Najlepsze rozwiązania dotyczące korzystania z usługi Azure Data Lake Storage Gen2
Ten artykuł zawiera wskazówki dotyczące najlepszych rozwiązań, które ułatwiają optymalizowanie wydajności, obniżanie kosztów i zabezpieczanie konta usługi Azure Storage z obsługą usługi Azure Storage w usłudze Data Lake Storage Gen2.
Aby uzyskać ogólne sugestie dotyczące struktury magazynu data lake, zobacz następujące artykuły:
- Omówienie usługi Azure Data Lake Storage na potrzeby scenariusza zarządzania danymi i analizy
- Aprowizuj trzy konta usługi Azure Data Lake Storage Gen2 dla każdej strefy docelowej danych
Znajdź dokumentację
Usługa Azure Data Lake Storage Gen2 nie jest dedykowaną usługą ani typem konta. Jest to zestaw funkcji, które obsługują obciążenia analityczne o wysokiej przepływności. Dokumentacja usługi Data Lake Storage Gen2 zawiera najlepsze rozwiązania i wskazówki dotyczące korzystania z tych funkcji. Wszystkie inne aspekty zarządzania kontami, takie jak konfigurowanie zabezpieczeń sieci, projektowanie pod kątem wysokiej dostępności i odzyskiwanie po awarii, można znaleźć w dokumentacji usługi Blob Storage.
Ocena obsługi funkcji i znanych problemów
Użyj poniższego wzorca podczas konfigurowania konta do korzystania z funkcji usługi Blob Storage.
Zapoznaj się z artykułem Obsługa funkcji usługi Blob Storage na kontach usługi Azure Storage, aby określić, czy funkcja jest w pełni obsługiwana na twoim koncie. Niektóre funkcje nie są jeszcze obsługiwane lub mają częściową obsługę kont usługi Data Lake Storage Gen2. Obsługa funkcji jest zawsze rozszerzana, dlatego należy okresowo przeglądać ten artykuł pod kątem aktualizacji.
Zapoznaj się z artykułem Znane problemy z usługą Azure Data Lake Storage Gen2 , aby sprawdzić, czy istnieją jakiekolwiek ograniczenia lub specjalne wskazówki dotyczące funkcji, która ma być używana.
Przejrzyj artykuły dotyczące funkcji, aby uzyskać wskazówki specyficzne dla kont z włączoną usługą Data Lake Storage Gen2.
Omówienie terminów używanych w dokumentacji
Podczas przechodzenia między zestawami zawartości zauważysz niewielkie różnice w terminologii. Na przykład zawartość polecana w dokumentacji usługi Blob Storage będzie używać terminu blob zamiast pliku. Technicznie pliki pozyskiwane na konto magazynu stają się obiektami blob na twoim koncie. W związku z tym termin jest poprawny. Jednak termin blob może powodować nieporozumienie, jeśli używasz go do pliku terminowego. Zobaczysz również termin kontener używany do odwoływania się do systemu plików. Należy wziąć pod uwagę te terminy jako synonimy.
Rozważ użycie warstwy Premium
Jeśli obciążenia wymagają małego spójnego opóźnienia i/lub wymagają dużej liczby operacji wyjściowych wejściowych na sekundę (IOP), rozważ użycie konta magazynu blokowych obiektów blob w warstwie Premium. Ten typ konta udostępnia dane za pośrednictwem sprzętu o wysokiej wydajności. Dane są przechowywane na dyskach półprzewodnikowych (SSD), które są zoptymalizowane pod kątem małych opóźnień. Dyski SSD zapewniają większą przepływność w porównaniu z tradycyjnymi dyskami twardymi. Koszty magazynowania w warstwie Premium są wyższe, ale koszty transakcji są niższe. W związku z tym, jeśli obciążenia wykonują dużą liczbę transakcji, konto blokowych obiektów blob o wydajności w warstwie Premium może być ekonomiczne.
Jeśli twoje konto magazynu będzie używane do analizy, zdecydowanie zalecamy użycie usługi Azure Data Lake Storage Gen2 wraz z kontem magazynu blokowych obiektów blob w warstwie Premium. Ta kombinacja użycia kont magazynu blokowych obiektów blob w warstwie Premium wraz z kontem z włączoną usługą Data Lake Storage jest nazywana warstwą Premium dla usługi Azure Data Lake Storage.
Optymalizowanie pod kątem pozyskiwania danych
Pozyskiwanie danych z systemu źródłowego, sprzęt źródłowy, sprzęt sieci źródłowej lub łączność sieciowa z kontem magazynu może być wąskim gardłem.
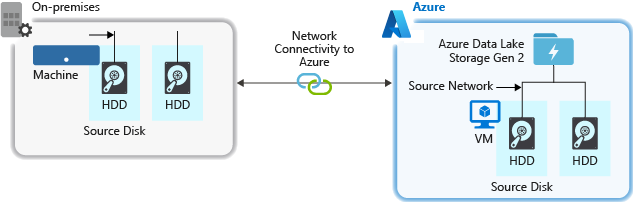
Sprzęt źródłowy
Niezależnie od tego, czy używasz maszyn lokalnych, czy maszyn wirtualnych na platformie Azure, pamiętaj, aby dokładnie wybrać odpowiedni sprzęt. W przypadku sprzętu dysku rozważ użycie dysków półprzewodnikowych (SSD) i wybierz sprzęt dyskowy, który ma szybsze wrzeciona. W przypadku sprzętu sieciowego użyj najszybszych kontrolerów interfejsu sieciowego (NIC), jak to możliwe. Na platformie Azure zalecamy maszyny wirtualne platformy Azure D14, które mają odpowiednio zaawansowany sprzęt dyskowy i sieciowy.
Łączność sieciowa z kontem magazynu
Łączność sieciowa między danymi źródłowymi a kontem magazynu może czasami być wąskim gardłem. Jeśli dane źródłowe są lokalne, rozważ użycie dedykowanego linku z usługą Azure ExpressRoute. Jeśli dane źródłowe są na platformie Azure, wydajność jest najlepsza, gdy dane są w tym samym regionie świadczenia usługi Azure co konto usługi Data Lake Storage Gen2.
Konfigurowanie narzędzi do pozyskiwania danych w celu uzyskania maksymalnej liczby równoległych
Aby uzyskać najlepszą wydajność, użyj całej dostępnej przepływności, wykonując dowolną liczbę operacji odczytu i zapisu równolegle.
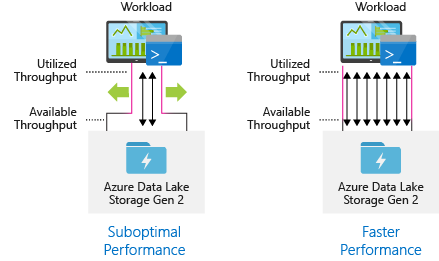
W poniższej tabeli przedstawiono podsumowanie kluczowych ustawień kilku popularnych narzędzi do pozyskiwania.
| Narzędzie | Ustawienia |
|---|---|
| DistCp | -m (maper) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (maper) |
Uwaga
Ogólna wydajność operacji pozyskiwania zależy od innych czynników, które są specyficzne dla narzędzia używanego do pozyskiwania danych. Aby uzyskać najlepsze aktualne wskazówki, zapoznaj się z dokumentacją dla każdego narzędzia, którego zamierzasz użyć.
Twoje konto może skalować w celu zapewnienia niezbędnej przepływności dla wszystkich scenariuszy analitycznych. Domyślnie konto z włączoną usługą Data Lake Storage Gen2 zapewnia wystarczającą przepływność w domyślnej konfiguracji, aby zaspokoić potrzeby szerokiej kategorii przypadków użycia. Jeśli napotkasz domyślny limit, konto można skonfigurować w celu zapewnienia większej przepływności, kontaktując się z pomocą techniczną platformy Azure.
Zestawy danych struktury
Rozważ wstępne planowanie struktury danych. Format pliku, rozmiar pliku i struktura katalogu mogą mieć wpływ na wydajność i koszty.
Formaty plików
Dane można pozyskiwać w różnych formatach. Dane mogą być wyświetlane w formatach czytelnych dla człowieka, takich jak JSON, CSV lub XML albo jako skompresowane formaty binarne, takie jak .tar.gz. Dane mogą również mieć różne rozmiary. Dane mogą składać się z dużych plików (kilka terabajtów), takich jak dane z eksportu tabeli SQL z systemów lokalnych. Dane mogą również pochodzić z dużej liczby małych plików (kilka kilobajtów), takich jak dane ze zdarzeń w czasie rzeczywistym z rozwiązania Internetu rzeczy (IoT). Wydajność i koszty można zoptymalizować, wybierając odpowiedni format pliku i rozmiar pliku.
Usługa Hadoop obsługuje zestaw formatów plików zoptymalizowanych pod kątem przechowywania i przetwarzania danych strukturalnych. Niektóre typowe formaty to Format Avro, Parquet i Optimized Row Columnar (ORC). Wszystkie te formaty to formaty plików binarnych z możliwością odczytu maszynowego. Są one kompresowane, aby ułatwić zarządzanie rozmiarem pliku. Mają one schemat osadzony w każdym pliku, co sprawia, że są one samoopisujące. Różnica między tymi formatami polega na sposobie przechowywania danych. Avro przechowuje dane w formacie opartym na wierszach, a formaty Parquet i ORC przechowują dane w formacie kolumnowym.
Rozważ użycie formatu pliku Avro w przypadkach, w których wzorce we/wy są bardziej duże, lub wzorce zapytań faworyzują pobieranie wielu wierszy rekordów w całości. Na przykład format Avro działa dobrze z magistralą komunikatów, taką jak Event Hubs lub Kafka, która zapisuje wiele zdarzeń/komunikatów z rzędu.
Należy wziąć pod uwagę formaty plików Parquet i ORC, gdy wzorce we/wy są bardziej czytelne lub gdy wzorce zapytań koncentrują się na podzestawie kolumn w rekordach. Transakcje odczytu można zoptymalizować w celu pobrania określonych kolumn zamiast odczytywania całego rekordu.
Apache Parquet to format plików typu open source zoptymalizowany pod kątem potoków analizy ciężkiej do odczytu. Struktura magazynu kolumnowego parquet umożliwia pomijanie danych, które nie są istotne. Zapytania są znacznie bardziej wydajne, ponieważ mogą wąsko określać zakres danych wysyłanych z magazynu do aparatu analitycznego. Ponadto, ponieważ podobne typy danych (dla kolumny) są przechowywane razem, Parquet obsługuje wydajne schematy kompresji i kodowania danych, które mogą obniżyć koszty magazynowania danych. Usługi takie jak Azure Synapse Analytics, Azure Databricks i Azure Data Factory mają natywne funkcje, które korzystają z formatów plików Parquet.
Rozmiar pliku
Większe pliki prowadzą do lepszej wydajności i obniżenia kosztów.
Zazwyczaj aparaty analityczne, takie jak USŁUGA HDInsight, mają obciążenie związane z zadaniami, takimi jak wyświetlanie listy, sprawdzanie dostępu i wykonywanie różnych operacji metadanych. Jeśli przechowujesz dane jak najwięcej małych plików, może to negatywnie wpłynąć na wydajność. Ogólnie rzecz biorąc, pogrupuj dane w większe pliki, aby uzyskać lepszą wydajność (od 256 MB do 100 GB rozmiaru). Niektóre aparaty i aplikacje mogą mieć problemy z wydajnym przetwarzaniem plików o rozmiarze większym niż 100 GB.
Zwiększenie rozmiaru pliku może również zmniejszyć koszty transakcji. Operacje odczytu i zapisu są rozliczane w 4 megabajtach, więc opłaty są naliczane za operację niezależnie od tego, czy plik zawiera 4 megabajty, czy tylko kilka kilobajtów. Aby uzyskać informacje o cenach, zobacz Cennik usługi Azure Data Lake Storage.
Czasami potoki danych mają ograniczoną kontrolę nad danymi nieprzetworzonymi, które mają wiele małych plików. Ogólnie rzecz biorąc, zalecamy, aby system miał jakiś proces agregowania małych plików w większe do użytku przez aplikacje podrzędne. Jeśli przetwarzasz dane w czasie rzeczywistym, możesz użyć aparatu przesyłania strumieniowego w czasie rzeczywistym (takiego jak usługa Azure Stream Analytics lub Spark Streaming) razem z brokerem komunikatów (takim jak Event Hubs lub Apache Kafka), aby przechowywać dane jako większe pliki. W miarę agregowania małych plików do większych rozważ zapisanie ich w formacie zoptymalizowanym pod kątem odczytu, takim jak Apache Parquet na potrzeby przetwarzania podrzędnego.
Struktura katalogów
Każde obciążenie ma inne wymagania dotyczące sposobu korzystania z danych, ale są to niektóre typowe układy, które należy wziąć pod uwagę podczas pracy z Internetem rzeczy (IoT), scenariuszami wsadowymi lub optymalizacją danych szeregów czasowych.
Struktura IoT
W przypadku obciążeń IoT może istnieć wiele pozyskiwanych danych obejmujących wiele produktów, urządzeń, organizacji i klientów. Ważne jest, aby wstępnie zaplanować układ katalogu dla organizacji, zabezpieczeń i wydajnego przetwarzania danych dla odbiorców strumienia w dół. Ogólny szablon do rozważenia może mieć następujący układ:
- {Region}/{SubjectMatter(s)}/{rrrr}/{mm}/{dd}/{hh}/
Na przykład dane telemetryczne lądowania silnika samolotu w Wielkiej Brytanii mogą wyglądać podobnie do następującej struktury:
- Uk/Planes/BA1293/Engine1/2017/08/11/12/
W tym przykładzie, umieszczając datę na końcu struktury katalogów, można użyć list ACL, aby łatwiej zabezpieczyć regiony i kwestie dotyczące określonych użytkowników i grup. Jeśli na początku umieścisz strukturę dat, znacznie trudniej byłoby zabezpieczyć te regiony i kwestie. Jeśli na przykład chcesz zapewnić dostęp tylko do danych Brytyjskich lub niektórych samolotów, musisz zastosować oddzielne uprawnienie dla wielu katalogów w ramach każdego katalogu godzin. Ta struktura również wykładniczo zwiększyłaby liczbę katalogów w miarę upływu czasu.
Struktura zadań wsadowych
Powszechnie stosowane podejście do przetwarzania wsadowego polega na umieszczaniu danych w katalogu "in". Następnie, po przetworzeniu danych, umieść nowe dane w katalogu "out" dla procesów podrzędnych do użytku. Ta struktura katalogów jest czasami używana w przypadku zadań wymagających przetwarzania poszczególnych plików i może nie wymagać masowego przetwarzania równoległego w dużych zestawach danych. Podobnie jak zalecana powyżej struktura IoT, dobra struktura katalogów zawiera katalogi na poziomie nadrzędnym dla takich rzeczy jak region i zagadnienia (na przykład organizacja, produkt lub producent). Rozważ datę i godzinę w strukturze, aby umożliwić lepszą organizację, przefiltrowane wyszukiwania, zabezpieczenia i automatyzację w przetwarzaniu. Poziom szczegółowości struktury daty zależy od interwału, w którym dane są przekazywane lub przetwarzane, na przykład co godzinę, codziennie, a nawet co miesiąc.
Czasami przetwarzanie plików kończy się niepowodzeniem z powodu uszkodzenia danych lub nieoczekiwanych formatów. W takich przypadkach struktura katalogów może skorzystać z folderu /bad , aby przenieść pliki do w celu dalszej inspekcji. Zadanie wsadowe może również obsługiwać raportowanie lub powiadamianie o tych nieprawidłowych plikach w celu ręcznej interwencji. Rozważ następującą strukturę szablonu:
- {Region}/{SubjectMatter(s)}/In/{rrrr}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{rrrr}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{rrrr}/{mm}/{dd}/{hh}/
Na przykład firma marketingowa odbiera codzienne dane z aktualizacji klientów z Ameryka Północna. Może to wyglądać podobnie do poniższego fragmentu kodu przed przetworzeniem i po jego przetworzeniu:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
W typowym przypadku przetwarzania danych wsadowych bezpośrednio do baz danych, takich jak Hive lub tradycyjne bazy danych SQL, nie ma potrzeby katalogu /in lub /out , ponieważ dane wyjściowe są już przekazywane do oddzielnego folderu dla tabeli Hive lub zewnętrznej bazy danych. Na przykład codzienne wyciągi z klientów wylądowałyby w odpowiednich katalogach. Następnie usługa, taka jak Azure Data Factory, Apache Oozie lub Apache Airflow , wyzwoli codzienne zadanie Hive lub Spark w celu przetworzenia i zapisania danych w tabeli Hive.
Struktura danych szeregów czasowych
W przypadku obciążeń Hive oczyszczanie partycji danych szeregów czasowych może pomóc niektórym zapytaniom w odczytywaniu tylko podzestawu danych, co zwiększa wydajność.
Te potoki, które pozyskują dane szeregów czasowych, często umieszczają pliki ze strukturą nazewnictwa plików i folderów. Poniżej przedstawiono typowy przykład dotyczący danych ustrukturyzowanych według daty:
/DataSet/RRRR/MM/DD/datafile_YYYY_MM_DD.tsv
Zwróć uwagę, że informacje o dacie/godziny są wyświetlane zarówno jako foldery, jak i nazwa pliku.
W przypadku daty i godziny następujący wzorzec jest typowy
/DataSet/RRRR/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Ponownie wybór w organizacji folderów i plików powinien być zoptymalizowany pod kątem większych rozmiarów plików i rozsądnej liczby plików w każdym folderze.
Konfigurowanie zabezpieczeń
Zacznij od zapoznania się z zaleceniami w artykule Zalecenia dotyczące zabezpieczeń dla usługi Blob Storage . Znajdziesz wskazówki dotyczące najlepszych rozwiązań dotyczących ochrony danych przed przypadkowym lub złośliwym usunięciem, zabezpieczaniem danych za zaporą i używaniem identyfikatora Entra firmy Microsoft jako podstawy zarządzania tożsamościami.
Następnie zapoznaj się z artykułem Model kontroli dostępu w usłudze Azure Data Lake Storage Gen2 , aby uzyskać wskazówki specyficzne dla kont z obsługą usługi Data Lake Storage Gen2. Ten artykuł pomaga zrozumieć, jak używać ról kontroli dostępu na podstawie ról (RBAC) platformy Azure wraz z listami kontroli dostępu (ACL) w celu wymuszania uprawnień zabezpieczeń do katalogów i plików w hierarchicznym systemie plików.
Pozyskiwanie, przetwarzanie i analizowanie
Istnieje wiele różnych źródeł danych i różnych sposobów pozyskiwania tych danych na koncie z włączoną usługą Data Lake Storage Gen2.
Na przykład można pozyskiwać duże zestawy danych z klastrów hdInsight i Hadoop lub mniejszych zestawów danych ad hoc na potrzeby tworzenia prototypów aplikacji. Można pozyskiwać strumieniowo dane generowane przez różne źródła, takie jak aplikacje, urządzenia i czujniki. W przypadku tego typu danych możesz użyć narzędzi do przechwytywania i przetwarzania danych na podstawie zdarzenia w czasie rzeczywistym, a następnie zapisywania zdarzeń w partiach na koncie. Można również pozyskiwać dzienniki serwera internetowego, które zawierają informacje, takie jak historia żądań stron. W przypadku danych dzienników rozważ napisanie niestandardowych skryptów lub aplikacji w celu ich przekazania, aby zapewnić elastyczność dołączania składnika przekazywania danych w ramach większej aplikacji danych big data.
Gdy dane będą dostępne na twoim koncie, możesz uruchomić analizę tych danych, utworzyć wizualizacje, a nawet pobrać dane na komputer lokalny lub do innych repozytoriów, takich jak baza danych Azure SQL Database lub wystąpienie programu SQL Server.
W poniższej tabeli przedstawiono narzędzia, których można użyć do pozyskiwania, analizowania, wizualizowania i pobierania danych. Skorzystaj z linków w tej tabeli, aby znaleźć wskazówki dotyczące konfigurowania i używania poszczególnych narzędzi.
Uwaga
Ta tabela nie odzwierciedla pełnej listy usług platformy Azure, które obsługują usługę Data Lake Storage Gen2. Aby wyświetlić listę obsługiwanych usług platformy Azure, ich poziom pomocy technicznej, zobacz Usługi platformy Azure, które obsługują usługę Azure Data Lake Storage Gen2.
Monitorowanie telemetrii
Monitorowanie użycia i wydajności jest ważną częścią operacjonalizacji usługi. Przykłady obejmują częste operacje, operacje z dużym opóźnieniem lub operacjami, które powodują ograniczanie przepustowości po stronie usługi.
Wszystkie dane telemetryczne dla konta magazynu są dostępne za pośrednictwem dzienników usługi Azure Storage w usłudze Azure Monitor. Ta funkcja integruje konto magazynu z usługami Log Analytics i Event Hubs, a jednocześnie umożliwia archiwizowanie dzienników na innym koncie magazynu. Aby wyświetlić pełną listę metryk i dzienników zasobów oraz skojarzony ze nimi schemat, zobacz Dokumentacja danych monitorowania usługi Azure Storage.
Miejsce, w którym chcesz przechowywać dzienniki, zależy od tego, jak planujesz uzyskać do nich dostęp. Jeśli na przykład chcesz uzyskać dostęp do dzienników niemal w czasie rzeczywistym i mieć możliwość korelowania zdarzeń w dziennikach z innymi metrykami z usługi Azure Monitor, możesz przechowywać dzienniki w obszarze roboczym usługi Log Analytics. Następnie wykonaj zapytania dotyczące dzienników przy użyciu języka KQL i zapytań autorów, które wyliczają tabelę StorageBlobLogs w obszarze roboczym.
Jeśli chcesz przechowywać dzienniki zarówno dla zapytań niemal w czasie rzeczywistym, jak i długoterminowego przechowywania, możesz skonfigurować ustawienia diagnostyczne, aby wysyłać dzienniki zarówno do obszaru roboczego usługi Log Analytics, jak i konta magazynu.
Jeśli chcesz uzyskać dostęp do dzienników za pośrednictwem innego aparatu zapytań, takiego jak Splunk, możesz skonfigurować ustawienia diagnostyczne, aby wysyłać dzienniki do centrum zdarzeń i pozyskiwać dzienniki z centrum zdarzeń do wybranego miejsca docelowego.
Dzienniki usługi Azure Storage w usłudze Azure Monitor można włączyć za pośrednictwem witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia platformy Azure i szablonów usługi Azure Resource Manager. W przypadku wdrożeń na dużą skalę można używać usługi Azure Policy z pełną obsługą zadań korygowania. Aby uzyskać więcej informacji, zobacz ciphertxt/AzureStoragePolicy.