Incrementeel vernieuwen en realtime gegevens voor semantische modellen
Incrementeel vernieuwen breidt geplande vernieuwingsbewerkingen uit door geautomatiseerde partities te maken en te beheren voor semantische modeltabellen die regelmatig nieuwe en bijgewerkte gegevens laden. Voor de meeste modellen bevatten een of meer tabellen transactiegegevens die vaak worden gewijzigd en exponentieel kunnen groeien, zoals een feitentabel in een relationeel of sterdatabaseschema. Een incrementeel vernieuwingsbeleid voor het partitioneren van de tabel, het vernieuwen van alleen de meest recente importpartities en optioneel het gebruik van een andere DirectQuery-partitie voor realtimegegevens kan de hoeveelheid gegevens die moet worden vernieuwd aanzienlijk verminderen. Tegelijkertijd zorgt dit beleid ervoor dat de meest recente wijzigingen in de gegevensbron worden opgenomen in de queryresultaten.
Met incrementeel vernieuwen en realtime gegevens:
- Er zijn minder vernieuwingscycli nodig voor snel veranderende gegevens. De DirectQuery-modus haalt de meest recente gegevensupdates op wanneer query's worden verwerkt, zonder dat er een hoog vernieuwingsfrequentie nodig is.
- Vernieuwingen zijn sneller. Alleen de meest recente gegevens die zijn gewijzigd, moeten worden vernieuwd.
- Vernieuwingen zijn betrouwbaarder. Langlopende verbindingen met vluchtige gegevensbronnen zijn niet nodig. Query's voor het uitvoeren van brongegevens worden sneller uitgevoerd, waardoor netwerkproblemen kunnen worden verstoord.
- Resourceverbruik wordt verminderd. Minder gegevens om te vernieuwen vermindert het totale geheugenverbruik en andere resources in zowel Power BI- als gegevensbronsystemen.
- Grote semantische modellen zijn ingeschakeld. Semantische modellen met mogelijk miljarden rijen kunnen groeien zonder dat het hele model volledig hoeft te worden vernieuwd met elke vernieuwingsbewerking.
- Het instellen is eenvoudig. Beleidsregels voor incrementeel vernieuwen worden gedefinieerd in Power BI Desktop met slechts een paar taken. Wanneer Power BI Desktop het rapport publiceert, past de service deze beleidsregels automatisch toe bij elke vernieuwing.
Wanneer u een Power BI Desktop-model naar de service publiceert, heeft elke tabel in het nieuwe model één partitie. Die ene partitie bevat alle rijen voor die tabel. Als de tabel groot is, bijvoorbeeld met tientallen miljoenen rijen of meer, kan een vernieuwing voor die tabel lang duren en een overmatige hoeveelheid resources verbruiken.
Met incrementeel vernieuwen wordt de service dynamisch gepartitioneerd en worden gegevens gescheiden die regelmatig moeten worden vernieuwd van gegevens die minder vaak kunnen worden vernieuwd. Tabelgegevens worden gefilterd met behulp van datum-/tijdparameters van Power Query met de gereserveerde, hoofdlettergevoelige namen RangeStart en RangeEnd. Wanneer u incrementeel vernieuwen configureert in Power BI Desktop, worden deze parameters gebruikt om slechts een kleine periode van gegevens te filteren die in het model worden geladen. Wanneer Power BI Desktop het rapport publiceert naar de Power BI-service, maakt de service met de eerste vernieuwingsbewerking incrementele vernieuwing en historische partities, en eventueel een realtime DirectQuery-partitie op basis van de beleidsinstellingen voor incrementeel vernieuwen. De service overschrijft vervolgens de parameterwaarden om gegevens voor elke partitie te filteren en op te vragen op basis van datum-/tijdwaarden voor elke rij.
Bij elke volgende vernieuwing retourneren de queryfilters alleen de rijen binnen de vernieuwingsperiode die dynamisch is gedefinieerd door de parameters. Deze rijen met een datum/tijd binnen de vernieuwingsperiode worden vernieuwd. Rijen met een datum/tijd die niet langer binnen de vernieuwingsperiode vallen, worden vervolgens onderdeel van de historische periode, die niet wordt vernieuwd. Als een realtime DirectQuery-partitie is opgenomen in het beleid voor incrementeel vernieuwen, wordt het filter ook bijgewerkt, zodat er wijzigingen worden opgehaald die zich na de vernieuwingsperiode voordoen. Zowel de vernieuwings- als de historische perioden worden vooruitgedraaid. Wanneer er nieuwe incrementele vernieuwingspartities worden gemaakt, worden vernieuwingspartities in de vernieuwingsperiode geen historische partities meer. In de loop van de tijd worden historische partities minder gedetailleerd wanneer ze samen worden samengevoegd. Wanneer een historische partitie zich niet meer in de historische periode bevindt die door het beleid is gedefinieerd, wordt deze volledig uit het model verwijderd. Dit gedrag wordt een patroon voor rollend venster genoemd.
