Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Użyj aktywności Przepływ Danych, aby przekształcać i przenosić dane za pomocą zmapowanych przepływów danych. Jeśli dopiero zaczynasz korzystać z przepływów danych, zobacz Mapping Przepływ danych overview
Tworzenie działania Przepływ danych za pomocą interfejsu użytkownika
Aby użyć działania Przepływ danych w potoku, wykonaj następujące kroki:
Wyszukaj Przepływ danych w okienku Działania potoku i przeciągnij działanie Przepływ danych na kanwę potoku.
Wybierz nowe działanie Przepływ danych na obszarze roboczym, jeśli nie zostało jeszcze wybrane, oraz jego Ustawienia, w celu edycji jego szczegółów.
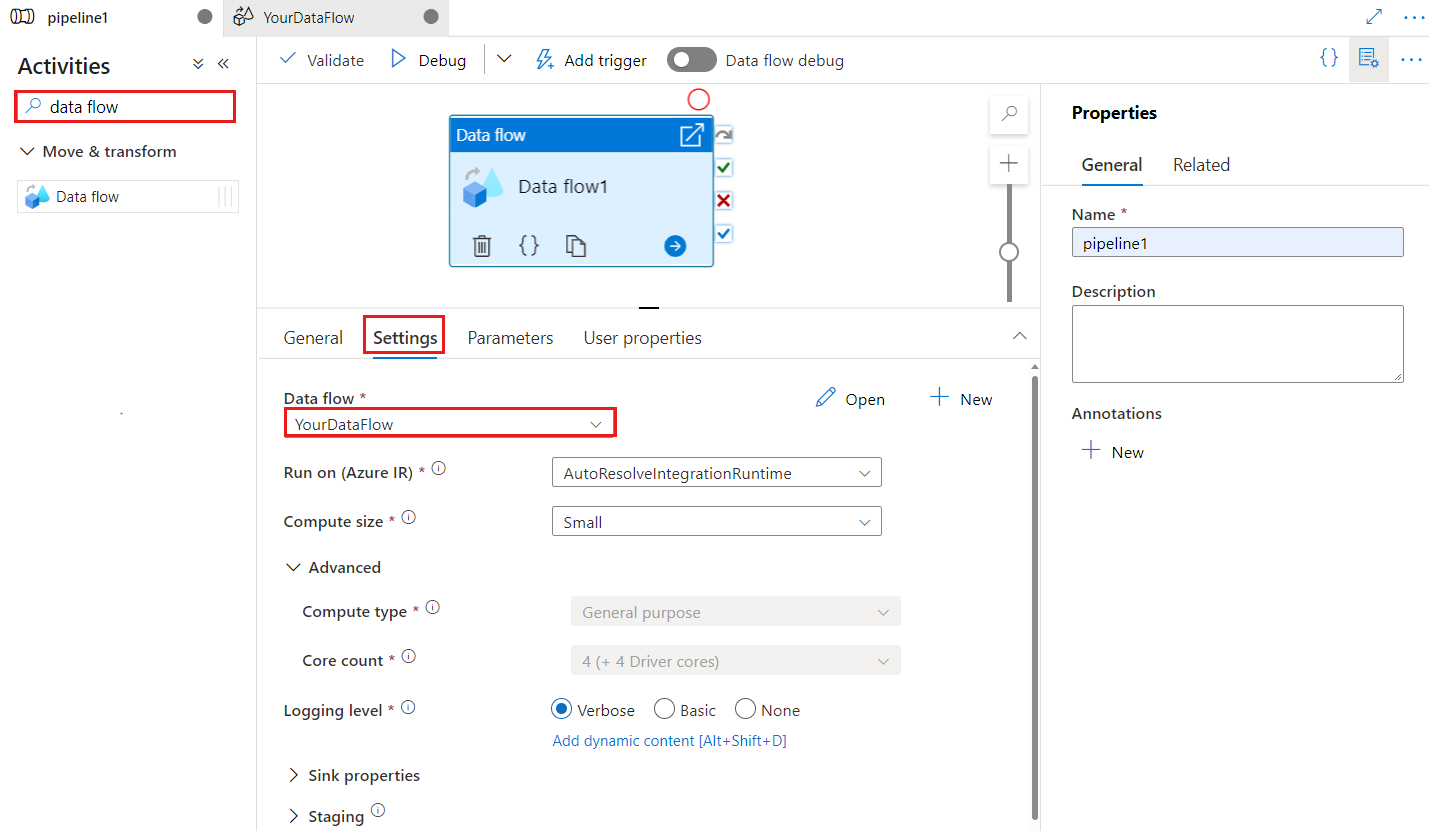
Klucz punktu kontrolnego służy do ustawiania punktu kontrolnego, gdy przepływ danych jest używany do przechwytywania zmienionych danych. Możesz go zastąpić. Działania przepływu danych używają wartości guid jako klucza punktu kontrolnego zamiast kombinacji "nazwa potoku + nazwa działania", aby można było zawsze śledzić stan przechwytywania zmian danych klienta, nawet w przypadku jakichkolwiek akcji zmiany nazwy. Wszystkie istniejące aktywności przepływu danych używają starego klucza wzorca dla zapewnienia zgodności wstecznej. Opcja klucza punktu kontrolnego po opublikowaniu nowej aktywności przepływu danych, w której zasób ma włączone przechwytywanie zmian w danych, jest pokazana poniżej.
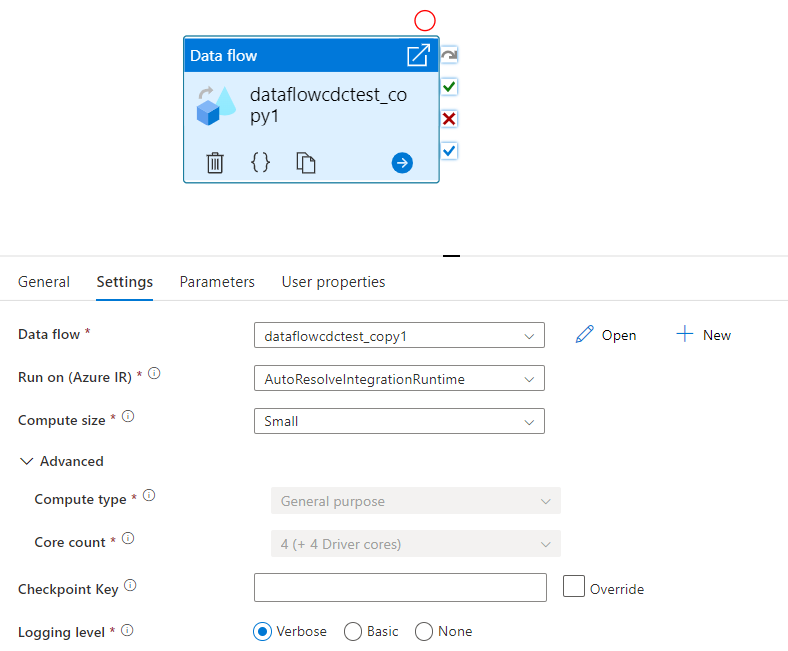
Wybierz istniejący przepływ danych lub utwórz nowy przy użyciu przycisku Nowy. Wybierz inne opcje zgodnie z wymaganiami, aby ukończyć konfigurację.
Składnia
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Właściwości typu
| Właściwości | opis | Dozwolone wartości | Wymagane |
|---|---|---|---|
| przepływ danych | Odwołanie do wykonywanego „przepływu danych” (Przepływ danych) | DataFlowReference | Tak |
| integrationRuntime | Środowisko obliczeniowe, na których działa przepływ danych. Jeśli nie zostanie określone, używane jest środowisko Azure Integration Runtime z funkcją autoresolve. | IntegrationRuntimeReference | Nie. |
| compute.coreCount | Liczba rdzeni używanych w klastrze Spark. Można określić tylko wtedy, gdy używane jest środowisko Azure Integration Runtime z funkcją autoresolve. | 8, 16, 32, 48, 80, 144, 272 | Nie. |
| compute.typObliczeń | Typ technologii obliczeniowej używanej w klastrze Spark. Można określić tylko wtedy, gdy używane jest środowisko Azure Integration Runtime z funkcją autoresolve. | "Ogólne" | Nie. |
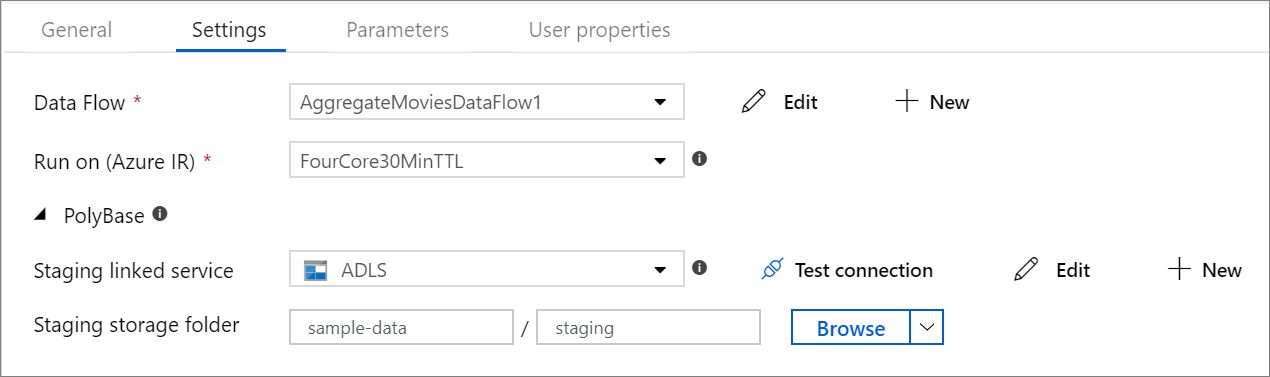
| staging.linkedService | Jeśli używasz źródła lub ujścia Azure Synapse Analytics, określ konto magazynu używane do przejściowego programu PolyBase. Jeśli Azure Storage jest skonfigurowany z punktem końcowym usługi sieci wirtualnej (VNet), musisz użyć uwierzytelniania tożsamości zarządzanej z włączoną funkcją "zezwalaj na zaufaną usługę Microsoft" na koncie magazynu. Odnieś się do Impact of using VNet Service Endpoints with Azure Storage. Poznaj również wymagane konfiguracje Azure Blob i Azure Data Lake Storage Gen2. |
LinkedServiceReference | Tylko wtedy, gdy przepływ danych odczytuje lub zapisuje w Azure Synapse Analytics |
| staging.folderPath | Jeśli używasz źródła lub ujścia Azure Synapse Analytics, ścieżka do folderu w koncie magazynu obiektów blob wykorzystywanym do tymczasowego przechowywania danych przez PolyBase | String | Tylko wtedy, gdy przepływ danych odczytuje lub zapisuje w Azure Synapse Analytics |
| traceLevel | Ustawianie poziomu rejestrowania wykonywania działań przepływu danych | Drobne, Grube, Brak | Nie. |
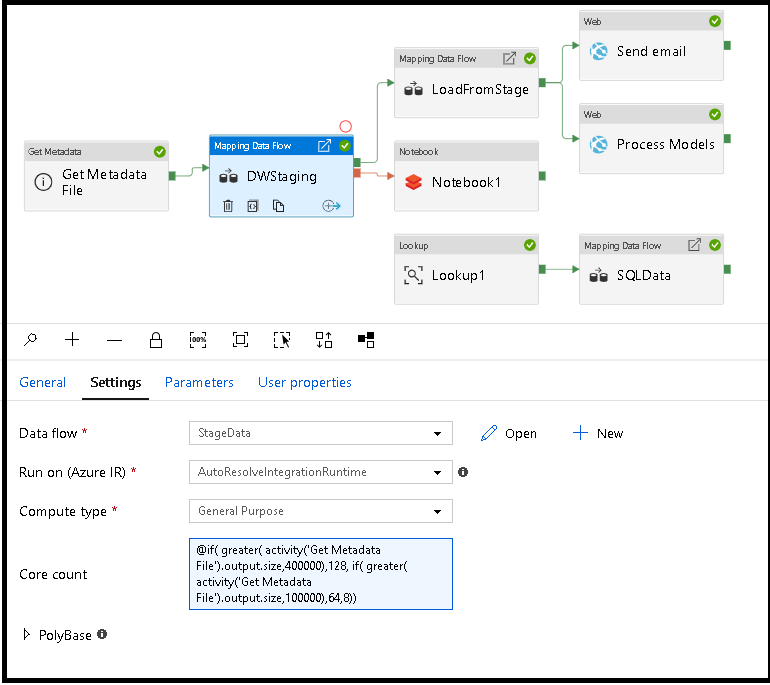
Dynamiczne ustawianie rozmiaru obliczeniowego przepływu danych w czasie wykonywania
Właściwości Liczba rdzeni i Typ obliczeniowy można ustawić dynamicznie, aby dostosować rozmiar przychodzących danych źródłowych w czasie wykonywania. Użyj działań potoku, takich jak Wyszukiwanie lub Pobieranie metadanych, aby znaleźć rozmiar danych źródłowego zestawu danych. Następnie użyj polecenia Dodaj zawartość dynamiczną we właściwościach działania Przepływ danych. Możesz wybrać małe, średnie lub duże rozmiary obliczeniowe. Opcjonalnie wybierz opcję "Niestandardowy" i ręcznie skonfiguruj typy obliczeniowe i liczbę rdzeni.
Oto krótki samouczek wideo wyjaśniający tę technikę
Środowisko uruchomieniowe integracji przepływu danych
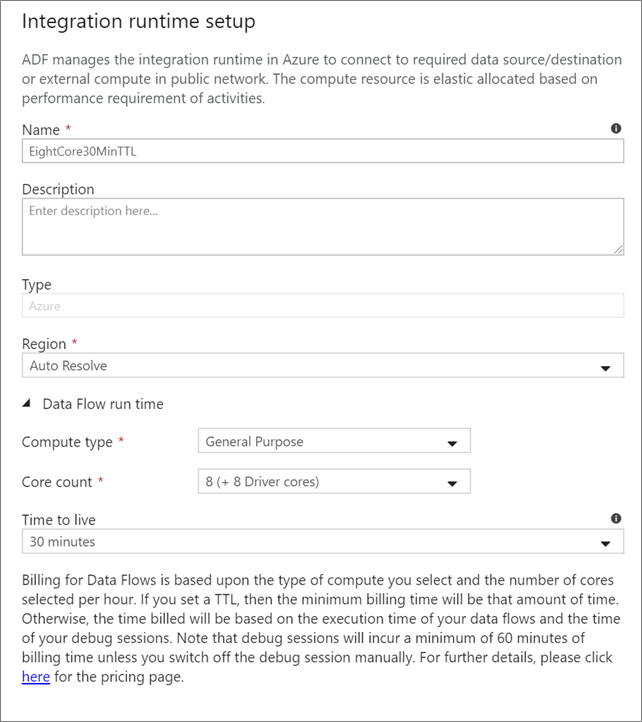
Wybierz środowisko uruchomieniowe integracji do wykonania aktywności przepływu danych. Domyślnie usługa używa funkcji autoresolve w Azure Integration Runtime z czterema rdzeniami roboczymi. ** To IR ma typ obliczeń ogólnego przeznaczenia i działa w tym samym regionie, co instancja usługi. W przypadku potoków zoperacjonalizowanych zdecydowanie zaleca się utworzenie własnych środowisk Azure Integration Runtime, które definiują określone regiony, typ obliczeniowy, liczbę rdzeni i czas życia dla wykonywania działania przepływu danych.
Minimalny typ obliczeniowy ogólnego przeznaczenia z konfiguracją 8+8 (łącznie 16 rdzeni wirtualnych) i 10-minutowym czasem życia (TTL) jest minimalnym zaleceniem dla większości obciążeń produkcyjnych. Ustawiając mały TTL, środowisko IR Azure może utrzymać ciepły klaster, który nie spowoduje naliczenia kilku minut czasu rozpoczęcia dla klastra zimnego. Aby uzyskać więcej informacji, zobacz Azure Integration Runtime.
Ważne
Wybór Integration Runtime w działaniach Przepływ danych dotyczy tylko wykonań wyzwalanych twojego potoku. Debugowanie potoku za pomocą przepływów danych działa na klastrze określonym w sesji debugowania.
PolyBase
Jeśli używasz Azure Synapse Analytics jako ujścia lub źródła, musisz wybrać lokalizację przejściową dla obciążenia wsadowego programu PolyBase. Technologia PolyBase umożliwia ładowanie wsadowe zamiast ładowania danych wiersz po wierszu. Program PolyBase znacząco skraca czas ładowania do Azure Synapse Analytics.
Klucz punktu kontrolnego
W przypadku korzystania z opcji przechwytywania zmian dla źródeł przepływu danych usługa ADF automatycznie obsługuje punkt kontrolny i zarządza nim. Domyślny klucz punktu kontrolnego to skrót nazwy przepływu danych i nazwy potoku. Jeśli używasz wzorca dynamicznego dla tabel źródłowych lub folderów, możesz zastąpić ten skrót i ustawić w tym miejscu własną wartość klucza punktu kontrolnego.
Poziom rejestrowania
Jeśli nie potrzebujesz, aby każde wykonanie potoku przepływu danych rejestrowało szczegółowe dzienniki telemetrii, możesz ustawić poziom rejestrowania na "Podstawowy" lub "Brak". Podczas wykonywania przepływów danych w trybie szczegółowym (ustawienie domyślne) żądasz, aby usługa w pełni rejestrowała aktywność na poziomie poszczególnych partycji podczas przekształcania danych. Może to być kosztowna operacja, dlatego warto włączać tryb szczegółowy tylko podczas rozwiązywania problemów, co może poprawić ogólny przepływ danych i wydajność potoku. Tryb "Podstawowy" rejestruje tylko czasy trwania transformacji, podczas gdy "Brak" zawiera tylko podsumowanie czasów trwania.

Właściwości ujścia
Funkcja grupowania w przepływach danych umożliwia zarówno ustawienie kolejności wykonywania ujścia, jak i grupowanie ujść razem przy użyciu tej samej liczby grupy. Aby ułatwić zarządzanie grupami, możesz poprosić usługę o równoległe uruchamianie ujścia w tej samej grupie. Możesz również ustawić grupę odbiorników, aby kontynuować nawet po wystąpieniu błędu w jednym z odbiorników.
Domyślnym zachowaniem odbiorników przepływu danych jest ich wykonywanie szeregowo i przerwanie przepływu danych w przypadku wystąpienia błędu w odbiorniku. Ponadto wszystkie ujścia są domyślne dla tej samej grupy, chyba że przejdziesz do właściwości przepływu danych i ustawisz różne priorytety ujścia.

Tylko pierwszy wiersz
Ta opcja jest dostępna tylko dla przepływów danych, które mają włączone ujścia pamięci podręcznej dla "Dane wyjściowe do działania". Dane wyjściowe przepływu danych, które są wstrzykiwane bezpośrednio do potoku, są ograniczone do 2 MB. Ustawienie "tylko pierwszego wiersza" pomaga ograniczyć dane wyjściowe przepływu danych podczas przesyłania wyników działania przepływu danych bezpośrednio do potoku.
Parametryzacja Przepływów Danych
Sparametryzowane zestawy danych
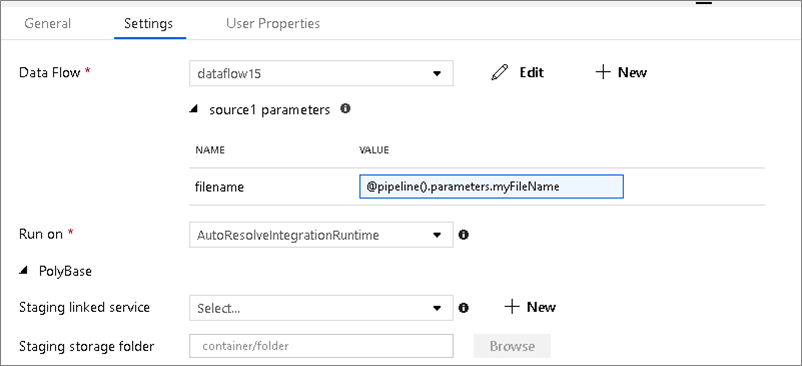
Jeśli przepływ danych używa sparametryzowanych zestawów danych, ustaw wartości parametrów na karcie Ustawienia .
Parametryzowane przepływy danych
Jeśli przepływ danych jest sparametryzowany, określ dynamiczne wartości parametrów przepływu danych w zakładce Parametry. Możesz użyć języka wyrażeń dla potoku lub języka wyrażeń przepływu danych, aby przypisać wartości parametrów dynamicznych lub literałów. Aby uzyskać więcej informacji, zobacz Przepływ danych Parameters.
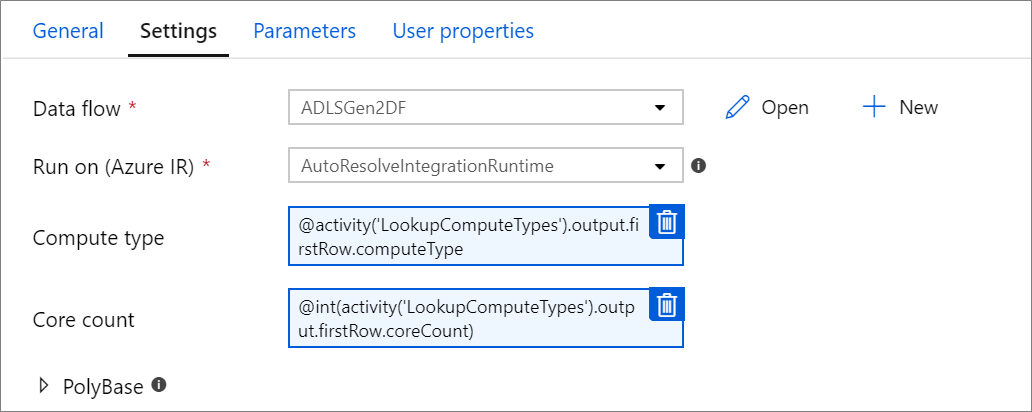
Sparametryzowane właściwości obliczeniowe.
Można sparametryzować liczbę rdzeni lub typ obliczeniowy, jeśli używasz funkcji autoresolve w usłudze Azure Integration Runtime i określisz wartości dla compute.coreCount oraz compute.computeType.
Debugowanie potoku działania Przepływ danych
Aby wykonać uruchomienie potoku debugowania przy użyciu działania Przepływ danych, należy włączyć tryb debugowania data flow za pomocą Przepływ danych Debugowanie suwak na górnym pasku. Tryb debugowania umożliwia uruchamianie przepływu danych na aktywnym klastrze Spark. Aby uzyskać więcej informacji, zobacz Tryb debugowania.

Potok debugowania jest uruchamiany względem aktywnego klastra debugowania, a nie środowiska Integration Runtime określonego w ustawieniach działania Przepływ danych. Podczas uruchamiania trybu debugowania możesz wybrać środowisko obliczeniowe debugowania.
Monitorowanie działania Przepływ danych
Działanie Przepływ danych ma specjalne środowisko monitorowania, w którym można wyświetlać informacje dotyczące partycjonowania, czasu etapu i pochodzenia danych. Otwórz okienko monitorowania za pomocą ikony okularów w obszarze Akcje. Aby uzyskać więcej informacji, zobacz Monitorowanie Przepływów danych.
Użycie działania Przepływ danych powoduje kolejne działanie
Działanie przepływu danych generuje metryki dotyczące liczby wierszy zapisanych w ujściu i wierszach odczytanych z każdego źródła. Te wyniki są zwracane w sekcji output rezultatu uruchomienia aktywności. Zwrócone metryki są w formacie poniższego kodu json.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Aby na przykład uzyskać liczbę wierszy zapisanych w ujściu o nazwie "sink1" w działaniu o nazwie "dataflowActivity", użyj polecenia @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Aby uzyskać liczbę wierszy odczytanych ze źródła o nazwie "source1", które zostało użyte w tym celu, użyj @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Uwaga
Jeśli ujście zawiera zero zapisanych wierszy, nie będzie ono wyświetlane w metrykach. Istnienie można zweryfikować przy użyciu contains funkcji . Na przykład contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') sprawdza, czy jakiekolwiek wiersze zostały zapisane w sink1.
Powiązana zawartość
Zobacz obsługiwane działania przepływu sterowania: