Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Ambari to interfejs internetowy do zarządzania klastrami usługi HDInsight i monitorowania ich. Aby zapoznać się z wprowadzeniem do internetowego interfejsu użytkownika systemu Ambari, zobacz Manage HDInsight clusters by using the Apache Ambari Web UI (Zarządzanie klastrami usługi HDInsight przy użyciu internetowego interfejsu użytkownika systemu Apache Ambari).
W poniższych sekcjach opisano opcje konfiguracji służące do optymalizowania ogólnej wydajności oprogramowania Apache Hive.
- Aby zmodyfikować parametry konfiguracji programu Hive, wybierz pozycję Hive na pasku bocznym Usługi.
- Przejdź do karty Konfiguracje .
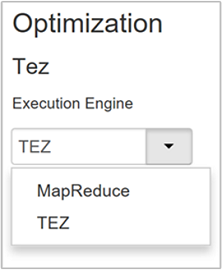
Ustaw silnik wykonawczy Hive
Usługa Hive udostępnia dwa silniki wykonawcze: Apache Hadoop MapReduce i Apache TEZ. Tez jest szybszy niż MapReduce. Klastry HDInsight z systemem Linux mają Tez jako domyślny silnik wykonawczy. Aby zmienić silnik wykonawczy:
Na karcie Konfiguracje programu Hive wpisz silnik wykonawczy w polu filtrowania.
Wartość domyślna właściwości Optimization to Tez.
Konfiguracja maperów
Usługa Hadoop próbuje podzielić (mapować) pojedynczy plik na wiele plików i przetworzyć wynikowe pliki równolegle. Liczba mapujących zależy od liczby podziałów. Następujące dwa parametry konfiguracji określają liczbę podziałów dla silnika wykonawczego Tez:
-
tez.grouping.min-size: Dolny limit rozmiaru grupowanego podziału, z domyślną wartością 16 MB (16,777,216 bajtów). -
tez.grouping.max-size: Górny limit rozmiaru pogrupowanego podziału z wartością domyślną 1 GB (1 073 741 824 bajtów).
W ramach wytycznych dotyczących wydajności obniż oba te parametry, aby zmniejszyć opóźnienia, zwiększ je, aby zwiększyć przepływność.
Aby na przykład ustawić cztery zadania mapowania dla rozmiaru danych o rozmiarze 128 MB, należy ustawić oba parametry na 32 MB każdy (33 554 432 bajty).
Aby zmodyfikować parametry limitu, przejdź do karty Konfiguracje usługi Tez. Rozwiń panel Ogólne i znajdź parametry
tez.grouping.max-sizeoraztez.grouping.min-size.Ustaw oba parametry na 33 554 432 bajty (32 MB).

Te zmiany wpływają na wszystkie zadania Tez na serwerze. Aby uzyskać optymalny wynik, wybierz odpowiednie wartości parametrów.
Reduktory dostrajania
Zarówno apache ORC, jak i Snappy oferują wysoką wydajność. Jednak Hive może mieć domyślnie zbyt małą liczbę reduktorów, co powoduje wąskie gardła.
Załóżmy na przykład, że masz rozmiar danych wejściowych o rozmiarze 50 GB. Te dane w formacie ORC z kompresją Snappy wynoszą 1 GB. Hive szacuje wymaganą liczbę reduktorów w następujący sposób: (liczba bajtów wejściowych (do maperów) / hive.exec.reducers.bytes.per.reducer).
W przypadku ustawień domyślnych ten przykład to cztery reduktory.
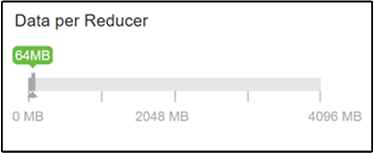
Parametr hive.exec.reducers.bytes.per.reducer określa liczbę bajtów przetworzonych dla każdego reduktora. Wartość domyślna to 64 MB. Dostrajanie tej wartości w dół zwiększa równoległość i może zwiększyć wydajność. Zbyt niskie dostrojenie może również spowodować powstawanie zbyt wielu reduktorów, co potencjalnie może negatywnie wpływać na wydajność. Ten parametr jest oparty na konkretnych wymaganiach dotyczących danych, ustawieniach kompresji i innych czynnikach środowiskowych.
Aby zmodyfikować parametr, przejdź do karty Konfiguracje programu Hive i znajdź parametr Data per Reducer na stronie Ustawienia.
Wybierz pozycję Edytuj , aby zmodyfikować wartość na 128 MB (134 217 728 bajtów), a następnie naciśnij Enter , aby zapisać.
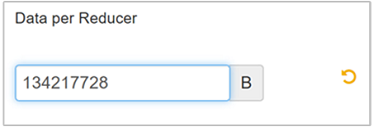
Biorąc pod uwagę rozmiar wejściowy 1024 MB, z 128 MB danych na reduktor, istnieje osiem reduktorów (1024/128).
Nieprawidłowa wartość parametru Data per Reducer może spowodować dużą liczbę reduktorów, co negatywnie wpływa na wydajność zapytań. Aby ograniczyć maksymalną liczbę reduktorów, ustaw wartość
hive.exec.reducers.maxna odpowiednią. Wartość domyślna to 1009.
Włącz równoległe wykonywanie
Zapytanie Hive jest wykonywane w co najmniej jednym etapie. Jeśli niezależne etapy mogą być uruchamiane równolegle, zwiększy to wydajność zapytań.
Aby włączyć równoległe wykonywanie zapytań, przejdź do karty Konfiguracja programu Hive i wyszukaj
hive.exec.parallelwłaściwość . Wartość domyślna to false. Zmień wartość na true, a następnie naciśnij Enter , aby zapisać wartość.Aby ograniczyć liczbę zadań do uruchomienia równolegle, zmodyfikuj
hive.exec.parallel.thread.numberwłaściwość . Wartość domyślna to 8.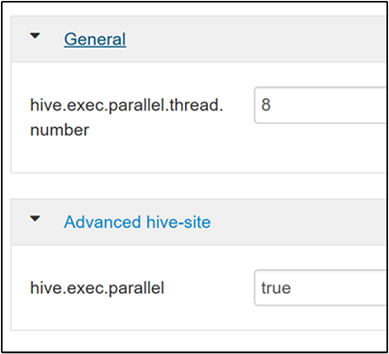
Włączanie wektoryzacji
Hive przetwarza dane wiersz po wierszu. Wektoryzacja kieruje hive do przetwarzania danych w blokach 1024 wierszy, a nie jednego wiersza jednocześnie. Wektoryzacja ma zastosowanie tylko do formatu pliku ORC.
Aby włączyć wektoryzowane wykonywanie zapytania, przejdź do karty Konfiguracje programu Hive i wyszukaj
hive.vectorized.execution.enabledparametr . Wartość domyślna ma wartość true dla programu Hive 0.13.0 lub nowszego.Aby włączyć wektoryzowane wykonywanie po stronie redukcji zapytania, ustaw
hive.vectorized.execution.reduce.enabledparametr na true. Wartość domyślna to false.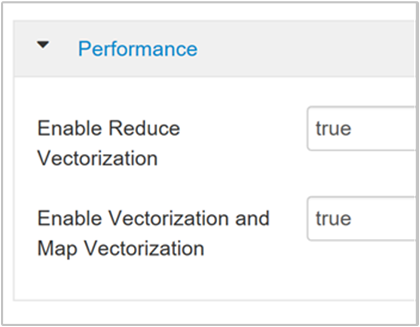
Włączanie optymalizacji opartej na kosztach (CBO)
Domyślnie Hive stosuje zestaw reguł, aby znaleźć optymalny plan wykonania zapytania. Optymalizacja oparta na kosztach (CBO) ocenia wiele planów w celu wykonania zapytania. I przypisuje koszt do każdego planu, a następnie określa najtańszy plan do wykonania zapytania.
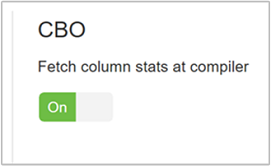
Aby włączyć funkcję CBO, przejdź dopozycji Ustawieniakonfiguracji>programu Hive> i znajdź pozycję Włącz optymalizator oparty na kosztach, a następnie przełącz przycisk przełącznika na Wł.

Następujące dodatkowe parametry konfiguracji zwiększają wydajność zapytań hive po włączeniu CBO:
hive.compute.query.using.statsW przypadku ustawienia wartości true program Hive używa statystyk przechowywanych w magazynie metadanych, aby odpowiedzieć na proste zapytania, takie jak
count(*).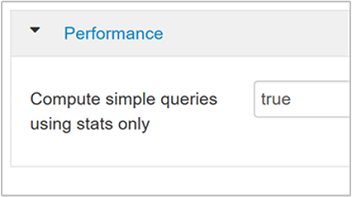
hive.stats.fetch.column.statsStatystyki kolumn są tworzone po włączeniu funkcji CBO. Usługa Hive używa statystyk kolumn, które są przechowywane w magazynie metadanych, aby zoptymalizować zapytania. Pobieranie statystyk kolumn dla każdej kolumny trwa dłużej, gdy liczba kolumn jest wysoka. Po ustawieniu wartości false to ustawienie wyłącza pobieranie statystyk kolumn z magazynu metadanych.
hive.stats.fetch.partition.statsPodstawowe statystyki partycji, takie jak liczba wierszy, rozmiar danych i rozmiar pliku, są przechowywane w magazynie metadanych. Jeśli ustawiono wartość true, statystyki partycji są pobierane z magazynu metadanych. W przypadku wartości false rozmiar pliku jest pobierany z systemu plików. Liczba wierszy jest uzyskiwana ze struktury wiersza.
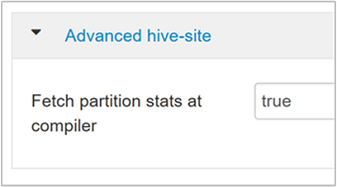
Aby uzyskać więcej informacji, zapoznaj się z wpisem na blogu optymalizacji opartej na kosztach w Hive na Blogu o analizach na platformie Azure.
Włącz kompresję pośrednią
Zadania mapy tworzą pliki pośrednie, które są wykorzystywane przez zadania reduktora. Kompresja pośrednia zmniejsza rozmiar pliku pośredniego.
Zadania Hadoop zazwyczaj napotykają ograniczenia w zakresie wejścia/wyjścia. Kompresowanie danych może przyspieszyć we/wy i ogólny transfer sieciowy.
Dostępne typy kompresji to:
| Forma | Narzędzie | Algorytm | Rozszerzenie pliku | Podzielny? |
|---|---|---|---|---|
| Gzip | Gzip | algorytm kompresji DEFLATE | .gz |
Nie. |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Tak |
| LZO | Lzop |
LZO | .lzo |
Tak, jeśli indeksowane |
| Żwawy | N/A | Żwawy | Żwawy | Nie. |
Ogólnie rzecz biorąc, możliwość podziału metody kompresji jest ważna, w przeciwnym razie mniej maperów zostanie utworzonych. Jeśli dane wejściowe są tekstowe, bzip2 jest najlepszą opcją. W przypadku formatu ORC snappy jest najszybszą opcją kompresji.
Aby włączyć kompresję pośrednią, przejdź do karty Konfiguracje programu Hive, a następnie ustaw
hive.exec.compress.intermediateparametr na wartość true. Wartość domyślna to false.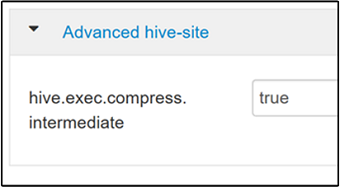
Uwaga
Aby skompresować pliki pośrednie, wybierz koder kompresji z niższym kosztem procesora, nawet jeśli nie oferuje on wysokiej kompresji wyjściowej.
Aby ustawić pośredni kodek kompresji, dodaj niestandardową właściwość
mapred.map.output.compression.codecdo plikuhive-site.xmllubmapred-site.xml.Aby dodać ustawienie niestandardowe:
a. Przejdź do Hive>Configs>Advanced>Custom hive-site.
b. Wybierz Dodaj właściwość... na dole okienka niestandardowego hive-site.
c. W oknie Dodawanie właściwości wprowadź
mapred.map.output.compression.codecjako klucz iorg.apache.hadoop.io.compress.SnappyCodecjako wartość.d. Wybierz Dodaj.
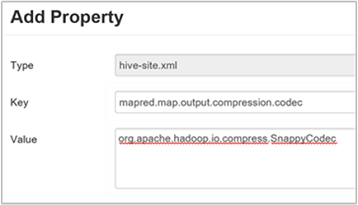
To ustawienie spowoduje skompresowanie pliku pośredniego przy użyciu kompresji Snappy. Po dodaniu właściwości zostanie ona wyświetlona w okienku niestandardowego hive-site.
Uwaga
Ta procedura modyfikuje
$HADOOP_HOME/conf/hive-site.xmlplik.
Kompresuj końcowe dane wyjściowe
Końcowe dane wyjściowe programu Hive można również skompresować.
Aby skompresować końcowe dane wyjściowe programu Hive, przejdź do karty Konfiguracje programu Hive, a następnie ustaw
hive.exec.compress.outputparametr na true. Wartość domyślna to false.Aby wybrać kodek kompresji wyjściowej, dodaj właściwość niestandardową
mapred.output.compression.codecdo sekcji niestandardowej hive-site, zgodnie z opisem w kroku 3 poprzedniej sekcji.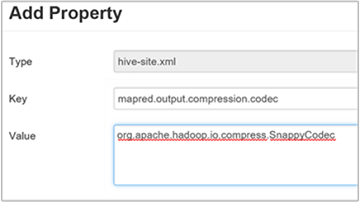
Włącz wykonywanie spekulatywne
Wykonywanie spekulatywne uruchamia pewną liczbę zduplikowanych zadań w celu wykrywania i odrzucania listy wolno działających monitorów zadań. Podczas ulepszania ogólnego wykonywania zadania przez optymalizację wyników poszczególnych zadań.
Wykonywanie spekulatywne nie powinno być włączone w przypadku długotrwałych zadań MapReduce z dużą ilością danych wejściowych.
Aby włączyć wykonywanie spekulatywne, przejdź do karty Konfiguracje programu Hive, a następnie ustaw parametr na
hive.mapred.reduce.tasks.speculative.executiontrue. Wartość domyślna to false.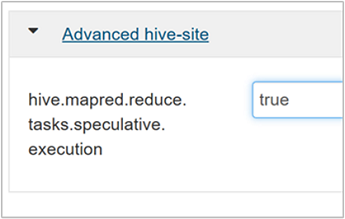
Dostrajanie partycji dynamicznych
Program Hive umożliwia tworzenie partycji dynamicznych podczas wstawiania rekordów do tabeli bez wstępnie zdefiniowanej każdej partycji. Ta możliwość jest zaawansowaną funkcją. Chociaż może to spowodować utworzenie dużej liczby partycji. Duża liczba plików dla każdej partycji.
W przypadku programu Hive do wykonywania partycji dynamicznych wartość parametru
hive.exec.dynamic.partitionpowinna mieć wartość true (wartość domyślna).Zmień tryb partycji dynamicznej na rygorystyczny. W trybie ścisłym co najmniej jedna partycja musi być statyczna. To ustawienie uniemożliwia wykonywanie zapytań bez filtru partycji w klauzuli WHERE, czyli ścisłe uniemożliwia wykonywanie zapytań, które skanują wszystkie partycje. Przejdź do karty Konfiguracje programu Hive, a następnie ustaw ustawienie
hive.exec.dynamic.partition.modena ścisłe. Wartość domyślna to nonstrict.Aby ograniczyć liczbę partycji dynamicznych do utworzenia, zmodyfikuj
hive.exec.max.dynamic.partitionsparametr . Wartość domyślna to 5000.Aby ograniczyć łączną liczbę partycji dynamicznych na węzeł, zmodyfikuj element
hive.exec.max.dynamic.partitions.pernode. Wartość domyślna to 2000.
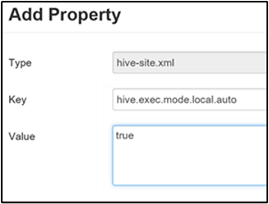
Włączanie trybu lokalnego
Tryb lokalny umożliwia Hive wykonywanie wszystkich zadań na jednej maszynie. A czasami w jednym procesie. To ustawienie zwiększa wydajność zapytań, jeśli dane wejściowe są małe. Obciążenie związane z uruchamianiem zadań dla zapytań zużywa znaczną część całkowitego czasu wykonywania zapytań.
Aby włączyć tryb lokalny, dodaj parametr hive.exec.mode.local.auto do panelu niestandardowego hive-site, zgodnie z opisem w kroku 3 sekcji Włącz kompresję pośrednią.
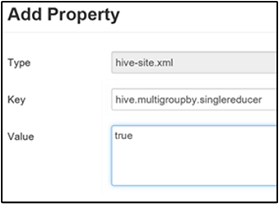
Ustawianie pojedynczego elementu MapReduce MultiGROUP BY
Gdy ta właściwość ma wartość true, zapytanie MultiGROUP BY z typowymi kluczami grupowania generuje pojedyncze zadanie MapReduce.
Aby włączyć to zachowanie, dodaj parametr do niestandardowego okienka hive-site, zgodnie z opisem w kroku 3 sekcji Włącz kompresję pośrednią.
Dodatkowe optymalizacje Hive
W poniższych sekcjach opisano dodatkowe optymalizacje związane z programem Hive, które można ustawić.
Optymalizacje złączeń
Domyślny typ sprzężenia w programie Hive to łączenie metodą tasowania. W programie Hive specjalne elementy mapujące odczytują dane wejściowe i emitują parę klucza i wartości dla sprzężenia do pliku tymczasowego. Usługa Hadoop sortuje i scala te pary w etapie mieszania. Ten etap mieszania jest kosztowny. Wybranie odpowiedniego sprzężenia na podstawie danych może znacznie poprawić wydajność.
| Typ sprzężenia | Kiedy | Jak | Ustawienia programu Hive | Komentarze |
|---|---|---|---|---|
| Łączenie shuffle |
|
|
Nie jest wymagane żadne istotne ustawienie Hive. | Działa za każdym razem |
| Łączenie map |
|
|
hive.auto.convert.join=true |
Szybkie, ale ograniczone |
| Sortowanie metodą kubełkowego scalania | Jeśli obie tabele są następujące:
|
Każdy proces:
|
hive.auto.convert.sortmerge.join=true |
Sprawny |
Optymalizacje silnika wykonawczego
Dodatkowe zalecenia dotyczące optymalizowania aparatu wykonawczego programu Hive:
| Ustawienie | Zalecane | Domyślna usługa HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = bezpieczniejsze, wolniejsze; false = szybciej | fałszywy |
tez.am.resource.memory.mb |
Górna granica 4 GB dla większości | Automatyczne dostrajanie |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10 000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |
Następne kroki
- Zarządzanie klastrami usługi HDInsight przy użyciu internetowego interfejsu użytkownika platformy Apache Ambari
- Apache Ambari REST API
- Optymalizowanie zapytań technologii Apache Hive w usłudze Azure HDInsight
- Optymalizowanie klastrów
- Optymalizowanie bazy danych Apache HBase
- Optymalizowanie oprogramowania Apache Pig