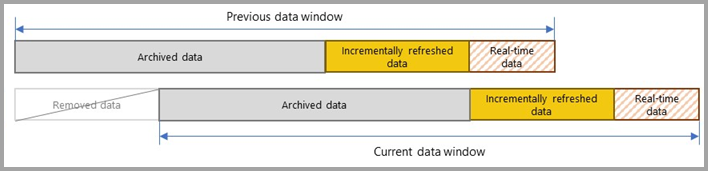
Het mooie van incrementeel vernieuwen is dat de service deze allemaal voor u verwerkt op basis van het beleid voor incrementeel vernieuwen dat u definieert. In feite zijn het proces en de partities die ermee zijn gemaakt, niet zichtbaar in de service. In de meeste gevallen is een goed gedefinieerd beleid voor incrementeel vernieuwen alles wat nodig is om de prestaties van het vernieuwen van modellen aanzienlijk te verbeteren. De realtime DirectQuery-partitie wordt echter alleen ondersteund voor modellen in Premium-capaciteiten. Power BI Premium maakt ook geavanceerdere partitie- en vernieuwingsscenario's mogelijk via het XMLA-eindpunt (XMLA).
Vereisten
In de volgende secties worden de ondersteunde plannen en gegevensbronnen beschreven.
Ondersteunde abonnementen
Incrementeel vernieuwen wordt ondersteund voor Power BI Premium-, Premium per gebruiker-, Power BI Pro- en Power BI Embedded-modellen.
Het ophalen van de meest recente gegevens in realtime met DirectQuery wordt alleen ondersteund voor Power BI Premium-, Premium per gebruiker- en Power BI Embedded-modellen.
Ondersteunde gegevensbronnen
Incrementeel vernieuwen en realtime gegevens werken het beste voor gestructureerde, relationele gegevensbronnen zoals SQL Database en Azure Synapse, maar kunnen ook voor andere gegevensbronnen werken. In elk geval moet uw gegevensbron het volgende ondersteunen:
Datumfiltering : de gegevensbron moet een mechanisme ondersteunen voor het filteren van gegevens op datum. Voor een relationele bron is dit meestal een datumkolom van het gegevenstype datum/tijd of geheel getal in de doeltabel. De parameters RangeStart en RangeEnd, die het gegevenstype datum/tijd moeten zijn, filteren tabelgegevens op basis van de datumkolom. Voor datumkolommen met surrogaatsleutels voor gehele getallen in de vorm van yyyymmdd, kunt u een functie maken waarmee de datum/tijd-waarde in de parameters RangeStart en RangeEnd wordt geconverteerd zodat deze overeenkomen met de surrogaatsleutels voor gehele getallen van de datumkolom. Zie Incrementeel vernieuwen configureren : Datum/tijd converteren naar geheel getal voor meer informatie.
Voor andere gegevensbronnen moeten de parameters RangeStart en RangeEnd op een of andere manier worden doorgegeven aan de gegevensbron, waardoor filteren mogelijk is. Voor gegevensbronnen op basis van bestanden waarin bestanden en mappen zijn geordend op datum, kunnen de parameters RangeStart en RangeEnd worden gebruikt om de bestanden en mappen te filteren om te selecteren welke bestanden moeten worden geladen. Voor webgegevensbronnen kunnen de parameters RangeStart en RangeEnd worden geïntegreerd in de HTTP-aanvraag. De volgende query kan bijvoorbeeld worden gebruikt voor het incrementeel vernieuwen van de traceringen van een AppInsights-exemplaar:
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
Wanneer incrementeel vernieuwen is geconfigureerd, wordt een Power Query-expressie met een datum-/tijdfilter op basis van de parameters RangeStart en RangeEnd uitgevoerd op basis van de gegevensbron. Als het filter is opgegeven in een querystap na de eerste bronquery, is het belangrijk dat query folding de eerste querystap combineert met de stappen die verwijzen naar de parameters RangeStart en RangeEnd. In de volgende query-expressie wordt de Table.SelectRows query bijvoorbeeld gevouwen omdat deze direct volgt op de Sql.Database stap en SQL Server ondersteuning biedt voor vouwen:
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
Het vouwen van de uiteindelijke query is niet vereist. In de volgende expressie gebruiken we bijvoorbeeld een niet-vouwen NativeQuery, maar integreren we de parameters RangeStart en RangeEnd rechtstreeks in SQL:
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
Als het beleid voor incrementeel vernieuwen echter het ophalen van realtimegegevens met DirectQuery omvat, kunnen niet-vouwtransformaties niet worden gebruikt. Als het een puur importmodusbeleid is zonder realtime gegevens, kan de query mashup-engine het filter mogelijk compenseren en lokaal toepassen. Hiervoor moet u alle rijen voor de tabel ophalen uit de gegevensbron. Dit kan ertoe leiden dat incrementeel vernieuwen traag is en het proces kan onvoldoende resources bevatten in de Power BI-service of in een on-premises gegevensgateway, waardoor het doel van incrementeel vernieuwen effectief wordt verslagen.
Omdat ondersteuning voor het vouwen van query's verschilt voor verschillende typen gegevensbronnen, moet verificatie worden uitgevoerd om ervoor te zorgen dat de filterlogica wordt opgenomen in de query's die worden uitgevoerd op de gegevensbron. In de meeste gevallen probeert Power BI Desktop deze verificatie voor u uit te voeren bij het definiëren van het beleid voor incrementeel vernieuwen. Voor gegevensbronnen op basis van SQL, zoals SQL Database, Azure Synapse, Oracle en Teradata, is deze verificatie betrouwbaar. Andere gegevensbronnen kunnen echter niet verifiëren zonder de query's te traceren. Als Power BI Desktop de query's niet kan bevestigen, wordt er een waarschuwing weergegeven in het dialoogvenster Beleidsconfiguratie incrementeel vernieuwen.
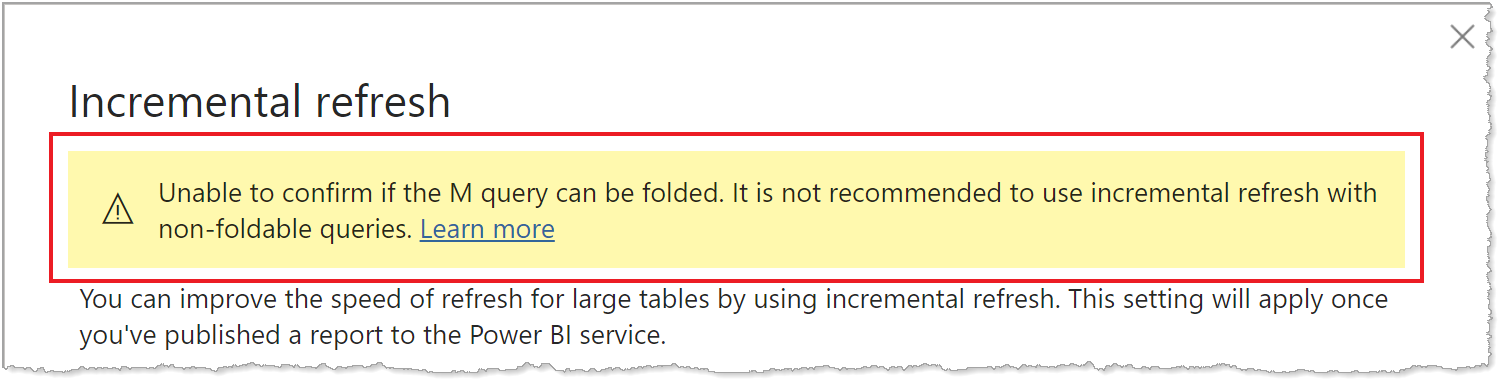
Als u deze waarschuwing ziet en wilt controleren of de benodigde query folding plaatsvindt, gebruikt u de functie Diagnostische gegevens van Power Query of traceer query's met behulp van een hulpprogramma dat wordt ondersteund door de gegevensbron, zoals SQL Profiler. Als het vouwen van query's niet plaatsvindt, controleert u of de filterlogica is opgenomen in de query die wordt doorgegeven aan de gegevensbron. Zo niet, dan bevat de query waarschijnlijk een transformatie die het vouwen voorkomt.
Voordat u de oplossing voor incrementeel vernieuwen configureert, moet u de richtlijnen voor het vouwen van query's in Power BI Desktop en Het vouwen van Query's grondig lezen en begrijpen. Deze artikelen kunnen u helpen bepalen of uw gegevensbron en query's ondersteuning bieden voor het vouwen van query's.
Eén gegevensbron
Wanneer u incrementele vernieuwings- en realtimegegevens configureert met behulp van Power BI Desktop of een geavanceerde oplossing configureert met behulp van TMSL (Tabular Model Scripting Language) of Tom (Tabular Object Model) via het XMLA-eindpunt, moeten alle partities, ongeacht of u importeert of DirectQuery, gegevens opvragen uit één bron.
Andere typen gegevensbronnen
Met behulp van meer aangepaste queryfuncties en querylogica kan incrementeel vernieuwen worden gebruikt met andere typen gegevensbronnen als filters op basis RangeStart van en RangeEnd kunnen worden doorgegeven in één query, zoals met gegevensbronnen zoals Excel-werkmapbestanden die zijn opgeslagen in een map, bestanden in SharePoint en RSS-feeds. Houd er rekening mee dat dit geavanceerde scenario's zijn waarvoor verdere aanpassingen en tests nodig zijn, behalve wat hier wordt beschreven. Raadpleeg de sectie Community verderop in dit artikel voor suggesties over hoe u meer informatie kunt vinden over het gebruik van incrementeel vernieuwen voor unieke scenario's.
Termijnen
Ongeacht incrementeel vernieuwen hebben Power BI Pro-modellen een vernieuwingstijdlimiet van twee uur en bieden geen ondersteuning voor het ophalen van realtime gegevens met DirectQuery. Voor modellen in een Premium-capaciteit is de tijdslimiet vijf uur. Vernieuwingsbewerkingen zijn proces- en geheugenintensief. Een volledige vernieuwingsbewerking kan zoveel als verdubbelen van de hoeveelheid geheugen die alleen door het model is vereist, omdat de service een momentopname van het model in het geheugen onderhoudt totdat de vernieuwingsbewerking is voltooid. Vernieuwingsbewerkingen kunnen ook intensief worden verwerkt, wat een aanzienlijke hoeveelheid beschikbare CPU-resources verbruikt. Vernieuwingsbewerkingen moeten ook afhankelijk zijn van vluchtige verbindingen met gegevensbronnen en de mogelijkheid van deze gegevensbronsystemen om snel queryuitvoer te retourneren. De tijdslimiet is een beveiliging om het oververbruik van uw beschikbare resources te beperken.
Notitie
Met Premium-capaciteiten hebben vernieuwingsbewerkingen die worden uitgevoerd via het XMLA-eindpunt geen tijdslimiet. Zie Geavanceerde incrementele vernieuwing met het XMLA-eindpunt voor meer informatie.
Omdat incrementeel vernieuwen vernieuwingsbewerkingen optimaliseert op partitieniveau in het model, kan het resourceverbruik aanzienlijk worden verminderd. Tegelijkertijd, zelfs bij incrementeel vernieuwen, tenzij ze het XMLA-eindpunt doorlopen, worden vernieuwingsbewerkingen gebonden aan dezelfde limieten van twee uur en vijf uur. Een effectief beleid voor incrementeel vernieuwen vermindert niet alleen de hoeveelheid gegevens die worden verwerkt met een vernieuwingsbewerking, maar vermindert ook de hoeveelheid onnodige historische gegevens die zijn opgeslagen in uw model.
Query's kunnen ook worden beperkt door een standaardtijdlimiet voor de gegevensbron. De meeste relationele gegevensbronnen staan het overschrijven van tijdslimieten in de Power Query M-expressie toe. In de onderstaande expressie wordt bijvoorbeeld de functie voor gegevenstoegang van SQL Server gebruikt om CommandTimeout in te stellen op 2 uur. Elke periode die door de beleidsbereiken is gedefinieerd, verzendt een query met de time-outinstelling voor de opdracht:
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
Voor zeer grote modellen in Premium-capaciteiten die waarschijnlijk miljarden rijen bevatten, kan de eerste vernieuwingsbewerking worden opgestart. Met Bootstrapping kan de service tabel- en partitieobjecten voor het model maken, maar worden geen gegevens in een van de partities geladen en verwerkt. Met BEHULP van SQL Server Management Studio kunt u partities instellen die afzonderlijk, opeenvolgend of parallel moeten worden verwerkt om de hoeveelheid gegevens die in één query worden geretourneerd, te verminderen en ook de tijdslimiet van vijf uur te omzeilen. Zie Geavanceerde incrementele vernieuwing: time-outs voorkomen bij de eerste volledige vernieuwing.
Huidige datum en tijd
Standaard wordt de huidige datum en tijd bepaald op basis van Coordinated Universal Time (UTC) op het moment van vernieuwen. Voor on-demand en geplande vernieuwingen kunt u een andere tijdzone configureren onder 'Vernieuwen plannen' waarmee rekening wordt gehouden bij het bepalen van de huidige datum en tijd. Een vernieuwing die plaatsvindt om 18:00 uur Pacific Time (VS en Canada) met een tijdzone die is geconfigureerd, bepaalt bijvoorbeeld de huidige datum en tijd op basis van Pacific Time, niet UTC, die de volgende dag zou retourneren.
Notitie
De tijdzoneconfiguratie wordt in aanmerking genomen, zelfs als het vernieuwen van de planning is uitgeschakeld.
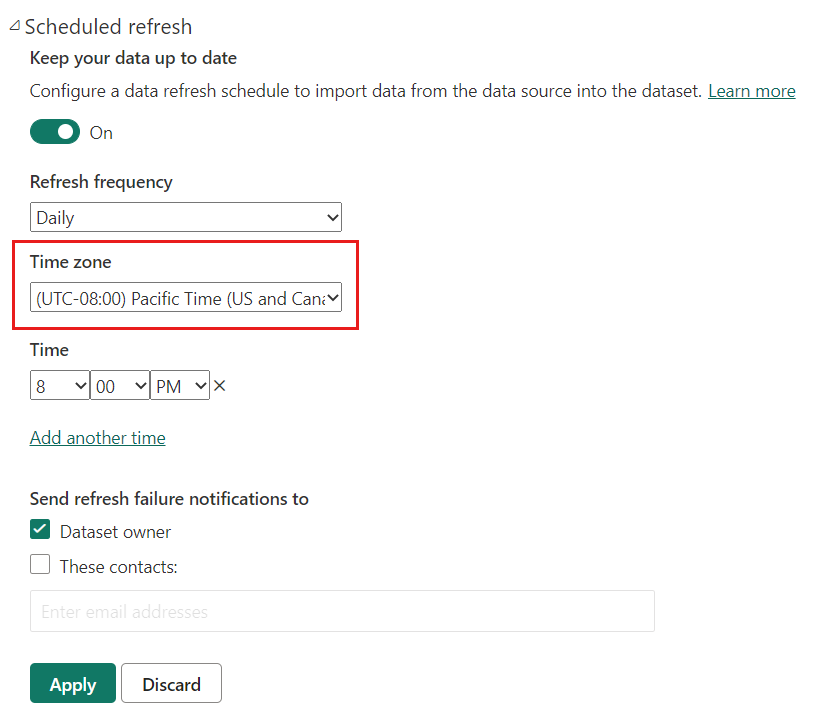
Vernieuwingsbewerkingen die niet worden aangeroepen via de Power BI-service, zoals de opdracht XMLA TMSL-vernieuwing of verbeterde vernieuwings-API, houden niet rekening met de geconfigureerde tijdzone voor geplande vernieuwing en de standaardinstelling voor UTC.
