Porady dotyczące wydajności zestawu Java SDK usługi Azure Cosmos DB w wersji 4
DOTYCZY: ![]() NoSQL
NoSQL
Ważne
Porady dotyczące wydajności w tym artykule dotyczą tylko zestawu Java SDK usługi Azure Cosmos DB w wersji 4. Aby uzyskać więcej informacji, zobacz przewodnik rozwiązywania problemów z zestawem Java SDK usługi Azure Cosmos DB w wersji 4, repozytorium Maven i zestaw Java SDK usługi Azure Cosmos DB w wersji 4. Jeśli obecnie używasz starszej wersji niż 4, zobacz przewodnik Migrowanie do zestawu Java SDK usługi Azure Cosmos DB w wersji 4 , aby uzyskać pomoc dotyczącą uaktualniania do wersji 4.
Azure Cosmos DB to szybka i elastyczna rozproszona baza danych, która bezproblemowo skaluje się z gwarantowanym opóźnieniem i przepływnością. Nie musisz wprowadzać istotnych zmian architektury ani pisać złożonego kodu w celu skalowania bazy danych za pomocą usługi Azure Cosmos DB. Skalowanie w górę i w dół jest tak proste, jak tworzenie pojedynczego wywołania interfejsu API lub wywołania metody zestawu SDK. Jednak ze względu na to, że dostęp do usługi Azure Cosmos DB jest uzyskiwany za pośrednictwem wywołań sieciowych, można dokonać optymalizacji po stronie klienta, aby osiągnąć szczytową wydajność podczas korzystania z zestawu Java SDK usługi Azure Cosmos DB w wersji 4.
Jeśli więc zadajesz pytanie "Jak mogę poprawić wydajność bazy danych?", rozważ następujące opcje:
Sieć
Sortowanie klientów w tym samym regionie świadczenia usługi Azure pod kątem wydajności
Jeśli to możliwe, umieść wszystkie aplikacje wywołujące usługę Azure Cosmos DB w tym samym regionie co baza danych usługi Azure Cosmos DB. Aby uzyskać przybliżone porównanie, wywołania usługi Azure Cosmos DB w tym samym regionie są kompletne w ciągu 1–2 ms, ale opóźnienie między zachodnim i wschodnim wybrzeżem STANÓW Zjednoczonych wynosi >50 ms. To opóźnienie może się różnić w zależności od trasy podjętej przez żądanie w zależności od trasy, która przechodzi od klienta do granicy centrum danych platformy Azure. Najmniejsze możliwe opóźnienie jest osiągane przez zapewnienie, że aplikacja wywołująca znajduje się w tym samym regionie świadczenia usługi Azure, co aprowizowany punkt końcowy usługi Azure Cosmos DB. Aby uzyskać listę dostępnych regionów, zobacz Regiony świadczenia usługi Azure.
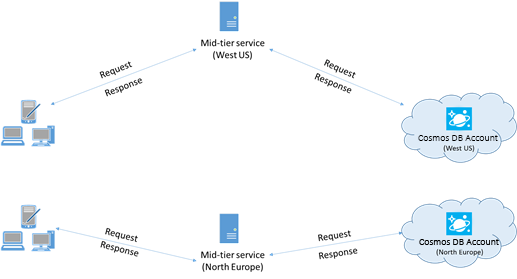
Aplikacja, która współdziała z kontem usługi Azure Cosmos DB w wielu regionach, musi skonfigurować preferowane lokalizacje , aby upewnić się, że żądania będą kierowane do kolokowanego regionu.
Włączanie przyspieszonej sieci w celu zmniejszenia opóźnienia i zakłócenia procesora CPU
Zdecydowanie zalecamy wykonanie instrukcji dotyczących włączania przyspieszonej sieci w systemie Windows (wybierz, aby uzyskać instrukcje) lub Linux (wybierz, aby uzyskać instrukcje) maszyny wirtualnej platformy Azure, aby zmaksymalizować wydajność przez zmniejszenie opóźnienia i zakłócenia procesora CPU.
Bez przyspieszonej sieci we/wy przesyłane między maszyną wirtualną platformy Azure i innymi zasobami platformy Azure mogą być kierowane za pośrednictwem hosta i przełącznika wirtualnego znajdującego się między maszyną wirtualną a jej kartą sieciową. Posiadanie wbudowanego hosta i przełącznika wirtualnego w ścieżce danych nie tylko zwiększa opóźnienie i zakłócenia w kanale komunikacyjnym, ale także kradnie cykle procesora CPU z maszyny wirtualnej. W przypadku przyspieszonej sieci interfejsy maszyn wirtualnych bezpośrednio z kartą sieciową bez pośredników. Wszystkie szczegóły zasad sieciowych są obsługiwane na sprzęcie na karcie sieciowej, pomijając hosta i przełącznik wirtualny. Ogólnie rzecz biorąc, można oczekiwać mniejszego opóźnienia i większej przepływności, a także bardziej spójnego opóźnienia i mniejszego wykorzystania procesora CPU po włączeniu przyspieszonej sieci.
Ograniczenia: przyspieszona sieć musi być obsługiwana w systemie operacyjnym maszyny wirtualnej i może być włączona tylko wtedy, gdy maszyna wirtualna zostanie zatrzymana i cofnięto przydział. Nie można wdrożyć maszyny wirtualnej za pomocą usługi Azure Resource Manager. Usługa App Service nie ma włączonej przyspieszonej sieci.
Aby uzyskać więcej informacji, zobacz instrukcje dotyczące systemów Windows i Linux .
Wysoka dostępność
Aby uzyskać ogólne wskazówki dotyczące konfigurowania wysokiej dostępności w usłudze Azure Cosmos DB, zobacz Wysoka dostępność w usłudze Azure Cosmos DB.
Oprócz dobrej podstawowej konfiguracji na platformie bazy danych istnieją konkretne techniki, które można zaimplementować w samym zestawie JAVA SDK, co może pomóc w scenariuszach awarii. Dwie istotne strategie to strategia dostępności oparta na progach i wyłącznik na poziomie partycji.
Te techniki zapewniają zaawansowane mechanizmy umożliwiające rozwiązywanie określonych problemów z opóźnieniami i dostępnością, wykraczających poza możliwości ponawiania prób między regionami, które są domyślnie wbudowane w zestaw SDK. Proaktywne zarządzanie potencjalnymi problemami na poziomach żądań i partycji może znacząco zwiększyć odporność i wydajność aplikacji, szczególnie w warunkach wysokiego obciążenia lub obniżonej wydajności.
Strategia dostępności oparta na progach
Strategia dostępności oparta na progach może poprawić opóźnienie i dostępność, wysyłając równoległe żądania odczytu do regionów pomocniczych i akceptując najszybszą odpowiedź. Takie podejście może znacząco zmniejszyć wpływ regionalnych awarii lub warunków o dużym opóźnieniu na wydajność aplikacji. Ponadto aktywne zarządzanie połączeniami można stosować w celu dalszego zwiększenia wydajności dzięki rozgrzewaniu połączeń i pamięci podręcznych zarówno w bieżącym regionie odczytu, jak i preferowanych regionach zdalnych.
Przykładowa konfiguracja:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Jak to działa:
Początkowe żądanie: w czasie T1 żądanie odczytu jest wykonywane w regionie podstawowym (na przykład Wschodnie stany USA). Zestaw SDK czeka na odpowiedź do 500 milisekund (
thresholdwartość).Drugie żądanie: jeśli nie ma odpowiedzi z regionu podstawowego w ciągu 500 milisekund, żądanie równoległe jest wysyłane do następnego preferowanego regionu (na przykład Wschodnie stany USA 2).
Trzecie żądanie: jeśli ani region podstawowy, ani pomocniczy nie odpowie w ciągu 600 milisekund (500 ms + 100 ms,
thresholdStepwartość), zestaw SDK wysyła kolejne równoległe żądanie do trzeciego preferowanego regionu (na przykład Zachodnie stany USA).Najszybsza odpowiedź wygrywa: niezależnie od tego, który region odpowiada jako pierwszy, odpowiedź jest akceptowana, a pozostałe żądania równoległe są ignorowane.
Proaktywne zarządzanie połączeniami pomaga poprzez rozgrzewanie połączeń i pamięci podręcznych dla kontenerów w preferowanych regionach, co zmniejsza opóźnienie zimnego uruchamiania w scenariuszach trybu failover lub zapisach w konfiguracjach obejmujących wiele regionów.
Ta strategia może znacząco poprawić opóźnienie w scenariuszach, w których określony region jest powolny lub tymczasowo niedostępny, ale może to wiązać się z większymi kosztami w zakresie jednostek żądań, gdy wymagane są równoległe żądania obejmujące wiele regionów.
Uwaga
Jeśli pierwszy preferowany region zwraca kod stanu błędu nieistniejących przejściowych (np. nie znaleziono dokumentu, błąd autoryzacji, konflikt itp.), operacja zakończy się niepowodzeniem, ponieważ strategia dostępności nie będzie miała żadnych korzyści w tym scenariuszu.
Wyłącznik na poziomie partycji
Wyłącznik na poziomie partycji zwiększa opóźnienie ogona i dostępność zapisu przez śledzenie i żądania zwarcie do partycji fizycznych w złej kondycji. Poprawia wydajność, unikając znanych problematycznych partycji i przekierowywania żądań do zdrowszych regionów.
Przykładowa konfiguracja:
Aby włączyć wyłącznik na poziomie partycji:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Aby ustawić częstotliwość procesu w tle na potrzeby sprawdzania niedostępnych regionów:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Aby ustawić czas trwania, przez który partycja może pozostać niedostępna:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Jak to działa:
Błędy śledzenia: zestaw SDK śledzi błędy terminalu (np. 503, 500s, limity czasu) dla poszczególnych partycji w określonych regionach.
Oznaczanie jako niedostępne: jeśli partycja w regionie przekroczy skonfigurowany próg awarii, zostanie oznaczona jako "Niedostępna". Kolejne żądania do tej partycji są zwarciem i przekierowywane do innych zdrowszych regionów.
Automatyczne odzyskiwanie: wątek w tle okresowo sprawdza niedostępne partycje. Po upływie określonego czasu trwania te partycje są wstępnie oznaczone jako "W dobrej kondycji" i poddawane testom żądań weryfikacji odzyskiwania.
Podwyższenie poziomu kondycji/obniżenie poziomu: na podstawie powodzenia lub niepowodzenia tych żądań testowych stan partycji jest promowany z powrotem do "W dobrej kondycji" lub ponownie obniżany do "Niedostępne".
Ten mechanizm pomaga stale monitorować kondycję partycji i zapewnia, że żądania są obsługiwane z minimalnym opóźnieniem i maksymalną dostępnością, bez pisania przez problematyczne partycje.
Uwaga
Wyłącznik dotyczy tylko kont zapisu w wielu regionach, ponieważ gdy partycja jest oznaczona jako , zarówno odczyty, jak Unavailablei zapisy są przenoszone do następnego preferowanego regionu. Zapobiega to odczytom i zapisom z różnych regionów obsługiwanych w tym samym wystąpieniu klienta, ponieważ jest to antywzór.
Ważne
Aby aktywować wyłącznik na poziomie partycji, musisz użyć wersji 4.63.0 zestawu Java SDK lub nowszej.
Porównywanie optymalizacji dostępności
Strategia dostępności oparta na progach:
- Korzyść: Zmniejsza opóźnienie końcowe przez wysyłanie równoległych żądań odczytu do regionów pomocniczych i zwiększa dostępność przez wstępne wymuszenie żądań, które spowodują przekroczenie limitu czasu sieci.
- Kompromis: wiąże się z dodatkowymi kosztami jednostek ru (jednostek żądań) w porównaniu z wyłącznikiem z powodu dodatkowych równoległych żądań między regionami (choć tylko w okresach, gdy progi są naruszone).
- Przypadek użycia: Optymalne dla obciążeń wymagających odczytu, w których zmniejszenie opóźnienia ma krytyczne znaczenie, a niektóre dodatkowe koszty (zarówno pod względem opłaty za jednostkę RU, jak i wykorzystanie procesora CPU klienta) są akceptowalne. Operacje zapisu mogą również przynieść korzyści, jeśli zdecydujesz się na zasady ponawiania operacji zapisu bez identyfikatora idempotentnego, a konto ma zapisy w wielu regionach.
Wyłącznik na poziomie partycji:
- Korzyść: Zwiększa dostępność i opóźnienia, unikając partycji w złej kondycji, zapewniając kierowanie żądań do zdrowszych regionów.
- Kompromis: nie wiąże się z dodatkowymi kosztami jednostek ŻĄDANIA, ale może nadal zezwalać na początkową utratę dostępności dla żądań, które spowodują przekroczenie limitu czasu sieci.
- Przypadek użycia: idealne rozwiązanie w przypadku obciążeń z dużym obciążeniem zapisu lub mieszanym, w przypadku których niezbędna jest spójna wydajność, szczególnie w przypadku obsługi partycji, które mogą sporadycznie stać się w złej kondycji.
Obie strategie mogą być używane razem w celu zwiększenia dostępności odczytu i zapisu oraz zmniejszenia opóźnienia końcowego. Wyłącznik na poziomie partycji może obsługiwać różne scenariusze błędów przejściowych, w tym te, które mogą powodować powolne wykonywanie replik bez konieczności wykonywania żądań równoległych. Ponadto dodanie strategii dostępności opartej na progach jeszcze bardziej minimalizuje opóźnienie końcowe i eliminuje utratę dostępności, jeśli dodatkowy koszt jednostek RU jest akceptowalny.
Wdrażając te strategie, deweloperzy mogą zapewnić odporność aplikacji, utrzymać wysoką wydajność i zapewnić lepsze środowisko użytkownika nawet podczas regionalnych awarii lub warunków o dużym opóźnieniu.
Spójność sesji w zakresie regionu
Omówienie
Aby uzyskać więcej informacji na temat ogólnych ustawień spójności, zobacz Poziomy spójności w usłudze Azure Cosmos DB. Zestaw JAVA SDK zapewnia optymalizację spójności sesji dla kont zapisu w wielu regionach, umożliwiając jej określanie zakresu regionów. Zwiększa to wydajność dzięki ograniczeniu opóźnienia replikacji między regionami dzięki zminimalizowaniu ponownych prób po stronie klienta. Jest to osiągane przez zarządzanie tokenami sesji na poziomie regionu zamiast globalnie. Jeśli spójność w aplikacji może być ograniczona do mniejszej liczby regionów, implementując spójność sesji w zakresie regionu, można osiągnąć lepszą wydajność i niezawodność operacji odczytu i zapisu na kontach z wieloma zapisami, minimalizując opóźnienia replikacji między regionami i ponawianie prób.
Świadczenia
- Mniejsze opóźnienie: dzięki zlokalizowaniu weryfikacji tokenu sesji na poziomie regionu ryzyko kosztownego ponawiania prób między regionami zostanie zmniejszone.
- Zwiększona wydajność: minimalizuje wpływ regionalnego trybu failover i opóźnienia replikacji, oferując większą spójność odczytu/zapisu i mniejsze wykorzystanie procesora CPU.
- Zoptymalizowane wykorzystanie zasobów: zmniejsza obciążenie procesora CPU i sieci w aplikacjach klienckich, ograniczając konieczność ponawiania prób i wywołań między regionami, optymalizując w ten sposób użycie zasobów.
- Wysoka dostępność: dzięki obsłudze tokenów sesji w zakresie regionu aplikacje mogą nadal działać bezproblemowo, nawet jeśli w niektórych regionach występują większe opóźnienia lub tymczasowe błędy.
- Gwarancje spójności: gwarantuje, że spójność sesji (odczyt zapisu, odczyt monotoniczny) gwarantuje, że będą bardziej niezawodne bez niepotrzebnych ponownych prób.
- Efektywność kosztowa: zmniejsza liczbę wywołań między regionami, co może potencjalnie obniżyć koszty związane z transferami danych między regionami.
- Skalowalność: umożliwia aplikacjom wydajniejsze skalowanie przez zmniejszenie rywalizacji i nakładu pracy związanej z utrzymywaniem globalnego tokenu sesji, zwłaszcza w konfiguracjach obejmujących wiele regionów.
Kompromisy
- Zwiększone użycie pamięci: filtr blooma i magazyn tokenów sesji specyficzny dla regionu wymagają dodatkowej pamięci, co może być istotne dla aplikacji z ograniczonymi zasobami.
- Złożoność konfiguracji: Dostrajanie oczekiwanej liczby wstawiania i współczynnik wyników fałszywie dodatnich dla filtru blooma zwiększa złożoność procesu konfiguracji.
- Potencjalne wyniki fałszywie dodatnie: chociaż filtr bloom minimalizuje ponowne próby między regionami, nadal istnieje niewielkie prawdopodobieństwo fałszywie dodatnich wpływających na walidację tokenu sesji, chociaż szybkość może być kontrolowana. Wynik fałszywie dodatni oznacza, że globalny token sesji jest rozpoznawany, co zwiększa prawdopodobieństwo ponownych prób obejmujących wiele regionów, jeśli region lokalny nie jest uwikłany w tę sesję globalną. Gwarancje sesji są spełnione nawet w obecności wyników fałszywie dodatnich.
- Zastosowanie: ta funkcja jest najbardziej korzystna dla aplikacji z wysoką kardynalnością partycji logicznych i regularnych ponownych uruchomień. Aplikacje z mniejszą liczbą partycji logicznych lub rzadkimi ponownymi uruchomieniami mogą nie widzieć znaczących korzyści.
Jak to działa
Ustawianie tokenu sesji
- Uzupełnianie żądań: po zakończeniu żądania zestaw SDK przechwytuje token sesji i kojarzy go z regionem i kluczem partycji.
- Magazyn na poziomie regionu: tokeny sesji są przechowywane w zagnieżdżonym
ConcurrentHashMapmagazynie, który utrzymuje mapowania między zakresami kluczy partycji i postępem na poziomie regionu. - Filtr blooma: filtr bloom śledzi regiony, do których uzyskiwano dostęp przez każdą partycję logiczną, co pomaga lokalizować weryfikację tokenu sesji.
Rozwiązywanie problemów z tokenem sesji
- Inicjowanie żądania: przed wysłaniem żądania zestaw SDK próbuje rozpoznać token sesji dla odpowiedniego regionu.
- Sprawdzanie tokenu: token jest sprawdzany względem danych specyficznych dla regionu, aby upewnić się, że żądanie jest kierowane do najbardziej aktualnej repliki.
- Logika ponawiania: jeśli token sesji nie jest weryfikowany w bieżącym regionie, zestaw SDK ponawia próbę z innymi regionami, ale biorąc pod uwagę zlokalizowany magazyn, jest to rzadziej używane.
Korzystanie z zestawu SDK
Poniżej przedstawiono sposób inicjowania obiektu CosmosClient przy użyciu spójności sesji o zakresie regionu:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Włączanie spójności sesji w zakresie regionu
Aby włączyć przechwytywanie sesji w zakresie regionu w aplikacji, ustaw następującą właściwość systemową:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Konfigurowanie filtru blooma
Dostosuj wydajność, konfigurując oczekiwane wstawienia i współczynnik wyników fałszywie dodatnich dla filtru blooma:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implikacje związane z pamięcią
Poniżej znajduje się zachowany rozmiar (rozmiar obiektu i niezależnie od tego, od czego zależy) kontenera sesji wewnętrznej (zarządzanego przez zestaw SDK) z różną oczekiwaną wstawień do filtru blooma.
| Oczekiwane wstawienia | Współczynnik wyników fałszywie dodatnich | Zachowany rozmiar |
|---|---|---|
| 10, 000 | 0,001 | 21 KB |
| 100, 000 | 0,001 | 183 KB |
| 1 mln | 0,001 | 1,8 MB |
| 10 mln | 0,001 | 17,9 MB |
| 100 milionów | 0,001 | 179 MB |
| 1 miliard | 0,001 | 1,8 GB |
Ważne
Aby aktywować spójność sesji w zakresie regionu, musisz używać wersji 4.60.0 zestawu Java SDK lub nowszej wersji.
Dostrajanie konfiguracji połączenia bezpośredniego i bramy
Aby zoptymalizować konfiguracje połączeń trybu bezpośredniego i bramy, zobacz jak dostroić konfiguracje połączeń dla zestawu Java SDK w wersji 4.
SDK usage (Użycie zestawu SDK)
- Instalowanie najnowszego zestawu SDK
Zestawy SDK usługi Azure Cosmos DB są stale ulepszane, aby zapewnić najlepszą wydajność. Aby określić najnowsze ulepszenia zestawu SDK, odwiedź stronę zestawu SDK usługi Azure Cosmos DB.
Każde wystąpienie klienta usługi Azure Cosmos DB jest bezpieczne wątkowo i wykonuje wydajne zarządzanie połączeniami i buforowanie adresów. Aby umożliwić wydajne zarządzanie połączeniami i lepszą wydajność przez klienta usługi Azure Cosmos DB, zdecydowanie zalecamy użycie pojedynczego wystąpienia klienta usługi Azure Cosmos DB przez cały okres istnienia aplikacji.
Podczas tworzenia elementu CosmosClient domyślna spójność używana, jeśli nie jest jawnie ustawiona, to Sesja. Jeśli spójność sesji nie jest wymagana przez logikę aplikacji, ustaw wartość Spójność na ostateczną. Uwaga: zaleca się stosowanie co najmniej spójności sesji w aplikacjach korzystających z procesora zestawienia zmian usługi Azure Cosmos DB.
- Używanie interfejsu API asynchronicznego do maksymalnej aprowizowanej przepływności
Zestaw Java SDK usługi Azure Cosmos DB w wersji 4 zawiera dwa interfejsy API: synchroniczny i asynchroniczny. Mówiąc mniej więcej, interfejs API asynchroniczny implementuje funkcje zestawu SDK, natomiast interfejs API synchronizacji jest cienką otoką, która wykonuje wywołania blokujące interfejsu API asynchronicznego. Jest to przeciwieństwo starszego zestawu Java SDK asynchronicznego języka Java usługi Azure Cosmos DB w wersji 2, który był tylko asynchroniczny, oraz starszego zestawu Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2, który był tylko synchronizacją i miał oddzielną implementację.
Wybór interfejsu API jest określany podczas inicjowania klienta; Obiekt CosmosAsyncClient obsługuje interfejs API asynchroniczny, a klient CosmosClient obsługuje interfejs API synchronizacji.
Interfejs API asynchroniczny implementuje nieblokujące operacje we/wy i jest optymalnym wyborem, jeśli twoim celem jest maksymalne wykorzystanie przepływności podczas wydawania żądań do usługi Azure Cosmos DB.
Użycie interfejsu API synchronizacji może być właściwym wyborem, jeśli chcesz lub potrzebujesz interfejsu API, który blokuje odpowiedź na każde żądanie, lub jeśli operacja synchroniczna jest dominującym paradygmatem w aplikacji. Na przykład możesz chcieć, aby interfejs API synchronizacji był utrwalany w usłudze Azure Cosmos DB w aplikacji mikrousług, pod warunkiem, że przepływność nie jest krytyczna.
Zwróć uwagę, że przepływność interfejsu API synchronizacji spada wraz ze zwiększeniem czasu odpowiedzi na żądanie, natomiast interfejs API asynchroniczny może usycić pełne możliwości przepustowości sprzętu.
Kolokacja geograficzna może zapewnić wyższą i bardziej spójną przepływność podczas korzystania z interfejsu API synchronizacji (zobacz Collocate clients in same region azure for performance), ale nadal nie oczekuje się przekroczenia osiągalnej przepływności interfejsu API asynchronicznego.
Niektórzy użytkownicy mogą być również nieznani w programie Project Reactor— strukturze reaktywnych strumieni używanych do implementowania zestawu Java SDK języka Java usługi Azure Cosmos DB w wersji 4 interfejsu API asynchronicznego. Jeśli jest to problem, zalecamy zapoznanie się z naszym przewodnikiem wprowadzającym wzorzec reaktora, a następnie zapoznaj się z tym wprowadzeniem do programowania reaktywnego, aby zapoznać się z tym tematem. Jeśli używasz już usługi Azure Cosmos DB z interfejsem asynchroniczny, a użyty zestaw SDK to zestaw SDK języka Java asynchronicznego usługi Azure Cosmos DB w wersji 2, możesz zapoznać się z reaktywnym X/RxJava, ale nie masz pewności, co zmieniło się w usłudze Project Reactor. W takim przypadku zapoznaj się z naszym przewodnikiem Reactor vs RxJava, aby się zapoznać.
W poniższych fragmentach kodu pokazano, jak zainicjować klienta usługi Azure Cosmos DB na potrzeby operacji interfejsu API asynchronicznego lub interfejsu API synchronizacji, odpowiednio:
Zestaw JAVA SDK w wersji 4 (Maven com.azure::azure-cosmos) Async API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Skalowanie w poziomie obciążenia klienta
Jeśli testujesz na wysokim poziomie przepływności, aplikacja kliencka może stać się wąskim gardłem spowodowanym ograniczeniem użycia procesora CPU lub sieci przez maszynę. Jeśli osiągniesz ten punkt, możesz kontynuować wypychanie konta usługi Azure Cosmos DB, skalując aplikacje klienckie na wielu serwerach.
Dobrą regułą kciuka nie jest przekroczenie >50% wykorzystania procesora CPU na dowolnym serwerze, aby zachować małe opóźnienie.
- Użyj odpowiedniego harmonogramu (unikaj kradzieży wątków we/wy pętli zdarzeń)
Funkcja asynchroniczna zestawu SDK java usługi Azure Cosmos DB jest oparta na netty nieblokujących operacji we/wy. Zestaw SDK używa do wykonywania operacji we/wy stałej liczby wątków Netty pętli zdarzeń operacji we/wy (równej liczbie rdzeni procesora CPU komputera). Strumień zwrócony przez interfejs API emituje wynik dla jednego z współdzielonych wątków Netty pętli zdarzeń we/wy. Dlatego ważne jest, aby nie blokować współdzielonych wątków Netty pętli zdarzeń operacji we/wy. Wykonywanie intensywnej pracy procesora CPU lub blokowanie operacji w wątku netty pętli zdarzeń we/wy może spowodować zakleszczenie lub znaczne zmniejszenie przepływności zestawu SDK.
Na przykład poniższy kod wykonuje pracę intensywnie korzystającą z procesora CPU w wątku netty pętli zdarzeń:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Po otrzymaniu wyniku należy unikać wykonywania wszelkich prac intensywnie korzystających z procesora CPU w wyniku w wątku netty pętli zdarzeń. Zamiast tego możesz podać własny harmonogram, aby udostępnić własny wątek do uruchamiania pracy, jak pokazano poniżej (wymaga import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Na podstawie typu pracy należy użyć odpowiedniego harmonogramu reaktora do pracy. Przeczytaj tutaj Schedulers.
Aby lepiej zrozumieć model wątkowania i planowania projektu Reactor, zapoznaj się z tym wpisem w blogu autorstwa Project Reactor.
Aby uzyskać więcej informacji na temat zestawu Java SDK usługi Azure Cosmos DB w wersji 4, zobacz katalog usługi Azure Cosmos DB zestawu Azure SDK dla języka Java monorepo w witrynie GitHub.
- Optymalizowanie ustawień rejestrowania w aplikacji
Z różnych powodów należy dodać rejestrowanie w wątku, który generuje wysoką przepływność żądań. Jeśli Twoim celem jest pełne nasycenie aprowizowanej przepływności kontenera z żądaniami wygenerowanymi przez ten wątek, optymalizacje rejestrowania mogą znacznie poprawić wydajność.
- Konfigurowanie rejestratora asynchronicznego
Opóźnienie synchronicznego rejestratora musi wpływać na ogólne obliczenie opóźnienia wątku generowania żądań. Rejestrator asynchroniczny, taki jak log4j2, zaleca się oddzielenie obciążeń związanych z rejestrowaniem z wątków aplikacji o wysokiej wydajności.
- Wyłączanie rejestrowania netty
Rejestrowanie biblioteki Netty jest czatty i musi być wyłączone (pomijanie logowania w konfiguracji może nie być wystarczające), aby uniknąć dodatkowych kosztów procesora CPU. Jeśli nie jesteś w trybie debugowania, wyłącz rejestrowanie netty całkowicie. Dlatego jeśli używasz usługi Log4j, aby usunąć dodatkowe koszty procesora CPU poniesione przez org.apache.log4j.Category.callAppenders() netty, dodaj następujący wiersz do bazy kodu:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Limit zasobów otwartych plików systemu operacyjnego
Niektóre systemy Linux (takie jak Red Hat) mają górny limit liczby otwartych plików, więc łączna liczba połączeń. Uruchom następujące polecenie, aby wyświetlić bieżące limity:
ulimit -a
Liczba otwartych plików (nofile) musi być wystarczająco duża, aby mieć wystarczającą ilość miejsca dla skonfigurowanego rozmiaru puli połączeń i innych otwartych plików przez system operacyjny. Można go zmodyfikować, aby umożliwić większy rozmiar puli połączeń.
Otwórz plik limits.conf:
vim /etc/security/limits.conf
Dodaj/zmodyfikuj następujące wiersze:
* - nofile 100000
- Określanie klucza partycji w zapisach punktów
Aby zwiększyć wydajność zapisów punktów, określ klucz partycji elementu w wywołaniu interfejsu API zapisu punktu, jak pokazano poniżej:
Zestaw JAVA SDK w wersji 4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Zamiast dostarczać tylko wystąpienie elementu, jak pokazano poniżej:
Zestaw JAVA SDK w wersji 4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item).block();
Ta ostatnia funkcja jest obsługiwana, ale spowoduje dodanie opóźnienia do aplikacji; zestaw SDK musi przeanalizować element i wyodrębnić klucz partycji.
Operacje zapytań
Aby uzyskać informacje o operacjach zapytań, zobacz porady dotyczące wydajności zapytań.
Zasady indeksowania
- Wyklucz nieużywane ścieżki z indeksowania w celu przyspieszenia operacji zapisu
Zasady indeksowania usługi Azure Cosmos DB umożliwiają określenie ścieżek dokumentów do uwzględnienia lub wykluczenia z indeksowania przy użyciu ścieżek indeksowania (setIncludedPaths i setExcludedPaths). Użycie ścieżek indeksowania może oferować lepszą wydajność zapisu i niższy magazyn indeksów w scenariuszach, w których wzorce zapytań są znane wcześniej, ponieważ koszty indeksowania są bezpośrednio skorelowane z liczbą indeksowanych unikatowych ścieżek. Na przykład poniższy kod przedstawia sposób dołączania i wykluczania całych sekcji dokumentów (nazywanych również poddrzewem) z indeksowania przy użyciu symbolu wieloznakowego "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Aby uzyskać więcej informacji, zobacz Zasady indeksowania usługi Azure Cosmos DB.
Produktywność
- Mierzenie i dostrajanie do niższych jednostek żądania/drugiego użycia
Usługa Azure Cosmos DB oferuje bogaty zestaw operacji bazy danych, w tym zapytania relacyjne i hierarchiczne z funkcjami zdefiniowanymi przez użytkownika, procedurami składowanymi i wyzwalaczami — wszystkie operacje na dokumentach w kolekcji bazy danych. Koszt związany z każdą z tych operacji zależy od procesora, danych We/Wy i pamięci wymaganej do wykonania danej operacji. Zamiast myśleć o zasobach sprzętowych i zarządzaniu nimi, możesz traktować jednostkę żądania (RU) jako pojedynczą miarę dla zasobów wymaganych do wykonywania różnych operacji bazy danych i obsługi żądania aplikacji.
Przepływność jest aprowizowana na podstawie liczby jednostek żądań ustawionych dla każdego kontenera. Użycie jednostek żądania jest oceniane jako szybkość na sekundę. Aplikacje, które przekraczają aprowizowaną liczbę jednostek żądań dla kontenera, są ograniczone do momentu spadku szybkości poniżej aprowizowanego poziomu dla kontenera. Jeśli aplikacja wymaga wyższego poziomu przepływności, możesz zwiększyć przepływność, aprowizując dodatkowe jednostki żądań.
Złożoność zapytania ma wpływ na liczbę jednostek żądania używanych dla operacji. Liczba predykatów, charakter predykatów, liczba funkcji zdefiniowanych przez użytkownika i rozmiar zestawu danych źródłowych wpływają na koszt operacji zapytań.
Aby zmierzyć obciążenie dowolnej operacji (tworzenie, aktualizowanie lub usuwanie), sprawdź nagłówek x-ms-request-charge , aby zmierzyć liczbę jednostek żądań używanych przez te operacje. Możesz również przyjrzeć się równoważnej właściwości RequestCharge w elemencie ResourceResponse<T> lub FeedResponse<T>.
Zestaw JAVA SDK w wersji 4 (Maven com.azure::azure-cosmos) Async API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
Opłata za żądanie zwrócona w tym nagłówku jest ułamkiem aprowizowanej przepływności. Jeśli na przykład masz aprowizowaną wartość 2000 RU/s, a poprzednie zapytanie zwróci 1000 dokumentów 1 KB, koszt operacji wynosi 1000. W związku z tym w ciągu jednej sekundy serwer honoruje tylko dwa takie żądania przed ograniczeniem liczby kolejnych żądań. Aby uzyskać więcej informacji, zobacz Request units and the request unit calculator (Jednostki żądań i kalkulator jednostek żądania).
- Obsługa ograniczania szybkości/szybkości żądań jest zbyt duża
Gdy klient próbuje przekroczyć zarezerwowaną przepływność dla konta, nie ma spadku wydajności na serwerze i nie ma użycia pojemności przepływności poza poziomem zarezerwowanym. Serwer z preemptively zakończy żądanie requestRateTooLarge (kod stanu HTTP 429) i zwróci nagłówek x-ms-retry-after-ms wskazujący ilość czasu w milisekundach, że użytkownik musi czekać przed ponownego przypisania żądania.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Zestawy SDK przechwytują tę odpowiedź niejawnie, przestrzegają określonego przez serwer nagłówka ponawiania próby i ponów próbę żądania. Jeśli twoje konto nie jest używane współbieżnie przez wielu klientów, następne ponowienie próby powiedzie się.
Jeśli masz więcej niż jednego klienta, który stale działa powyżej szybkości żądań, domyślna liczba ponownych prób jest obecnie ustawiona na 9 wewnętrznie przez klienta może nie być wystarczająca; w tym przypadku klient zgłasza wyjątek CosmosClientException z kodem stanu 429 do aplikacji. Domyślna liczba ponownych prób można zmienić przy użyciu polecenia setMaxRetryAttemptsOnThrottledRequests() w wystąpieniu ThrottlingRetryOptions . Domyślnie wyjątek CosmosClientException z kodem stanu 429 jest zwracany po skumulowanym czasie oczekiwania wynoszącym 30 sekund, jeśli żądanie nadal działa powyżej szybkości żądania. Dzieje się tak nawet wtedy, gdy bieżąca liczba ponownych prób jest mniejsza niż maksymalna liczba ponownych prób, może to być wartość domyślna 9 lub wartość zdefiniowana przez użytkownika.
Chociaż automatyczne zachowanie ponawiania prób pomaga zwiększyć odporność i użyteczność dla większości aplikacji, może to być sprzeczne podczas wykonywania testów porównawczych wydajności, zwłaszcza podczas mierzenia opóźnienia. Obserwowane przez klienta opóźnienie wzrośnie, jeśli eksperyment osiągnie ograniczenie przepustowości serwera i spowoduje, że zestaw SDK klienta ponawia próbę w trybie dyskretnym. Aby uniknąć skoków opóźnień podczas eksperymentów wydajności, zmierz opłatę zwróconą przez każdą operację i upewnij się, że żądania działają poniżej zarezerwowanej stawki żądań. Aby uzyskać więcej informacji, zobacz Request units (Jednostki żądań).
- Projektowanie pod kątem mniejszych dokumentów pod kątem większej przepływności
Opłata za żądanie (koszt przetwarzania żądań) danej operacji jest bezpośrednio skorelowana z rozmiarem dokumentu. Operacje na dużych dokumentach kosztują więcej niż operacje dla małych dokumentów. W idealnym przypadku należy utworzyć architekturę aplikacji i przepływów pracy, aby rozmiar elementu wynosił ok. 1 KB lub podobnej kolejności lub wielkości. W przypadku aplikacji wrażliwych na opóźnienia należy unikać dużych elementów — dokumenty z wieloma MB spowalniają aplikację.
Następne kroki
Aby dowiedzieć się więcej na temat projektowania aplikacji pod kątem skalowania i wysokiej wydajności, zobacz Partycjonowanie i skalowanie w usłudze Azure Cosmos DB.
Próbujesz zaplanować pojemność migracji do usługi Azure Cosmos DB? Informacje o istniejącym klastrze bazy danych można użyć do planowania pojemności.
- Jeśli wszystko, co wiesz, to liczba rdzeni wirtualnych i serwerów w istniejącym klastrze bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu rdzeni wirtualnych lub procesorów wirtualnych
- Jeśli znasz typowe stawki żądań dla bieżącego obciążenia bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu planisty pojemności usługi Azure Cosmos DB