Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Clusterwaarden maken automatisch groepen met vergelijkbare waarden met behulp van een fuzzy overeenkomend algoritme en wijzen vervolgens de waarde van elke kolom toe aan de best overeenkomende groep. Deze transformatie is handig wanneer u werkt met gegevens met veel verschillende variaties van dezelfde waarde en u waarden moet combineren in consistente groepen.
Overweeg een voorbeeldtabel met een id-kolom met een set id's en een kolom Persoon met een reeks verschillende gespelde en gekapitaliseerde versies van de namen Miguel, Mike, William en Bill.
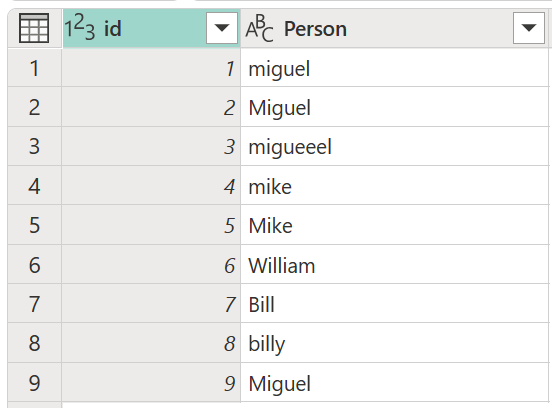
In dit voorbeeld is het resultaat dat u zoekt een tabel met een nieuwe kolom met de juiste groepen waarden uit de kolom Persoon en niet alle verschillende variaties van dezelfde woorden.
Opmerking
De functie Clusterwaarden is alleen beschikbaar voor Power Query Online.
Een clusterkolom maken
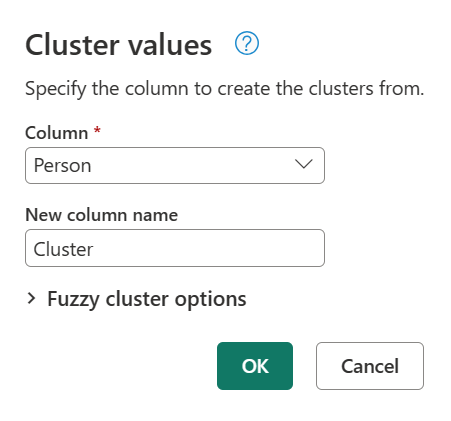
Als u waarden wilt clusteren, selecteert u eerst de kolom Persoon , gaat u naar het tabblad Kolom toevoegen op het lint en selecteert u vervolgens de optie Clusterwaarden .
![]()
Bevestig in het dialoogvenster Clusterwaarden de kolom waaruit u de clusters wilt maken en voer de nieuwe naam van de kolom in. Geef in dit geval de naam van dit nieuwe kolomcluster.
Het resultaat van die bewerking wordt weergegeven in de volgende afbeelding.
Opmerking
Voor elk cluster met waarden kiest Power Query het meest voorkomende exemplaar uit de geselecteerde kolom als het 'canonieke' exemplaar. Als er meerdere exemplaren met dezelfde frequentie optreden, kiest Power Query de eerste.
De fuzzy clusteropties gebruiken
De volgende opties zijn beschikbaar voor clusterwaarden in een nieuwe kolom:
- Vergelijkbaarheidsdrempel (optioneel): met deze optie wordt aangegeven hoe vergelijkbare twee waarden moeten worden gegroepeerd. De minimuminstelling nul (0) zorgt ervoor dat alle waarden worden gegroepeerd. Met de maximuminstelling van 1 kunnen alleen waarden worden gegroepeerd die exact overeenkomen. De standaardwaarde is 0.8.
- Houd geen rekening met hoofdletters: wanneer teksttekenreeksen worden vergeleken, wordt geen rekening gehouden met hoofdletters. Deze optie is standaard ingeschakeld.
- Groeperen door tekstonderdelen te combineren: het algoritme probeert tekstonderdelen (zoals micro en zacht in Microsoft) te combineren om waarden te groeperen.
- Overeenkomstenscores weergeven: Geeft overeenkomstenscores weer tussen de invoerwaarden en berekende representatieve waarden na fuzzy clustering.
- Transformatietabel (optioneel): u kunt een transformatietabel selecteren waarmee waarden (zoals MSFT aan Microsoft) worden toegewezen om ze te groeperen.
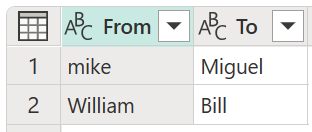
In dit voorbeeld wordt een nieuwe transformatietabel met de naam Mijn transformatietabel gebruikt om te laten zien hoe waarden kunnen worden toegewezen. Deze transformatietabel heeft twee kolommen:
- Van: De tekenreeks waarnaar u in de tabel wilt zoeken.
- To: De tekenreeks die moet worden gebruikt om de tekenreeks in de kolom Van te vervangen.