Incrementele vernieuwing en realtimegegevens configureren
In deze sectie worden belangrijke concepten beschreven van het configureren van incrementele vernieuwing en realtimegegevens. Als u klaar bent voor gedetailleerde stapsgewijze instructies, raadpleegt u Incrementeel vernieuwen en realtime gegevens configureren voor semantische modellen.
Het configureren van incrementeel vernieuwen wordt uitgevoerd in Power BI Desktop. Voor de meeste modellen zijn slechts enkele taken vereist. Houd echter rekening met de volgende punten:
- Nadat u naar de Power BI-service hebt gepubliceerd, kunt u hetzelfde model niet opnieuw publiceren vanuit Power BI Desktop. Als u opnieuw publiceert, worden bestaande partities en gegevens die al in het model aanwezig zijn, verwijderd. Als u publiceert naar een Premium-capaciteit, kunnen volgende wijzigingen in het metagegevensschema worden aangebracht met hulpprogramma's zoals de opensource ALM Toolkit of met BEHULP van TMSL. Zie Geavanceerde incrementele vernieuwing- alleen-metagegevensimplementatie voor meer informatie.
- Nadat u het model naar de Power BI-service hebt gepubliceerd, kunt u het model niet terug downloaden als pbix-bestand naar Power BI Desktop. Omdat modellen in de service zo groot kunnen worden, is het niet praktisch om ze te downloaden en te openen op een gewone desktopcomputer.
- Wanneer u realtime gegevens met DirectQuery ophaalt, kunt u het model niet publiceren naar een niet-Premium-werkruimte. Incrementeel vernieuwen met realtime gegevens wordt alleen ondersteund met Power BI Premium.
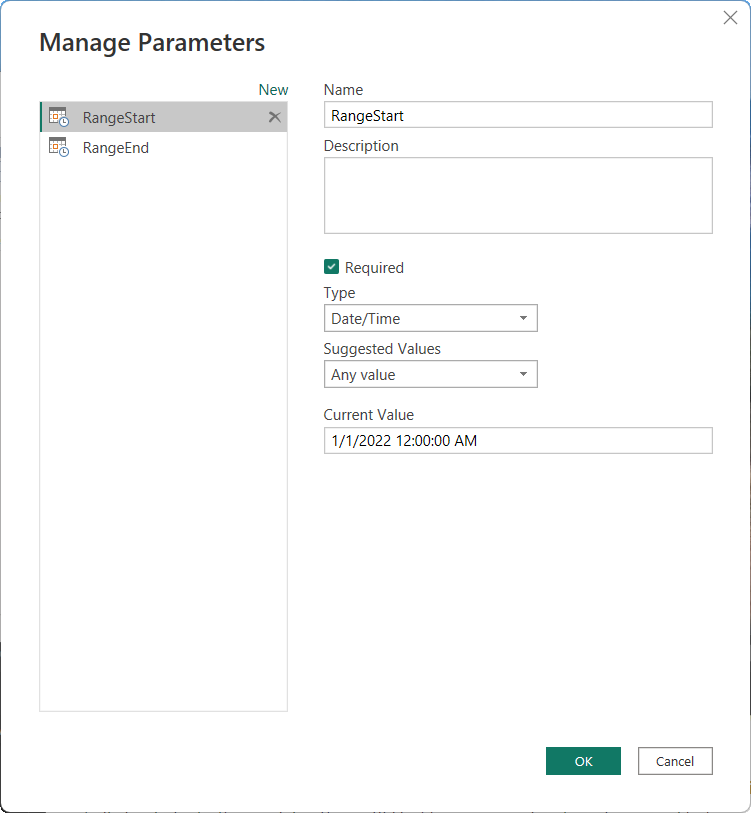
Parameters maken
Als u incrementeel vernieuwen in Power BI Desktop wilt configureren, maakt u eerst twee Power Query-datum-/tijdparameters met de gereserveerde, hoofdlettergevoelige namen RangeStart en RangeEnd. Deze parameters, die zijn gedefinieerd in het dialoogvenster Parameters beheren in Power Query-editor, worden in eerste instantie gebruikt om de gegevens te filteren die in de Power BI Desktop-modeltabel zijn geladen, zodat alleen die rijen met een datum/tijd binnen die periode worden opgenomen. RangeStart vertegenwoordigt de oudste of vroegste datum/tijd en RangeEnd vertegenwoordigt de nieuwste of laatste datum/tijd. Nadat het model naar de service RangeStart is gepubliceerd en RangeEnd automatisch wordt overschreven door de service om gegevens op te vragen die zijn gedefinieerd door de vernieuwingsperiode die is opgegeven in de beleidsinstellingen voor incrementeel vernieuwen.
De gegevensbrontabel FactInternetSales gemiddelden 10.000 nieuwe rijen per dag. Als u het aantal rijen wilt beperken dat in eerste instantie in het model in Power BI Desktop is geladen, geeft u een periode van twee dagen tussen RangeStart en RangeEnd.
Gegevens filteren
Met de RangeStart gedefinieerde parameters RangeEnd past u aangepaste datumfilters toe op de datumkolom van uw tabel. De filters die u toepast, selecteren een subset met gegevens die in het model worden geladen wanneer u Toepassen selecteert.
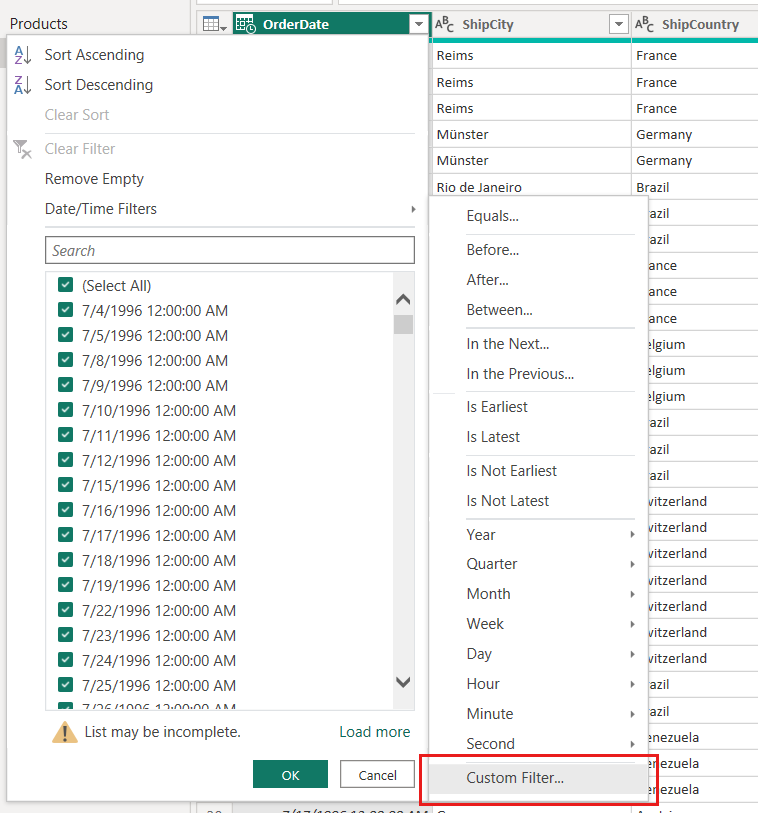
In ons voorbeeld FactInternetSales worden twee dagen aan gegevens (ongeveer 20.000 rijen) in het model geladen nadat u filters hebt gemaakt op basis van de parameters en het toepassen van stappen.
Beleid definiëren
Nadat filters zijn toegepast en er een subset met gegevens in het model is geladen, definieert u een beleid voor incrementeel vernieuwen voor de tabel. Nadat het model naar de service is gepubliceerd, wordt het beleid door de service gebruikt om tabelpartities te maken en te beheren en vernieuwingsbewerkingen uit te voeren. Als u het beleid wilt definiëren, gebruikt u het dialoogvenster Incrementeel vernieuwen en realtime gegevens om zowel vereiste als optionele instellingen op te geven.
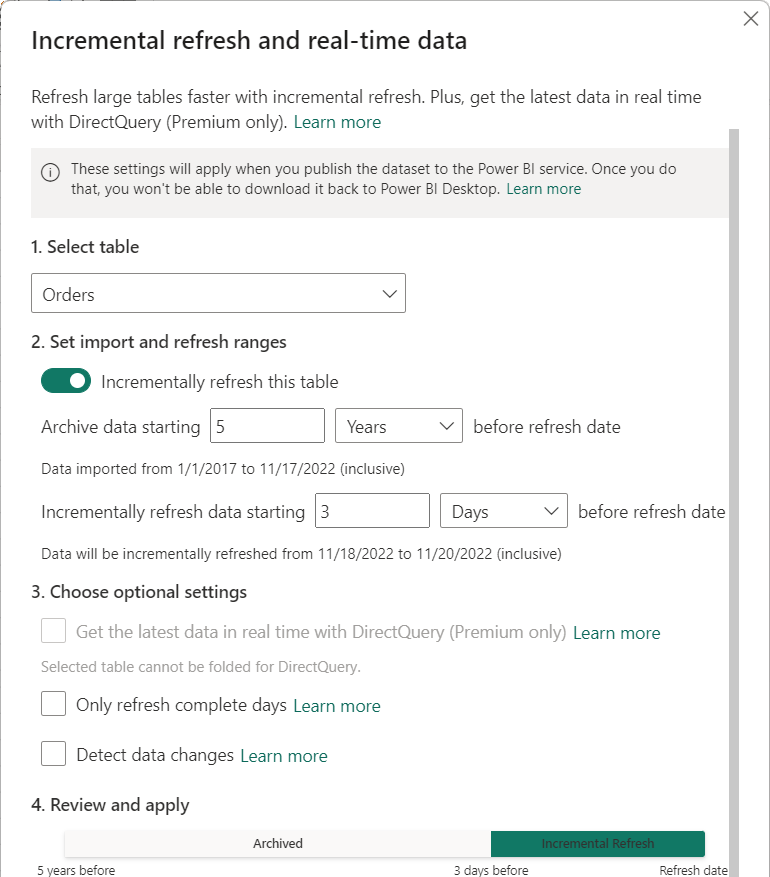
Tabel
De keuzelijst Tabel selecteren is standaard ingesteld op de tabel die u hebt geselecteerd in de gegevensweergave. Schakel incrementeel vernieuwen in voor de tabel met de schuifregelaar. Als de Power Query-expressie voor de tabel geen filter bevat op basis van de RangeStart en RangeEnd parameters, is de wisselknop niet beschikbaar.
