Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Oorspronkelijke productversie: SQL Server
Oorspronkelijk KB-nummer: 243589
Inleiding
In dit artikel wordt beschreven hoe u omgaat met een prestatieprobleem bij databasetoepassingen bij het gebruik van SQL Server: trage prestaties van een specifieke query of groep query's. Met de volgende methodologie kunt u de oorzaak van het probleem met trage query's beperken en u naar de oplossing leiden.
Langzame zoekopdrachten vinden
Om vast te stellen of er prestatieproblemen zijn met uw SQL Server-exemplaar, begint u met het onderzoeken van query's op basis van hun uitvoeringstijd (gemeten verstreken tijd). Controleer of de tijd een drempelwaarde overschrijdt die u hebt ingesteld (in milliseconden) op basis van een vastgestelde prestatiebasislijn. In een stresstestomgeving hebt u bijvoorbeeld mogelijk een drempelwaarde ingesteld voor uw workload die niet langer is dan 300 ms en u kunt deze drempelwaarde gebruiken. Vervolgens kunt u alle query's identificeren die deze drempelwaarde overschrijden, waarbij u zich richt op elke afzonderlijke query en de vooraf vastgestelde duur van de prestatiebasislijn. Uiteindelijk maken zakelijke gebruikers zich zorgen over de totale duur van databasequery's; Daarom is de belangrijkste focus op de uitvoeringsduur. Andere metrische gegevens, zoals CPU-tijd en logische leesbewerkingen, worden verzameld om het onderzoek te beperken.
Controleer total_elapsed_time en cpu_time kolommen in sys.dm_exec_requests voor het uitvoeren van instructies. Voer de volgende query uit om de gegevens op te halen:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Voor eerdere uitvoeringen van de query controleert u last_elapsed_time en last_worker_time kolommen in sys.dm_exec_query_stats. Voer de volgende query uit om de gegevens op te halen:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNotitie
Als
avg_wait_timeeen negatieve waarde wordt weergegeven, is dit een parallelle query.Als u de query op aanvraag kunt uitvoeren in SQL Server Management Studio (SSMS), sqlcmd of de MSSQL-extensie voor Visual Studio Code, voert u deze uit met SET STATISTICS TIME
ONen SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFVervolgens ziet u in Berichten de CPU-tijd, verstreken tijd en logische leesbewerkingen als volgt:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Als u een queryplan kunt verzamelen, controleert u de gegevens uit de eigenschappen van het uitvoeringsplan.
Voer de query uit inclusief Werkelijk Uitvoeringsplan Opnemen.
Selecteer de meest linkse operator in het uitvoeringsplan.
Vouw vanuit Eigenschappen de eigenschap QueryTimeStats uit.
Controleer ElapsedTime en CpuTime.
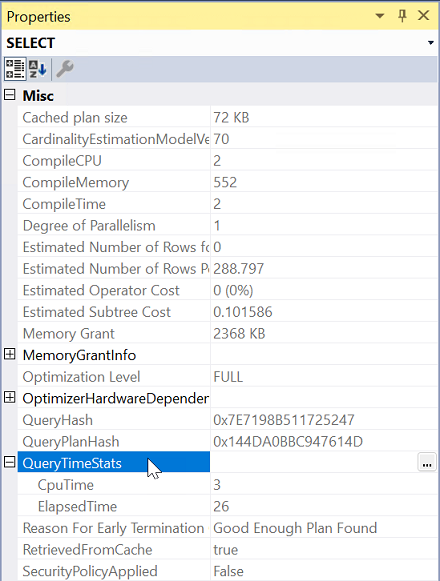
Uitvoeren versus wachten: waarom zijn query's traag?
Als u query's vindt die de vooraf gedefinieerde drempelwaarde overschrijden, controleert u waarom deze traag kunnen zijn. De oorzaak van prestatieproblemen kan worden gegroepeerd in twee categorieën, actief of wachtend:
WACHTEN: query's kunnen traag zijn omdat ze lange tijd op een knelpunt wachten. Bekijk een gedetailleerde lijst met knelpunten in typen wachttijden.
UITVOEREN: Queries kunnen traag zijn omdat ze al lange tijd aan het uitvoeren zijn. Met andere woorden, deze query's maken actief gebruik van CPU-resources.
Een query kan gedurende zijn levensduur enige tijd actief zijn en enige tijd in de wacht staan. Uw focus is echter om te bepalen welke dominante categorie bijdraagt aan de lange verstreken tijd. Daarom moet u eerst bepalen in welke categorie de query's vallen. Het is eenvoudig: als een query niet wordt uitgevoerd, wacht deze. Ideaal gezien besteedt een query het grootste deel van de verstreken tijd in een draaiende staat en weinig tijd wachtend op middelen. In het beste geval wordt een query ook uitgevoerd binnen of onder een vooraf vastgestelde basislijn. Vergelijk de verstreken tijd en CPU-tijd van de query om het probleemtype te bepalen.
Type 1: CPU-gebonden (runner)
Als de CPU-tijd bijna, gelijk aan, of hoger is dan de verstreken tijdsduur, kunt u dit beschouwen als een CPU-intensieve query. Als de verstreken tijd bijvoorbeeld 3000 milliseconden (ms) is en de CPU-tijd 2900 ms is, betekent dit dat de meeste verstreken tijd wordt besteed aan de CPU. Vervolgens kunnen we zeggen dat het een CPU-afhankelijke query is.
Voorbeelden van actieve (CPU-gebonden) query's:
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Logische leesbewerkingen waarbij gegevens- of indexpagina's in de cache worden gelezen, zijn meestal de drijvende kracht achter het CPU-gebruik in SQL Server. Er kunnen scenario's zijn waarin CPU-gebruik afkomstig is van andere bronnen: een while-lus (in T-SQL of andere code, zoals XProcs- of SQL CRL-objecten). Het tweede voorbeeld in de tabel illustreert een dergelijk scenario, waarbij het merendeel van de CPU niet van leesbewerkingen afkomstig is.
Notitie
Als de CPU-tijd groter is dan de duur, geeft dit aan dat er een parallelle query wordt uitgevoerd; meerdere threads gebruiken tegelijkertijd de CPU. Zie Parallel queries - runner of waiter voor meer informatie.
Type 2: Wachten op een knelpunt (wachtende)
Een query wacht op een knelpunt als de verstreken tijd aanzienlijk groter is dan de CPU-tijd. De verstreken tijd omvat de tijd die de query uitvoert op de CPU (CPU-tijd) en de tijd die wacht tot een resource wordt vrijgegeven (wachttijd). Als de verstreken tijd bijvoorbeeld 2000 ms is en de CPU-tijd 300 ms is, is de wachttijd 1700 ms (2000 - 300 = 1700). Zie Typen wachttijden voor meer informatie.
Voorbeelden van wachtende queries
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10.080 | 700 | 80.000 |
Parallel queries - runner of waiter
Parallelle query's kunnen meer CPU-tijd gebruiken dan de totale duur. Het doel van parallellisme is om meerdere threads toe te staan om delen van een query tegelijkertijd uit te voeren. In één seconde van de kloktijd kan een query acht seconden CPU-tijd gebruiken door acht parallelle threads uit te voeren. Daarom wordt het lastig om een CPU-gebonden of een wachtquery te bepalen op basis van het verstreken tijds- en CPU-tijdsverschil. Als algemene regel volgt u echter de principes die in de bovenstaande twee secties worden vermeld. De samenvatting is:
- Als de verstreken tijd veel groter is dan de CPU-tijd, kunt u een ober overwegen.
- Als de CPU-tijd veel groter is dan de verstreken tijd, overweeg dan een hardloper.
Voorbeelden van parallelle query's:
| Verstreken tijd (ms) | CPU-tijd (ms) | Leesbewerkingen (logisch) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Visuele weergave op hoog niveau van de methodologie

Diagnostiseren en oplossen van wachtende query's
Als u hebt vastgesteld dat de relevante query's wachtrijen vormen, is de volgende stap om u te concentreren op het oplossen van knelpunten. Ga anders naar stap 4: Diagnose uitvoeren van query's en los deze op.
Als u een query wilt optimaliseren die wacht op knelpunten, identificeert u hoe lang de wachttijd is en waar het knelpunt zich bevindt (het wachttype). Zodra het wachttype is bevestigd, vermindert u de wachttijd of elimineert u de wachttijd volledig.
Als u de geschatte wachttijd wilt berekenen, trekt u de CPU-tijd (werktijd) af van de verstreken tijd van een query. Normaal gesproken is de CPU-tijd de werkelijke uitvoeringstijd, terwijl de rest van de levensduur van de query wachtende tijd is.
Voorbeelden van het berekenen van de geschatte wachttijd:
| Verstreken tijd (ms) | CPU-tijd (ms) | Wachttijd (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Het knelpunt identificeren of wachten
Voer de volgende query uit om historische langwachtquery's te identificeren (bijvoorbeeld >20% van de totale verstreken tijd is wachttijd). Deze query maakt gebruik van prestatiestatistieken voor queryplannen in de cache sinds het begin van SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCVoer de volgende query uit om query's met wachttijden langer dan 500 ms te identificeren:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Als u een queryplan kunt verzamelen, controleer de WaitStats van de eigenschappen van het uitvoeringsplan in SSMS:
- Voer de query uit met Het werkelijke uitvoeringsplan opnemen op.
- Klik met de rechtermuisknop op de meest linkse operator op het tabblad Uitvoeringsplan
- Selecteer Eigenschappen en vervolgens de eigenschap WaitStats .
- Controleer de WaitTimeMs en WaitType.
Als u bekend bent met PSSDiag-/SQLdiag - of SQL LogScout LightPerf-/GeneralPerf-scenario's, kunt u een van deze scenario's gebruiken om prestatiestatistieken te verzamelen en wachtquery's op uw SQL Server-exemplaar te identificeren. U kunt de verzamelde gegevensbestanden importeren en de prestatiegegevens analyseren met SQL Nexus.
Verwijzingen om wachttijden te elimineren of te verminderen
De oorzaken en oplossingen voor elk wachttype variëren. Er is geen algemene methode om alle wachttypen op te lossen. Hier volgen artikelen voor het oplossen van veelvoorkomende problemen met wachttypen:
- Blokkerende problemen begrijpen en oplossen (LCK_M_*)
- Problemen met blokkerende Azure SQL Database begrijpen en oplossen
- Oplossen van trage SQL Server-prestaties veroorzaakt door I/O-problemen (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- PAGELATCH_EX-conflicten bij het invoegen van de laatste pagina in SQL Server oplossen
- Geheugen verleent uitleg en oplossingen (RESOURCE_SEMAPHORE)
- Problemen met trage query's oplossen die het gevolg zijn van ASYNC_NETWORK_IO wachttype
- Oplossen van problemen met het hoge HADR_SYNC_COMMIT-wachttype met Always On-beschikbaarheidsgroepen
- Hoe het werkt: CMEMTHREAD en foutopsporing
- Parallelle wachttijden actiegericht maken (CXPACKET en CXCONSUMER)
- THREADPOOL-wachttijd
Zie de tabel in Typen wachttijden voor beschrijvingen van veel wachttypen en wat ze aangeven.
Lopende query's diagnose stellen en oplossen
Als de CPU-tijd (werktijd) zeer dicht bij de totale verstreken tijd ligt, besteedt de query het grootste deel van zijn levensduur aan uitvoering. Wanneer de SQL Server-engine een hoog CPU-gebruik aanstuurt, komt het hoge CPU-gebruik meestal uit query's die een groot aantal logische leesbewerkingen aansturen (de meest voorkomende reden).
Voer de volgende instructie uit om de query's te identificeren die verantwoordelijk zijn voor de activiteit met hoog CPU-gebruik:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Als query's de CPU op dit moment niet aansturen, kunt u de volgende instructie uitvoeren om te zoeken naar historische CPU-gebonden query's:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Algemene methoden voor het oplossen van langlopende, CPU-gebonden query's
- Het queryplan van de query onderzoeken
- Statistieken bijwerken
- ontbrekende indexen identificeren en toepassen. Zie Niet-geclusterde indexen afstemmen met ontbrekende indexsuggesties voor meer stappen voor het identificeren van ontbrekende indexen
- De query's opnieuw ontwerpen of herschrijven
- parametergevoelige plannen identificeren en oplossen
- Problemen met SARG-mogelijkheden identificeren en oplossen
- Identificeer en los problemen met rijdoel op waarbij langlopende geneste lussen kunnen worden veroorzaakt door TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Zie Row Goals Gone Rogue en Showplan-verbeteringen - Row Goal EstimateRowsWithoutRowGoal voor meer informatie
- Evalueer en los kardinaliteitschattingsproblemen op. Zie Verminderde queryprestaties na de upgrade van SQL Server 2012 of eerder naar 2014 of hoger voor meer informatie
- Identificeer en los quries op die niet volledig lijken te zijn, zie Problemen oplossen met query's die nooit eindigen in SQL Server
- Trage query's identificeren en oplossen die worden beïnvloed door time-out van de optimalisatie
- Problemen met hoge CPU-prestaties identificeren. Zie Problemen met hoog CPU-gebruik in SQL Server oplossen voor meer informatie
- Problemen met een query oplossen die een aanzienlijk prestatieverschil tussen twee servers laat zien
- Computing-resources in het systeem vergroten (CPU's)
- UPDATE-prestatieproblemen oplossen door smalle en brede plannen
Aanbevolen informatiebronnen
- Detecteerbare typen knelpunten in queryprestaties op SQL Server en Azure SQL Managed Instance
- Prestatiebewaking- en -afstemmingshulpmiddelen
- Opties voor automatisch afstemmen in SQL Server
- Indexarchitectuur- en ontwerprichtlijnen
- Query-timeoutfouten oplossen
- Problemen met hoog CPU-gebruik in SQL Server oplossen
- Verminderde queryprestaties na een upgrade van SQL Server 2012 of eerder naar versie 2014 of hoger