Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dla każdego źródła z wyjątkiem usługi Azure SQL Database zaleca się zachowanie opcji Użyj bieżącego partycjonowania jako wybranej wartości. Podczas odczytywania ze wszystkich innych systemów źródłowych przepływy danych automatycznie partycjonują dane równomiernie na podstawie rozmiaru danych. Nowa partycja jest tworzona dla około 128 MB danych. Wraz ze wzrostem rozmiaru danych liczba partycji rośnie.
Wszelkie partycjonowanie niestandardowe odbywa się po odczytaniu danych przez platformę Spark i negatywnie wpływa na wydajność przepływu danych. Ponieważ dane są równomiernie partycjonowane podczas odczytu, nie jest zalecane, chyba że najpierw rozumiesz kształt i kardynalność danych.
Uwaga / Notatka
Szybkość odczytu może być ograniczona przez przepływność systemu źródłowego.
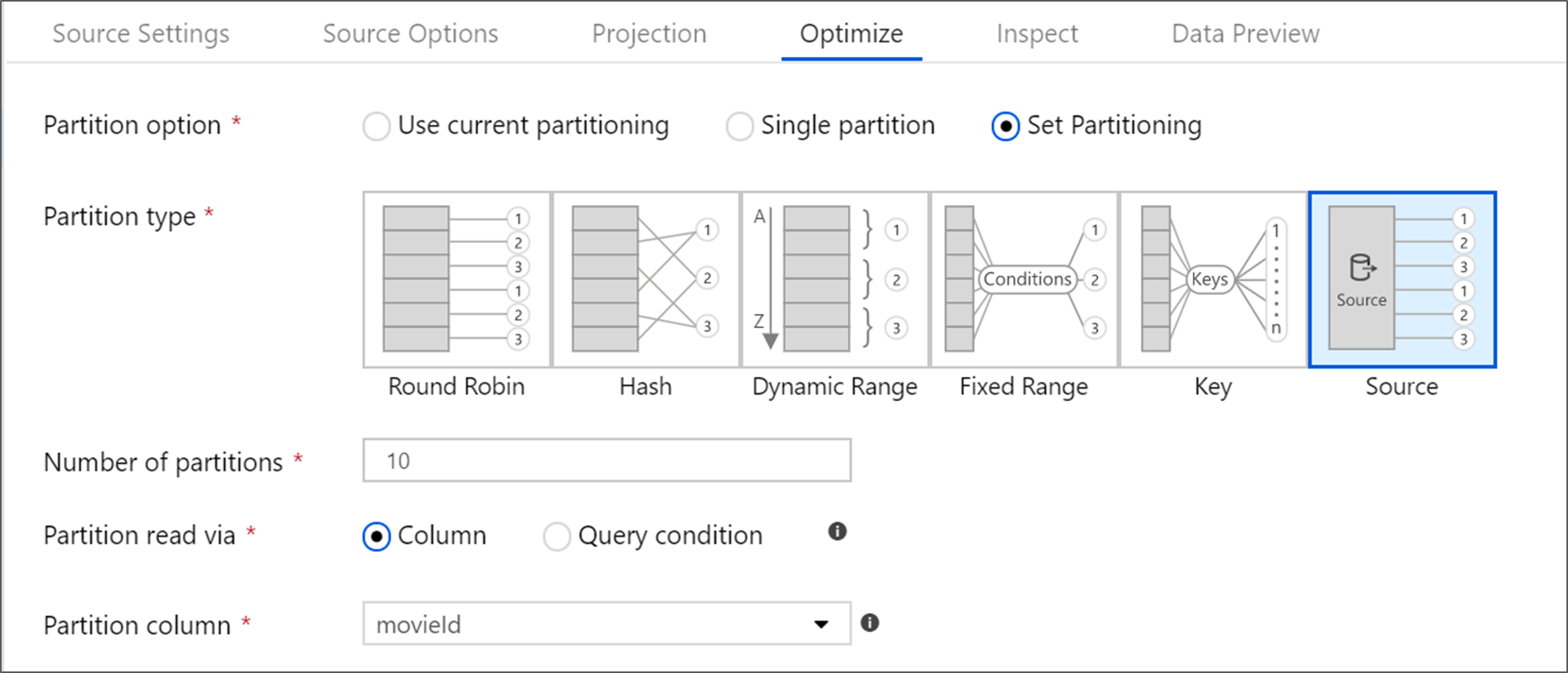
Źródła usługi Azure SQL Database
Usługa Azure SQL Database ma unikatową opcję partycjonowania o nazwie "Source" partitioning (Partycjonowanie źródła). Włączenie partycjonowania źródłowego może poprawić czas odczytu z usługi Azure SQL Database, włączając połączenia równoległe w systemie źródłowym. Określ liczbę partycji i sposób partycjonowania danych. Użyj kolumny partycji z wysoką kardynalnością. Możesz również wprowadzić zapytanie zgodne ze schematem partycjonowania tabeli źródłowej.
Wskazówka
W przypadku partycjonowania źródłowego operacje we/wy programu SQL Server są wąskim gardłem. Dodanie zbyt wielu partycji może nasycić źródłową bazę danych. Zazwyczaj cztery lub pięć partycji jest idealnym rozwiązaniem w przypadku korzystania z tej opcji.
Poziom izolacji
Poziom izolacji odczytu w systemie źródłowym usługi Azure SQL wpływa na wydajność. Wybranie opcji "Odczyt niezatwierdzony" zapewnia najszybszą wydajność i zapobieganie wszelkim blokadom bazy danych. Aby dowiedzieć się więcej na temat poziomów izolacji SQL, zobacz Opis poziomów izolacji.
Odczytaj za pomocą zapytania
Możesz odczytać z usługi Azure SQL Database przy użyciu tabeli lub zapytania SQL. Jeśli wykonujesz zapytanie SQL, zapytanie musi zostać ukończone przed rozpoczęciem transformacji. Zapytania SQL mogą być przydatne do przekazywania operacji, które mogą być wykonywane szybciej i zmniejszyć ilość danych odczytywanych z serwera SQL, takich jak instrukcji SELECT, WHERE i JOIN. Podczas przesuwania operacji tracisz możliwość śledzenia linii i wydajności przekształceń przed wejściem danych do przepływu danych.
Źródła usługi Azure Synapse Analytics
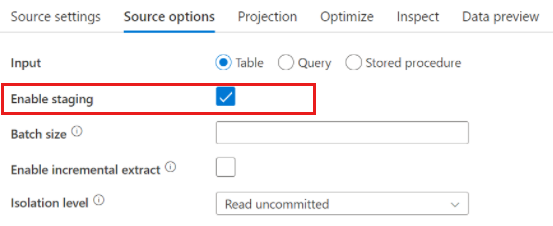
W przypadku korzystania z usługi Azure Synapse Analytics w opcjach źródłowych istnieje ustawienie o nazwie Włącz archiwizację tymczasową. Dzięki temu usługa może odczytywać dane z usługi Synapse przy użyciu polecenia Staging, co znacznie poprawia wydajność odczytu przy użyciu najbardziej wydajnych funkcji ładowania zbiorczego, takich jak CETAS i COPY.
Staging Włączenie wymaga określenia lokalizacji przejściowej usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 w ustawieniach działania przepływu danych.
Źródła oparte na plikach
Parquet a tekst rozdzielany
Chociaż przepływy danych obsługują różne typy plików, format Parquet natywny dla platformy Spark jest zalecany w celu uzyskania optymalnego czasu odczytu i zapisu.
Jeśli uruchamiasz ten sam przepływ danych w zestawie plików, zalecamy odczytywanie z folderu, korzystając ze ścieżek wieloznacznych lub odczytywanie z listy plików. Jedno uruchomienie działania przepływu danych może przetwarzać wszystkie pliki w partii. Więcej informacji na temat konfigurowania tych ustawień można znaleźć w sekcji Przekształcanie źródła w dokumentacji łącznika usługi Azure Blob Storage .
Jeśli to możliwe, unikaj używania działania For-Each do uruchamiania przepływów danych w zestawie plików. Powoduje to, że każda iteracja poszczególnych elementów uruchamia własny klaster Spark, który często nie jest konieczny i może być kosztowny.
Wbudowane zestawy danych a udostępnione zestawy danych
Zestawy danych ADF i Synapse są wspólnymi zasobami w zakładach produkcyjnych i miejscach pracy. Jednak przy odczytywaniu wielu folderów źródłowych i plików ze źródłami w postaci tekstów rozdzielanych i źródłami JSON można zwiększyć wydajność odnajdywania plików przepływu danych, ustawiając opcję "Projektowany schemat użytkownika" w oknie dialogowym ustawień schematu. Ta opcja wyłącza domyślne wykrywanie schematu przez ADF i znacznie poprawia wydajność odkrywania plików. Przed ustawieniem tej opcji zaimportuj projekcję, aby ADF miał istniejący schemat projekcji. Ta opcja nie działa w przypadku zmian schematu.
Treści powiązane
- Omówienie wydajności przepływu danych
- Optymalizowanie ujścia
- Optymalizowanie przekształceń
- Używanie przepływów danych w potokach
Zobacz inne artykuły dotyczące przepływu danych związane z wydajnością: