Een gegevensintegratie- en analyseoplossing ontwerpen met Azure Synapse Analytics
Azure Synapse Analytics combineert functies van big data-analyses, opslag van zakelijke gegevens en gegevensintegratie. Met de service kunt u query's uitvoeren op serverloze gegevens of gegevens op schaal. Azure Synapse biedt ondersteuning voor gegevensopname, verkenning, transformatie en beheer en biedt ondersteuning voor analyse voor al uw BI- en machine learning-behoeften.
Dingen die u moet weten over Azure Synapse Analytics
Azure Synapse Analytics implementeert een MPP-architectuur (Massively Parallel Processing) en heeft de volgende kenmerken.
De Architectuur van Azure Synapse Analytics bevat een besturingsknooppunt en een pool rekenknooppunten.
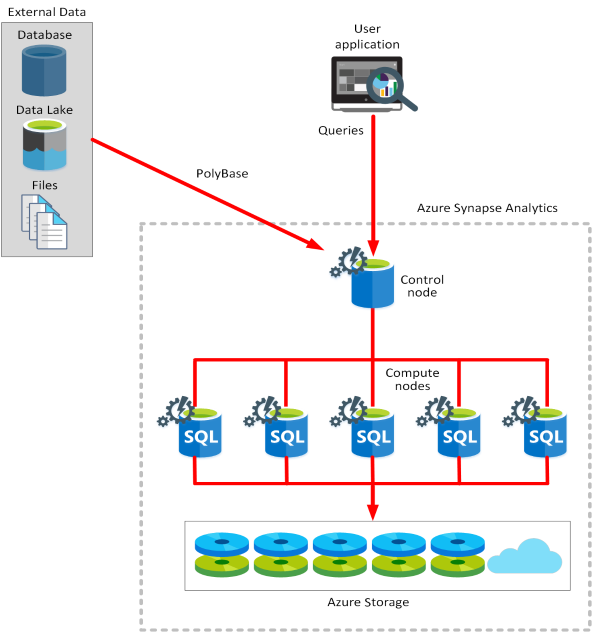
Het besturingsknooppunt is de hersenen van de architectuur. Het is de front-end die met alle toepassingen communiceert. De rekenknooppunten leveren de rekenkracht. De gegevens die moeten worden verwerkt, worden gelijkmatig verdeeld over de knooppunten.
U verzendt query's in de vorm van Transact-SQL-instructies die door Azure Synapse Analytics worden uitgevoerd.
Azure Synapse maakt gebruik van een technologie met de naam PolyBase waarmee u gegevens kunt ophalen en opvragen uit relationele en niet-relationele bronnen. U kunt de gegevens opslaan die zijn gelezen als SQL-tabellen in de Azure Synapse-service.

Onderdelen van Azure Synapse Analytics
Azure Synapse Analytics bestaat uit de vijf elementen:
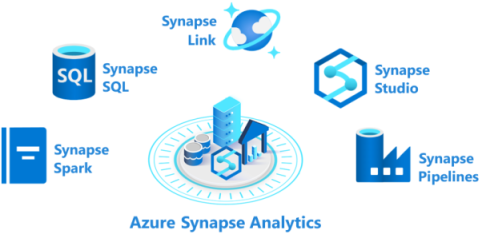
- Azure Synapse SQL-pool: Synapse SQL biedt zowel serverloze als toegewezen resourcemodellen voor gebruik met een architectuur op basis van knooppunten. Voor voorspelbare prestaties en kosten kunt u toegewezen SQL-pools maken. Voor onregelmatige of niet-geplande workloads kunt u het altijd beschikbare serverloze SQL-eindpunt gebruiken.
- Azure Synapse Spark-pool: deze pool is een cluster met servers waarop Apache Spark wordt uitgevoerd om gegevens te verwerken. U schrijft uw logica voor gegevensverwerking met behulp van een van de vier ondersteunde talen: Python, Scala, SQL en C# (via .NET voor Apache Spark). Apache Spark voor Azure Synapse integreert Apache Spark (de open source big data-engine die wordt gebruikt voor gegevensvoorbereiding, data engineering, ETL en machine learning).
- Azure Synapse Pipelines: Azure Synapse Pipelines past de mogelijkheden van Azure Data Factory toe. Pijplijnen zijn de cloudgebaseerde ETL- en gegevensintegratieservice waarmee u gegevensgestuurde werkstromen kunt maken voor het organiseren van gegevensverplaatsing en het transformeren van gegevens op schaal. U kunt activiteiten opnemen die de gegevens transformeren terwijl deze worden overgedragen, of u kunt gegevens uit meerdere bronnen combineren.
- Azure Synapse Link: Met dit onderdeel kunt u verbinding maken met Azure Cosmos DB. U kunt deze gebruiken om bijna realtime analyses uit te voeren voor de operationele gegevens die zijn opgeslagen in een Azure Cosmos DB-database.
- Azure Synapse Studio: dit element is een webgebaseerde IDE die centraal kan worden gebruikt om te werken met alle mogelijkheden van Azure Synapse Analytics. U kunt Azure Synapse Studio gebruiken om SQL- en Spark-pools te maken, pijplijnen te definiëren en uit te voeren en koppelingen naar externe gegevensbronnen te configureren.
