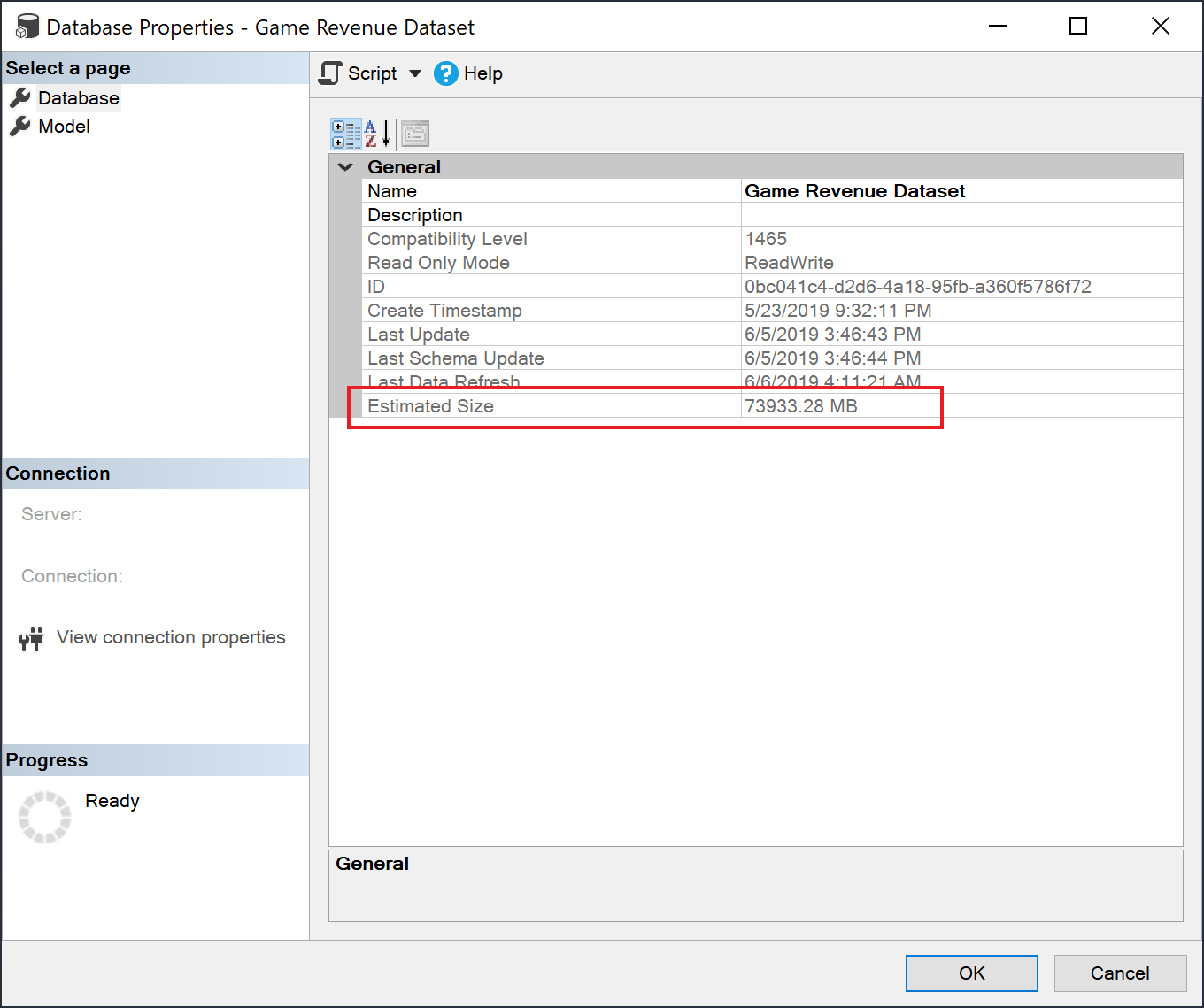
Nadat u historische gegevens hebt geladen, kunt u SSMS via het XMLA-eindpunt gebruiken om de geschatte semantische modelgrootte te controleren in het venster met modeleigenschappen.
U kunt ook de grootte van het semantische model controleren door de volgende DMV-query's uit te voeren vanuit SSMS. Som de kolommen DICTIONARY_SIZE en USED_SIZE uit de uitvoer om de semantische modelgrootte in bytes weer te geven.
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMNS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum DICTIONARY_SIZE (bytes)
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum USED_SIZE (bytes)
Standaardsegmentgrootte
Voor semantische modellen met behulp van de opslagindeling voor grote semantische modellen stelt Power BI automatisch de standaardsegmentgrootte in op 8 miljoen rijen om een goede balans te vinden tussen de geheugenvereisten en queryprestaties voor grote tabellen. Dit is dezelfde segmentgrootte als in Azure Analysis Services. Door de segmentgrootten uitgelijnd te houden, zorgt u voor vergelijkbare prestatiekenmerken bij het migreren van een groot gegevensmodel van Azure Analysis Services naar Power BI.
Overwegingen en beperkingen
Houd rekening met de volgende beperkingen bij het gebruik van grote semantische modellen:
Ondersteunde regio's: Grote semantische modellen zijn beschikbaar in Azure-regio's die Ondersteuning bieden voor Azure Premium Files Storage. Bekijk de tabel in de beschikbaarheid van regio's om een lijst weer te geven met alle ondersteunde regio's.
Maximale semantische modelgrootte instellen: Maximale semantische modelgrootte kan worden ingesteld door beheerders. Zie Max Memory in Datasets voor meer informatie.
Het vernieuwen van grote semantische modellen: Semantische modellen die dicht bij de helft van de capaciteitsgrootte liggen (bijvoorbeeld een semantisch model van 12 GB op een capaciteitsgrootte van 25 GB) kan groter zijn dan het beschikbare geheugen tijdens vernieuwingen. Met behulp van de verbeterde REST API voor vernieuwen of het XMLA-eindpunt kunt u fijnmazige gegevensvernieuwing uitvoeren, zodat het geheugen dat nodig is voor het vernieuwen, kan worden geminimaliseerd zodat deze binnen de grootte van uw capaciteit past.
Semantische modellen pushen: semantische modellen pushen bieden geen ondersteuning voor de opslagindeling van grote semantische modellen.
Pro wordt niet ondersteund : grote semantische modellen worden niet ondersteund in Pro-werkruimten. Als een werkruimte wordt gemigreerd van Premium naar Pro, kunnen semantische modellen met de instelling voor de opslagindeling voor grote semantische modellen niet worden geladen.
U kunt REST API's niet gebruiken om de instellingen van een werkruimte te wijzigen zodat nieuwe semantische modellen standaard de opslagindeling voor grote semantische modellen kunnen gebruiken.
Regionale beschikbaarheid
Grote semantische modellen in Power BI zijn alleen beschikbaar in Azure-regio's die Ondersteuning bieden voor Azure Premium Files Storage.
De volgende lijst bevat regio's waarin grote semantische modellen in Power BI beschikbaar zijn. Regio's die niet in de volgende lijst worden vermeld, worden niet ondersteund voor grote modellen.
Notitie
Zodra een groot semantisch model is gemaakt in een werkruimte, moet het in die regio blijven. U kunt een werkruimte met een groot semantisch model niet opnieuw toewijzen aan een Premium-capaciteit in een andere regio.
| Azure-regio | Afkorting van Azure-regio |
|---|---|
| Australië - oost | australiaeast |
| Australië - zuidoost | australiasoutheast |
| Brazilië - zuid | brazilsouth |
| Canada - oost | canadaeast |
| Canada - midden | canadacentral |
| India - centraal | centralindia |
| Central US | centralus |
| Azië - oost | eastasia |
| VS - oost | eastus |
| VS - oost 2 | eastus2 |
| Frankrijk - centraal | francecentral |
| Frankrijk - zuid | francesouth |
| Duitsland - noord | germanynorth |
| Duitsland - west-centraal | germanywestcentral |
| Japan East | japaneast |
| Japan - west | japanwest |
| Korea - centraal | koreacentral |
| Korea - zuid | koreasouth |
| VS - noord-centraal | northcentralus |
| Europa - noord | northeurope |
| Zuid-Afrika - noord | southafricanorth |
| Zuid-Afrika - west | southafricawest |
| VS - zuid-centraal | US - zuid-centraal |
| Azië - zuidoost | southeastasia |
| Zwitserland - noord | switzerlandnorth |
| Zwitserland - west | zwitserlandwest |
| UAE - centraal | uaecentral |
| VAE - noord | uaenorth |
| Verenigd Koninkrijk Zuid | uksouth |
| Verenigd Koninkrijk West | ukwest |
| Europa -west | westeurope |
| India - west | westindia |
| VS - west | westus |
| VS - west 2 | westus2 |
Gerelateerde inhoud
De volgende koppelingen bevatten informatie die nuttig kan zijn voor het werken met grote modellen: