Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Działanie Platformy Spark w fabryce danych i potokach usługi Synapse
Dodawanie działania platformy Spark do potoku za pomocą interfejsu użytkownika
Aby użyć aktywności Spark w potoku, wykonaj następujące kroki:
Wyszukaj Spark w okienku Działania potoku, a następnie przeciągnij działanie Spark na kanwę potoku.
Wybierz nowe działanie platformy Spark na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Klaster HDI, aby wybrać lub utworzyć nową usługę połączoną z klastrem HDInsight, który będzie używany do wykonywania czynności Spark.
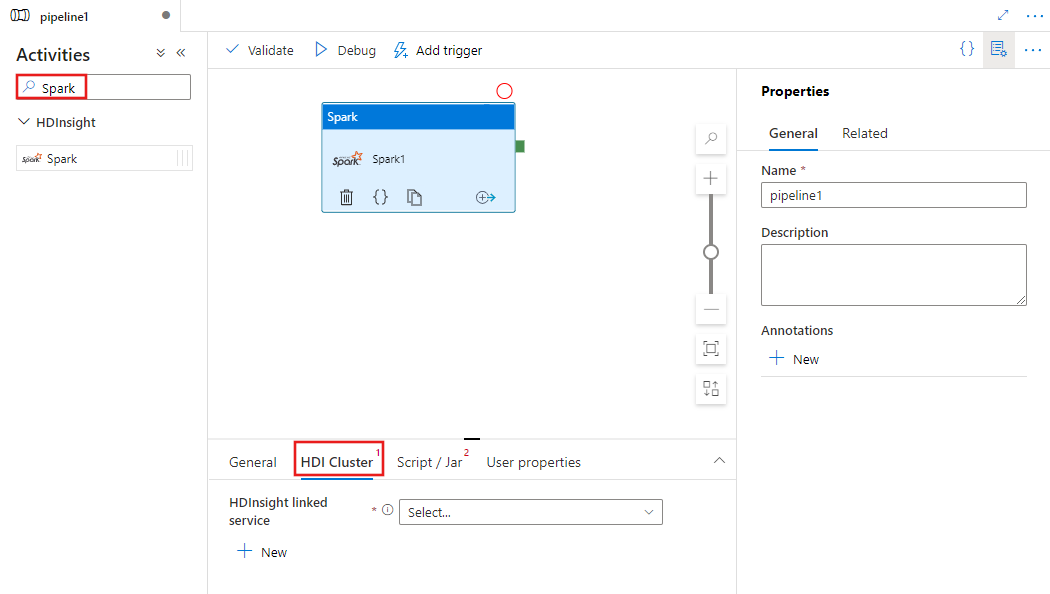
Wybierz zakładkę Script/Jar, aby wybrać lub utworzyć nową połączoną usługę dla nowego zadania z kontem Azure Storage, które będzie hostować Twój skrypt. Określ ścieżkę do pliku, który ma zostać tam wykonany. Możesz również skonfigurować zaawansowane szczegóły, w tym użytkownika serwera proxy, konfigurację debugowania i argumenty oraz parametry konfiguracji platformy Spark, które mają zostać przekazane do skryptu.
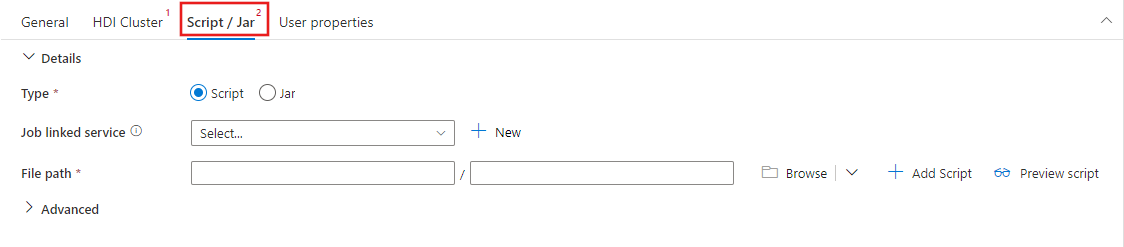
Właściwości działania platformy Spark
Oto przykładowa definicja JSON działania platformy Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwości | Opis | Wymagane |
|---|---|---|
| nazwa | Nazwa działania w pipeline. | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| typ | W przypadku działania platformy Spark typ działania to HDInsightSpark. | Tak |
| linkedServiceName | Nazwa połączonej usługi HDInsight Spark, na której działa program Spark. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| SparkJobLinkedService | Połączona usługa Azure Storage, która zawiera plik zadania platformy Spark, zależności i dzienniki. Obsługiwane są tylko Azure Blob Storage i ADLS Gen2 połączone usługi. Jeśli nie określisz wartości dla tej właściwości, zostanie użyty magazyn skojarzony z klastrem usługi HDInsight. Wartość tej właściwości może być tylko skojarzoną usługą Azure Storage. | Nie. |
| rootPath | Kontener Blob Azure i folder zawierający plik Spark. W nazwie pliku jest uwzględniana wielkość liter. Aby uzyskać szczegółowe informacje na temat struktury tego folderu, zapoznaj się z sekcją struktury folderów (następna sekcja). | Tak |
| entryFilePath | Ścieżka względna do folderu głównego kodu/pakietu Spark. Plik wpisu musi być plikiem Python lub plikiem .jar. | Tak |
| nazwa klasy | Klasa główna aplikacji Java/Spark | Nie. |
| Argumenty | Lista argumentów wiersza polecenia programu Spark. | Nie. |
| proxyUser | Konto użytkownika do personifikacji w celu wykonania programu Spark | Nie. |
| sparkConfig | Określ wartości właściwości konfiguracji platformy Spark wymienione w temacie: Konfiguracja platformy Spark — właściwości aplikacji. | Nie. |
| getDebugInfo | Określa, kiedy pliki dziennika platformy Spark są kopiowane do magazynu Azure używanego przez klaster usługi HDInsight lub określonego przez sparkJobLinkedService. Dozwolone wartości: Brak, Zawsze lub Niepowodzenie. Wartość domyślna: None. | Nie. |
Struktura folderów
Zadania platformy Spark są bardziej rozszerzalne niż zadania Pig/Hive. W przypadku zadań platformy Spark można podać wiele zależności, takich jak pakiety jar (umieszczone w Java CLASSPATH), pliki Python (umieszczone w języku PYTHONPATH) i inne pliki.
Utwórz następującą strukturę folderów w usłudze Azure Blob Storage, do których odwołuje się połączona usługa HDInsight. Następnie przekaż pliki zależne do odpowiednich podfolderów w folderze głównym reprezentowanym przez entryFilePath. Na przykład przekaż pliki Python do podfolderu pyFiles oraz pliki jar do podfolderu jars w folderze głównym. W czasie wykonywania usługa oczekuje następującej struktury folderów w usłudze Azure Blob Storage:
| Ścieżka | Opis | Wymagane | Typ |
|---|---|---|---|
. (katalog główny) |
Ścieżka główna zadania Spark w połączonej usłudze magazynowania | Tak | Folder |
| <zdefiniowany przez użytkownika > | Ścieżka wskazująca plik startowy zadania Spark | Tak | Plik |
| ./jars | Wszystkie pliki w tym folderze są przesyłane i umieszczane na Java classpath klastra. | Nie. | Folder |
| ./pyFiles | Wszystkie pliki w tym folderze są przesyłane i umieszczane na ścieżce PYTHONPATH klastra. | Nie. | Folder |
| ./Pliki | Wszystkie pliki w tym folderze są przekazywane i umieszczane w katalogu roboczym wykonawcy. | Nie. | Folder |
| ./archiwum | Wszystkie pliki w tym folderze są nieskompresowane | Nie. | Folder |
| ./logs | Folder zawierający dzienniki z klastra Spark. | Nie. | Folder |
Oto przykład magazynu zawierającego dwa pliki zadań Spark w Azure Blob Storage, do których odwołuje się usługa powiązana z HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: