Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: ![]() Power BI Desktop-Power BI-service
Power BI Desktop-Power BI-service ![]()
Met de uitgevouwen structuurvisual in Power BI kunt u gegevens in meerdere dimensies visualiseren. Hiermee worden automatisch gegevens samengevoegd en kunt u in elke willekeurige volgorde inzoomen op uw dimensies. Het is ook een AI-visualisatie (kunstmatige intelligentie), zodat u deze kunt vragen om de volgende dimensie te vinden om in te zoomen op basis van bepaalde criteria. Dit hulpprogramma is waardevol voor ad-hocverkenning en het uitvoeren van hoofdoorzaakanalyses.
In deze zelfstudie worden twee voorbeelden gebruikt:
- Een supply chain-scenario dat het percentage producten analyseert dat een bedrijf heeft op backorder (niet op voorraad).
- Een verkoopscenario dat de verkoop van videogames opsplitst door talloze factoren, zoals gamegenre en uitgever.
Voor Power BI Desktop kunt u het semantische model van het toeleveringsketenscenario downloaden. Als u de Power BI-service wilt gebruiken, downloadt u Supply Chain Sample.pbix en uploadt u deze naar een werkruimte in de Power BI-service.
Notitie
Als u uw rapport deelt met een Power BI-collega, moet u beide afzonderlijke Power BI Pro-licenties hebben of dat het rapport is opgeslagen in Premium-capaciteit.
Aan de slag
Selecteer het pictogram van de uitgevouwen structuur in het deelvenster Visualisaties.
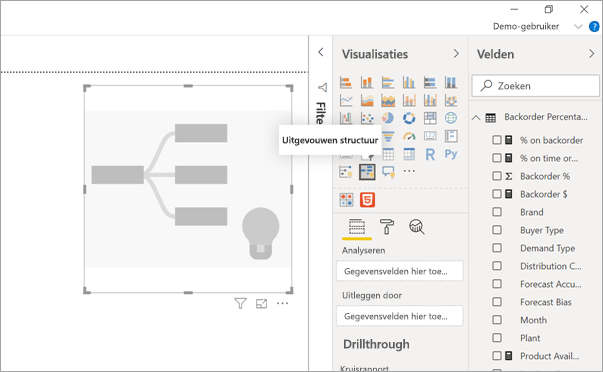
Voor de visualisatie zijn twee typen invoer vereist:
- Analyseren : de metrische gegevens die u wilt analyseren. Dit moet een meting of een aggregaties zijn.
- Uitleg door : een of meer dimensies waarop u wilt inzoomen.
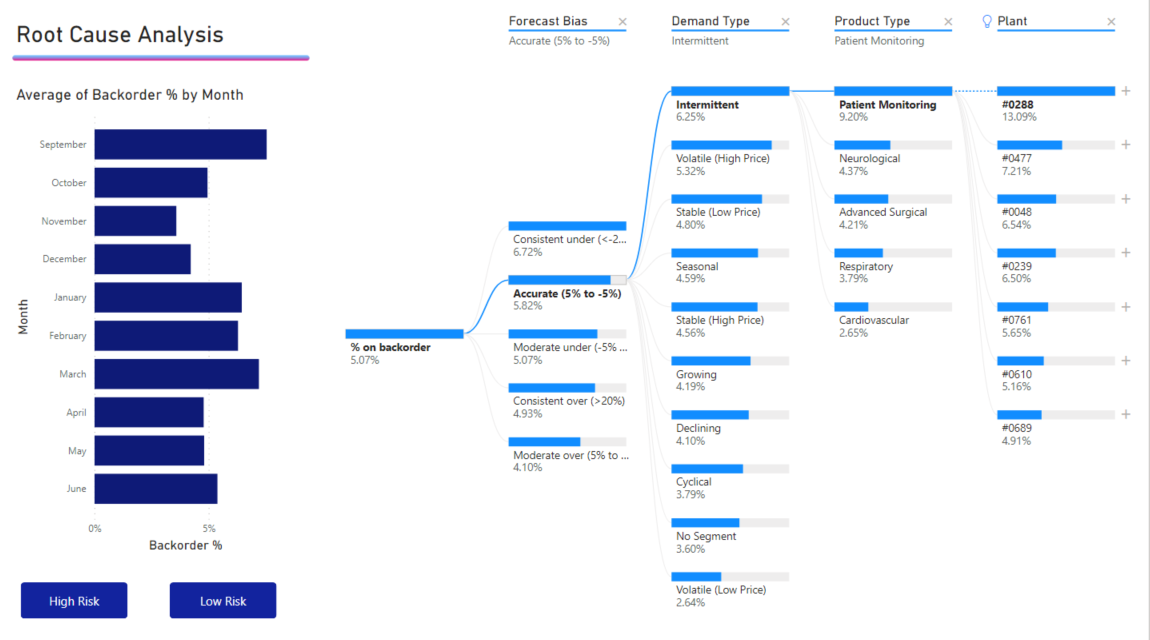
Zodra u de meting naar de veldbron sleept, wordt de visual bijgewerkt om de geaggregeerde meting weer te geven. In het onderstaande voorbeeld visualiseren we het gemiddelde percentage producten in de achterorder (5,07%).

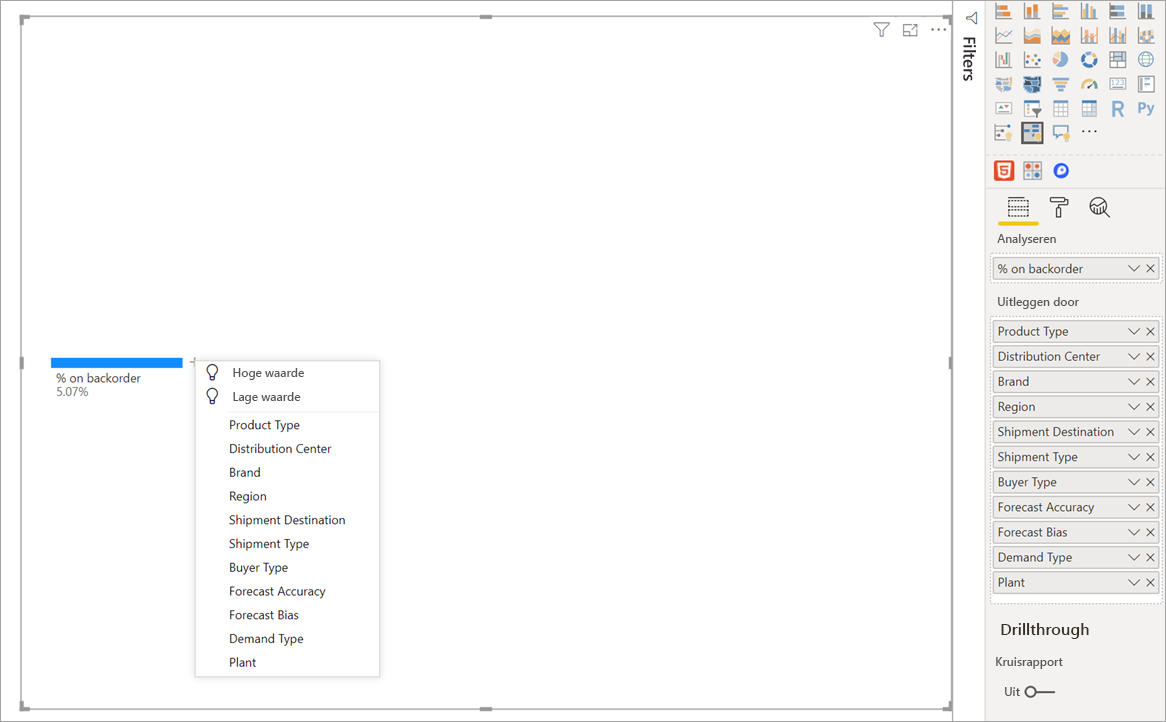
De volgende stap bestaat uit het invoeren van een of meer dimensies waarin u wilt inzoomen. Voeg deze velden toe aan de bucket Uitleg per . U ziet dat er een plusteken naast het hoofdknooppunt wordt weergegeven. Als u het plusteken selecteert, kunt u kiezen in welk veld u wilt inzoomen (u kunt inzoomen op velden in elke gewenste volgorde).
Als u prognose-bias selecteert, wordt de structuur uitgevouwen en opgesplitst door de waarden in de kolom. Dit proces kan worden herhaald door een ander knooppunt te kiezen om in te zoomen.
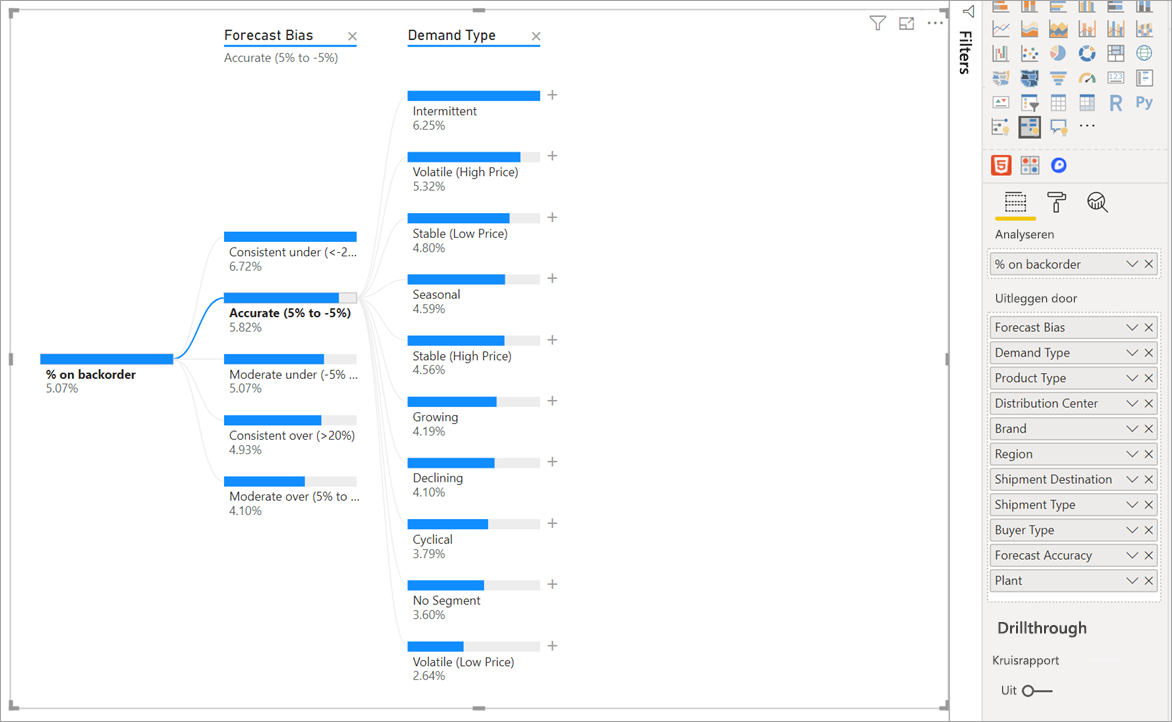
Als u een knooppunt op het laatste niveau selecteert, worden de gegevens kruislings gefilterd. Als u een knooppunt op een eerder niveau selecteert, wordt het pad gewijzigd.
