Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Opmerking
Voor meer functionaliteit kan PyTorch ook worden gebruikt met DirectML in Windows.
In de vorige fase van deze zelfstudie hebben we de gegevensset verkregen die we gaan gebruiken om onze afbeeldingsclassificatie te trainen met PyTorch. Nu is het tijd om die gegevens te gebruiken.
Als u de afbeeldingsclassificatie wilt trainen met PyTorch, moet u de volgende stappen uitvoeren:
- Laad de gegevens. Als u de vorige stap van deze zelfstudie hebt uitgevoerd, hebt u dit al afgehandeld.
- Definieer een convolutie neuraal netwerk.
- Definieer een verliesfunctie.
- Train het model op de trainingsgegevens.
- Test het netwerk op de testgegevens.
Definieer een convolutie neuraal netwerk.
Als u een neuraal netwerk wilt bouwen met PyTorch, gebruikt u het torch.nn pakket. Dit pakket bevat modules, uitbreidbare klassen en alle vereiste onderdelen voor het bouwen van neurale netwerken.
Hier bouwt u een eenvoudig convolutieneuraal netwerk (CNN) om de afbeeldingen van de CIFAR10 gegevensset te classificeren.
Een CNN is een klasse neurale netwerken, gedefinieerd als meerlaagse neurale netwerken die zijn ontworpen om complexe functies in gegevens te detecteren. Ze worden het meest gebruikt in Computer Vision-toepassingen.
Ons netwerk wordt gestructureerd met de volgende 14 lagen:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
De convolutielaag
De convolutielaag is een hoofdlaag van CNN waarmee we functies in afbeeldingen kunnen detecteren. Elk van de lagen heeft een aantal kanalen voor het detecteren van specifieke functies in afbeeldingen en een aantal kernels om de grootte van de gedetecteerde functie te definiëren. Daarom zou een convolutielaag met 64 kanalen en kernelgrootte van 3 x 3 64 verschillende functies detecteren, elk van de grootte 3 x 3. Wanneer u een convolutielaag definieert, geeft u het aantal in-kanalen, het aantal out-kanalen en de kernelgrootte op. Het aantal out-kanalen in de laag fungeert als het aantal in-kanalen naar de volgende laag.
Bijvoorbeeld: Een convolutielaag met in-channels=3, out-channels=10, en kernel-size=6 krijgt de RGB-afbeelding (3 kanalen) als invoer en past 10 kenmerkdetectoren toe op de afbeeldingen met het kernelformaat van 6x6. Kleinere kernelgrootten verminderen het delen van rekentijd en gewicht.
Andere lagen
De volgende andere lagen zijn betrokken bij ons netwerk:
- De
ReLUlaag is een activeringsfunctie voor het definiëren van alle binnenkomende functies die 0 of hoger zijn. Wanneer u deze laag toepast, wordt een getal kleiner dan 0 gewijzigd in nul, terwijl anderen hetzelfde blijven. - de
BatchNorm2dlaag past normalisatie toe op de invoer om nul gemiddelde en eenheidsvariantie te hebben en de netwerknauwkeurigheid te verhogen. - De
MaxPoollaag helpt ons ervoor te zorgen dat de locatie van een object in een afbeelding niet van invloed is op de mogelijkheid van het neurale netwerk om de specifieke functies te detecteren. - De
Linearlaag is laatste lagen in ons netwerk, waarmee de scores van elk van de klassen worden berekend. In de CIFAR10 gegevensset zijn er tien klassen labels. Het label met de hoogste score is degene die het model voorspelt. In de lineaire laag moet u het aantal invoerfuncties en het aantal uitvoerfuncties opgeven dat moet overeenkomen met het aantal klassen.
Hoe werkt een neuraal netwerk?
De CNN is een feed-forward-netwerk. Tijdens het trainingsproces verwerkt het netwerk de invoer door alle lagen, berekent het de fout om te begrijpen hoe ver het voorspelde label van de afbeelding afwijkt van het juiste, en geeft het de gradiënten terug door aan het netwerk om de gewichten van de lagen bij te werken. Door een enorme gegevensset met invoer te herhalen, leert het netwerk de gewichten ervan in te stellen om de beste resultaten te bereiken.
