Vooraf samengestelde modellen gebruiken
Tip
Zie het tabblad Tekst en afbeeldingen voor meer informatie.
Met vooraf samengestelde modellen in Azure Document Intelligence kunt u gegevens extraheren uit algemene formuliertypen zonder uw eigen modellen te trainen. Microsoft traint deze modellen op grote aantallen voorbeelddocumenten, zodat u nauwkeurige en betrouwbare resultaten kunt verwachten voor standaarddocumenttypen.
Modellen voor documentanalyse
Voordat u naar de vooraf samengestelde domeinspecifieke modellen kijkt, is het belangrijk om inzicht te hebben in de documentanalysemodellen die deze modellen ondersteunen.
Model lezen
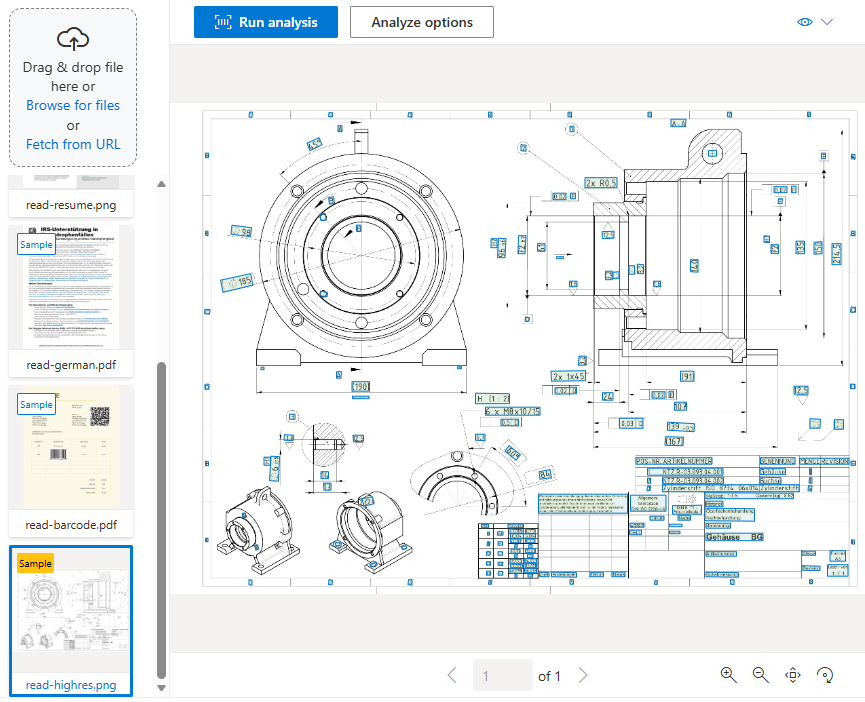
Het leesmodel extraheert gedrukte en handgeschreven tekst uit documenten en afbeeldingen. Hiermee wordt de taal van elke tekstregel gedetecteerd en wordt aangegeven of tekst handgeschreven of afgedrukt is. Het leesmodel wordt gebruikt als de basis voor tekstextractie in alle andere Document Intelligence-modellen.
Voor PDF- of TIFF-bestanden met meerdere pagina's kunt u de pages parameter in uw aanvraag gebruiken om een paginabereik voor analyse op te geven.
Het leesmodel is ideaal als u woorden en lijnen wilt extraheren uit documenten zonder vaste of voorspelbare structuur.
