Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-database in Microsoft Fabric
SQL-database in Microsoft Fabric
In dit artikel wordt beschreven hoe u gegevens plot met behulp van het Python-pakket pandas.hist(). Een SQL Server-database is de bron die wordt gebruikt om de histogramgegevensintervallen met opeenvolgende, niet-overlappende waarden te visualiseren.
Prerequisites
SQL Server Management Studio voor het herstellen van de voorbeelddatabase naar Azure SQL Managed Instance.
Azure Data Studio. Zie Azure Data Studio om te installeren.
Herstel de DW-voorbeelddatabase om voorbeeldgegevens op te halen die in dit artikel worden gebruikt.
Herstelde database controleren
U kunt controleren of de herstelde database bestaat door een query uit te voeren op de Person.CountryRegion tabel:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Python-pakketten installeren
Download en installeer Azure Data Studio.
Installeer de volgende Python-pakketten:
pyodbcpandassqlalchemymatplotlib
Ga als volgt te werk om deze pakketten te installeren:
- Selecteer Pakketten beheren in uw Azure Data Studio-notebook.
- Selecteer in het deelvenster Pakketten beheren het tabblad Nieuwe toevoegen .
- Voer voor elk van de volgende pakketten de pakketnaam in, selecteer Zoeken en selecteer Vervolgens Installeren.
Histogram tekenen
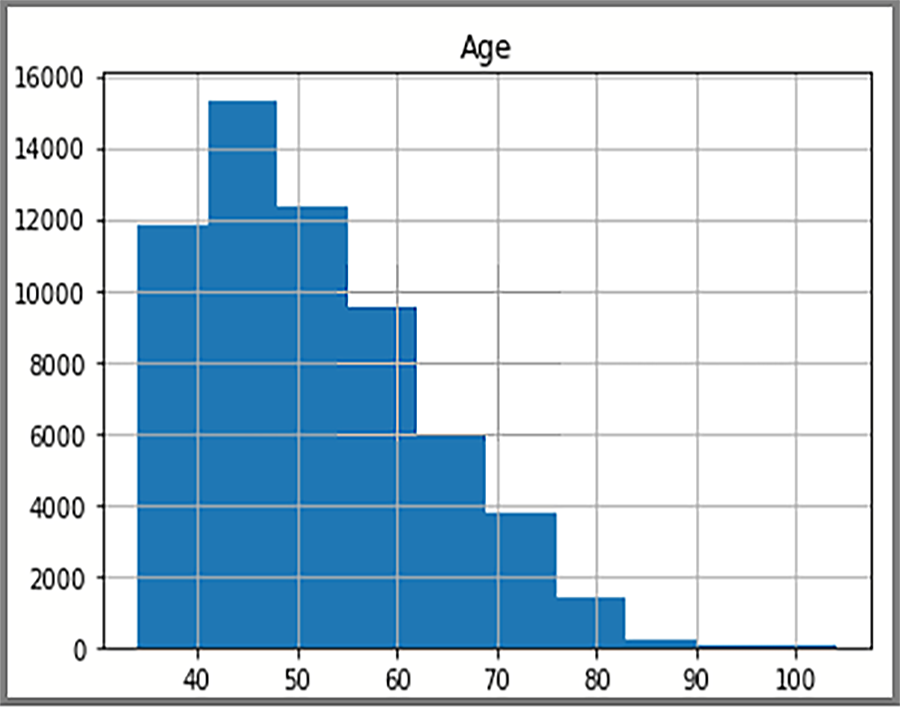
De gedistribueerde gegevens die in het histogram worden weergegeven, zijn gebaseerd op een SQL-query van AdventureWorksDW2025. Het histogram visualiseert gegevens en de frequentie van gegevenswaarden.
Bewerk de verbindingsreeksvariabelen: server, database, usernameen password maak verbinding met de SQL Server-database.
Ga als volgt te werk om een nieuw notitieblok te maken:
Selecteer Bestand in Azure Data Studio en selecteer Nieuw notitieblok.
Selecteer in het notebook de kernel Python3 en klik op +code.
Plak code in de notebook. Selecteer Alles uitvoeren.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
De weergave toont de leeftijdsverdeling van klanten in de FactInternetSales tabel.