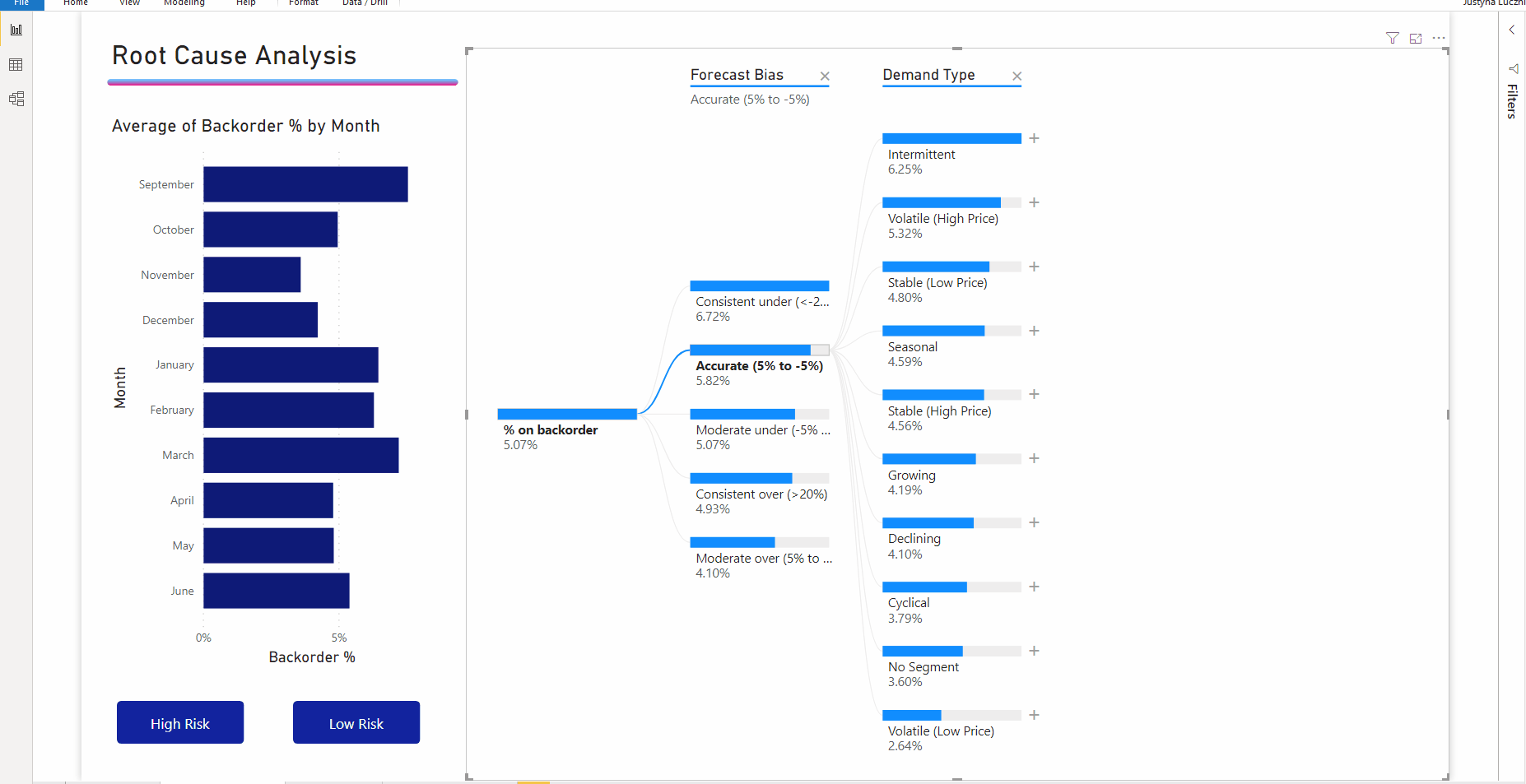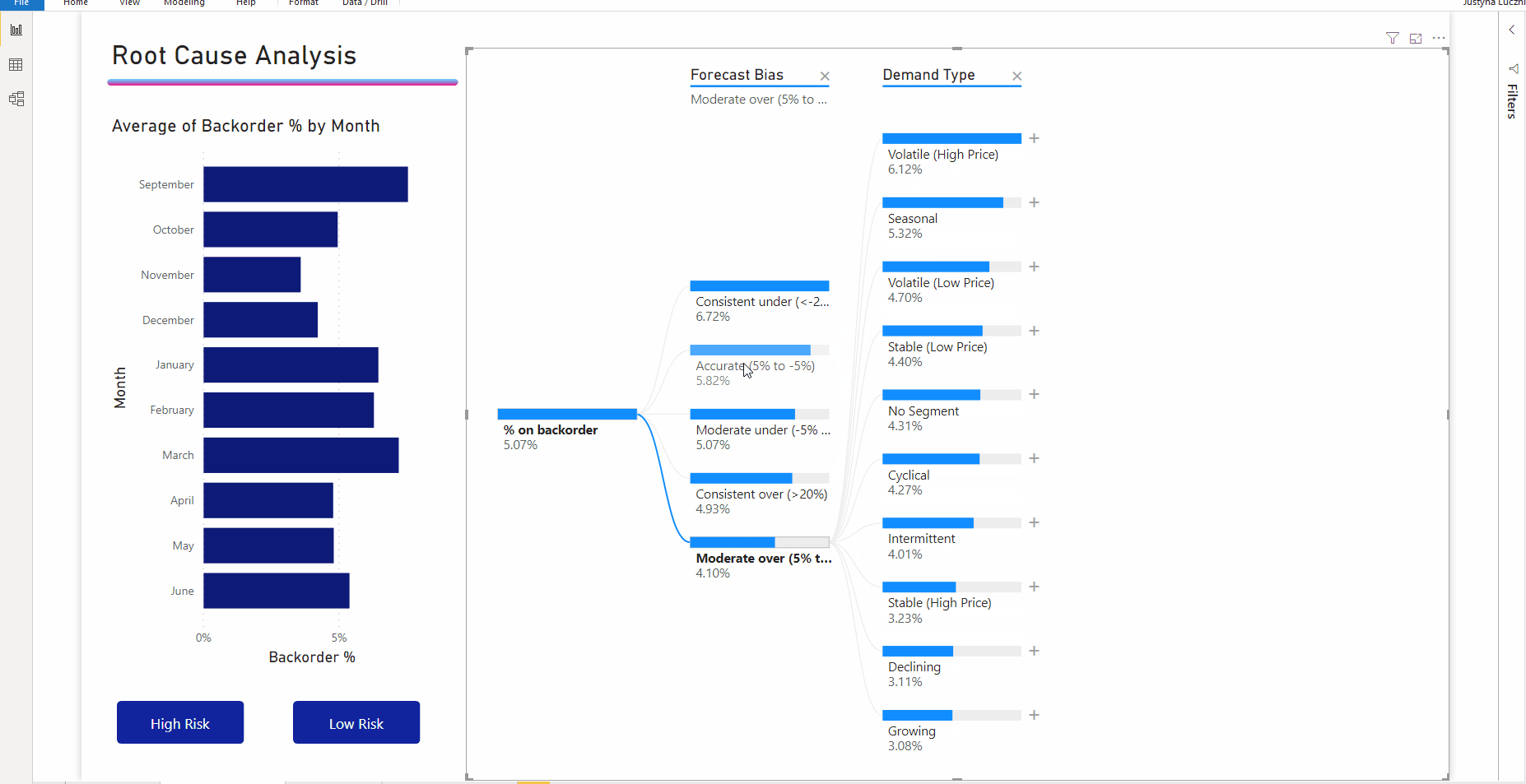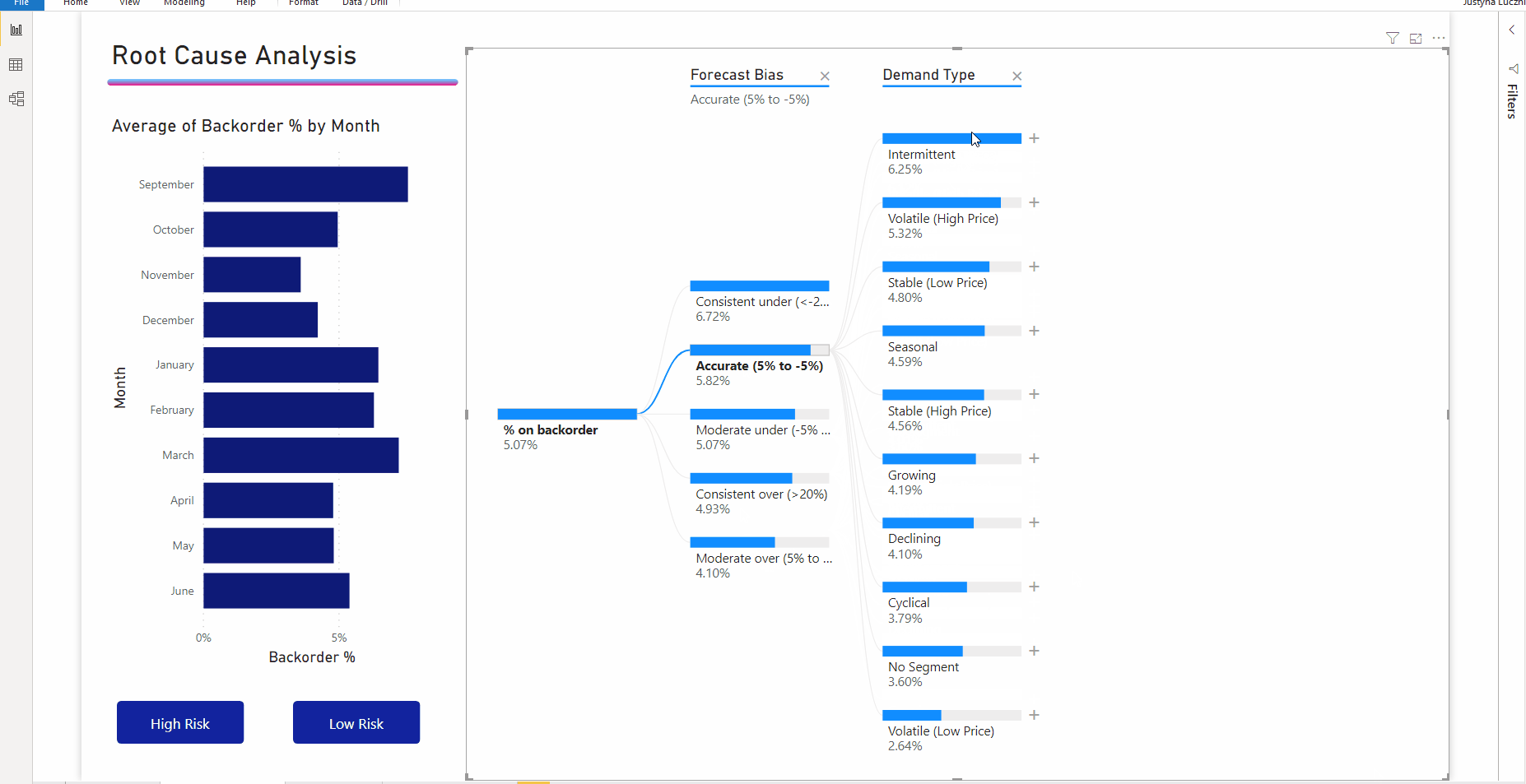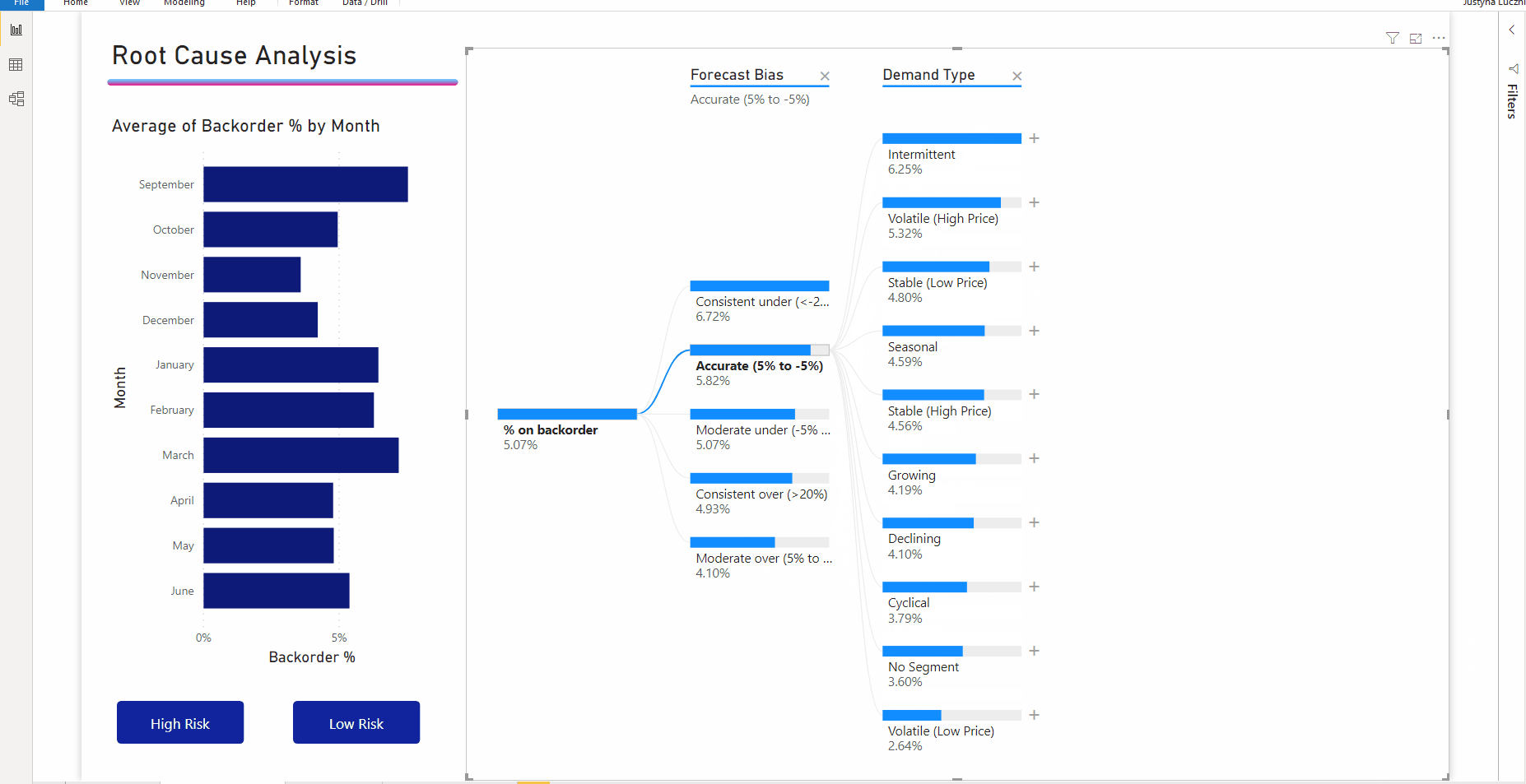
Interactie met andere visuals filtert de uitgevouwen structuur kruislings. De volgorde van de knooppunten binnen niveaus kan hierdoor veranderen.
Als u een ander scenario wilt weergeven, bekijkt het onderstaande voorbeeld de verkoop van videogames per uitgever.
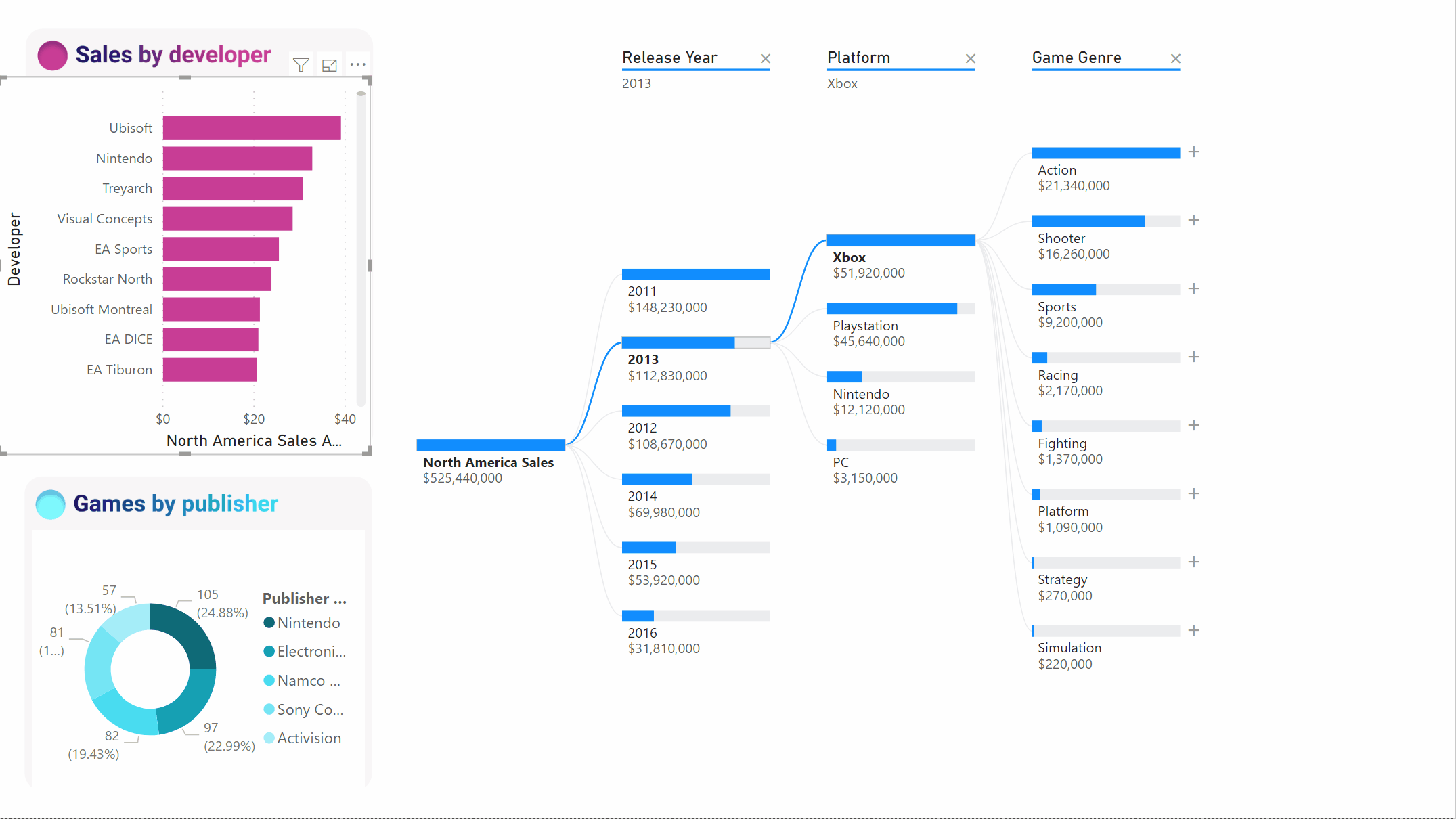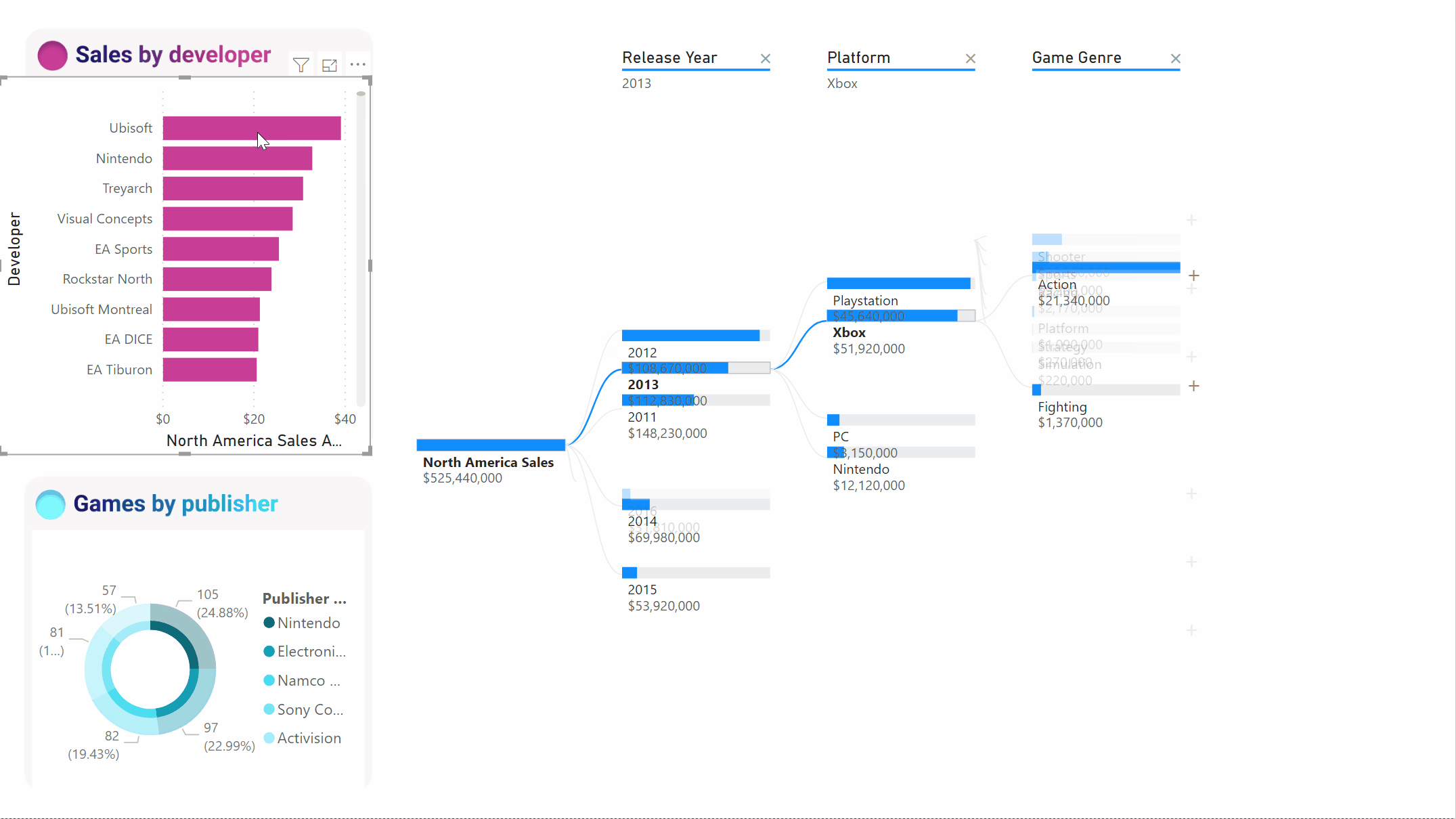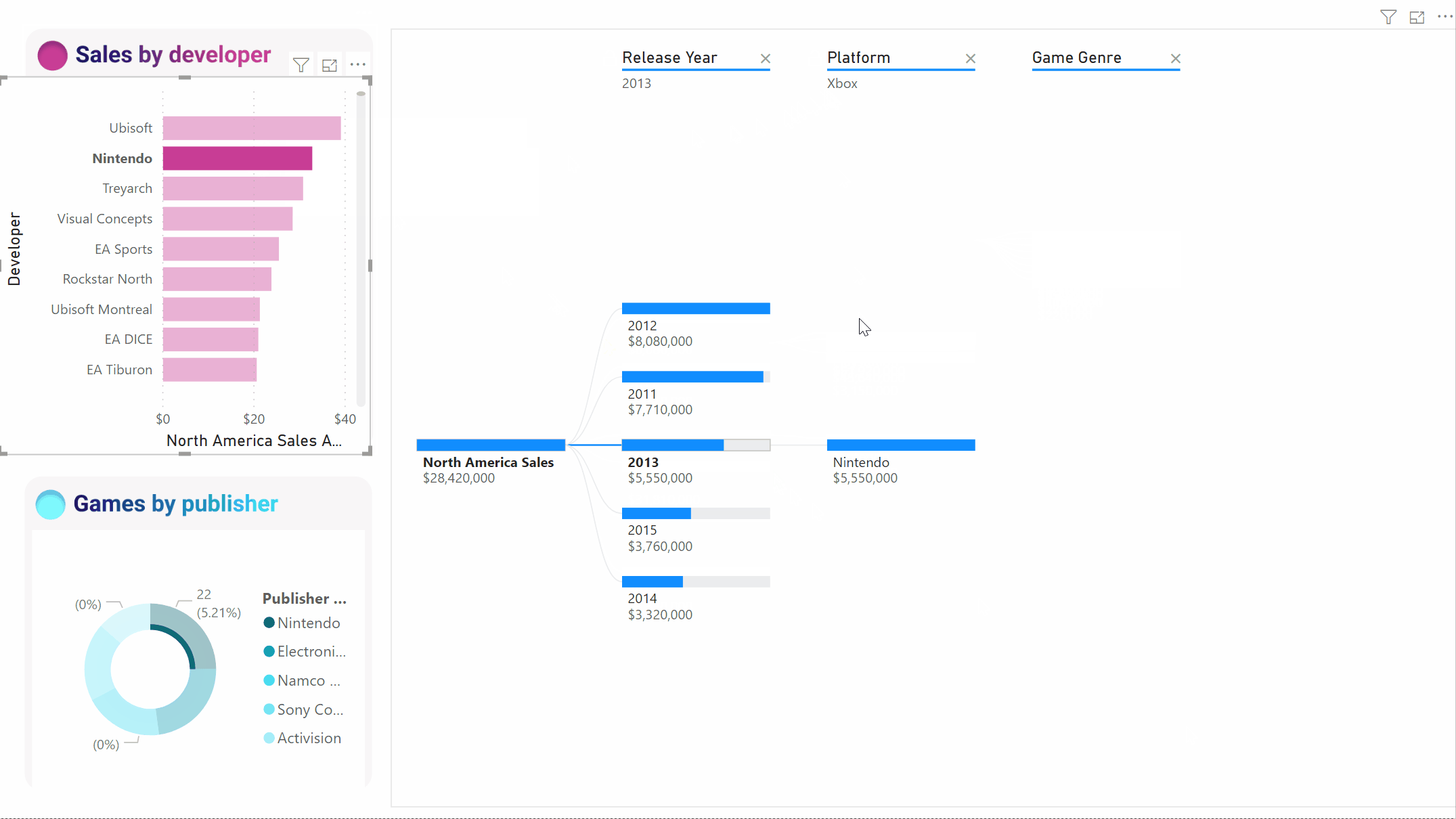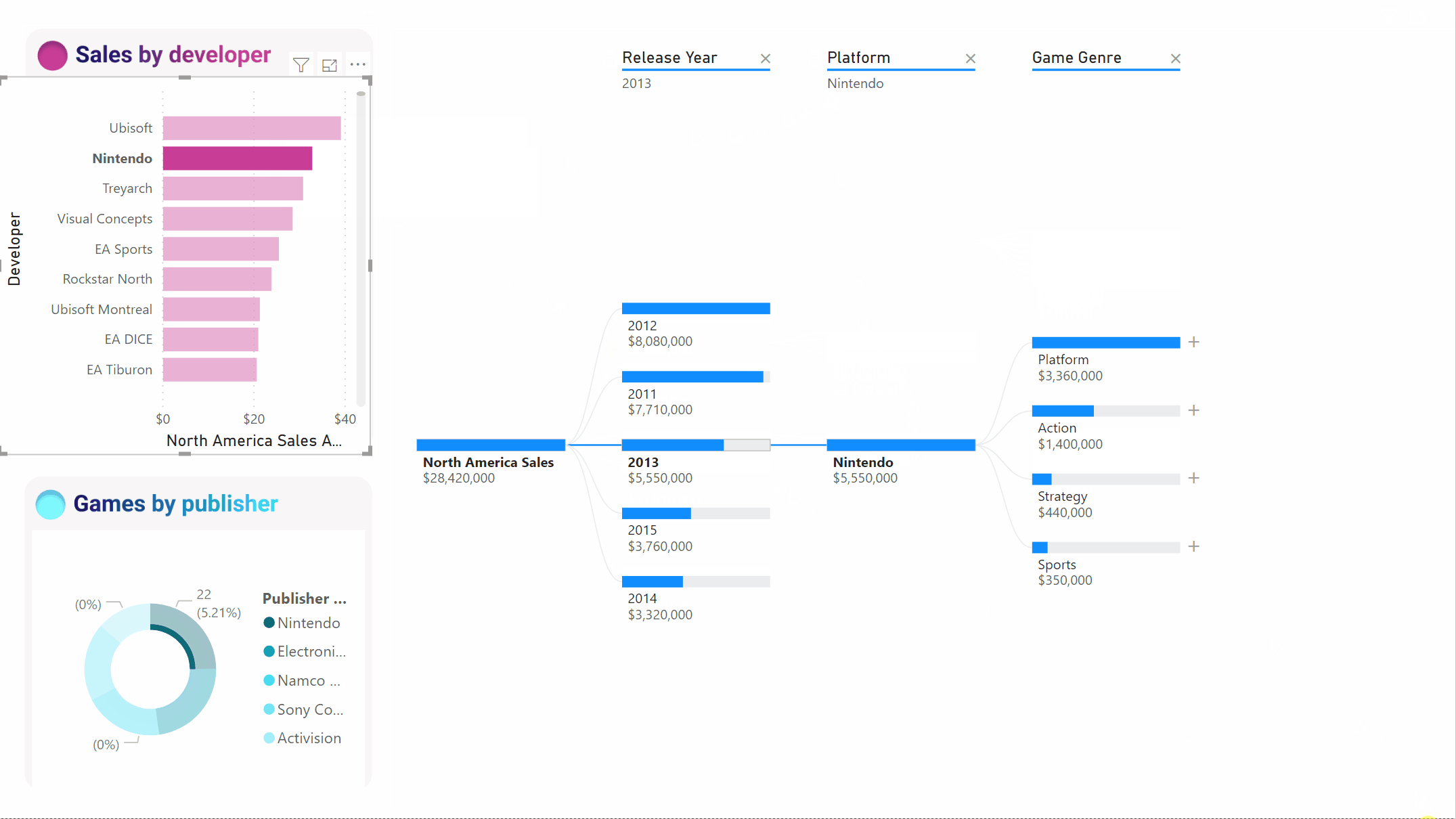
Wanneer we de boom kruislings filteren door Ubisoft, wordt het pad bijgewerkt om de Xbox-verkoop te laten zien van de eerste naar de tweede plaats, overschreden door PlayStation.
Als we de boom vervolgens kruislings filteren door Nintendo, zijn de Xbox-verkopen leeg omdat er geen Nintendo-games zijn ontwikkeld voor Xbox. Xbox wordt samen met het volgende pad uit de weergave gefilterd.
Ondanks dat het pad verdwijnt, blijven de bestaande levels (in dit geval Game Genre) vastgemaakt aan de boom. Als u het Nintendo-knooppunt selecteert, wordt de structuur daarom automatisch uitgebreid naar Game Genre.
AI-splitsingen
U kunt AI-splitsingen gebruiken om te bepalen waar u hierna in de gegevens moet zoeken. Deze splitsingen worden boven aan de lijst weergegeven en zijn gemarkeerd met een gloeilamp. De splitsingen zijn er om u te helpen bij het vinden van hoge en lage waarden in de gegevens, automatisch.
De analyse kan op twee manieren werken, afhankelijk van uw voorkeuren. Als u het voorbeeld van de toeleveringsketen opnieuw gebruikt, is het standaardgedrag als volgt:
- Hoge waarde: kijkt naar alle beschikbare velden en bepaalt op welke wordt ingezoomd, om de hoogste waarde te krijgen voor de meting die wordt geanalyseerd.
- Lage waarde: kijkt naar alle beschikbare velden en bepaalt op welke wordt ingezoomd, om de laagste waarde te krijgen voor de meting die wordt geanalyseerd.
Selecteer Hoge waarde met behulp van het plusteken naast Onregelmatig. Er wordt een nieuwe kolom met de markering Producttype weergegeven.
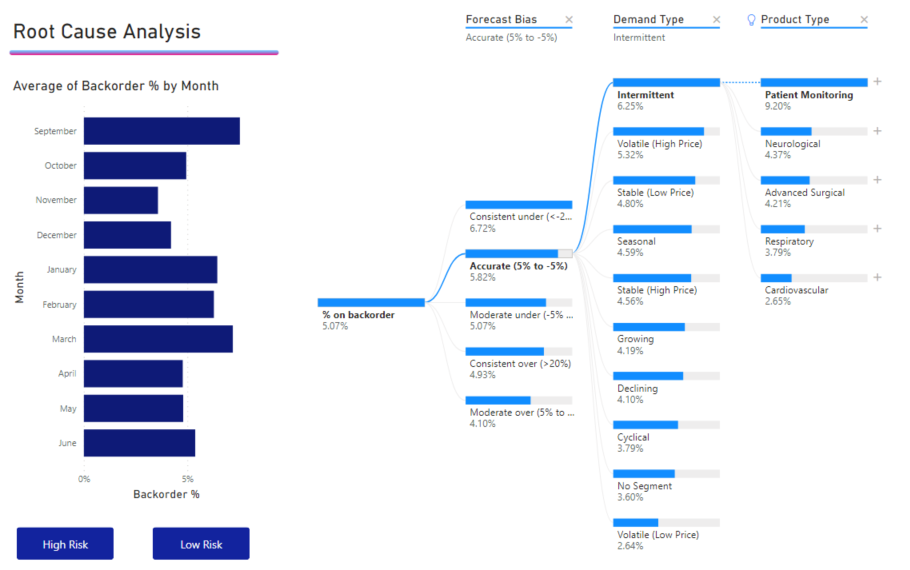
Er verschijnt een gloeilamp naast Producttype die aangeeft dat deze kolom een AI-splitsing is. De structuur biedt ook een stippellijn die het knooppunt Patiëntbewaking aanbeveelt, wat de hoogste waarde van de achterorders aangeeft (9,2%).
Beweeg de muisaanwijzer over de gloeilamp om knopinfo weer te geven. In dit voorbeeld is de knopinfo %on backorder is highest when Product Type is Patient Monitoring.
U kunt de visual configureren om relatieve AI-splitsingen te vinden in plaats van Absolute.
De relatieve modus zoekt naar hoge waarden die opvallen (vergeleken met de rest van de gegevens in de kolom). Laten we eens kijken naar de verkoop van videogames als voorbeeld:
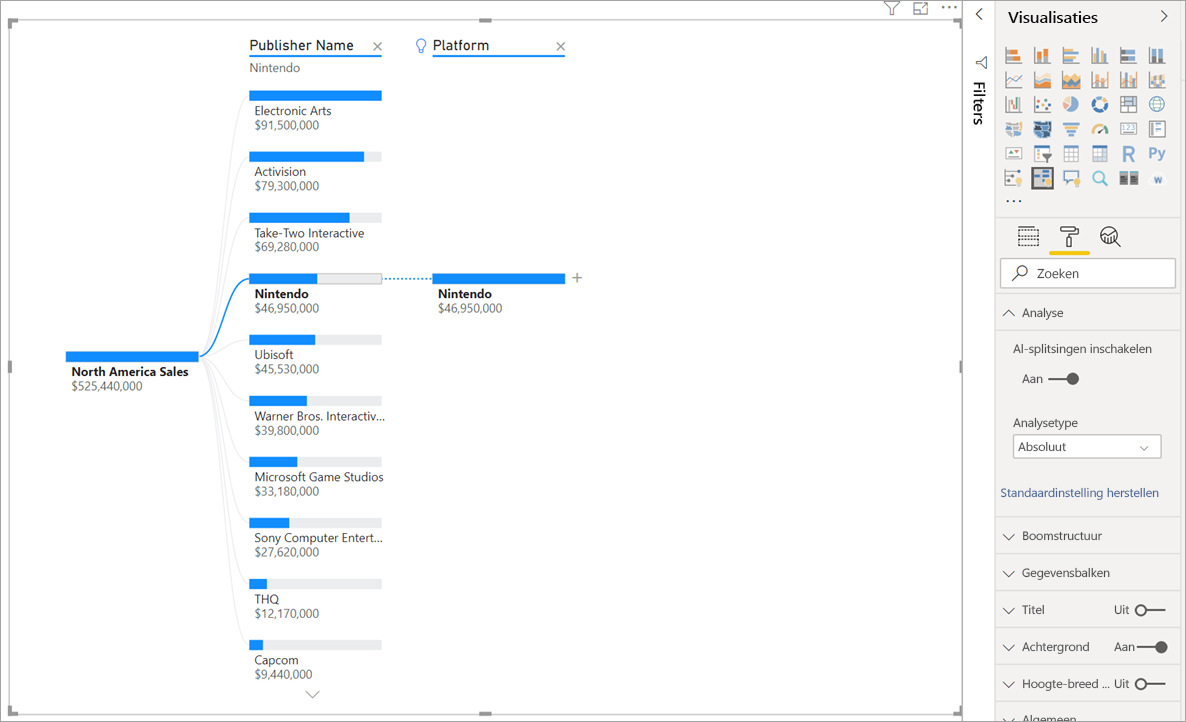
In de bovenstaande schermopname kijken we naar Noord-Amerika verkoop van videogames. We splitsen eerst de structuur op door Publisher Name en zoomen vervolgens in op Nintendo. Het selecteren van high value resultaten in de uitbreiding van Platform is Nintendo. Omdat Nintendo (de uitgever) zich alleen ontwikkelt voor Nintendo-consoles, is er slechts één waarde aanwezig en dus is dat niet zeker de hoogste waarde.
Een interessantere splitsing zou echter zijn om te kijken naar welke hoge waarde opvalt ten opzichte van andere waarden in dezelfde kolom. Als we het analysetype wijzigen van Absoluut in Relatief, krijgen we het volgende resultaat voor Nintendo:
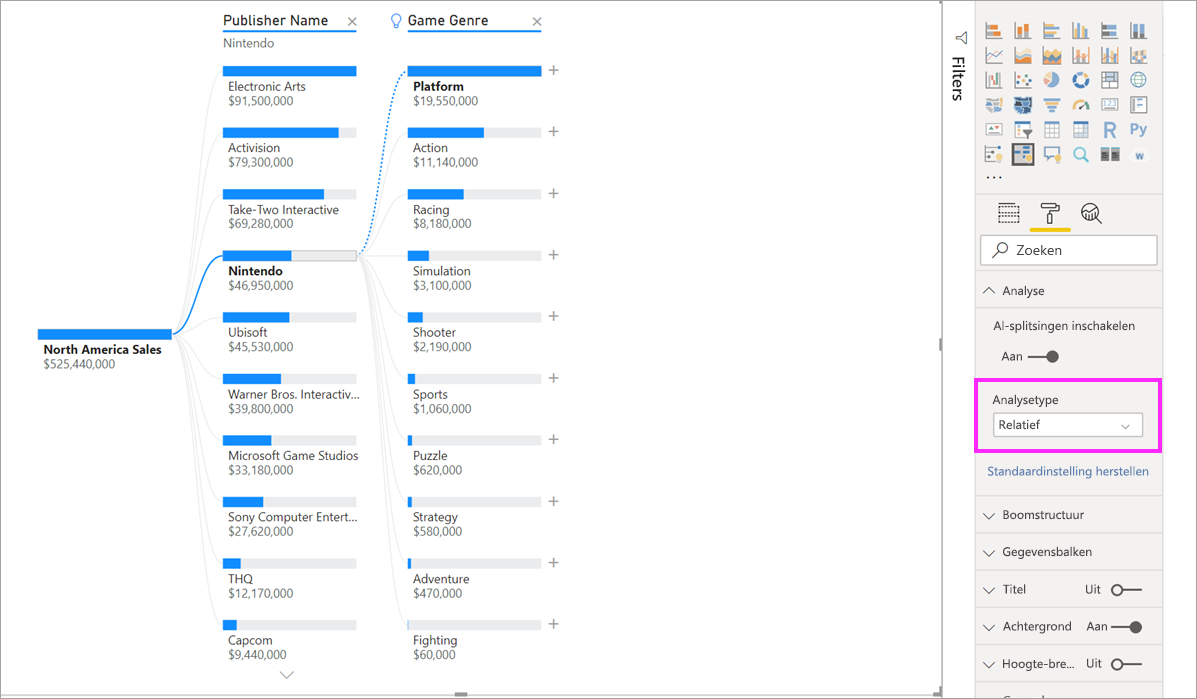
Deze keer is de aanbevolen waarde Platform binnen Game Genre. Platform levert geen hogere absolute waarde op dan Nintendo ($ 19.950.000 versus $ 46.950.000). Toch is het een waarde die opvalt.
Meer precies, omdat er 10 Game Genre-waarden zijn, zou de verwachte waarde voor Platform $ 4,6M zijn als ze gelijkmatig zouden worden gesplitst. Omdat Platform een waarde van bijna $ 20M heeft, is dat een interessant resultaat omdat het vier keer hoger is dan het verwachte resultaat.
De berekening is als volgt:
Noord-Amerika Verkoop voor Platform/Abs(Avg(Noord-Amerika Sales for Game Genre))
vs.
Noord-Amerika verkoop voor Nintendo /Abs(Avg(Noord-Amerika Sales for Platform))
Dit vertaalt zich in:
19.550.000 / (19.550.000 + 11.140.000 + ... + 470.000 + 60.000 /10) = 4,25x
vs.
46.950.000/ (46.950.000/1) = 1x
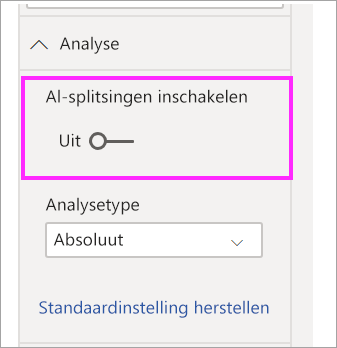
Als u liever geen AI-splitsingen in de structuur gebruikt, hebt u ook de mogelijkheid om ze uit te schakelen onder de opmaakopties analyse:
Structuurinteracties met AI-splitsingen
U kunt meerdere volgende AI-niveaus hebben. U kunt ook verschillende soorten AI-niveaus combineren (van hoge waarde tot lage waarde en terug naar hoge waarde):
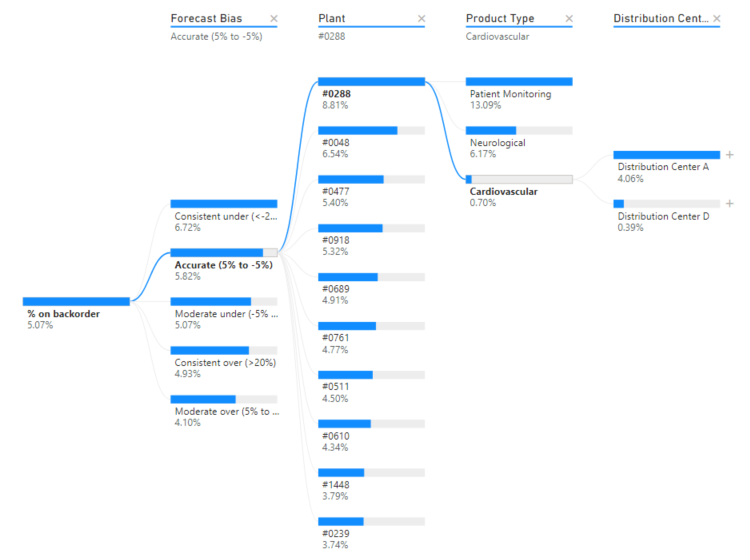
Als u een ander knooppunt in de structuur selecteert, worden de AI-splitsingen opnieuw berekend. In het onderstaande voorbeeld hebben we het geselecteerde knooppunt in het niveau Prognose-bias gewijzigd. De volgende niveaus veranderen om de juiste hoge en lage waarden te verkrijgen.
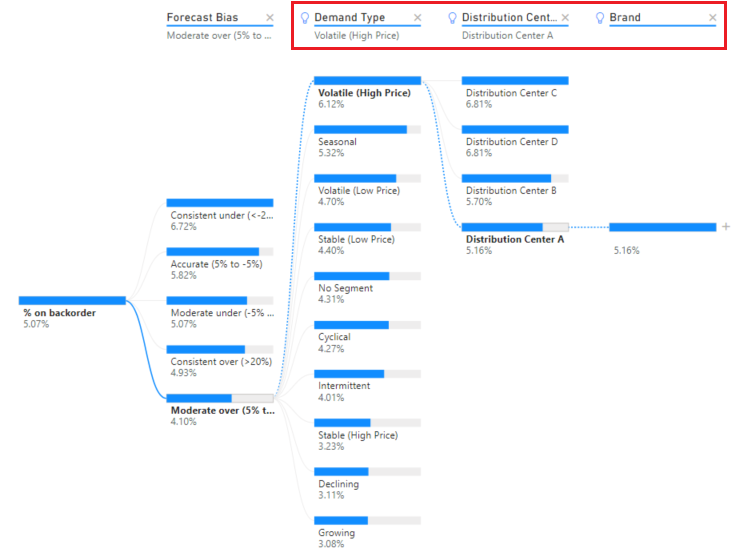
AI-niveaus worden ook opnieuw berekend wanneer u de uitgevouwen structuur kruislings filtert op een andere visual. In het onderstaande voorbeeld zien we dat onze terugorderpercentage het hoogst is voor Plant #0477.
