Samouczek REST: generowanie zawartości z możliwością wyszukiwania w usłudze Azure AI Search przy użyciu zestawów umiejętności
Z tego samouczka dowiesz się, jak wywoływać interfejsy API REST, które tworzą potok wzbogacania sztucznej inteligencji na potrzeby wyodrębniania i przekształcania zawartości podczas indeksowania.
Zestawy umiejętności dodają przetwarzanie sztucznej inteligencji do nieprzetworzonej zawartości, dzięki czemu zawartość będzie bardziej jednolita i będzie można wyszukiwać. Gdy już wiesz, jak działają zestawy umiejętności, możesz obsługiwać szeroką gamę przekształceń: od analizy obrazów po przetwarzanie języka naturalnego w celu dostosowania przetwarzania, które udostępniasz zewnętrznie.
Ten samouczek ułatwia zapoznanie się z następującymi instrukcjami:
- Zdefiniuj obiekty w potoku wzbogacania.
- Tworzenie zestawu umiejętności. Wywołaj rozpoznawanie znaków OCR, wykrywanie języka, rozpoznawanie jednostek i wyodrębnianie kluczowych fraz.
- Wykonaj potok. Tworzenie i ładowanie indeksu wyszukiwania.
- Sprawdź wyniki przy użyciu wyszukiwania pełnotekstowego.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem otwórz bezpłatne konto .
Omówienie
W tym samouczku użyto klienta REST i interfejsów API REST usługi Azure AI Search do utworzenia źródła danych, indeksu, indeksatora i zestawu umiejętności.
Indeksator napędza każdy krok w potoku, począwszy od wyodrębniania zawartości przykładowych danych (tekstu bez struktury i obrazów) w kontenerze obiektów blob w usłudze Azure Storage.
Po wyodrębnieniu zawartości zestaw umiejętności wykonuje wbudowane umiejętności od firmy Microsoft, aby znaleźć i wyodrębnić informacje. Te umiejętności obejmują optyczne rozpoznawanie znaków (OCR) na obrazach, wykrywanie języka tekstu, wyodrębnianie kluczowych fraz i rozpoznawanie jednostek (organizacje). Nowe informacje utworzone przez zestaw umiejętności są wysyłane do pól w indeksie. Po wypełnieniu indeksu można użyć pól w zapytaniach, aspektach i filtrach.
Wymagania wstępne
Uwaga
W tym samouczku możesz użyć bezpłatnej usługi wyszukiwania. Warstwa Bezpłatna ogranicza do trzech indeksów, trzech indeksatorów i trzech źródeł danych. W ramach tego samouczka tworzony jest jeden element każdego z tych typów. Przed rozpoczęciem upewnij się, że masz pokój w usłudze, aby zaakceptować nowe zasoby.
Pobieranie plików
Pobierz plik zip z przykładowego repozytorium danych i wyodrębnij zawartość. Dowiedz się, jak to zrobić.
Przekazywanie przykładowych danych do usługi Azure Storage
W usłudze Azure Storage utwórz nowy kontener i nadaj mu nazwę cog-search-demo.
Przekaż przykładowe pliki danych.
Uzyskaj parametry połączenia magazynu, aby można było sformułować połączenie w usłudze Azure AI Search.
Po lewej stronie wybierz pozycję Klucze dostępu.
Skopiuj parametry połączenia dla jednego lub drugiego klucza. Parametry połączenia jest podobny do następującego przykładu:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Usługi platformy Azure AI
Wbudowane wzbogacanie sztucznej inteligencji jest wspierane przez usługi Azure AI, w tym usługę językową i usługę Azure AI Vision na potrzeby przetwarzania języka naturalnego i obrazów. W przypadku małych obciążeń, takich jak w tym samouczku, możesz użyć bezpłatnej alokacji dwudziestu transakcji na indeksator. W przypadku większych obciążeń dołącz zasób usługi Azure AI Services w wielu regionach do zestawu umiejętności dla cennika z płatnością zgodnie z rzeczywistym użyciem.
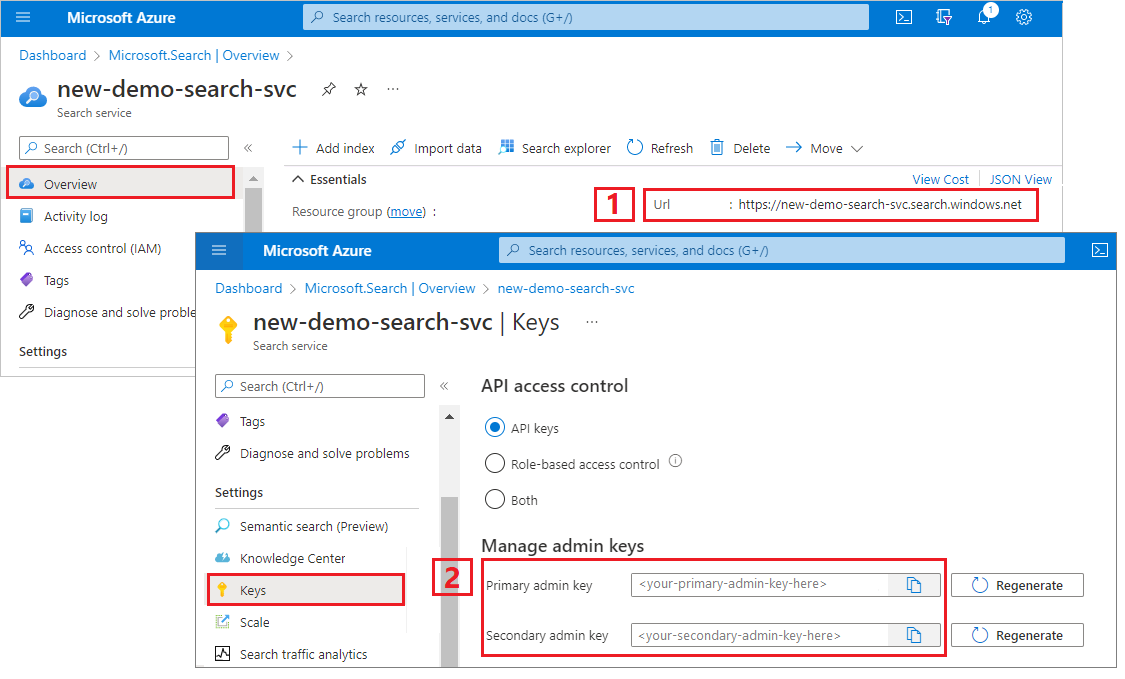
Kopiowanie adresu URL usługi wyszukiwania i klucza interfejsu API
Na potrzeby tego samouczka połączenia z usługą Azure AI Search wymagają punktu końcowego i klucza interfejsu API. Te wartości można uzyskać w witrynie Azure Portal.
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd usługi wyszukiwania i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Ustawienia> Keys skopiuj klucz administratora. Administracja klucze służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
Konfigurowanie pliku REST
Uruchom program Visual Studio Code i otwórz plik skillset-tutorial.rest . Zobacz Szybki start: wyszukiwanie tekstu przy użyciu interfejsu REST , jeśli potrzebujesz pomocy dotyczącej klienta REST.
Podaj wartości zmiennych: punkt końcowy usługi wyszukiwania, klucz interfejsu API administratora usługi wyszukiwania, nazwę indeksu, parametry połączenia do konta usługi Azure Storage i nazwę kontenera obiektów blob.
Tworzenie potoku
Wzbogacanie sztucznej inteligencji jest oparte na indeksatorze. Ta część przewodnika tworzy cztery obiekty: źródło danych, definicję indeksu, zestaw umiejętności, indeksator.
Krok 1. Tworzenie źródła danych
Wywołaj metodę Create Data Source (Utwórz źródło danych), aby ustawić parametry połączenia na kontener obiektów blob zawierający przykładowe pliki danych.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Krok 2. Tworzenie zestawu umiejętności
Wywołaj tworzenie zestawu umiejętności, aby określić, które kroki wzbogacania są stosowane do zawartości. Umiejętności są wykonywane równolegle, chyba że istnieje zależność.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Kluczowe punkty:
Treść żądania określa następujące wbudowane umiejętności:
Umiejętności opis Optyczne rozpoznawanie znaków Rozpoznaje tekst i liczby w plikach obrazów. Scalanie tekstu Tworzy "scaloną zawartość", która ponownie łączy wcześniej oddzieloną zawartość, przydatną w przypadku dokumentów z obrazami osadzonymi (PDF, DOCX itd.). Obrazy i tekst są oddzielane w fazie pękania dokumentu. Umiejętność scalania łączy je ponownie, wstawiając dowolny rozpoznany tekst, podpis obrazów lub tagi utworzone podczas wzbogacania do tej samej lokalizacji, z której obraz został wyodrębniony z dokumentu. Podczas pracy z scaloną zawartością w zestawie umiejętności ten węzeł zawiera cały tekst w dokumencie, w tym dokumenty tylko tekstowe, które nigdy nie są poddawane analizie OCR lub obrazów. Wykrywanie języka Wykrywa język i zwraca nazwę języka lub kod. W wielojęzycznych zestawach danych pole języka może być przydatne w przypadku filtrów. Rozpoznawanie jednostek Wyodrębnia nazwy osób, organizacji i lokalizacji z scalonej zawartości. Podział tekstu Dzieli dużą scaloną zawartość na mniejsze fragmenty przed wywołaniem umiejętności wyodrębniania kluczowych fraz. Umiejętność wyodrębniania fraz kluczowych przyjmuje dane wejściowe składające się maksymalnie z 50 000 znaków. Kilka przykładowych plików należy podzielić, aby zmieścić się w tym limicie. Wyodrębnianie kluczowych fraz Wyciąga najważniejsze kluczowe frazy. Każda umiejętność jest wykonywana dla zawartości dokumentu. Podczas przetwarzania usługa Azure AI Search pęka z każdego dokumentu w celu odczytu zawartości z różnych formatów plików. Tekst znaleziony w pliku źródłowym jest umieszczany w polu
contentgenerowanym pojedynczo dla każdego dokumentu. W związku z tym dane wejściowe stają się ."/document/content"W przypadku wyodrębniania kluczowych fraz, ponieważ używamy umiejętności dzielenia tekstu do dzielenia większych plików na strony, kontekstem umiejętności wyodrębniania kluczowych fraz jest
"document/pages/*"(dla każdej strony w dokumencie) zamiast"/document/content".
Uwaga
Dane wyjściowe można mapować na indeks i/lub używać ich jako danych wejściowych umiejętności podrzędnej — jak w przypadku kodu języka. W indeksie kod języka jest przydatny do filtrowania. Aby uzyskać więcej podstawowych informacji na temat zestawów umiejętności, zobacz Jak zdefiniować zestaw umiejętności.
Krok 3. Tworzenie indeksu
Wywołaj metodę Create Index (Utwórz indeks ), aby udostępnić schemat używany do tworzenia indeksów odwróconych i innych konstrukcji w usłudze Azure AI Search.
Największym składnikiem indeksu jest kolekcja pól, w której typ danych i atrybuty określają zawartość i zachowanie w usłudze Azure AI Search. Upewnij się, że masz pola dla nowo wygenerowanych danych wyjściowych.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Krok 4. Tworzenie i uruchamianie indeksatora
Wywołaj metodę Create Indexer , aby napędzać potok. Trzy składniki utworzone do tej pory (źródło danych, zestaw umiejętności, indeks) to dane wejściowe indeksatora. Tworzenie indeksatora w usłudze Azure AI Search to zdarzenie, które umieszcza cały potok w ruchu.
Wykonanie tego kroku może potrwać kilka minut. Mimo że zestaw danych jest mały, umiejętności analityczne wykorzystują znaczną moc obliczeniową.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Kluczowe punkty:
Treść żądania zawiera odwołania do poprzednich obiektów, właściwości konfiguracji wymagane do przetwarzania obrazów i dwa typy mapowań pól.
"fieldMappings"są przetwarzane przed zestawem umiejętności, wysyłając zawartość ze źródła danych do pól docelowych w indeksie. Mapowania pól służą do wysyłania istniejącej, niezmodyfikowanej zawartości do indeksu. Jeśli nazwy pól i typy są takie same na obu końcach, żadne mapowanie nie jest wymagane."outputFieldMappings"są przeznaczone dla pól utworzonych przez umiejętności po wykonaniu zestawu umiejętności. Odwołania dosourceFieldNamew programieoutputFieldMappingsnie istnieją, dopóki nie zostaną one utworzone przez pęknięcie dokumentu lub wzbogacenie. JesttargetFieldNameto pole w indeksie zdefiniowanym w schemacie indeksu.Parametr
"maxFailedItems"jest ustawiony na -1, co instruuje aparat indeksowania, aby ignorował błędy podczas importowania danych. Jest to dopuszczalne, ponieważ w źródle danych demonstracyjnych jest tak mało dokumentów. W przypadku większego źródła danych należy ustawić wartość większą od 0.Instrukcja
"dataToExtract":"contentAndMetadata"nakazuje indeksatorowi automatyczne wyodrębnianie wartości z właściwości zawartości obiektu blob i metadanych każdego obiektu.Parametr
imageActioninformuje indeksator o wyodrębnieniu tekstu z obrazów znalezionych w źródle danych. Konfiguracja"imageAction":"generateNormalizedImages", w połączeniu z umiejętnością OCR i umiejętnością scalania tekstu, wskazuje indeksatorowi, aby wyodrębniał tekst z obrazów (np. wyraz „stop” ze znaku drogowego Stop) i osadzał go jako część pola zawartości. To zachowanie dotyczy zarówno obrazów osadzonych (pomyśl o obrazie wewnątrz pliku PDF), jak i autonomicznych plikach obrazów, na przykład w pliku JPG.
Uwaga
Utworzenie indeksatora powoduje wywołanie potoku. Jeśli występują problemy z dostępem do danych, mapowaniem danych wejściowych i wyjściowych lub kolejnością operacji, pojawią się one na tym etapie. Aby ponownie uruchomić potok po zmianach kodu lub skryptu, może być konieczne uprzednie usunięcie obiektów. Aby uzyskać więcej informacji, zobacz Resetowanie i ponowne uruchamianie.
Monitorowanie indeksowania
Indeksowanie i wzbogacanie rozpoczyna się zaraz po przesłaniu żądania Tworzenia indeksatora. W zależności od złożoności i operacji zestawu umiejętności indeksowanie może zająć trochę czasu.
Aby dowiedzieć się, czy indeksator jest nadal uruchomiony, wywołaj metodę Pobierz stan indeksatora, aby sprawdzić stan indeksatora.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Kluczowe punkty:
Ostrzeżenia są typowe w niektórych scenariuszach i nie zawsze wskazują problem. Jeśli na przykład kontener obiektów blob zawiera pliki obrazów, a potok nie obsługuje obrazów, zostanie wyświetlone ostrzeżenie informujące, że obrazy nie zostały przetworzone.
W tym przykładzie istnieje plik PNG, który nie zawiera tekstu. Wszystkie pięć umiejętności opartych na tekście (wykrywanie języka, rozpoznawanie jednostek lokalizacji, organizacji, osób i wyodrębniania kluczowych fraz) nie może zostać wykonane w tym pliku. Wyświetlone powiadomienie zostanie wyświetlone w historii wykonywania.
Sprawdzanie wyników
Po utworzeniu indeksu zawierającego zawartość wygenerowaną przez sztuczną inteligencję wywołaj funkcję Search Documents , aby uruchomić kilka zapytań, aby wyświetlić wyniki.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filtry mogą ułatwić zawężenie wyników do interesujących elementów:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Te zapytania ilustrują kilka sposobów pracy ze składnią zapytań i filtrami w nowych polach utworzonych przez usługę Azure AI Search. Aby uzyskać więcej przykładów zapytań, zobacz Przykłady w interfejsie API REST dokumentów wyszukiwania, przykłady prostych zapytań składniowych i przykłady pełnych zapytań Lucene.
Resetowanie i ponowne uruchamianie
We wczesnych etapach opracowywania iteracja nad projektem jest powszechna. Resetowanie i ponowne uruchamianie ułatwia iterację.
Wnioski
W tym samouczku przedstawiono podstawowe kroki używania interfejsów API REST do tworzenia potoku wzbogacania sztucznej inteligencji: źródła danych, zestawu umiejętności, indeksu i indeksatora.
Wprowadzono wbudowane umiejętności wraz z definicją zestawu umiejętności , która pokazuje mechanikę łączenia umiejętności za pośrednictwem danych wejściowych i wyjściowych. Wiesz również, że outputFieldMappings w definicji indeksatora jest wymagany routing wzbogaconych wartości z potoku do indeksu z możliwością wyszukiwania w usługa wyszukiwania usługi Azure AI.
Ponadto przedstawiono sposób testowania wyników i resetowania systemu na potrzeby przyszłych iteracji. Omówiono proces, w ramach którego odpytanie indeksu powoduje zwrócenie danych wyjściowych utworzonych przez wzbogacony potok indeksowania.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w portalu i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Następne kroki
Teraz, gdy znasz już wszystkie obiekty w potoku wzbogacania sztucznej inteligencji, przyjrzyj się bliżej definicjom zestawu umiejętności i indywidualnym umiejętnościom.