Verplichte instellingen
De instelling Archiefgegevens die vóór de vernieuwingsdatum beginnen, bepaalt de historische periode waarin rijen met een datum/tijd in die periode zijn opgenomen in het model, plus rijen voor de huidige onvolledige historische periode, plus rijen in de vernieuwingsperiode tot aan de huidige datum en tijd.
Als u bijvoorbeeld vijf jaar opgeeft, worden in de tabel de laatste vijf hele jaren aan historische gegevens in jaarpartities opgeslagen. De tabel bevat ook rijen voor het huidige jaar in kwartaal-, maand- of dagpartities, tot en met de vernieuwingsperiode.
Voor modellen in Premium-capaciteiten kunnen backdated historische partities selectief worden vernieuwd met een granulariteit die wordt bepaald door deze instelling. Zie Geavanceerde incrementele vernieuwing - Partities voor meer informatie.
De instelling Incrementeel vernieuwen van gegevens die beginnen voordat de vernieuwingsdatum wordt ingesteld, bepaalt de incrementele vernieuwingsperiode waarin alle rijen met een datum/tijd in die periode zijn opgenomen in de vernieuwingspartities en worden vernieuwd met elke vernieuwingsbewerking.
Als u bijvoorbeeld een vernieuwingsperiode van drie dagen opgeeft, overschrijft de service de RangeStart en RangeEnd parameters voor het maken van een query voor rijen met een datum/tijd binnen een periode van drie dagen, waarbij het begin en einde afhankelijk zijn van de huidige datum en tijd. Rijen met een datum/tijd in de afgelopen drie dagen tot aan de huidige vernieuwingsbewerkingstijd worden vernieuwd. Met dit type beleid kunt u onze modeltabel FactInternetSales verwachten in de service, die gemiddelden 10.000 nieuwe rijen per dag gebruikt om ongeveer 30.000 rijen te vernieuwen met elke vernieuwingsbewerking.
Geef een periode op die alleen het minimale aantal rijen bevat dat vereist is om nauwkeurige rapportage te garanderen. Wanneer u beleidsregels voor meer dan één tabel definieert, moeten dezelfde RangeStart en RangeEnd parameters worden gebruikt, zelfs als er verschillende opslag- en vernieuwingsperioden zijn gedefinieerd voor elke tabel.
Optionele instellingen
Met de instelling De meest recente gegevens in realtime ophalen met de instelling DirectQuery (alleen Premium) kunt u de meest recente wijzigingen uit de geselecteerde tabel in de gegevensbron ophalen na de incrementele vernieuwingsperiode met behulp van DirectQuery. Alle rijen met een datum/tijd later dan de incrementele vernieuwingsperiode worden opgenomen in een DirectQuery-partitie en opgehaald uit de gegevensbron met elke modelquery.
Als deze instelling bijvoorbeeld is ingeschakeld bij elke vernieuwingsbewerking, overschrijft de service de RangeStart en RangeEnd parameters voor het maken van een query voor rijen met een datum/tijd na de vernieuwingsperiode, waarbij het begin afhankelijk is van de huidige datum en tijd. Rijen met een datum/tijd na de huidige vernieuwingsbewerkingstijd worden ook opgenomen. Met dit type beleid bevat de modeltabel FactInternetSales in de service de meest recente gegevensupdates.
De instelling Alleen volledige vernieuwingsdagen zorgt ervoor dat alle rijen voor de hele dag worden opgenomen in de vernieuwingsbewerking. Deze instelling is optioneel, tenzij u de meest recente gegevens in realtime ophalen inschakelt met de instelling DirectQuery (alleen Premium). Stel dat uw vernieuwing elke ochtend om 4:00 uur wordt uitgevoerd. Als er tijdens die vier uur tussen middernacht en 4:00 uur nieuwe rijen met gegevens worden weergegeven in de gegevensbrontabel, wilt u er geen rekening mee houden. Sommige zakelijke metrische gegevens, zoals vaten per dag in de olie- en gasindustrie, zijn niet logisch met gedeeltelijke dagen. Een ander voorbeeld is het vernieuwen van gegevens uit een financieel systeem waarbij gegevens voor de vorige maand worden goedgekeurd op de twaalfde kalenderdag van de maand. U kunt de vernieuwingsperiode instellen op één maand en de vernieuwing plannen op de twaalfde dag van de maand. Als deze optie is geselecteerd, worden bijvoorbeeld januarigegevens op 12 februari vernieuwd.
Houd er rekening mee dat, tenzij geplande vernieuwing is geconfigureerd voor een niet-UTC-tijdzone, vernieuwingsbewerkingen in de service worden uitgevoerd onder UTC-tijd, die de effectieve datum en volledige perioden kunnen bepalen.
Met de instelling Gegevenswijzigingen detecteren kunt u nog selectiever vernieuwen. U kunt een datum-/tijdkolom selecteren die wordt gebruikt om alleen de dagen te identificeren en te vernieuwen waarop de gegevens zijn gewijzigd. Bij deze instelling wordt ervan uitgegaan dat een dergelijke kolom bestaat in de gegevensbron. Dit is doorgaans voor controledoeleinden. Deze kolom mag niet dezelfde kolom zijn die wordt gebruikt om de gegevens te partitioneren met de RangeStart en RangeEnd parameters. De maximumwaarde van deze kolom wordt geëvalueerd voor elk van de perioden in het incrementele bereik. Als deze niet is gewijzigd sinds de laatste vernieuwing, is het niet nodig om de periode te vernieuwen, waardoor de dagen die incrementeel van drie naar één zijn vernieuwd, kunnen worden verminderd.