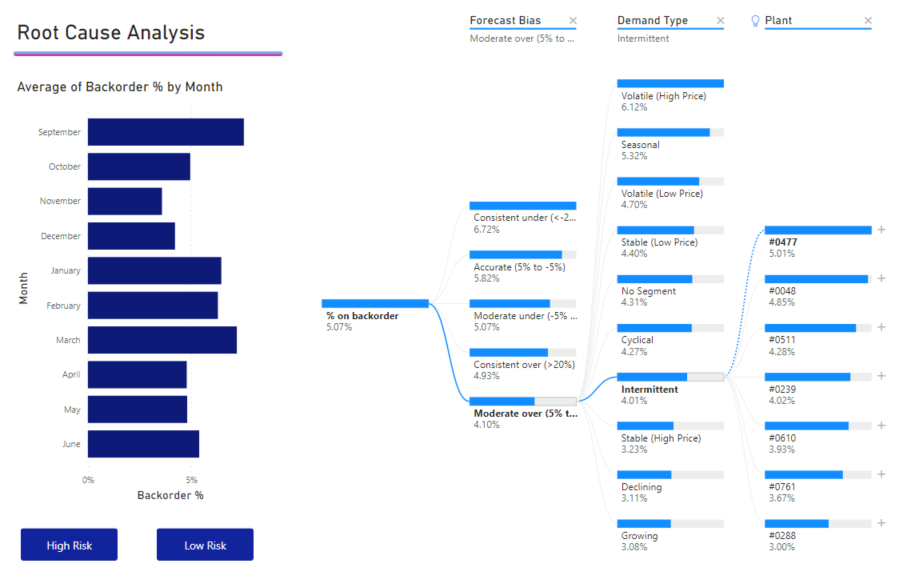
Maar als we april in het staafdiagram selecteren, zijn de hoogste wijzigingen in Producttype Geavanceerd chirurgisch. In dit geval zijn het niet alleen de knooppunten die opnieuw zijn gerangschikt, maar een andere kolom is gekozen.
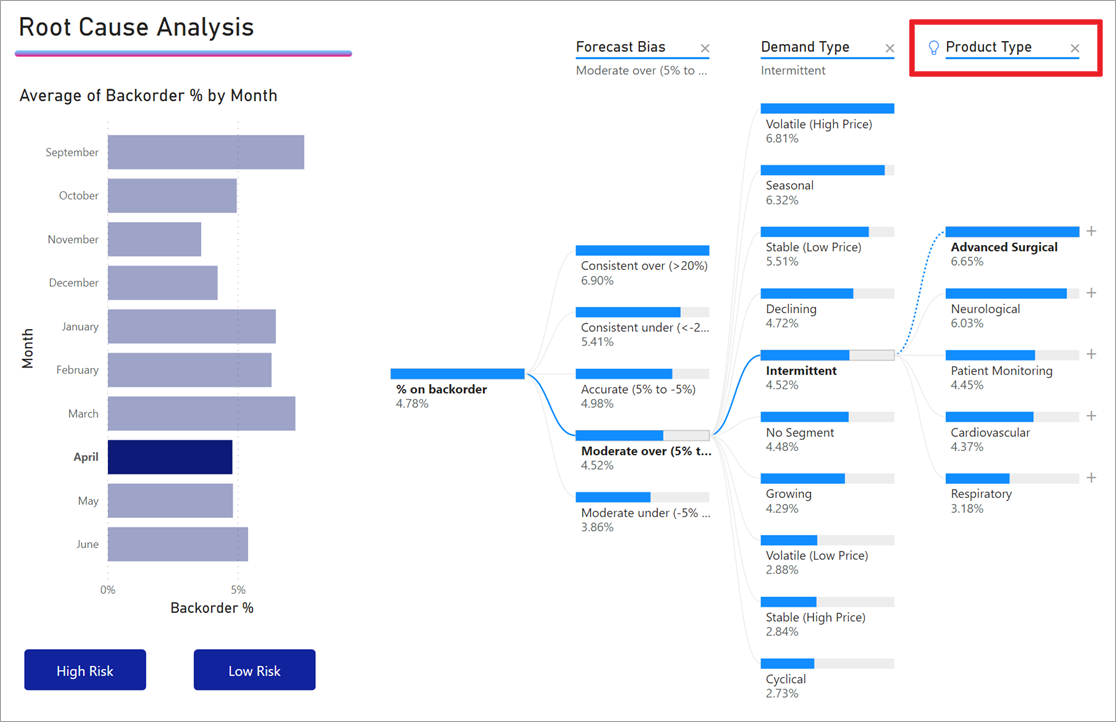
Als we willen dat AI-niveaus zich gedragen als niet-AI-niveaus, selecteert u de gloeilamp om het gedrag terug te zetten op de standaardinstelling.
Hoewel meerdere AI-niveaus aan elkaar kunnen worden gekoppeld, kan een niet-AI-niveau geen AI-niveau volgen. Als we een handmatige splitsing uitvoeren na een AI-splitsing, verdwijnt de gloeilamp van het AI-niveau en wordt het niveau omgezet in een normaal niveau.
Vergrendelen
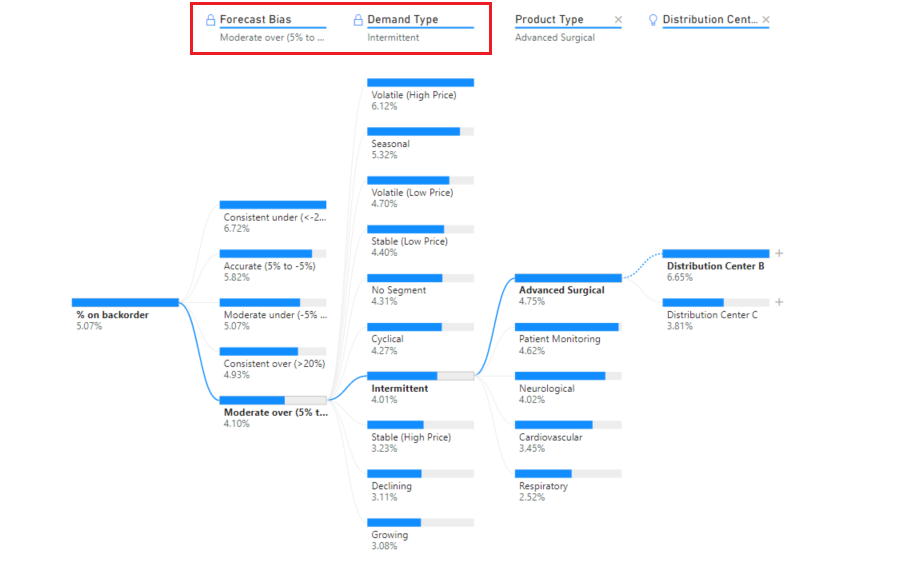
Een maker van inhoud kan niveaus vergrendelen voor rapportgebruikers. Wanneer een niveau is vergrendeld, kan het niet worden verwijderd of gewijzigd. Een consument kan verschillende paden binnen het vergrendelde niveau verkennen, maar het niveau zelf kan niet worden gewijzigd. Als maker kunt u de muisaanwijzer op bestaande niveaus bewegen om het vergrendelingspictogram te zien. U kunt zoveel niveaus vergrendelen als u wilt, maar u kunt geen ontgrendelde niveaus hebben die voorafgaan aan vergrendelde niveaus.
In het onderstaande voorbeeld zijn de eerste twee niveaus vergrendeld. Rapportgebruikers kunnen niveau 3 en 4 wijzigen en later zelfs nieuwe niveaus toevoegen. De eerste twee niveaus kunnen echter niet worden gewijzigd:
Overwegingen en beperkingen
Het maximum aantal niveaus voor de boomstructuur is 50. Het maximum aantal gegevenspunten dat tegelijk in de boomstructuur kan worden gevisualiseerd, is 5000. We kapen niveaus af om top n weer te geven. Momenteel is de hoogste n per niveau ingesteld op 10.
De uitgevouwen structuur wordt niet ondersteund in de volgende scenario's:
- On-premises Analysis Services
AI-splitsingen worden niet ondersteund in de volgende scenario's:
- Azure Analysis Services
- Power BI Report Server
- Publiceren op internet
- Complexe metingen en metingen van uitbreidingsschema's in Analyseren
Andere beperkingen:
- Ondersteuning binnen Q&A