Een forward-functie berekent de waarde van de verliesfunctie en de backward-functie berekent de gradienten van de leerbare parameters. Wanneer u ons neurale netwerk maakt met PyTorch, hoeft u alleen de doorstuurfunctie te definiëren. De achterwaartse functie wordt automatisch gedefinieerd.
- Kopieer de volgende code naar het
PyTorchTraining.pybestand in Visual Studio om de CCN te definiëren.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Opmerking
Bent u geïnteresseerd in meer informatie over neuraal netwerk met PyTorch? Raadpleeg de PyTorch-documentatie
Een verliesfunctie definiëren
Een verliesfunctie berekent een waarde waarmee wordt geschat hoe ver de uitvoer zich van het doel bevindt. Het belangrijkste doel is om de waarde van de verliesfunctie te verminderen door de gewichtsvectorwaarden te wijzigen door middel van backpropagatie in neurale netwerken.
Verlieswaarde verschilt van modelnauwkeurigheid. Verliesfunctie geeft ons inzicht in hoe goed een model zich gedraagt na elke iteratie van optimalisatie in de trainingsset. De nauwkeurigheid van het model wordt berekend op de testgegevens en toont het percentage van de juiste voorspelling.
In PyTorch bevat het neurale netwerkpakket verschillende verliesfuncties die de bouwstenen van diepe neurale netwerken vormen. In deze zelfstudie gebruikt u een classificatieverliesfunctie op basis van De verliesfunctie definiëren met classificatieoverschrijdende entropieverlies en een Adam Optimizer. De leersnelheid (lr) bepaalt hoeveel u de gewichten van uw netwerk aanpast met betrekking tot de verliesgradiënt. U stelt deze in op 0,001. Hoe lager het is, hoe langzamer de training zal zijn.
- Kopieer de volgende code naar het
PyTorchTraining.pybestand in Visual Studio om de verliesfunctie en een optimalisatiefunctie te definiëren.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Train het model op de trainingsgegevens.
Als u het model wilt trainen, moet u onze gegevens-iterator doorlopen, de invoer invoeren in het netwerk en optimaliseren. PyTorch heeft geen toegewezen bibliotheek voor GPU-gebruik, maar u kunt het uitvoeringsapparaat handmatig definiëren. Het apparaat is een Nvidia GPU als het op uw computer aanwezig is, of uw CPU als dat niet het geval is.
- Voeg de volgende code toe aan het
PyTorchTraining.pybestand
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Test het model op de testgegevens.
Nu kunt u het model testen met batch afbeeldingen uit onze testset.
- Voeg de volgende code toe aan het bestand
PyTorchTraining.py.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Ten slotte gaan we de hoofdcode toevoegen. Hiermee wordt modeltraining gestart, het model opgeslagen en worden de resultaten op het scherm weergegeven. We voeren slechts twee iteraties [train(2)] uit via de trainingsset, dus het trainingsproces duurt niet te lang.
- Voeg de volgende code toe aan het bestand
PyTorchTraining.py.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
We gaan de test uitvoeren. Zorg ervoor dat de vervolgkeuzemenu’s in de bovenste balk zijn ingesteld op debuggen. Wijzig het Solution Platform in x64 om het project uit te voeren op uw lokale computer als uw apparaat 64-bits is of x86 als het 32-bits is.
Als u het aantal epochen kiest dat gelijk is aan twee ([train(2)]), wordt er twee keer over de volledige testdataset van 10.000 afbeeldingen gegaan. Het duurt ongeveer 20 minuten om de training op intel-CPU van de 8e generatie te voltooien en het model zou meer of minder 65% slagingspercentage moeten bereiken in de classificatie van tien labels.
- Als u het project wilt uitvoeren, klikt u op de knop Foutopsporing starten op de werkbalk of drukt u op F5.
Het consolevenster wordt weergegeven, en je kunt het trainingsproces zien.
Zoals u hebt gedefinieerd, wordt de verlieswaarde elke 1.000 batches van afbeeldingen weergegeven, of vijf keer voor elke iteratie over de trainingsset. U verwacht dat de verlieswaarde met elke lus afneemt.
Na elke iteratie ziet u ook de nauwkeurigheid van het model. De nauwkeurigheid van het model verschilt van de verlieswaarde. Verliesfunctie geeft ons inzicht in hoe goed een model zich gedraagt na elke iteratie van optimalisatie in de trainingsset. De nauwkeurigheid van het model wordt berekend op de testgegevens en toont het percentage van de juiste voorspelling. In ons geval wordt aangegeven hoeveel afbeeldingen uit de testset van 10.000 afbeeldingen ons model correct kon classificeren na elke trainingsiteratie.
Zodra de training is voltooid, zult u een uitvoer zien die vergelijkbaar is met de onderstaande. Uw getallen zijn niet precies hetzelfde, trianing is afhankelijk van veel factoren en retourneert niet altijd identificale resultaten, maar ze moeten er ongeveer als volgt uitzien.
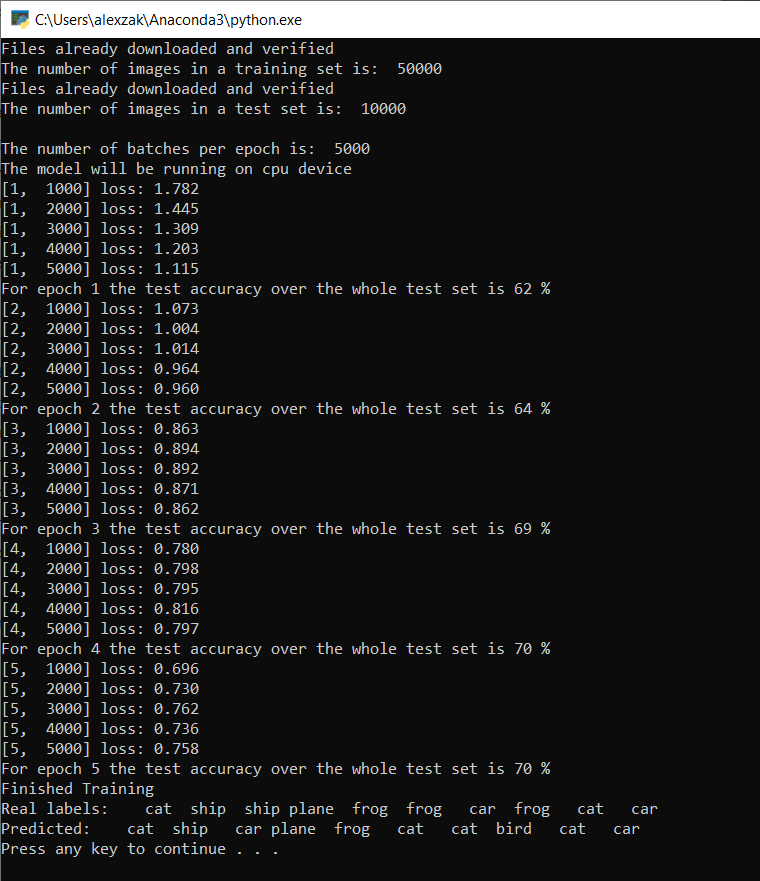
Na slechts 5 tijdvakken is het succespercentage van het model 70%. Dit is een goed resultaat voor een basismodel dat voor korte tijd is getraind!
Bij het testen met een batch van 10 afbeeldingen, heeft het model 7 afbeeldingen correct geïdentificeerd. Helemaal niet slecht en consistent met het succespercentage van het model.

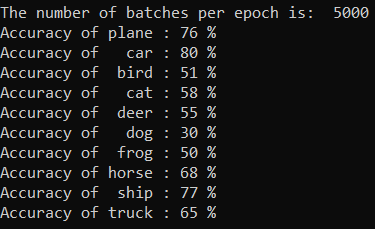
U kunt controleren welke klassen ons model het beste kan voorspellen. Voeg eenvoudig de onderstaande code toe en voer deze uit:
-
Optioneel : voeg de volgende
testClassessfunctie toe aan hetPyTorchTraining.pybestand, voeg een aanroep van deze functie toe -testClassess()binnen de hoofdfunctie -__name__ == "__main__".
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
De uitvoer is als volgt:
Volgende stappen
Nu we een classificatiemodel hebben, is de volgende stap het model converteren naar de ONNX-indeling