Belangrijk
Het is belangrijk dat de transformatietabel dezelfde kolommen en kolomnamen heeft als in de vorige afbeelding (ze moeten de naam 'Van' en 'Aan' hebben), anders herkent Power Query deze tabel niet als een transformatietabel en vindt er geen transformatie plaats.
Dubbelklik met behulp van de eerder gemaakte query op de stap Geclusterde waarden en vouw vervolgens in het dialoogvenster Clusterwaardenfuzzy clusteropties uit. Schakel onder Opties voor fuzzy cluster de optie Overeenkomstenscores weergeven in. Selecteer bij Transformatietabel (optioneel) de query met de transformatietabel.
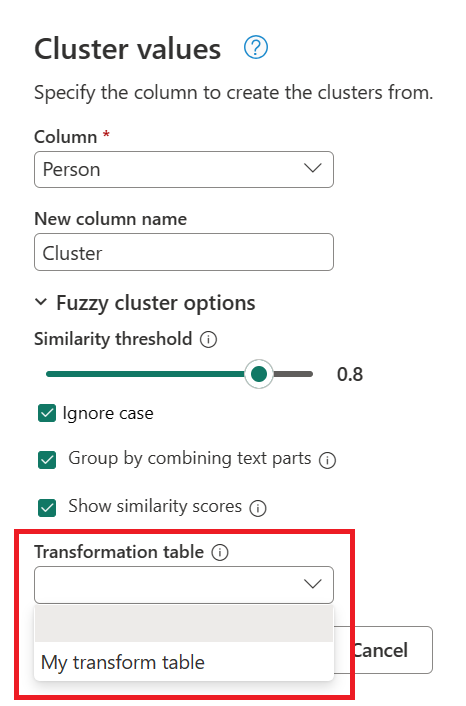
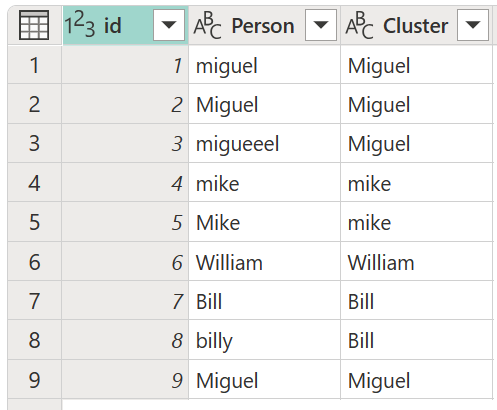
Nadat u de transformatietabel hebt geselecteerd en de optie Overeenkomstenscores weergeven hebt ingeschakeld, selecteert u OK. Het resultaat van deze bewerking geeft u een tabel met dezelfde id en persoonkolommen als de oorspronkelijke tabel, maar bevat ook twee nieuwe kolommen met de naam Cluster en Person_Cluster_Similarity. De kolom Cluster bevat de correct gespelde en gekapitaliseerde versies van de namen Miguel voor versies van Miguel en Mike, en William voor versies van Bill, Billy en William. De kolom Person_Cluster_Similarity bevat de overeenkomstenscores voor elk van de namen.

Principes voor transformatietabellen
U ziet misschien dat de transformatietabel in de vorige sectie lijkt aan te geven dat exemplaren van Mike zijn gewijzigd in Miguel en exemplaren van William worden gewijzigd in Bill. In de resulterende tabel werden de voorvallen van Bill en "billy" gewijzigd in William. In de transformatietabel, in plaats van een direct vannaar pad te zijn, is de transformatietabel symmetrisch tijdens het clusteren, wat betekent dat 'mike' gelijk is aan Miguel en vice versa. Het resultaat van de equivalenten in de transformatietabel is afhankelijk van de volgende regels:
- Als er een meerderheid van identieke waarden is, hebben deze waarden voorrang op niet-identische waarden.
- Als er geen meerderheid van de waarden is, heeft de waarde die als eerste wordt weergegeven voorrang.
In de oorspronkelijke tabel die in dit artikel wordt gebruikt, vormen versies van de naam Miguel (zowel "miguel" als "Miguel") in de kolom Person de meerderheid van de gevallen van de namen Miguel en Mike. Daarnaast is de naam Miguel met initiële hoofdletters het grootste deel van de naam Miguel. Dus het koppelen van Miguel en zijn derivaten en Mike en de derivaten in de transformatietabel resulteert in de naam Miguel die in de kolom Cluster wordt gebruikt.
Voor de namen William, Bill en Billy is er echter geen meerderheid van de waarden omdat alle drie uniek zijn. Sinds William eerst verschijnt, wordt William gebruikt in de kolom Cluster . Als 'billy' eerst in de tabel werd weergegeven, zou 'billy' worden gebruikt in de kolom Cluster . Aangezien er geen meerderheid van de waarden is, wordt de schrijfwijze van de afzonderlijke namen toegepast. Als William het eerst is, wordt William met een hoofdletter "W" gebruikt als resultaatwaarde; als 'billy' eerst is, wordt 'billy' met een kleine letter 'b' gebruikt.