Indeksatory w usłudze Azure AI Search
Indeksator w usłudze Azure AI Search to przeszukiwarka, która wyodrębnia dane tekstowe ze źródeł danych w chmurze i wypełnia indeks wyszukiwania przy użyciu mapowań między danymi źródłowymi a indeksem wyszukiwania. Takie podejście jest czasami określane jako "model ściągania", ponieważ usługa wyszukiwania ściąga dane bez konieczności pisania kodu, który dodaje dane do indeksu.
Indeksatory umożliwiają również wykonywanie zestawów umiejętności i wzbogacanie sztucznej inteligencji, gdzie można skonfigurować umiejętności w celu zintegrowania dodatkowego przetwarzania zawartości w drodze do indeksu. Oto kilka przykładów OCR na plikach obrazów, umiejętność dzielenia tekstu na fragmenty danych, tłumaczenie tekstu dla wielu języków.
Indeksatory są przeznaczone dla obsługiwanych źródeł danych. Konfiguracja indeksatora określa źródło danych (źródło) i indeks wyszukiwania (miejsce docelowe). Kilka źródeł, takich jak usługa Azure Blob Storage, ma więcej właściwości konfiguracji specyficznych dla tego typu zawartości.
Indeksatory można uruchamiać na żądanie lub według cyklicznego harmonogramu odświeżania danych, który jest uruchamiany nawet co pięć minut. Częstsze aktualizacje wymagają modelu wypychania , który jednocześnie aktualizuje dane w usłudze Azure AI Search i zewnętrznym źródle danych.
Usługa wyszukiwania uruchamia jedno zadanie indeksatora na jednostkę wyszukiwania. Jeśli potrzebujesz przetwarzania współbieżnego, upewnij się, że masz wystarczające repliki. Indeksatory nie działają w tle, więc możesz wykryć więcej ograniczania zapytań niż zwykle, jeśli usługa jest pod presją.
Scenariusze indeksatora i przypadki użycia
Indeksator można użyć jako jedynego środka pozyskiwania danych lub w połączeniu z innymi technikami. Poniższa tabela zawiera podsumowanie głównych scenariuszy.
| Scenariusz | Strategia |
|---|---|
| Pojedyncze źródło danych | Ten wzorzec jest najprostszy: jedno źródło danych jest jedynym dostawcą zawartości dla indeksu wyszukiwania. Większość obsługiwanych źródeł danych zapewnia pewną formę wykrywania zmian, dzięki czemu kolejne uruchomienia indeksatora pobierają różnicę podczas dodawania lub aktualizowania zawartości w źródle. |
| Wiele źródeł danych | Specyfikacja indeksatora może mieć tylko jedno źródło danych, ale sam indeks wyszukiwania może akceptować zawartość z wielu źródeł, w których każdy przebieg indeksatora przynosi nową zawartość od innego dostawcy danych. Każde źródło może współtworzyć udział pełnych dokumentów lub wypełnić wybrane pola w każdym dokumencie. Aby przyjrzeć się bliżej temu scenariuszowi, zobacz Samouczek: indeksowanie z wielu źródeł danych. |
| Wiele indeksatorów | Wiele źródeł danych jest zwykle sparowanych z wieloma indeksatorami, jeśli konieczne jest zmianę parametrów czasu wykonywania, harmonogramu lub mapowań pól. Skalowanie między regionami w poziomie usługi Azure AI Search to inny scenariusz. Być może masz kopie tego samego indeksu wyszukiwania w różnych regionach. Aby zsynchronizować zawartość indeksu wyszukiwania, można mieć wiele indeksatorów ściągających z tego samego źródła danych, gdzie każdy indeksator jest przeznaczony dla innego indeksu wyszukiwania w każdym regionie.Równoległe indeksowanie bardzo dużych zestawów danych wymaga również strategii wieloindeksatora, w której każdy indeksator jest przeznaczony dla podzbioru danych. |
| Przekształcanie zawartości | Indeksatory napędzają wykonywanie zestawu umiejętności i wzbogacanie sztucznej inteligencji. Przekształcenia zawartości są definiowane w zestawie umiejętności dołączanym do indeksatora. Możesz użyć umiejętności do uwzględnienia fragmentowania i wektoryzacji danych. |
Należy zaplanować utworzenie jednego indeksatora dla każdej kombinacji indeksu docelowego i źródła danych. Istnieje wiele indeksatorów zapisujących w tym samym indeksie i można ponownie użyć tego samego źródła danych dla wielu indeksatorów. Jednak indeksator może używać tylko jednego źródła danych jednocześnie i może zapisywać tylko w jednym indeksie. Jak pokazano na poniższej ilustracji, jedno źródło danych dostarcza dane wejściowe do jednego indeksatora, który następnie wypełnia pojedynczy indeks:

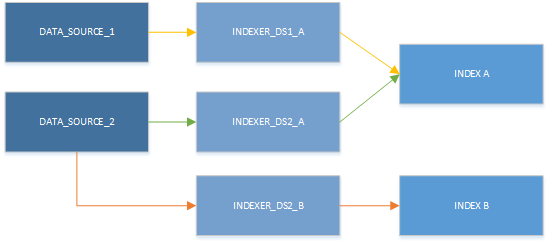
Chociaż jednocześnie można używać tylko jednego indeksatora, zasoby mogą być używane w różnych kombinacjach. Głównym wnioskiem z następnej ilustracji jest to, że źródło danych może być sparowane z więcej niż jednym indeksatorem, a wiele indeksatorów może zapisywać w tym samym indeksie.
Obsługiwane źródła danych
Indeksatory przeszukiwają magazyny danych na platformie Azure i poza platformą Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Wystąpienie zarządzane Azure SQL
- Program SQL Server na maszynach wirtualnych platformy Azure
- Azure Files (w wersji zapoznawczej)
- Azure MySQL (w wersji zapoznawczej)
- Program SharePoint na platformie Microsoft 365 (w wersji zapoznawczej)
- Usługa Azure Cosmos DB dla bazy danych MongoDB (w wersji zapoznawczej)
- Usługa Azure Cosmos DB dla języka Apache Gremlin (w wersji zapoznawczej)
Usługa Azure Cosmos DB dla bazy danych Cassandra nie jest obsługiwana.
Indeksatory akceptują spłaszczone zestawy wierszy, takie jak tabela lub widok, lub elementy w kontenerze lub folderze. W większości przypadków tworzy jeden dokument wyszukiwania dla każdego wiersza, rekordu lub elementu.
Połączenia indeksatora ze zdalnymi źródłami danych można nawiązać przy użyciu standardowych połączeń internetowych (publicznych) lub szyfrowanych połączeń prywatnych podczas korzystania z udostępnionego łącza prywatnego. Możesz również skonfigurować połączenia do uwierzytelniania przy użyciu tożsamości zarządzanej. Aby uzyskać więcej informacji na temat bezpiecznych połączeń, zobacz Indeksator dostępu do zawartości chronionej przez funkcje zabezpieczeń sieci platformy Azure i Połączenie do źródła danych przy użyciu tożsamości zarządzanej.
Etapy indeksowania
W początkowym uruchomieniu, gdy indeks jest pusty, indeksator odczytuje wszystkie dane podane w tabeli lub kontenerze. W kolejnych uruchomieniach indeksator zwykle może wykrywać i pobierać tylko zmienione dane. W przypadku danych obiektów blob wykrywanie zmian jest automatyczne. W przypadku innych źródeł danych, takich jak Azure SQL lub Azure Cosmos DB, należy włączyć wykrywanie zmian.
Dla każdego odbieranego dokumentu indeksator implementuje lub koordynuje wiele kroków, od pobierania dokumentu do końcowego "przekazywania" aparatu wyszukiwania na potrzeby indeksowania. Opcjonalnie indeksator również napędza wykonywanie zestawu umiejętności i dane wyjściowe, przy założeniu, że zestaw umiejętności jest zdefiniowany.

Etap 1. Pękanie dokumentów
Pękanie dokumentów to proces otwierania plików i wyodrębniania zawartości. Zawartość tekstowa może być wyodrębniona z plików w usłudze, wierszach w tabeli lub elementach w kontenerze lub kolekcji. Jeśli dodasz zestaw umiejętności i umiejętności dotyczące obrazów, cracking dokumentów może również wyodrębnić obrazy i umieścić je w kolejce do przetwarzania obrazów.
W zależności od źródła danych indeksator spróbuje wykonać różne operacje w celu wyodrębnienia potencjalnie indeksowalnej zawartości:
Gdy dokument jest plikiem z obrazami osadzonymi, takimi jak PDF, indeksator wyodrębnia tekst, obrazy i metadane. Indeksatory mogą otwierać pliki z usług Azure Blob Storage, Azure Data Lake Storage Gen2 i SharePoint.
Gdy dokument jest rekordem w usłudze Azure SQL, indeksator wyodrębni zawartość niebinarną z każdego pola w każdym rekordzie.
Gdy dokument jest rekordem w usłudze Azure Cosmos DB, indeksator wyodrębni zawartość niebinarną z pól i pól podrzędnych z dokumentu usługi Azure Cosmos DB.
Etap 2. Mapowania pól
Indeksator wyodrębnia tekst z pola źródłowego i wysyła go do pola docelowego w indeksie lub magazynie wiedzy. Gdy nazwy pól i typy danych zbiegają się, ścieżka jest jasna. Możesz jednak chcieć użyć różnych nazw lub typów w danych wyjściowych, w tym przypadku musisz poinformować indeksator, jak mapować pole.
Aby określić mapowania pól, wprowadź pola źródłowe i docelowe w definicji indeksatora.
Mapowanie pól występuje po pęknięciu dokumentu, ale przed przekształceniami, gdy indeksator odczytuje z dokumentów źródłowych. Podczas definiowania mapowania pól wartość pola źródłowego jest wysyłana jako do pola docelowego bez żadnych modyfikacji.
Etap 3. Wykonywanie zestawu umiejętności
Wykonywanie zestawu umiejętności to opcjonalny krok, który wywołuje wbudowane lub niestandardowe przetwarzanie sztucznej inteligencji. Zestawy umiejętności mogą dodawać optyczne rozpoznawanie znaków (OCR) lub inne formy analizy obrazów, jeśli zawartość jest binarna. Zestawy umiejętności mogą również dodawać przetwarzanie języka naturalnego. Można na przykład dodać tłumaczenie tekstu lub wyodrębnianie kluczowych fraz.
Niezależnie od transformacji, wykonywanie zestawu umiejętności jest miejscem, w którym występuje wzbogacanie. Jeśli indeksator jest potokiem, możesz traktować zestaw umiejętności jako "potok w potoku".
Etap 4. Mapowania pól wyjściowych
Jeśli dołączysz zestaw umiejętności, musisz określić mapowania pól wyjściowych w definicji indeksatora. Dane wyjściowe zestawu umiejętności są manifestowane wewnętrznie jako struktura drzewa nazywana wzbogaconym dokumentem. Mapowania pól wyjściowych umożliwiają wybranie części tego drzewa do mapowania na pola w indeksie.
Pomimo podobieństwa w nazwach mapowania pól wyjściowych i mapowań pól tworzą skojarzenia z różnych źródeł. Mapowania pól kojarzą zawartość pola źródłowego z polem docelowym w indeksie wyszukiwania. Mapowania pól wyjściowych kojarzą zawartość wewnętrznego wzbogaconego dokumentu (dane wyjściowe umiejętności) z polami docelowymi w indeksie. W przeciwieństwie do mapowań pól, które są uważane za opcjonalne, mapowanie pól wyjściowych jest wymagane dla każdej przekształconej zawartości, która powinna znajdować się w indeksie.
Następny obraz przedstawia przykładową sesję debugowania indeksatora przedstawiającą etapy indeksatora: pękanie dokumentów, mapowania pól, wykonywanie zestawu umiejętności i mapowania pól wyjściowych.

Podstawowy przepływ pracy
Indeksatory oferują funkcje, które są unikatowe dla źródła danych. W związku z tym niektóre aspekty konfiguracji indeksatora lub źródła danych różnią się w zależności od typu indeksatora. Wszystkie indeksatory korzystają jednak z takich samych kompozycji i wymagań. Kroki, które są wspólne dla wszystkich indeksatorów, znajdują się poniżej.
Krok 1. Tworzenie źródła danych
Indeksatory wymagają obiektu źródła danych, który udostępnia parametry połączenia i ewentualnie poświadczenia. Źródła danych są niezależnymi obiektami. Wiele indeksatorów może użyć tego samego obiektu źródła danych do załadowania więcej niż jednego indeksu jednocześnie.
Źródło danych można utworzyć przy użyciu dowolnego z następujących podejść:
- Korzystając z witryny Azure Portal, na karcie Źródła danych stron usługi wyszukiwania wybierz pozycję Dodaj źródło danych, aby określić definicję źródła danych.
- Za pomocą witryny Azure Portal kreator importu danych generuje źródło danych.
- Za pomocą interfejsów API REST wywołaj metodę Create Data Source (Tworzenie źródła danych).
- Za pomocą zestawu Azure SDK dla platformy .NET wywołaj klasę SearchIndexerDataSource Połączenie ion
Krok 2. Tworzenie indeksu
Indeksator automatyzuje niektóre zadania związane z pozyskiwaniem danych, ale tworzenie indeksu na ogół nie należy do tych zadań. W ramach wymagań wstępnych musisz mieć wstępnie zdefiniowany indeks zawierający odpowiednie pola docelowe dla dowolnych pól źródłowych w zewnętrznym źródle danych. Pola muszą być zgodne według nazwy i typu danych. Jeśli nie, możesz zdefiniować mapowania pól w celu ustanowienia skojarzenia.
Aby uzyskać więcej informacji, zobacz Tworzenie indeksu.
Krok 3. Tworzenie i uruchamianie (lub planowanie) indeksatora
Definicja indeksatora składa się z właściwości, które jednoznacznie identyfikują indeksator, określają źródło danych i indeks do użycia oraz udostępniają inne opcje konfiguracji wpływające na zachowania czasu wykonywania, w tym informacje o tym, czy indeksator działa na żądanie, czy zgodnie z harmonogramem.
Podczas wykonywania indeksatora wystąpią błędy lub ostrzeżenia dotyczące dostępu do danych lub weryfikacji zestawu umiejętności. Dopóki wykonywanie indeksatora nie zostanie uruchomione, obiekty zależne, takie jak źródła danych, indeksy i zestawy umiejętności, są pasywne w usłudze wyszukiwania.
Aby uzyskać więcej informacji, zobacz Tworzenie indeksatora
Po pierwszym uruchomieniu indeksatora można ponownie uruchomić go na żądanie lub skonfigurować harmonogram.
Stan indeksatora można monitorować w portalu lub za pomocą interfejsu API pobierania stanu indeksatora. Należy również uruchomić zapytania dotyczące indeksu , aby sprawdzić, czy wynik jest oczekiwany.
Indeksatory nie mają dedykowanych zasobów przetwarzania. W zależności od tego stan indeksatorów może być wyświetlany jako bezczynny przed uruchomieniem (w zależności od innych zadań w kolejce), a czasy wykonywania mogą nie być przewidywalne. Inne czynniki definiują również wydajność indeksatora, takie jak rozmiar dokumentu, złożoność dokumentu, analiza obrazów, między innymi.
Następne kroki
Po wprowadzeniu indeksatorów następnym krokiem jest przejrzenie właściwości i parametrów indeksatora, planowanie i monitorowanie indeksatora. Alternatywnie możesz wrócić do listy obsługiwanych źródeł danych, aby uzyskać więcej informacji na temat określonego źródła.