Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit document wordt beschreven hoe gegevensontdubbeling werkt.
Hoe werkt gegevensontdubbeling?
Gegevensontdubbeling in Windows Server is gemaakt met de volgende twee principes:
Optimalisatie mag het schrijven naar de schijf niet hinderen Gegevensontdubbeling optimaliseert gegevens met behulp van een naverwerkingsmodel. Alle gegevens worden niet-geoptimaliseerd naar de schijf geschreven en later geoptimaliseerd door gegevensontdubbeling.
Optimalisatie mag de toegangsemantiek niet wijzigen Gebruikers en toepassingen die toegang hebben tot gegevens op een geoptimaliseerd volume, weten niet dat de bestanden die ze openen, zijn ontdubbeld.
Zodra gegevensontdubbeling is ingeschakeld voor een volume, wordt het op de achtergrond uitgevoerd om:
- Identificeer herhaalde patronen in bestanden op dat volume.
- Verplaats deze gedeelten, of segmenten, naadloos met speciale aanwijzers die reparsepunten worden genoemd die verwijzen naar een unieke kopie van dat segment.
Dit gebeurt in de volgende vier stappen:
- Scan het bestandssysteem voor bestanden die voldoen aan het optimalisatiebeleid.

- Deel bestanden op in segmenten met een variabele grootte.

- Unieke segmenten identificeren.
- Plaats segmenten in het segmentarchief en comprimeert eventueel.
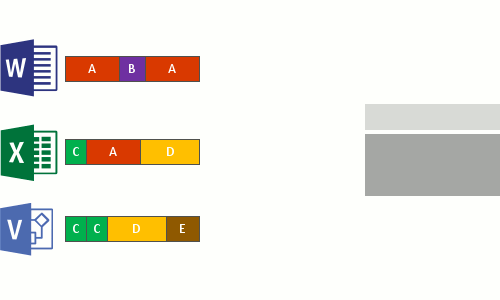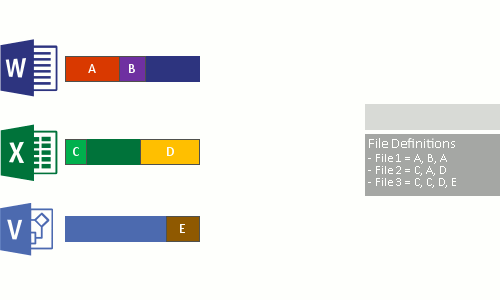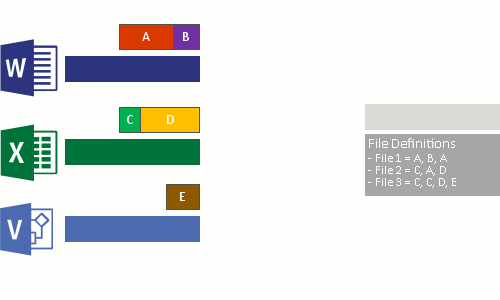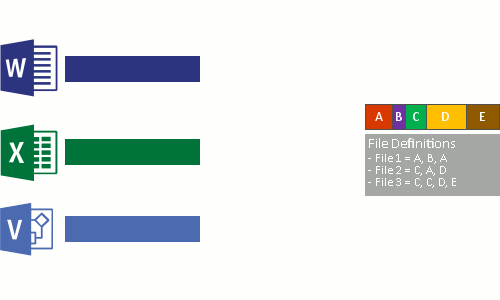
- Vervang de oorspronkelijke bestandsstroom van de nu geoptimaliseerde bestanden door een reparsepunt naar de chunk store.
Wanneer geoptimaliseerde bestanden worden gelezen, verzendt het bestandssysteem de bestanden met een reparsepunt naar het bestandssysteemfilter voor gegevensontdubbeling (Dedup.sys). Het filter leidt de leesbewerking om naar de juiste segmenten die de stroom vormen voor dat bestand in het segmentarchief. Wijzigingen in bereiken van ontdubbelde bestanden worden niet-geoptimaliseerd naar de schijf geschreven en worden geoptimaliseerd door de optimalisatietaak wanneer deze de volgende keer wordt uitgevoerd.
Gebruikstypen
De volgende gebruikstypen bieden een redelijke configuratie voor gegevensontdubbeling voor algemene werkbelastingen:
| Gebruikstype | Ideale workloads | Wat is er anders? |
|---|---|---|
| Verstek | Bestandsserver voor algemeen gebruik:
|
|
| Hyper-V | VDI-servers (Virtualized Desktop Infrastructure) |
|
| Backup | Gevirtualiseerde back-uptoepassingen, zoals Microsoft Data Protection Manager (DPM) |
|
Jobs
Gegevensontdubbeling maakt gebruik van een strategie voor naverwerking om de ruimte-efficiëntie van een volume te optimaliseren en te behouden.
| Taaknaam | Taakbeschrijvingen | Standaardschema |
|---|---|---|
| Optimalisering | De optimalisatietaak ontdubbelt door gegevens te segmenteren op een volume volgens de volumebeleidsinstellingen, (optioneel) die segmenten te comprimeren en segmenten uniek op te slaan in het segmentarchief. Het optimalisatieproces dat door gegevensontdubbeling wordt gebruikt, wordt uitgebreid beschreven in Hoe werkt gegevensontdubbeling? | Eenmaal per uur |
| Vuilnisinzameling | De garbagecollection-taak maakt schijfruimte vrij door overbodige segmenten te verwijderen waarnaar niet meer wordt verwezen door bestanden die onlangs zijn gewijzigd of verwijderd. | Elke zaterdag om 2:35 uur |
| Integriteitsopschoning | De integriteitsscrijstaak identificeert beschadiging in het segmentarchief vanwege schijffouten of slechte sectoren. Indien mogelijk kan gegevensontdubbeling automatisch volumefuncties (zoals spiegeling of pariteit op een Opslagruimten-volume) gebruiken om de beschadigde gegevens te reconstrueren. Daarnaast houdt Gegevensontdubbeling back-ups bij van populaire segmenten wanneer er meer dan 100 keer naar verwezen wordt in een gebied dat de hotspot heet. | Elke zaterdag om 3:35 uur |
| Optimalisatie ongedaan maken | De taak Optimalisatie ongedaan maken, een speciale taak die alleen handmatig moet worden uitgevoerd, maakt de optimalisatie ongedaan door ontdubbeling en schakelt gegevensontdubbeling voor dat volume uit. | Alleen op aanvraag |
Terminologie voor gegevensontdubbeling
| Term | Definition |
|---|---|
| Stuk | Een segment is een sectie van een bestand dat is geselecteerd door het segmenteringsalgoritmen voor gegevensontdubbeling, zoals waarschijnlijk voorkomt in andere, vergelijkbare bestanden. |
| Chunkopslag | Het segmentarchief is een georganiseerde reeks containerbestanden in de map System Volume Information die door Data Deduplicatie wordt gebruikt om segmenten uniek op te slaan. |
| Ontdubbeling | Een afkorting voor gegevensontdubbeling die vaak wordt gebruikt in PowerShell, Windows Server-API's en onderdelen en de Windows Server-community. |
| Bestandsmetagegevens | Elk bestand bevat metagegevens die interessante eigenschappen beschrijven over het bestand dat niet is gerelateerd aan de hoofdinhoud van het bestand. Bijvoorbeeld datum gemaakt, datum van laatste leesdatum, auteur, enzovoort. |
| Bestandsstroom | De bestandsstroom is de hoofdinhoud van het bestand. Dit is het deel van het bestand dat door gegevensontdubbeling wordt geoptimaliseerd. |
| Bestandssysteem | Het bestandssysteem is de software en de gegevensstructuur op schijf die het besturingssysteem gebruikt voor het opslaan van bestanden op opslagmedia. Gegevensontdubbeling wordt ondersteund op volumes die zijn geformatteerd met NTFS. |
| Bestandssysteemfilter | Een bestandssysteemfilter is een invoegtoepassing die het standaardgedrag van het bestandssysteem wijzigt. Gegevensontdubbeling maakt gebruik van een bestandssysteemfilter (Dedup.sys) om leesbewerkingen om te leiden naar geoptimaliseerde inhoud, volledig transparant voor de gebruiker of toepassing die de leesaanvraag doet. |
| Optimalisering | Een bestand wordt als geoptimaliseerd (of ontdubbeld) beschouwd door gegevensontdubbeling als het is gesegmenteerd en de unieke segmenten zijn opgeslagen in het segmentarchief. |
| Optimalisatiebeleid | Het optimalisatiebeleid geeft de bestanden op die moeten worden overwogen voor gegevensontdubbeling. Bestanden kunnen bijvoorbeeld buiten het beleid worden beschouwd als ze gloednieuw zijn, geopend, in een bepaald pad op het volume of een bepaald bestandstype zijn. |
| Reparsepunt | Een reparsepunt is een speciale tag die het bestandssysteem op de hoogte stelt om I/O door te geven aan een opgegeven bestandssysteemfilter. Wanneer de bestandsstroom van een bestand is geoptimaliseerd, vervangt Gegevensontdubbeling de bestandsstroom door een reparsepunt, waardoor gegevensontdubbeling de toegangsemantiek voor dat bestand kan behouden. |
| Volume | Een volume is een Windows-constructie voor een logisch opslagstation dat meerdere fysieke opslagapparaten op een of meer servers kan omvatten. Ontdubbeling is ingeschakeld op basis van volume-per-volume. |
| Werkdruk | Een workload is een toepassing die wordt uitgevoerd op Windows Server. Voorbeeldworkloads zijn bestandsserver voor algemeen gebruik, Hyper-V en SQL Server. |
Warning
Tenzij u door geautoriseerd Microsoft-ondersteuningspersoneel geïnstrueerd wordt, probeert u het chunk store niet handmatig te wijzigen. Als u dit doet, kan dit leiden tot beschadiging of verlies van gegevens.