Indelingsmodel
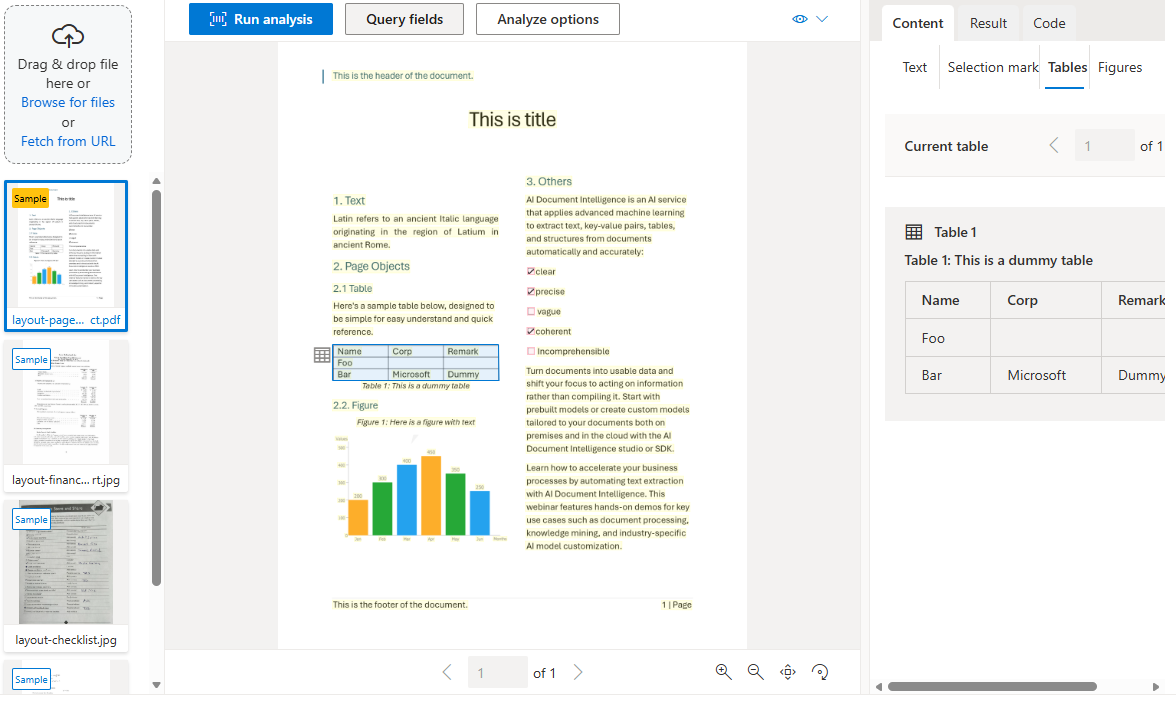
Het indelingsmodel breidt de tekstextractie van het leesmodel uit met detectie van selectiemarkeringen, tabellen en documentstructuurinformatie. Het ondersteunt ook een optionele keyValuePairs functie om sleutel-waardeparen te extraheren.
Wanneer u een document digitaliseert, kan het worden gehoekt of kunnen tabellen complexe structuren hebben met samengevoegde cellen of onvolledige rijen. Het indelingsmodel kan deze problemen afhandelen. Elke tabelcel wordt geëxtraheerd met de inhoud, de omkaderingspositie en de rij-/kolomindexen.
Selectiemarkeringen (selectievakjes en keuzerondjes) worden geëxtraheerd met het begrenzingsvak, het betrouwbaarheidsniveau en of ze zijn geselecteerd.
Opmerking
Het algemene documentmodel was beschikbaar in eerdere versies van Document Intelligence, maar is afgeschaft in de 2023-10-31-preview release. De functionaliteit voor sleutel-waardepaar en entiteitextractie is opgenomen in het indelingsmodel en andere functies.
Vooraf samengestelde modellen voor specifieke documenttypen
Azure Document Intelligence bevat vooraf samengestelde modellen die zijn getraind op specifieke documenttypen. De volgende vooraf samengestelde modellen zijn enkele voorbeelden die beschikbaar zijn voor het extraheren van velden uit algemene zakelijke documenten:
Financiële en juridische documenten
| Model | Beschrijving |
|---|---|
| Factuur | Extraheert de klantnaam, leveranciergegevens, inkoopordernummer, factuur- en einddatums, facturerings- en verzendadressen, regelitems en totalen. |
| Kwitantie | Extraheert verkoopgegevens, transactiedatum en -tijd, regelitems en totalen. Ondersteunt verwerking van hotelbevestigingen met één pagina. |
| Bankafschrift | Extraheert accountgegevens, begin- en eindsaldi en transactiegegevens. |
| Cheque | Haalt ontvanger, bedrag, datum en andere relevante informatie eruit. |
| Loonstrookje | Extraheert lonen, uren, aftrek, nettoloon en andere gebruikelijke loonstrookvelden. |
| Creditcard | Extraheert betalingskaartgegevens. |
| Contract | Extraheert overeenkomst- en partijgegevens. |
Amerikaanse belastingdocumenten
| Model | Beschrijving |
|---|---|
| Verenigde Amerikaanse belasting | Eén model dat wordt geëxtraheerd uit elk ondersteund amerikaans belastingformuliertype. |
| W-2 | Haalt belastbare belastinggegevens op. |
| 1098 en varianten | Haalt hypotheekrente en gerelateerde gegevens op. |
| 1099 en variaties | Verwerft inkomsten uit verschillende bronnen. |
| 1040 en varianten | Extraheert de details van de individuele inkomstenbelastingformulieren. |
Amerikaanse hypotheekdocumenten
| Model | Beschrijving |
|---|---|
| 1003 (URLA) | Extraheert details van de leningsaanvraag. |
| 1004 (URAR) | Haalt informatie op uit de beoordeling van onroerend goed. |
| 1005 | Extraheert validatie-van-werkgegevens. |
| 1008 | Extraheert de overdrachtsgegevens van de lening. |
| Openbaarmaking sluiten | Extraheert de definitieve voorwaarden voor de finalisering van leningen. |
Persoonlijke identificatiedocumenten
| Model | Beschrijving |
|---|---|
| ID-document | Extraheert gegevens uit Amerikaanse rijbewijzen, EU-identiteitskaarten en rijbewijzen, en internationale paspoorten. Bevat namen, geboortedatums, documentnummers en goedkeuringen of beperkingen. |
| Zorgverzekeringskaart | Extraheert algemene velden uit Amerikaanse gezondheidsverzekeringskaarten. |
| Huwelijksakte | Haalt gecertificeerde huwelijksinformatie op. |
Belangrijk
Het id-documentmodel extraheert persoonlijke gegevens die in de meeste rechtsgebieden onder de wetgeving inzake gegevensbescherming vallen. Zorg ervoor dat u de toestemming van de persoon hebt om hun gegevens op te slaan en dat u voldoet aan alle toepasselijke wettelijke vereisten.
Functies van vooraf samengestelde modellen
Vooraf samengestelde modellen zijn ontworpen om verschillende typen gegevens uit documenten te extraheren. Deze functies zijn onder andere:
- Tekstextractie: Alle vooraf samengestelde modellen extraheren lijnen en woorden uit handgeschreven en afgedrukte tekst.
- Sleutel-waardeparen: tekstbereiken waarmee een label en het bijbehorende antwoord worden geïdentificeerd. Bijvoorbeeld gewicht en 31 kg.
- Selectiemarkeringen: selectievakjes en radioknoppen, inclusief of ze al dan niet zijn geselecteerd.
- Tabellen: Gegevens in cellen, inclusief het aantal kolommen en rijen, kolom- en rijkoppen en samengevoegde cellen.
-
Velden: Modellen die zijn getraind voor een specifiek formuliertype identificeren een vaste set velden. Bijvoorbeeld extraheert het factuurmodel
CustomerNameenInvoiceTotal.
Wanneer gebruikt u vooraf gemaakte versus aangepaste modellen
Vooraf samengestelde modellen hebben betrekking op de meest voorkomende documenttypen. Als u een branchespecifiek of uniek formuliertype hebt, krijgt u mogelijk nauwkeurigere resultaten met een aangepast model. Voor aangepaste modellen zijn echter tijd- en voorbeeldgegevens vereist om te trainen. Controleer altijd of er een vooraf samengesteld model bestaat voor uw scenario voordat u in aangepaste modelontwikkeling investeert.