Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Opmerking
Voor meer functionaliteit kan PyTorch ook worden gebruikt met DirectML in Windows.
In de vorige fase van deze zelfstudie hebben we PyTorch op uw computer geïnstalleerd. Nu gebruiken we deze om onze code in te stellen met de gegevens die we gaan gebruiken om ons model te maken.
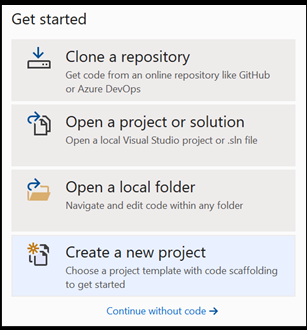
Open een nieuw project in Visual Studio.
- Open Visual Studio en kies
create a new project.
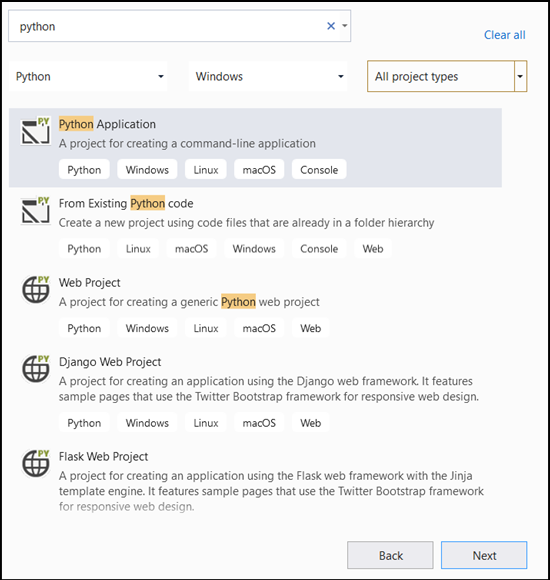
- Typ
Pythonen selecteerPython Applicationdeze in de zoekbalk als uw projectsjabloon.
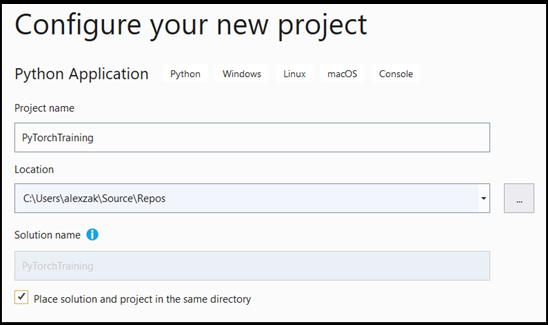
- In het configuratievenster:
- Geef uw project een naam. Hier noemen we het PyTorchTraining.
- Kies de locatie van uw project.
- Als u VS2019 gebruikt, zorg er dan voor dat
Create directory for solutionis ingeschakeld. - Als u VS 2017 gebruikt, zorg ervoor dat
Place solution and project in the same directoryniet is aangevinkt.
Druk create om uw project te maken.
Een Python-interpreter maken
Nu moet u een nieuwe Python-interpreter definiëren. Dit moet het PyTorch-pakket bevatten dat u onlangs hebt geïnstalleerd.
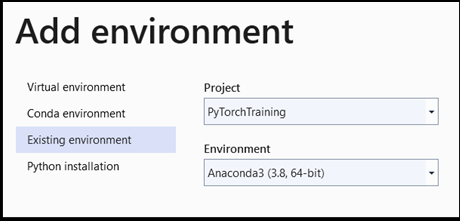
- Navigeer naar de selectie van de interpreter en selecteer
Add environment:

- Selecteer
Add environmenten kiesExisting environmentin hetAnaconda3 (3.6, 64-bit)venster. Dit omvat het PyTorch-pakket.
Als u het nieuwe Python-interpreter- en PyTorch-pakket wilt testen, voert u de volgende code in voor het PyTorchTraining.py bestand:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
De uitvoer moet een willekeurige 5x3-tensor zijn die vergelijkbaar is met de onderstaande.
Opmerking
Bent u geïnteresseerd in meer informatie? Bezoek de officiële website van PyTorch.
De gegevensset laden
U gebruikt de PyTorch-klasse torchvision om de gegevens te laden.
De Torchvision-bibliotheek bevat verschillende populaire gegevenssets, zoals Imagenet, CIFAR10, MNIST, enzovoort, modelarchitecturen en algemene afbeeldingstransformaties voor Computer Vision. Dat maakt het laden van gegevens in PyTorch heel eenvoudig.
CIFAR10
Hier gebruiken we de CIFAR10 gegevensset om het model voor afbeeldingsclassificatie te bouwen en te trainen. CIFAR10 is een veelgebruikte gegevensset voor machine learning-onderzoek. Het bestaat uit 50.000 trainingsafbeeldingen en 10.000 testafbeeldingen. Ze zijn allemaal van grootte 3x32x32, wat betekent dat 3-kanaals kleurenafbeeldingen van 32 x 32 pixels groot zijn.
De afbeeldingen zijn onderverdeeld in 10 klassen: 'vliegtuig' (0), 'auto' (1), 'vogel' (2), 'kat' (3) , 'herten' (4), 'hond' (5), 'kikker' (6), 'paard' (7), 'schip' (8), 'vrachtwagen' (9).
U volgt drie stappen om de CIFAR10 gegevensset in PyTorch te laden en te lezen:
- Definieer transformaties die moeten worden toegepast op de afbeelding: Als u het model wilt trainen, moet u de afbeeldingen transformeren naar Tensors van genormaliseerd bereik [-1,1].
- Maak een exemplaar van de beschikbare gegevensset en laad de gegevensset: als u de gegevens wilt laden, gebruikt u de
torch.utils.data.Datasetklasse: een abstracte klasse voor het weergeven van een gegevensset. De gegevensset wordt alleen lokaal gedownload wanneer u de code voor het eerst uitvoert. - Open de gegevens met behulp van de DataLoader. Als u de toegang tot de gegevens wilt krijgen en de gegevens in het geheugen wilt plaatsen, gebruikt u de
torch.utils.data.DataLoaderklasse. DataLoader in PyTorch verpakt een gegevensset en biedt toegang tot de onderliggende gegevens. Deze wrapper bevat batches met afbeeldingen volgens de gedefinieerde batchgrootte.
U herhaalt deze drie stappen voor zowel trainings- als testsets.
- Open de
PyTorchTraining.py filecode in Visual Studio en voeg de volgende code toe. Hiermee worden de drie bovenstaande stappen verwerkt voor de trainings- en testdatasets van de CIFAR10-dataset.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
De eerste keer dat u deze code uitvoert, wordt de CIFAR10 gegevensset naar uw apparaat gedownload.

Volgende stappen
Nu de gegevens klaar zijn, is het tijd om ons PyTorch-model te trainen