Analytische opties
Azure Synapse Analytics ondersteunt een reeks analytische scenario's. Wanneer u de tabel bekijkt, kunt u overwegen hoe de scenario's van toepassing zijn op de Organisatie van Tailwind Traders.
| Analyse | Scenariobeschrijving | Beschrijving |
|---|---|---|
| Beschrijvend | Wat gebeurt er? | Azure Synapse past de dedicated SQL-poolmogelijkheid toe waarmee u een persistent datawarehouse kunt maken om vragen van het type 'wat nu?' te analyseren. U kunt gebruikmaken van de serverloze SQL-pool om gegevens voor te bereiden op bestanden die zijn opgeslagen in een data lake om interactief een datawarehouse te maken. |
| Diagnostiek | Waarom gebeurt het? | U kunt de serverloze SQL-poolfunctie in Azure Synapse gebruiken om interactief gegevens binnen een data lake te verkennen. Met serverloze SQL-pools kan een gebruiker snel zoeken naar andere gegevens die hen kunnen helpen begrijpen waarom vragen zijn. |
| Voorspellende | Wat gebeurt er waarschijnlijk? | Azure Synapse Analytics maakt gebruik van de geïntegreerde Apache Spark-engine en Azure Synapse Spark-pools voor predictive analytics. Deze actie wordt gecombineerd met andere services, zoals Azure Machine Learning Services en Azure Databricks, om u te helpen bij het beantwoorden van toekomstige vragen. |
| Prescriptief | Wat moet er gebeuren? | U kunt prescriptieve analyse met realtime- of bijna-realtimegegevens gebruiken om oplossingen voor uw vragen over welke actie te identificeren. Azure Synapse Analytics biedt deze mogelijkheid via Apache Spark en Azure Synapse Link, en door streamingtechnologieën zoals Azure Stream Analytics te integreren. |
Bedrijfsscenario
Laten we eens kijken naar een scenario waarin het bedrijf klanten bedient met informatie over de aandelenmarkt. U moet een combinatie van batch- en stroomverwerking bieden ter ondersteuning van de Tailwind Traders-infrastructuur. De up-to-the-second-gegevens kunnen worden gebruikt om realtime te bewaken, waarbij een directe beslissing nodig is om weloverwogen beslissingen te nemen over kopen of verkopen opsplitsen. Historische gegevens zijn even belangrijk voor een weergave van trends in prestaties. Wat voor soort datawarehouse- en gegevensintegratieoplossing zou u aanbevelen om toegang te bieden tot de gegevensstromen van onbewerkte gegevens en de voorbereide bedrijfsgegevens die zijn afgeleid van deze gegevens? Met Azure Synapse Analytics kunt u gegevens uit externe bronnen opnemen en deze gegevens vervolgens transformeren en aggregeren in een indeling die geschikt is voor analyseverwerking.
Aandachtspunten bij het kiezen van Azure Data Factory of Azure Synapse Analytics
De volgende tabel vergelijkt opslagoplossingscriteria voor het gebruik van Azure Data Factory versus Azure Synapse Analytics. Bekijk de criteria en bedenk welke oplossing optimaal is voor Tailwind Traders.
| Vergelijken | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Gegevens delen | Gegevens kunnen worden gedeeld in verschillende data factory's | Niet ondersteund |
| Oplossingssjablonen | Oplossingssjablonen worden geleverd met de galerie met Azure Data Factory-sjablonen | Oplossingssjablonen worden aangeboden in het Synapse Workspace Knowledge Center |
| Integratieruntime-stromen voor meerdere regio's | Gegevensstromen tussen regio's worden ondersteund | Niet ondersteund |
| Gegevens monitoren | Gegevensbewaking is geïntegreerd met Azure Monitor | Diagnostische logboeken zijn beschikbaar in Azure Monitor |
| Gegevensstroom bewaken voor Spark-taken | Niet ondersteund | Spark-taken kunnen worden bewaakt voor de gegevensstroom met behulp van Synapse Spark-pools |
Azure Synapse Analytics is een ideale oplossing voor veel andere scenario's. Overweeg de volgende opties:
- Overweeg verschillende gegevensbronnen. Wanneer u verschillende gegevensbronnen hebt die gebruikmaken van Azure Synapse Analytics voor codevrije ETL- en gegevensstroomactiviteiten.
- Overweeg Machine Learning. Wanneer u Machine Learning-oplossingen wilt implementeren met behulp van Apache Spark, kunt u Azure Synapse Analytics gebruiken voor ingebouwde ondersteuning voor Azure Machine Learning.
- Overweeg data lake-integratie. Wanneer u bestaande gegevens hebt opgeslagen in een data lake en integratie met Azure Data Lake en andere invoerbronnen nodig hebt, biedt Azure Synapse Analytics naadloze integratie tussen de twee onderdelen.
- Overweeg realtime analyses. Wanneer u realtime analyses nodig hebt, kunt u functies zoals Azure Synapse Link gebruiken om gegevens in realtime te analyseren en inzichten te bieden.