Veelgestelde vragen
Hoe verschilt gegevensontdubbeling van andere optimalisatieproducten? Er zijn verschillende belangrijke verschillen tussen gegevensontdubbeling en andere algemene producten voor opslagoptimalisatie:
Hoe verschilt gegevensontdubbeling van Single Instance Store? Single Instance Store of SIS is een technologie die voorafging aan gegevensontdubbeling en voor het eerst werd geïntroduceerd in Windows Storage Server 2008 R2. Om een volume te optimaliseren, identificeerde Single Instance Store bestanden die volledig identiek waren en vervangen door logische koppelingen naar één kopie van een bestand dat is opgeslagen in het algemene SIS-archief. In tegenstelling tot Single Instance Store kan gegevensontdubbeling ruimte besparen op bestanden die niet identiek zijn, maar veel algemene patronen delen en bestanden die zelf veel herhaalde patronen bevatten. Single Instance Store is afgeschaft in Windows Server 2012 R2 en verwijderd in Windows Server 2016 ten gunste van gegevensontdubbeling.
Hoe verschilt gegevensontdubbeling van NTFS-compressie? NTFS-compressie is een functie van NTFS die u desgewenst kunt inschakelen op volumeniveau. Met NTFS-compressie wordt elk bestand afzonderlijk geoptimaliseerd via compressie tijdens schrijftijd. In tegenstelling tot NTFS-compressie kan gegevensontdubbeling ruimte besparen op alle bestanden op een volume. Dit is beter dan NTFS-compressie omdat bestanden mogelijk zowel interne duplicatie hebben (die wordt geadresseerd door NTFS-compressie) en overeenkomsten hebben met andere bestanden op het volume (die niet worden geadresseerd door NTFS-compressie). Daarnaast heeft Gegevensontdubbeling een naverwerkingsmodel, dat betekent dat nieuwe of gewijzigde bestanden niet-geoptimaliseerd naar de schijf worden geschreven, en later worden geoptimaliseerd door Gegevensontdubbeling.
Hoe verschilt gegevensontdubbeling van archiefbestandsindelingen zoals zip, rar, 7z, cab, enzovoort? Archiefbestandsindelingen, zoals zip, rar, 7z, cab, enzovoort, voeren compressie uit over een opgegeven set bestanden. Net zoals bij gegevensontdubbeling worden dubbele patronen binnen bestanden en gedupliceerde patronen tussen bestanden geoptimaliseerd. U moet echter de bestanden kiezen die u wilt opnemen in het archief. Toegangssemantiek is ook anders. Als u toegang wilt krijgen tot een specifiek bestand in het archief, moet u het archief openen, een specifiek bestand selecteren en dat bestand decomprimeren voor gebruik. Gegevensontdubbeling werkt transparant voor gebruikers en beheerders en vereist geen handmatige start. Daarnaast behoudt gegevensontdubbeling toegangssemantiek: geoptimaliseerde bestanden worden ongewijzigd weergegeven na optimalisatie.
Kan ik de instellingen voor gegevensontdubbeling voor mijn geselecteerde gebruikstype wijzigen? Yes. Hoewel gegevensontdubbeling redelijke standaardwaarden biedt voor aanbevolen werkbelastingen, wilt u mogelijk nog steeds de instellingen voor gegevensontdubbeling aanpassen om optimaal gebruik te maken van uw opslag. Daarnaast vereisen andere workloads enige aanpassingen om ervoor te zorgen dat gegevensontdubbeling de werkbelasting niet beïnvloedt.
Kan ik handmatig een gegevensontdubbelingstaak uitvoeren? Ja, alle gegevensontdubbelingstaken kunnen handmatig worden uitgevoerd. Dit kan wenselijk zijn als geplande taken niet zijn uitgevoerd vanwege onvoldoende systeembronnen of vanwege een fout. Daarnaast kan de taak Optimalisatie ongedaan maken alleen handmatig worden uitgevoerd.
Kan ik de historische resultaten van gegevensontdubbelingstaken bewaken? Ja, alle gegevensontdubbelingstaken maken vermeldingen in het Windows-gebeurtenislogboek.
Kan ik de standaardschema's voor de gegevensontdubbelingstaken op mijn systeem wijzigen? Ja, alle planningen kunnen worden geconfigureerd. Het wijzigen van de standaardschema's voor gegevensontdubbeling is vooral nuttig om ervoor te zorgen dat de gegevensontdubbelingstaken genoeg tijd hebben om te voltooien en niet hoeven te concurreren om middelen met de workload.