Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel bevat richtlijnen voor het oplossen van problemen waarbij een Microsoft SQL Server-query te veel tijd (uren of dagen) duurt.
Symptomen
Dit artikel is gericht op query's die zonder einde lijken te worden uitgevoerd of gecompileerd. Dat wil gezegd, het CPU-gebruik blijft toenemen. Dit artikel is niet van toepassing op query's die zijn geblokkeerd of wachten op een resource die nooit is vrijgegeven. In die gevallen blijft het CPU-gebruik constant of verandert het slechts enigszins.
Belangrijk
Als er nog een query wordt uitgevoerd, kan deze uiteindelijk worden voltooid. Dit proces kan slechts enkele seconden of meerdere dagen duren. In sommige situaties kan de query echt eindeloos zijn, bijvoorbeeld wanneer een WHILE-lus niet wordt afgesloten. De term 'nooit eindigend' wordt hier gebruikt om de perceptie te beschrijven van een query die niet is voltooid.
Oorzaak
Veelvoorkomende oorzaken van langlopende (nooit eindigende) query's zijn:
-
Geneste lus (NL) joins op zeer grote tabellen: Vanwege de aard van NL-joins kan een query die tabellen met veel rijen bevat lange tijd worden uitgevoerd. Zie Joins voor meer informatie.
- Een voorbeeld van een NL join is het gebruik van
TOP,FASTofEXISTS. Zelfs als een hash- of samenvoegingsdeelname sneller kan zijn, kan de optimizer geen operator gebruiken vanwege het rijdoel. - Een ander voorbeeld van een NL join is het gebruik van een ongelijkheidsdeelnamepredicaat in een query. Bijvoorbeeld:
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. De optimizer kan hier ook geen samenvoegen of hash-joins gebruiken.
- Een voorbeeld van een NL join is het gebruik van
- Verouderde statistieken: Query's die een plan kiezen op basis van verouderde statistieken, kunnen suboptimaal zijn en lang duren voordat ze worden uitgevoerd.
- Eindeloze lussen: T-SQL-query's die gebruikmaken van WHILE-lussen, zijn mogelijk onjuist geschreven. De resulterende code verlaat de lus nooit en wordt eindeloos uitgevoerd. Deze query's zijn echt nooit eindigend. Ze lopen totdat ze handmatig worden gedood.
- Complexe query's met veel joins en grote tabellen: Query's die betrekking hebben op veel gekoppelde tabellen, hebben doorgaans complexe queryplannen die lang kunnen duren voordat ze worden uitgevoerd. Dit scenario is gebruikelijk in analytische query's die geen rijen uitfilteren en die betrekking hebben op een groot aantal tabellen.
- Ontbrekende indexen: Query's kunnen aanzienlijk sneller worden uitgevoerd als de juiste indexen worden gebruikt voor tabellen. Met indexen kunt u een subset van de gegevens selecteren om snellere toegang te bieden.
Solution
Stap 1: Nooit eindigende query's detecteren
Zoek naar een nooit-eindigende query die wordt uitgevoerd op het systeem. U moet bepalen of een query een lange uitvoeringstijd heeft, een lange wachttijd (vastgelopen op een knelpunt) of een lange compilatietijd.
1.1 Voer een diagnose uit
Voer de volgende diagnostische query uit op uw SQL Server-exemplaar waar de nooit eindigende query actief is:
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 Bekijk de uitvoer
Er zijn verschillende scenario's die ertoe kunnen leiden dat een query lang wordt uitgevoerd: lange uitvoering, lange wachttijd en lange compilatie. Zie Uitvoeren versus wachten voor meer informatie over waarom een query langzaam kan worden uitgevoerd : waarom zijn query's traag?
Lange uitvoeringstijd
De stappen voor probleemoplossing in dit artikel zijn van toepassing wanneer u een uitvoer ontvangt die vergelijkbaar is met het volgende, waarbij de CPU-tijd evenredig toeneemt aan de verstreken tijd zonder aanzienlijke wachttijden.
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | actief | 64.40 | 23.50 | 0 | 0.00 | NULL |
De query wordt continu uitgevoerd als deze het volgende heeft:
- Een toenemende CPU-tijd
- Een status van
runningofrunnable - Minimale of nul wachttijd
- Geen wait_type
In deze situatie leest de query rijen, samenvoegen, verwerken, resultaten verwerken, berekenen of opmaken. Deze activiteiten zijn alle CPU-gebonden acties.
Notitie
Wijzigingen in logical_reads dit geval zijn niet relevant omdat sommige CPU-gebonden T-SQL-aanvragen, zoals het uitvoeren van berekeningen of een WHILE lus, helemaal geen logische leesbewerkingen uitvoeren.
Als de trage query aan deze criteria voldoet, moet u zich richten op het verminderen van de runtime. Het verminderen van runtime omvat meestal het verminderen van het aantal rijen dat de query gedurende de hele levensduur moet verwerken door indexen toe te passen, de query opnieuw te schrijven of statistieken bij te werken. Zie de sectie Oplossing voor meer informatie.