Het huidige ontwerp vereist dat de kolom voor het detecteren van gegevenswijzigingen wordt bewaard en in het geheugen in de cache wordt opgeslagen. De volgende technieken kunnen worden gebruikt om kardinaliteit en geheugenverbruik te verminderen:
- Behoud alleen de maximumwaarde van de kolom op het moment van vernieuwen, mogelijk met behulp van een Power Query-functie.
- Verminder de precisie tot een acceptabel niveau, gezien de vereisten voor de vernieuwingsfrequentie.
- Definieer een aangepaste query voor het detecteren van gegevenswijzigingen met behulp van het XMLA-eindpunt en voorkom dat de kolomwaarde helemaal behouden blijft.
In sommige gevallen kan het inschakelen van de optie Gegevenswijzigingen detecteren* verder worden uitgebreid. U kunt bijvoorbeeld voorkomen dat een kolom voor laatste updates in de cache in het geheugen behouden blijft of scenario's inschakelt waarin een configuratie-/instructietabel wordt voorbereid door ETL-processen (extract-transform-load) voor het markeren van alleen de partities die moeten worden vernieuwd. In dergelijke gevallen gebruikt u TMSL en/of tom voor Premium-capaciteiten om het gedrag van wijzigingen in gegevens te overschrijven. Zie Geavanceerde incrementele vernieuwing: aangepaste query's voor het detecteren van gegevenswijzigingen voor meer informatie.
Publiceren
Nadat u het beleid voor incrementeel vernieuwen hebt geconfigureerd, publiceert u het model naar de service. Wanneer het publiceren is voltooid, kunt u de eerste vernieuwingsbewerking uitvoeren op het model.
Notitie
Semantische modellen met een incrementeel vernieuwingsbeleid om de meest recente gegevens in realtime op te halen met DirectQuery, kunnen alleen worden gepubliceerd naar een Premium-werkruimte.
Voor modellen die zijn gepubliceerd naar werkruimten die zijn toegewezen aan Premium-capaciteiten, kunt u, als u denkt dat het model groter wordt dan 1 GB, de prestaties van de vernieuwingsbewerking verbeteren en ervoor zorgen dat het model de maximale grootte niet overschrijdt door de opslagindeling voor grote modellen in te schakelen voordat u de eerste vernieuwingsbewerking in de service uitvoert. Zie Grote modellen in Power BI Premium voor meer informatie.
Belangrijk
Nadat power BI Desktop het model naar de service heeft gepubliceerd, kunt u dat PBIX-bestand niet meer downloaden.
Vernieuwen
Nadat u naar de service hebt gepubliceerd, voert u een eerste vernieuwingsbewerking uit op het model. Deze vernieuwing moet een afzonderlijke (handmatige) vernieuwing zijn, zodat u de voortgang kunt controleren. Het kan even duren voordat de eerste vernieuwingsbewerking is voltooid. Partities moeten worden gemaakt, historische gegevens geladen, objecten zoals relaties en hiërarchieën die zijn gebouwd of opnieuw worden opgebouwd en berekende objecten opnieuw worden berekend.
Volgende vernieuwingsbewerkingen, afzonderlijk of gepland, zijn veel sneller omdat alleen de incrementele vernieuwingspartities worden vernieuwd. Andere verwerkingsbewerkingen moeten nog steeds plaatsvinden, zoals het samenvoegen van partities en herberekening, maar het duurt meestal veel minder tijd dan de eerste vernieuwing.
Automatisch rapport vernieuwen
Voor rapporten die een model gebruiken met een beleid voor incrementeel vernieuwen om de meest recente gegevens in realtime op te halen met DirectQuery, is het een goed idee om automatische paginavernieuwing met een vast interval in te schakelen of op basis van wijzigingsdetectie, zodat de rapporten de meest recente gegevens zonder vertraging bevatten. Zie Pagina automatisch vernieuwen in Power BI voor meer informatie.
Geavanceerd incrementeel vernieuwen
Als uw model zich in een Premium-capaciteit bevindt waarvoor een XMLA-eindpunt is ingeschakeld, kan incrementeel vernieuwen verder worden uitgebreid voor geavanceerde scenario's. U kunt bijvoorbeeld SQL Server Management Studio gebruiken om partities weer te geven en te beheren, de eerste vernieuwingsbewerking te bootstrapen of backdated historische partities te vernieuwen. Zie Geavanceerde incrementele vernieuwing met het XMLA-eindpunt voor meer informatie.
Community
Power BI heeft een levendige community waar MVP's, BI-professionals en peers expertise delen in discussiegroepen, video's, blogs en meer. Als u meer wilt weten over incrementeel vernieuwen, raadpleegt u deze resources:
- Power BI-community
- Zoeken in 'Incrementeel vernieuwen van Power BI' in Bing
- Zoeken in 'Incrementeel vernieuwen voor bestanden' in Bing
- Zoeken in 'Bestaande gegevens behouden met incrementeel vernieuwen' in Bing
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor