Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Tabele systemowe MLflow są dostępne w publicznej wersji zapoznawczej.
Tabele mlflow systemowe przechwytują metadane eksperymentu zarządzane w usłudze śledzenia MLflow. Te tabele umożliwiają uprzywilejowanym użytkownikom korzystanie z narzędzi typu lakehouse usługi Databricks na danych przepływu MLflow we wszystkich obszarach roboczych w regionie. Tabele umożliwiają tworzenie niestandardowych pulpitów nawigacyjnych sztucznej inteligencji/analizy biznesowej, konfigurowanie alertów SQL lub wykonywanie zapytań analitycznych na dużą skalę.
mlflow Za pomocą tabel systemowych użytkownicy mogą odpowiedzieć na pytania, takie jak:
- Które eksperymenty mają najniższą niezawodność?
- Jakie jest średnie wykorzystanie procesora GPU w różnych eksperymentach?
Uwaga / Notatka
Tabele mlflow systemowe zaczęły rejestrować dane MLflow ze wszystkich regionów 2 września 2025 roku. Dane z wcześniejszej daty mogą być niedostępne.
Dostępne tabele
Schemat mlflow zawiera następujące tabele:
-
system.mlflow.experiments_latest: Rejestruje nazwy eksperymentów i zdarzenia miękkiego usuwania. Te dane są podobne do strony eksperymentów w interfejsie użytkownika platformy MLflow. -
system.mlflow.runs_latest: rejestruje informacje o cyklu życia przebiegu, parametry i tagi skojarzone z każdym przebiegiem oraz zagregowane statystyki minimalnych, maksymalnych i najnowszych wartości wszystkich metryk. Te dane są podobne do strony wyników lub szczegółów uruchomień. -
system.mlflow.run_metrics_history: Rejestruje nazwę, wartość, znacznik czasu i krok wszystkich przebiegów, na których zarejestrowano metryki, które mogą być użyte do wykreślenia szczegółowych szeregów czasowych z tych przebiegów. Te dane są podobne do zakładki z metrykami na stronie szczegółów biegów.
Poniżej przedstawiono przykład wykreślenia informacji o przebiegu przy użyciu pulpitu nawigacyjnego:
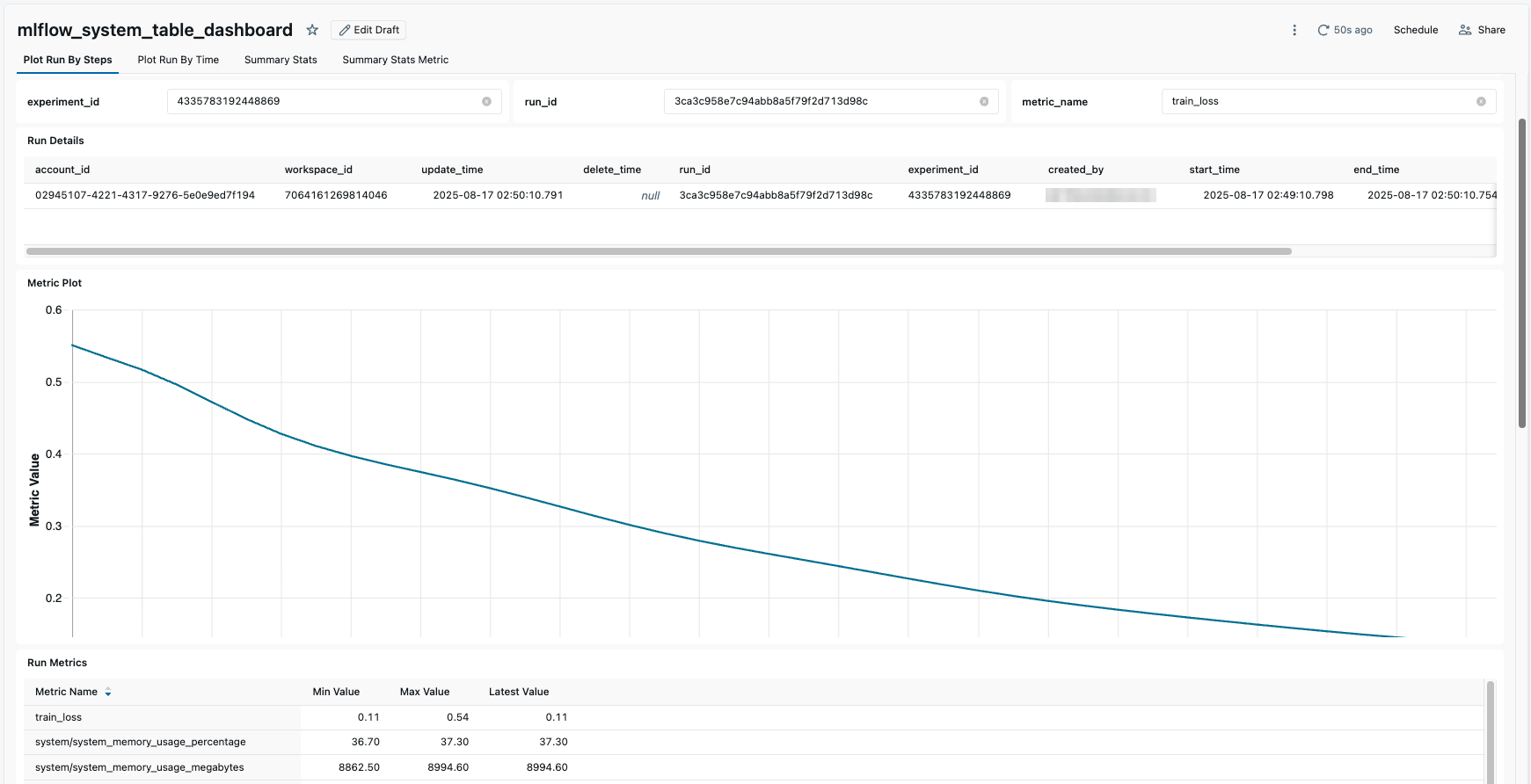
Schematy tabel
Poniżej przedstawiono schematy tabel z opisami i przykładowymi danymi.

system.mlflow.experiments_latest
| Nazwa kolumny | Typ danych | Description | Example | Zanullowalny |
|---|---|---|---|---|
account_id |
ciąg | Identyfikator konta zawierającego eksperyment MLflow | "bd59efba-4444-4444-443f-44444449203" |
Nie. |
update_time |
sygnatura czasowa | Czas systemowy ostatniej aktualizacji eksperymentu | 2024-06-27T00:58:57.000+00:00 |
Nie. |
delete_time |
sygnatura czasowa | Czas systemowy, kiedy eksperyment MLflow został usunięty nietrwale przez użytkownika | 2024-07-02T12:42:59.000+00:00 |
Tak |
experiment_id |
ciąg | Identyfikator eksperymentu MLflow | "2667956459304720" |
Nie. |
workspace_id |
ciąg | Identyfikator obszaru roboczego zawierającego eksperyment MLflow | "6051921418418893" |
Nie. |
name |
ciąg | Podana przez użytkownika nazwa eksperymentu | "/Users/first.last@databricks.com/myexperiment" |
Nie. |
create_time |
sygnatura czasowa | Czas systemowy utworzenia eksperymentu | 2024-06-27T00:58:57.000+00:00 |
Nie. |
system.mlflow.runs_latest
| Nazwa kolumny | Typ danych | Description | Example | Zanullowalny |
|---|---|---|---|---|
account_id |
ciąg | Identyfikator konta zawierającego przebieg MLflow | "bd59efba-4444-4444-443f-44444449203" |
Nie. |
update_time |
sygnatura czasowa | Czas systemowy, kiedy uruchomienie było ostatnio aktualizowane | 2024-06-27T00:58:57.000+00:00 |
Nie. |
delete_time |
sygnatura czasowa | Czas systemowy, gdy uruchomienie MLflow zostało tymczasowo usunięte przez użytkownika | 2024-07-02T12:42:59.000+00:00 |
Tak |
workspace_id |
ciąg | Identyfikator obszaru roboczego zawierającego przebieg MLflow | "6051921418418893" |
Nie. |
run_id |
ciąg | Identyfikator Przebiegu MLflow | "7716d750d279487c95f64a75bff2ad56" |
Nie. |
experiment_id |
ciąg | Identyfikator eksperymentu MLflow zawierającego przebieg MLflow | "2667956459304720" |
Nie. |
created_by |
ciąg | Nazwa głównego podmiotu, użytkownika lub grupy w Databricks, który utworzył przebieg MLflow | "<user>@<domain-name>" |
Tak |
start_time |
sygnatura czasowa | Czas określony przez użytkownika po uruchomieniu platformy MLflow | 2024-06-27T00:58:57.000+00:00 |
Nie. |
end_time |
sygnatura czasowa | Określony przez użytkownika czas zakończenia przebiegu MLflow | 2024-07-02T12:42:59.000+00:00 |
Tak |
run_name |
ciąg | Nazwa przebiegu MLflow |
"wistful-deer-932", "my-xgboost-training-run" |
Nie. |
status |
ciąg | Stan wykonywania uruchomienia MLflow | "FINISHED" |
Nie. |
params |
ciąg mapy<, ciąg> | Parametry klucz i wartość uruchomienia MLflow | {"n_layers": "5", "batch_size": "64", "optimizer": "Adam"} |
Nie. |
tags |
ciąg mapy<, ciąg> | Tagi klucz-wartość ustawione w ramach uruchomienia MLflow | {"ready_for_review": "true"} |
Nie. |
aggregated_metrics |
lista<struktura<ciąg, podwójna, podwójna, podwójna>> | Zagregowany widok podsumowujący metryki w run_metrics_history | [{"metric_name": "training_accuracy", "latest_value": 0.97, "min_value": 0.8, "max_value": 1.0}, ...] |
Nie. |
aggregated_metrics.metric_name |
ciąg | Określona przez użytkownika nazwa metryki | "training_accuracy" |
Nie. |
aggregated_metrics.latest_value |
podwójny | Najnowsza wartość metric_name w serii czasowej tej kombinacji (uruchom, metric_name) w run_metrics_history | 0.97 |
Nie. |
aggregated_metrics.max_value |
podwójny | Maksymalna wartość metric_name w serii czasowej tej kombinacji (uruchom, metric_name) w run_metrics_history. Jeśli dla metryki zarejestrowano dowolną wartość NaN, wartość będzie NaN. | 1.0 |
Nie. |
aggregated_metrics.min_value |
podwójny | Minimalna wartość wskaźnika o nazwie 'metric_name' w szeregach czasowych dla tej kombinacji (run, metric_name) w run_metrics_history. Jeśli dla metryki zarejestrowano dowolną wartość NaN, wartość będzie NaN. | 0.8 |
Nie. |
system.mlflow.run_metrics_history
| Nazwa kolumny | Typ danych | Description | Example | Zanullowalny |
|---|---|---|---|---|
account_id |
ciąg | Identyfikator konta zawierającego przebieg MLflow, do którego zalogowano metrykę. | "bd59efba-4444-4444-443f-44444449203" |
Nie. |
insert_time |
sygnatura czasowa | Czas systemowy, kiedy została wstawiona metryka | 2024-06-27T00:58:57.000+00:00 |
Nie. |
record_id |
ciąg | Unikatowy identyfikator metryki do rozróżnienia między identycznymi wartościami | "Ae1mDT5gFMSUwb+UUTuXMQ==" |
Nie. |
workspace_id |
ciąg | Identyfikator obszaru roboczego zawierającego uruchomienie MLflow, do którego zarejestrowano metrykę | "6051921418418893" |
Nie. |
experiment_id |
ciąg | Identyfikator eksperymentu MLflow zawierającego przebieg MLflow, do którego zapisano metrykę | "2667956459304720" |
Nie. |
run_id |
ciąg | Identyfikator przebiegu MLflow, do którego zarejestrowano metrykę | "7716d750d279487c95f64a75bff2ad56" |
Nie. |
metric_name |
ciąg | Nazwa metryki | "training_accuracy" |
Nie. |
metric_time |
sygnatura czasowa | Czas określony przez użytkownika podczas obliczania metryki | 2024-06-27T00:55:54.1231+00:00 |
Nie. |
metric_step |
bigint | Krok (na przykład epoka) trenowania modelu lub opracowywania agenta, w którym zarejestrowano metrykę. | 10 |
Nie. |
metric_value |
podwójny | Wartość metryki | 0.97 |
Nie. |
Udostępnianie dostępu użytkownikom
Domyślnie tylko administratorzy kont mają dostęp do schematów systemowych. Aby zapewnić dodatkowym użytkownikom dostęp do tabel, administrator konta musi przyznać im uprawnienia USE i SELECT w schemacie system.mlflow. . Zobacz odniesienie dotyczące uprawnień Unity Catalog.
Każdy użytkownik mający dostęp do tych tabel może wyświetlać metadane we wszystkich eksperymentach MLflow dla wszystkich obszarów roboczych na koncie. Aby skonfigurować dostęp do tabeli dla danej grupy zamiast poszczególnych użytkowników, odwołaj się do sekcji Unity Catalog best practices.
Jeśli potrzebujesz bardziej szczegółowej kontroli niż przyznanie wszystkim użytkownikom dostępu do tabeli, możesz użyć widoków dynamicznych z kryteriami niestandardowymi, aby udzielić grupom określonego dostępu. Można na przykład utworzyć widok, który pokazuje tylko rekordy z określonego zestawu identyfikatorów eksperymentów. Po skonfigurowaniu widoku niestandardowego nadaj użytkownikom nazwę widoku, aby mogli wykonywać zapytania względem widoku dynamicznego, a nie bezpośrednio tabelę systemową.
Uwaga / Notatka
Nie można bezpośrednio zsynchronizować uprawnień eksperymentu MLflow z uprawnieniami katalogu Unity.
Przykładowe przypadki użycia metadanych MLflow
W poniższych sekcjach przedstawiono przykłady użycia tabel systemowych MLflow do odpowiadania na pytania dotyczące eksperymentów i przebiegów platformy MLflow.
Konfigurowanie alertu SQL pod kątem niskiej niezawodności eksperymentu
Korzystając z alertów SQL usługi Databricks (publiczna wersja zapoznawcza), możesz zaplanować regularne cykliczne zapytanie i otrzymywać powiadomienia, jeśli nie zostaną już spełnione pewne ograniczenia.
Przykład ten tworzy alert, który analizuje najczęściej uruchamiane eksperymenty w twoim obszarze roboczym, aby określić, czy mają niską niezawodność i mogą wymagać szczególnej uwagi. Zapytanie używa tabeli runs_latest do obliczenia stosunku przebiegów oznaczonych jako zakończone w eksperymencie do łącznej liczby przebiegów.
Uwaga / Notatka
Funkcja Alerty SQL jest obecnie dostępna w publicznej wersji zapoznawczej i można również używać starszych alertów .
Kliknij
 w pasku bocznym, a następnie kliknij Utwórz alert.
w pasku bocznym, a następnie kliknij Utwórz alert.Skopiuj i wklej następujące zapytanie w edytorze zapytań.
SELECT experiment_id, AVG(CASE WHEN status = 'FINISHED' THEN 1.0 ELSE 0.0 END) AS success_ratio, COUNT(status) AS run_count FROM system.mlflow.runs_latest WHERE status IS NOT NULL GROUP BY experiment_id ORDER BY run_count DESC LIMIT 20;W polu Warunek ustaw warunki na
MIN success_ratio < 0.9. Spowoduje to wyzwolenie alertu, jeśli którykolwiek z 20 najlepszych eksperymentów (według liczby przebiegów) ma współczynnik powodzenia mniejszy niż 90%.
Ponadto można przetestować warunek, ustawić harmonogram i skonfigurować powiadomienia. Aby uzyskać więcej informacji na temat konfigurowania alertu, zobacz Konfigurowanie alertu SQL. Poniżej przedstawiono przykładową konfigurację przy użyciu zapytania.
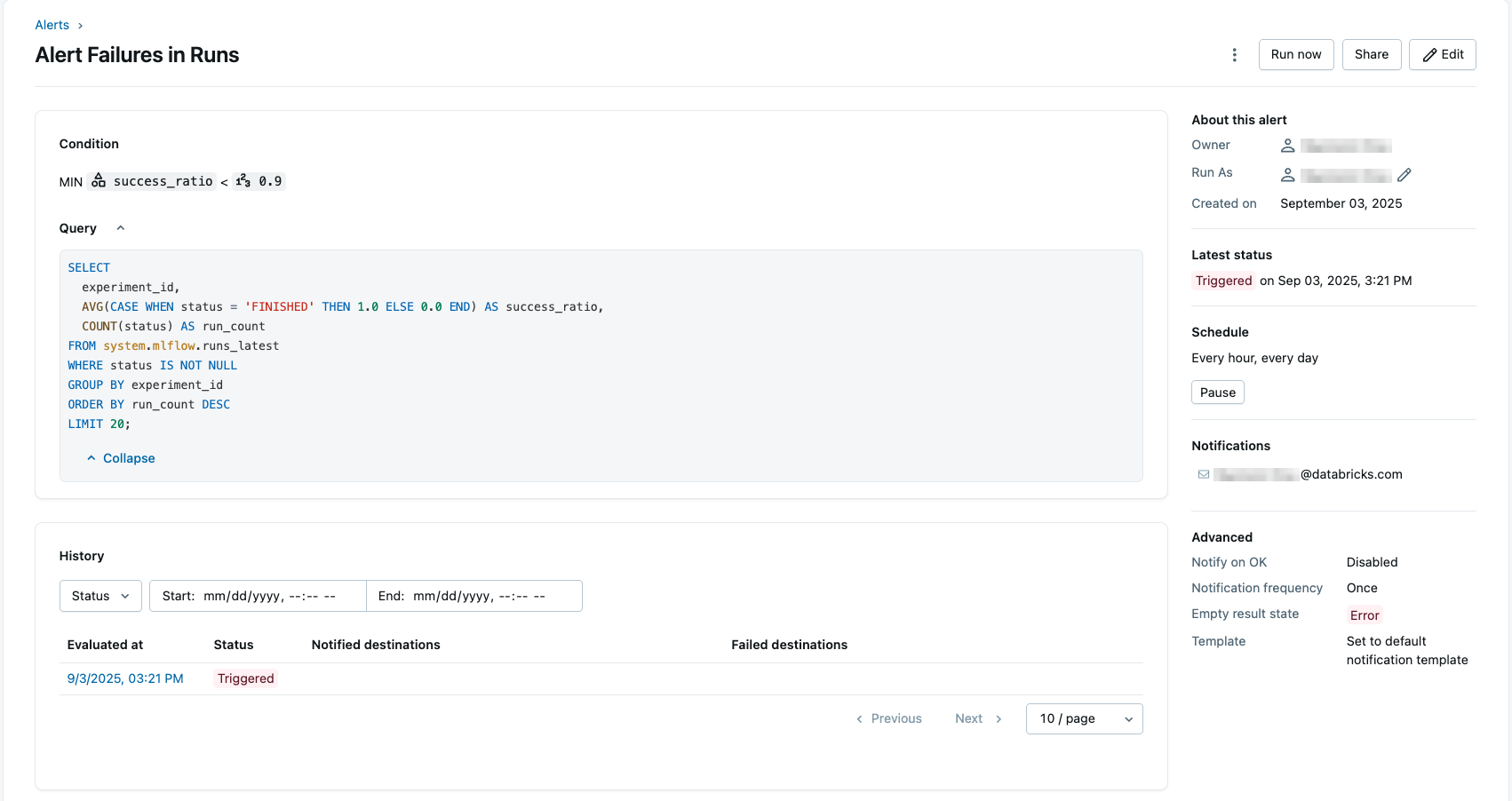
Przykładowe zapytania
Poniższe przykładowe zapytania umożliwiają uzyskanie informacji o działaniu platformy MLflow na koncie przy użyciu usługi Databricks SQL. Możesz również korzystać z narzędzi, takich jak notesy języka Python za pomocą platformy Spark.
Uzyskiwanie informacji o uruchomieniu z runs_latest
SELECT
run_name,
date(start_time) AS start_date,
status,
TIMESTAMPDIFF(MINUTE, start_time, end_time) AS run_length_minutes
FROM system.mlflow.runs_latest
WHERE
experiment_id = :experiment_id
AND run_id = :run_id
LIMIT 1
Zwraca informacje o danym przebiegu:

Pobierz informacje o eksperymencie i uruchomieniu z experiments_latest i runs_latest
SELECT
runs.run_name,
experiments.name,
date(runs.start_time) AS start_date,
runs.status,
TIMESTAMPDIFF(MINUTE, runs.start_time, runs.end_time) AS run_length_minutes
FROM system.mlflow.runs_latest runs
JOIN system.mlflow.experiments_latest experiments ON runs.experiment_id = experiments.experiment_id
WHERE
runs.experiment_id = :experiment_id
AND runs.run_id = :run_id
LIMIT 1
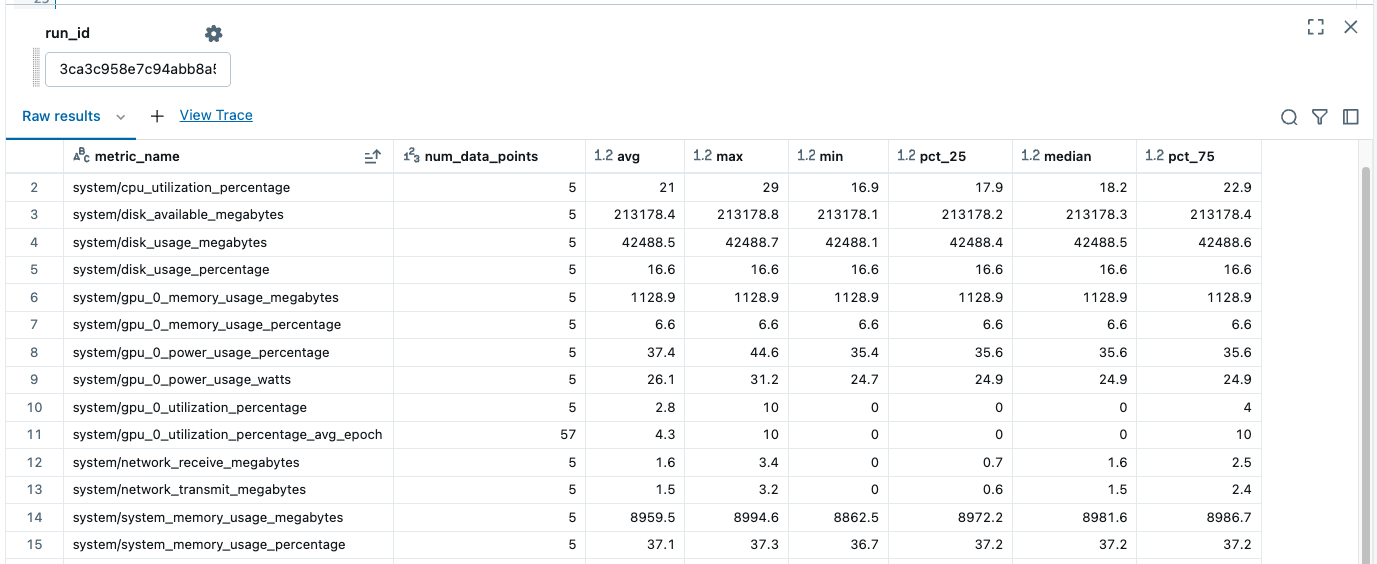
Uzyskaj statystyki podsumowujące dla danego przebiegu run_metrics_history
SELECT
metric_name,
count(metric_time) AS num_data_points,
ROUND(avg(metric_value), 1) AS avg,
ROUND(max(metric_value), 1) AS max,
ROUND(min(metric_value), 1) AS min,
ROUND(PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY metric_value), 1) AS pct_25,
ROUND(PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY metric_value), 1) AS median,
ROUND(PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY metric_value), 1) AS pct_75
FROM
system.mlflow.run_metrics_history
WHERE
run_id = :run_id
GROUP BY
metric_name, run_id
LIMIT 100
Spowoduje to zwrócenie podsumowania metryk dla danego run_idelementu :
Pulpity nawigacyjne dla eksperymentów i przebiegów
Pulpity nawigacyjne można tworzyć na podstawie danych tabel systemowych MLflow, aby analizować eksperymenty MLflow i uruchamiać je z całego obszaru roboczego.
Aby uzyskać więcej informacji, zobacz Build dashboards with MLflow metadata in system tables (Tworzenie pulpitów nawigacyjnych za pomocą metadanych platformy MLflow w tabelach systemowych)