Lange wachttijd
Dit artikel is niet van toepassing op scenario's met lange wachttijden. In een wachtscenario ontvangt u mogelijk een uitvoer die lijkt op het volgende voorbeeld waarin het CPU-gebruik niet enigszins wordt gewijzigd of gewijzigd omdat de sessie op een resource wacht:
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | onderbroken | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
Het wachttype geeft aan dat de sessie wacht op een resource. Een lange verstreken tijd en een lange wachttijd geven aan dat de sessie op de meeste levensduur van deze resource wacht. Тhe korte CPU-tijd geeft aan dat er weinig tijd is besteed aan het verwerken van de query.
Zie Problemen met trage query's in SQL Server oplossen om problemen met query's op te lossen die lang zijn vanwege wachttijden.
Lange compilatietijd
In zeldzame gevallen merkt u mogelijk dat het CPU-gebruik gedurende een bepaalde periode voortdurend toeneemt, maar niet wordt aangestuurd door de uitvoering van de query. In plaats daarvan kan een te lange compilatie (het parseren en compileren van een query) de oorzaak zijn. In deze gevallen controleert u de transaction_name uitvoerkolom op een waarde van sqlsource_transform. Deze transactienaam geeft een compilatie aan.
Stap 2: Diagnostische logboeken handmatig verzamelen
Nadat u hebt vastgesteld dat er een nooit-eindigende query op het systeem bestaat, kunt u de plangegevens van de query verzamelen om verdere problemen op te lossen. Als u de gegevens wilt verzamelen, gebruikt u een van de volgende methoden, afhankelijk van uw versie van SQL Server.
- SQL Server 2008 - SQL Server 2014 (eerder dan SP2)
- SQL Server 2014 (later dan SP2) en SQL Server 2016 (ouder dan SP1)
- SQL Server 2016 (later dan SP1) en SQL Server 2017
- SQL Server 2019 en latere versies
Voer de volgende stappen uit om diagnostische gegevens te verzamelen met behulp van SQL Server Management Studio (SSMS):
Leg de xml van het geschatte uitvoeringsplan voor query's vast.
Bekijk het queryplan om te zien of de gegevens duidelijke indicaties tonen van wat de traagheid veroorzaakt. Voorbeelden van typische indicaties zijn:
- Tabel- of indexscans (bekijk geschatte rijen)
- Geneste lussen die worden aangestuurd door een enorme buitenste tabelgegevensset
- Geneste lussen met een grote vertakking aan de binnenkant van de lus
- Tabelspools
- Functies in de
SELECTlijst die lang duren om elke rij te verwerken
Als de query sneller wordt uitgevoerd, kunt u de 'snelle' uitvoeringen (werkelijk XML-uitvoeringsplan) vastleggen om resultaten te vergelijken.
SQL LogScout gebruiken om nooit-eindigende query's vast te leggen
U kunt SQL LogScout gebruiken om logboeken vast te leggen terwijl een nooit eindigende query wordt uitgevoerd. Gebruik het nooit eindigende queryscenario met de volgende opdracht:
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
Notitie
Dit logboekopnameproces vereist dat de lange query ten minste 60 seconden CPU-tijd verbruikt.
SQL LogScout legt ten minste drie queryplannen vast voor elke query met een hoog CPU-verbruik. U kunt bestandsnamen vinden die lijken op servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan. U kunt deze bestanden in de volgende stap gebruiken wanneer u plannen bekijkt om de reden voor lange uitvoering van query's te identificeren.
Stap 3: De verzamelde plannen bekijken
In deze sectie wordt beschreven hoe u de verzamelde gegevens kunt controleren. Het maakt gebruik van de meerdere XML-queryplannen (met behulp van extensie .sqlplan) die worden verzameld in Microsoft SQL Server 2016 SP1 en latere builds en versies.
Vergelijk uitvoeringsplannen door de volgende stappen uit te voeren:
Open een eerder opgeslagen queryuitvoeringsplanbestand (
.sqlplan).Klik met de rechtermuisknop in een leeg gebied van het uitvoeringsplan en selecteer Showplan vergelijken.
Kies het tweede queryplanbestand dat u wilt vergelijken.
Zoek naar dikke pijlen die duiden op een groot aantal rijen die tussen operators stromen. Selecteer vervolgens de operator vóór of na de pijl en vergelijk het aantal werkelijke rijen over de twee plannen.
Vergelijk de tweede en derde planning om te zien of de grootste stroom rijen zich in dezelfde operatoren voordoet.
Voorbeeld:
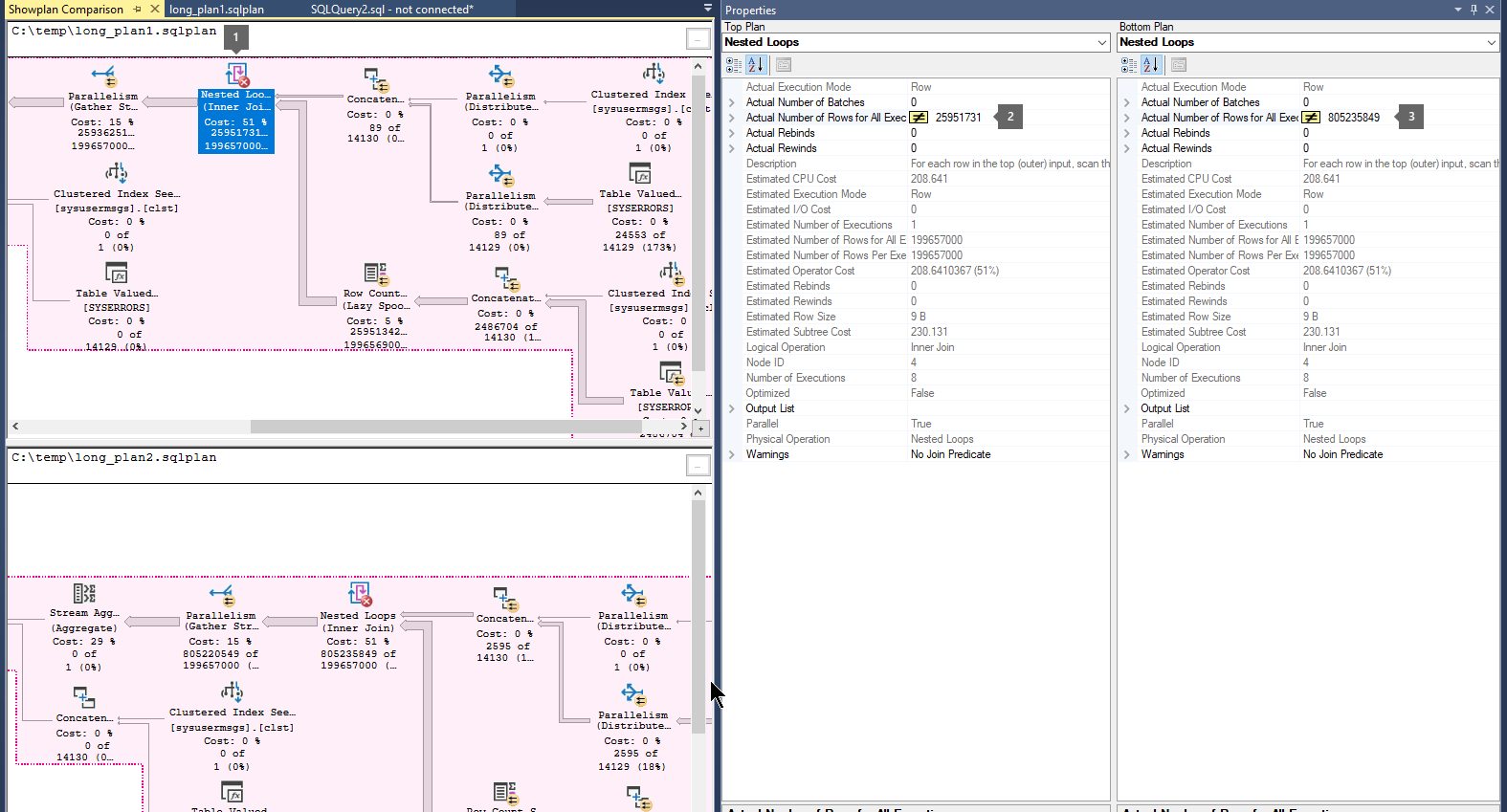

Stap 4: Oplossing
Zorg ervoor dat statistieken worden bijgewerkt voor de tabellen die in de query worden gebruikt.
Zoek naar ontbrekende indexaan aanbevelingen in het queryplan en pas alle aanbevelingen toe die u vindt.
Vereenvoudig de query:
- Gebruik meer selectieve
WHEREpredicaten om de gegevens te verminderen die vooraf worden verwerkt. - Breek het uit elkaar.
- Selecteer enkele onderdelen in tijdelijke tabellen en voeg ze later toe.
- Verwijder
TOP,EXISTSenFAST(T-SQL) in de query's die lange tijd worden uitgevoerd vanwege een optimalisatierijdoel.- U kunt ook de
DISABLE_OPTIMIZER_ROWGOALhint gebruiken. Zie Row Goals Gone Rogue voor meer informatie.
- U kunt ook de
- Vermijd het gebruik van CTE's (Common Table Expressions) in dergelijke gevallen omdat ze instructies combineren in één grote query.
- Gebruik meer selectieve
Probeer queryhints te gebruiken om een beter plan te maken:
-
HASH JOINofMERGE JOINhint -
FORCE ORDERtip -
FORCESEEKtip RECOMPILE- USE
PLAN N'<xml_plan>'(als u een snel queryplan hebt dat u kunt afdwingen)
-
Gebruik Query Store (QDS) om een goed bekend plan af te dwingen als een dergelijk plan bestaat en of uw SQL Server-versie Query Store ondersteunt.