Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób używania przebiegów platformy MLflow do wyświetlania i analizowania wyników eksperymentu trenowania modelu oraz sposobu zarządzania przebiegami i organizowania ich. Aby uzyskać więcej informacji na temat eksperymentów MLflow, zobacz Organizowanie przebiegów trenowania przy użyciu eksperymentów MLflow.
Uruchomienie platformy MLflow odpowiada pojedynczemu wykonaniu kodu modelu. Każdy przebieg rejestruje informacje, takie jak notatnik, który uruchomił przebieg, ewentualnie wszystkie modele utworzone przez przebieg, parametry modelu i metryki zapisane jako pary klucz-wartość, etykiety dla metadanych dotyczących przebiegu oraz wszystkie artefakty lub pliki wyjściowe utworzone w jego trakcie.
Wszystkie uruchomienia MLflow są rejestrowane w aktywnym eksperymencie. Jeśli nie ustawiłeś eksperymentu jawnie jako aktywnego eksperymentu, przebiegi są rejestrowane w eksperymencie w notebooku.
Wyświetlanie szczegółów przebiegu
Możesz uzyskać dostęp do uruchomienia ze strony szczegółów eksperymentu lub bezpośrednio z notatnika, który utworzył uruchomienie.
Na stronie szczegółów eksperymentu kliknij nazwę przebiegu w tabeli przebiegów.
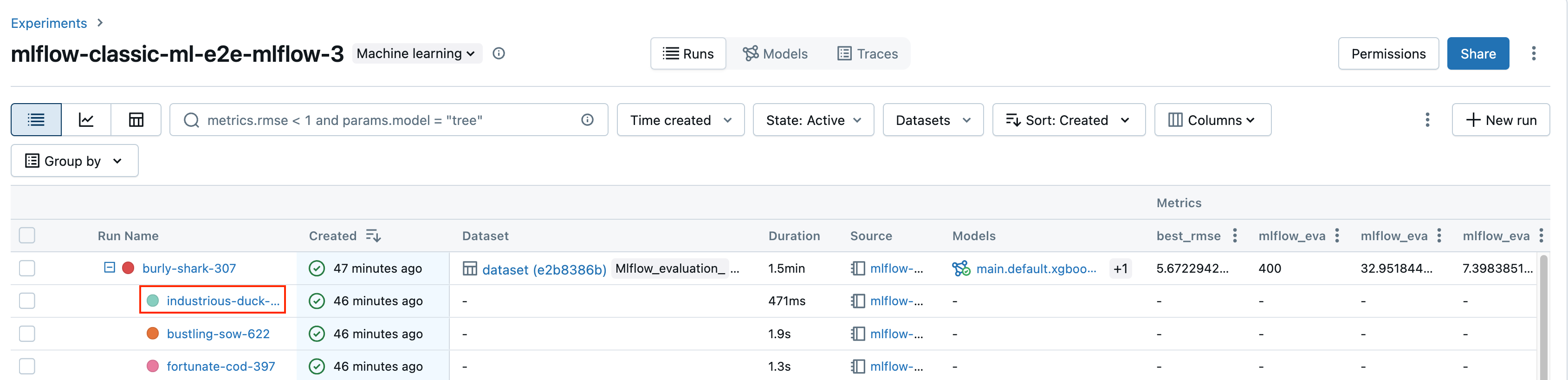
W notatniku kliknij nazwę przebiegu na pasku bocznym "Przebiegi eksperymentów".
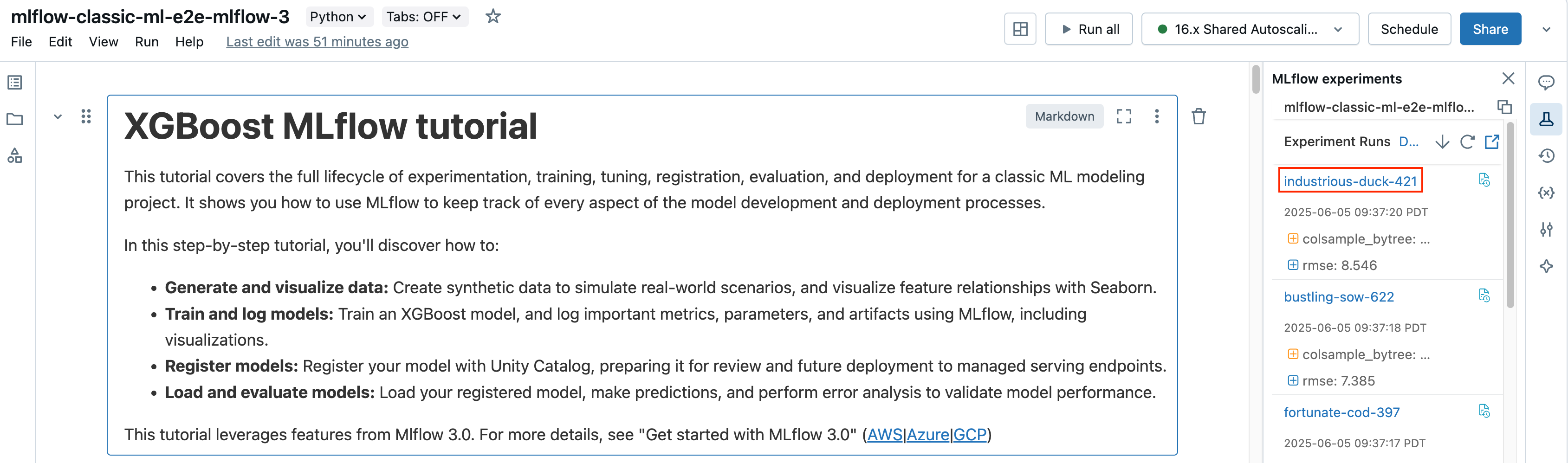
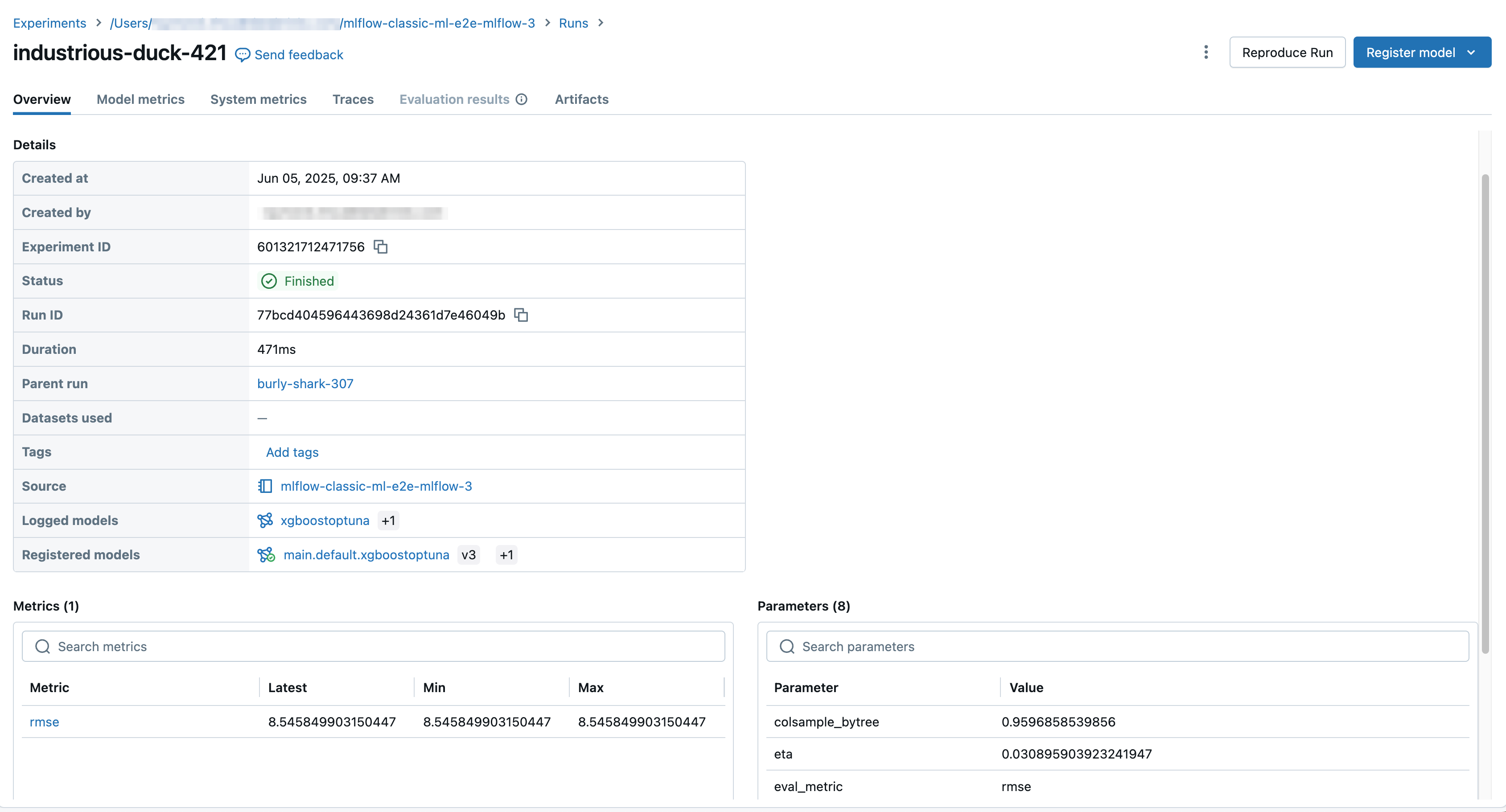
Na ekranie uruchamiania jest wyświetlany identyfikator przebiegu, parametry używane dla przebiegu, metryki wynikające z przebiegu oraz szczegółowe informacje o przebiegu, w tym link do notesu źródłowego. Artefakty zapisane w przebiegu są dostępne na karcie Artifacts.
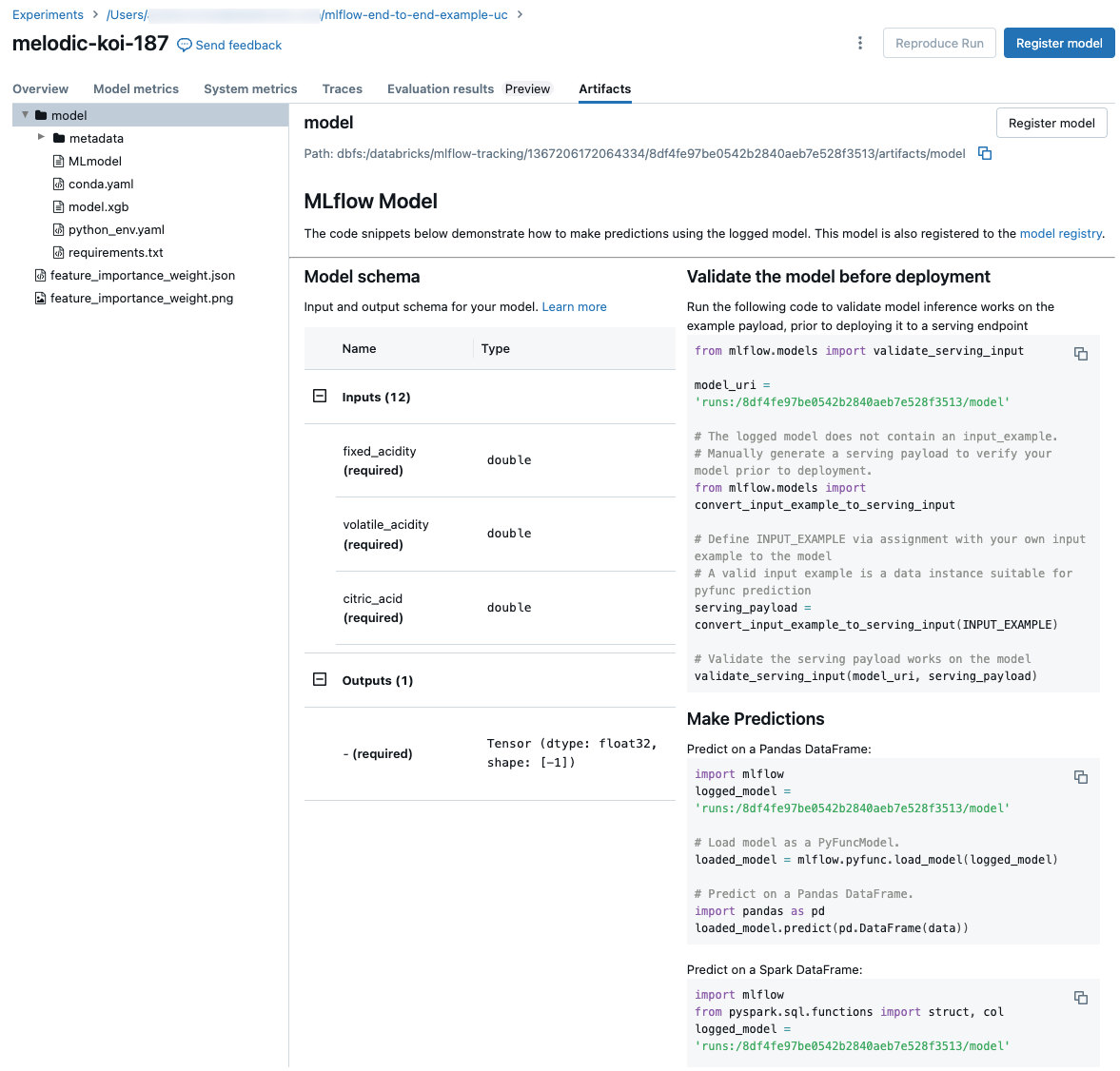
Fragmenty kodu do przewidywania
Jeśli logujesz model z przebiegu, model pojawi się na karcie Artifacts wraz z fragmentami kodu ilustrującymi sposób ładowania i używania modelu do przewidywania ramek danych Spark i Pandas. W środowisku MLflow 3 modele są teraz odrębnym obiektem pierwszej klasy, a nie rejestrowanym jako artefakt uruchamiania. Aby uzyskać więcej informacji, zobacz Wprowadzenie do platformy MLflow 3 dla modeli.
Zobacz notatnik używany do uruchomienia
Aby wyświetlić wersję notesu, która utworzyła uruchomienie.
- Na stronie szczegółów eksperymentu kliknij link w kolumnie Źródła.
- Na stronie uruchamiania kliknij link obok pozycji Źródło.
- W notesie, na pasku bocznym Przebiegi eksperymentów, kliknij ikonę w polu tego przebiegu eksperymentu.
Wersja notatnika powiązanego z uruchomieniem jest wyświetlana w oknie głównym z paskiem podświetlenia przedstawiającym datę i godzinę uruchomienia.
Dodawanie tagu do przebiegu
Tagi to pary klucz-wartość, które można utworzyć i użyć później do wyszukiwania przebiegów.
W tabeli Szczegóły na stronie uruchamiania kliknij pozycję Dodaj tagi obok pozycji Tagi.

Zostanie otwarte okno dialogowe Dodawanie/edytowanie tagów. W polu klucz wprowadź nazwę klucza, a następnie kliknij Dodaj tag.
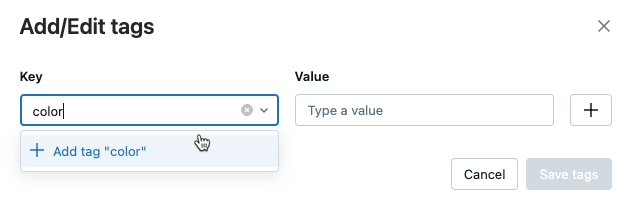
W polu Wartość wprowadź wartość tagu.
Kliknij znak plusa, aby zapisać wprowadzoną parę klucz-wartość.
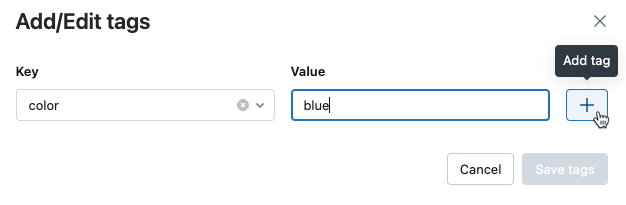
Aby dodać dodatkowe tagi, powtórz kroki od 2 do 4.
Po zakończeniu kliknij pozycję Zapisz tagi.
Edytowanie lub usuwanie tagu dla przebiegu
W tabeli Szczegóły na stronie uruchamiania kliknij
 Obok istniejących tagów.
Obok istniejących tagów.
Zostanie otwarte okno dialogowe Dodawanie/edytowanie tagów.
Aby usunąć tag, kliknij znak X na tym tagu.
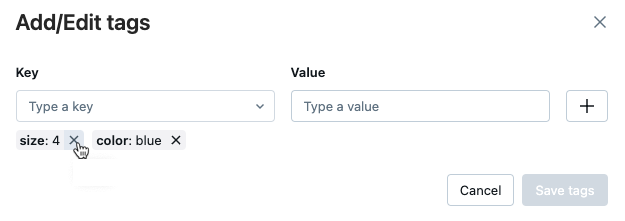
Aby edytować tag, wybierz klucz z menu rozwijanego i edytuj wartość w polu Wartość. Kliknij znak plusa, aby zapisać zmianę.
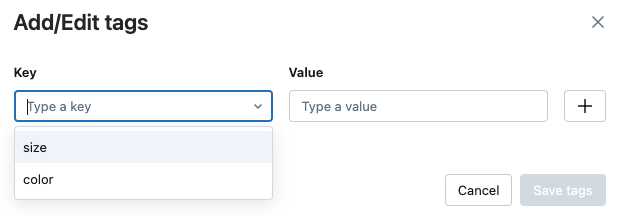
Po zakończeniu kliknij pozycję Zapisz tagi.
Odtworzenie środowiska oprogramowania dla sesji uruchomieniowej
Możesz odtworzyć dokładne środowisko oprogramowania dla przebiegu, klikając Odtwórz przebieg w prawym górnym rogu strony przebiegu. Zostanie wyświetlone następujące okno dialogowe:
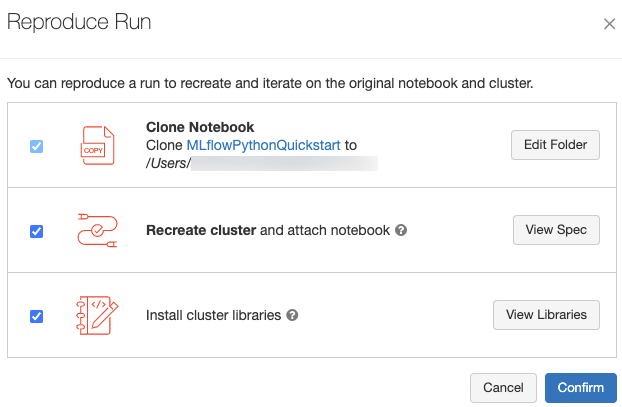
Przy użyciu ustawień domyślnych po kliknięciu przycisku Potwierdź:
- Notebook zostaje sklonowany do lokalizacji wyświetlanej w oknie dialogowym.
- Jeśli oryginalny klaster nadal istnieje, sklonowany notatnik zostaje dołączony do oryginalnego klastra, a następnie klaster jest uruchamiany.
- Jeśli oryginalny klaster już nie istnieje, zostanie utworzony i uruchomiony nowy klaster z tą samą konfiguracją, w tym wszystkie zainstalowane biblioteki. Notebook jest dołączony do nowego klastra.
Możesz wybrać inną lokalizację sklonowanego notesu i sprawdzić konfigurację klastra i zainstalowane biblioteki:
- Aby wybrać inny folder do zapisania sklonowanego notesu, kliknij pozycję Edytuj folder.
- Aby wyświetlić specyfikację klastra, kliknij pozycję Wyświetl specyfikację. Aby sklonować tylko notatnik, a nie klaster, odznacz tę opcję.
- Jeśli oryginalny klaster już nie istnieje, możesz wyświetlić biblioteki zainstalowane w oryginalnym klastrze, klikając pozycję Wyświetl biblioteki. Jeśli oryginalny klaster nadal istnieje, ta sekcja jest wyszarajona.
Zmień nazwę uruchomienia
Aby zmienić nazwę przebiegu, kliknij ![]() w prawym górnym rogu strony przebiegu (obok przycisku Uprawnienia) i wybierz Zmień nazwę.
w prawym górnym rogu strony przebiegu (obok przycisku Uprawnienia) i wybierz Zmień nazwę.
Wybieranie kolumn do wyświetlenia
Aby kontrolować kolumny wyświetlane w tabeli przebiegów na stronie szczegółów eksperymentu, kliknij Kolumny i wybierz z menu rozwijanego.
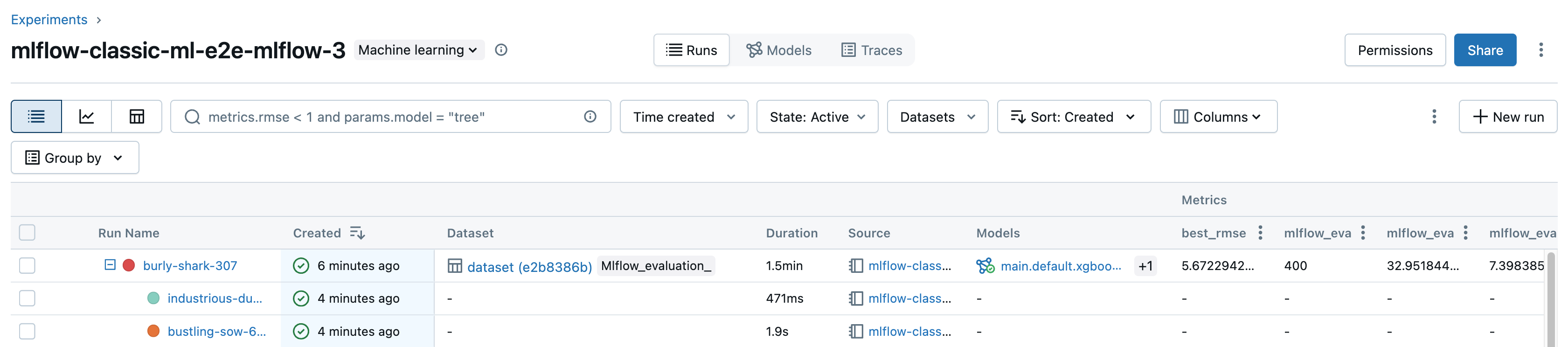
Uruchomienia filtrów
Możesz wyszukać przebiegi w tabeli na stronie szczegółów eksperymentu na podstawie parametrów lub wartości metryk. Możesz również wyszukać uruchomienia według tagu.
Aby wyszukać uruchomienia zgodne z wyrażeniem zawierającym wartości parametrów i metryk, wprowadź zapytanie w polu wyszukiwania i naciśnij Enter. Oto kilka przykładów składni zapytań:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Domyślnie wartości metryk są filtrowane na podstawie ostatniej zarejestrowanej wartości. Użycie
MINlubMAXumożliwia wyszukiwanie przebiegów odpowiednio na podstawie minimalnych lub maksymalnych wartości metryk. Tylko przebiegi rejestrowane po sierpniu 2024 r. mają minimalne i maksymalne wartości metryk.Aby wyszukać uruchomienia według tagu, wprowadź tagi w formacie:
tags.<key>="<value>". Wartości ciągu muszą być ujęte w cudzysłowy, jak pokazano.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Zarówno klucze, jak i wartości mogą zawierać spacje. Jeśli klucz zawiera spacje, należy go ująć w apostrofy zwrotne, jak pokazano.
tags.`my custom tag` = "my value"
Można również filtrować przebiegi na podstawie ich stanu (aktywne lub usunięte), gdy przebieg został utworzony i jakie zestawy danych zostały użyte. W tym celu należy dokonać wyboru z menu rozwijanych Czas utworzony, Stanlub Datasets.
Przebiegi pobierania
Przebiegi można pobrać ze strony szczegółów eksperymentu w następujący sposób:
Kliknij
 Aby otworzyć menu kebab.
Aby otworzyć menu kebab.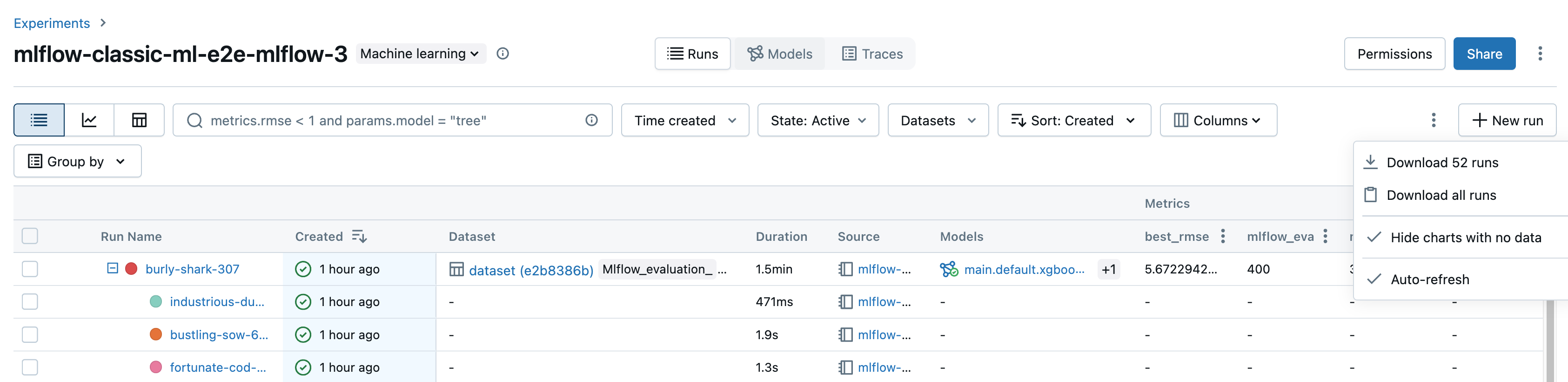
Aby pobrać plik w formacie CSV zawierający wszystkie pokazywane uruchomienia (maksymalnie 100), wybierz opcję Pobierz
<n>uruchomienia. MLflow tworzy i pobiera plik z jednym wykonaniem na wiersz, zawierający następujące pola dla każdego wykonania:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Jeśli chcesz pobrać więcej niż 100 przebiegów lub chcesz pobrać przebiegi za pomocą oprogramowania, wybierz Pobierz wszystkie przebiegi. Zostanie otwarte okno dialogowe z fragmentem kodu, który można skopiować lub otworzyć w notesie. Po uruchomieniu tego kodu w komórce notesu wybierz pozycję Pobierz wszystkie wiersze z danych wyjściowych komórki.
Usuwanie przebiegów
Możesz usunąć przebiegi ze strony szczegółów eksperymentu, wykonując następujące kroki:
- W eksperymencie zaznacz jeden lub więcej przebiegów, klikając pole wyboru po lewej stronie każdego przebiegu.
- Kliknij Usuń.
- Jeśli przebieg jest przebiegiem nadrzędnym, zdecyduj, czy chcesz również usunąć przebiegi elementów potomnych. Ta opcja jest domyślnie wybrana.
- Kliknij przycisk Usuń , aby potwierdzić. Usunięte przebiegi są zapisywane przez 30 dni. Aby wyświetlić usunięte przebiegi, wybierz pozycję Usunięto w polu Stan.
Operacje usuwania zbiorczego są uruchamiane na podstawie czasu tworzenia
Python pozwala na zbiorcze usuwanie przebiegów eksperymentu, które zostały utworzone przed lub w momencie danego znacznika czasu systemu UNIX.
Za pomocą środowiska Databricks Runtime 14.1 lub nowszego można wywołać interfejs API mlflow.delete_runs, aby usunąć zadania i zwrócić liczbę usuniętych zadań.
Poniżej przedstawiono mlflow.delete_runs parametry:
-
experiment_id: identyfikator eksperymentu zawierającego przebiegi do usunięcia. -
max_timestamp_millis: Maksymalny znacznik czasu utworzenia w milisekundach od epoki systemu UNIX dla usuwania uruchomień. Usuwane są tylko uruchomienia utworzone przed tym znacznikiem czasu lub w jego momencie. -
max_runs:Fakultatywny. Maksymalna dodatnia liczba całkowita wskazująca liczbę przebiegów do usunięcia. Maksymalna dozwolona wartość dla max_runs to 10000. Jeśli nie zostanie określony,max_runswartość domyślna to 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Za pomocą środowiska Databricks Runtime 13.3 LTS lub starszego można uruchomić następujący kod klienta w notesie usługi Azure Databricks.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Zapoznaj się z dokumentacją interfejsu API eksperymentów usługi Azure Databricks, aby uzyskać informacje o parametrach i specyfikacji wartości zwracanych dla usuwania przebiegów na podstawie czasu tworzenia.
Przebiegi przywracania
Możesz przywrócić poprzednio usunięte uruchomienia z interfejsu użytkownika w następujący sposób:
- Na stronie Experiment, w polu State, wybierz Deleted, aby pokazać usunięte uruchomienia.
- Zaznacz co najmniej jeden przebieg, klikając pole wyboru po lewej stronie listy przebiegów.
- Kliknij przycisk Przywróć.
- Kliknij przycisk Przywróć , aby potwierdzić. Przywrócone uruchomienia są teraz wyświetlane po wybraniu Aktywne w polu Stan.
Operacje przywracania zbiorczego są uruchamiane na podstawie czasu usunięcia
Możesz również użyć języka Python, aby zbiorczo przywrócić przebiegi eksperymentu, który został usunięty przy lub po sygnaturze czasowej systemu UNIX.
Za pomocą środowiska Databricks Runtime 14.1 lub nowszego można wywołać interfejs API mlflow.restore_runs, aby przywrócić przebiegi i zwrócić liczbę przywróconych przebiegów.
Poniżej przedstawiono mlflow.restore_runs parametry:
-
experiment_id: identyfikator eksperymentu zawierającego przebiegi do przywrócenia. -
min_timestamp_millis: minimalny czas usunięcia w milisekundach od epoki systemu UNIX do przywracania sesji. Przywracane są tylko przebiegi usunięte w momencie lub po tej sygnaturze czasowej. -
max_runs:Fakultatywny. Dodatnia liczba całkowita wskazująca maksymalną liczbę uruchomień do przywrócenia. Maksymalna dozwolona wartość dla max_runs to 10000. Jeśli nie zostanie określony, domyślna wartość max_runs to 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Za pomocą środowiska Databricks Runtime 13.3 LTS lub starszego można uruchomić następujący kod klienta w notesie usługi Azure Databricks.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Proszę zapoznać się z dokumentacją interfejsu API eksperymentów usługi Azure Databricks w celu uzyskania informacji o parametrach i specyfikacjach wartości zwracanej dla przywracania przebiegów w oparciu o czas ich usunięcia.
Porównywanie przebiegów
Możesz porównać przebiegi z jednego eksperymentu lub z wielu eksperymentów. Na stronie Porównanie przebiegów przedstawiono informacje o wybranych przebiegach w formacie tabelarycznym. Można także tworzyć wizualizacje wyników i tabele zawierające informacje o przebiegach, parametrach oraz metrykach. Zobacz Porównaj przebiegi i modele MLflow przy użyciu wykresów i diagramów.
W tabelach Parametry i metryki są wyświetlane parametry przebiegu i metryki ze wszystkich wybranych przebiegów. Kolumny w tych tabelach są identyfikowane przez tabelę Szczegóły uruchamiania bezpośrednio nad. Dla uproszczenia można ukryć parametry i metryki, które są identyczne we wszystkich wybranych przebiegach, wybierając  .
.
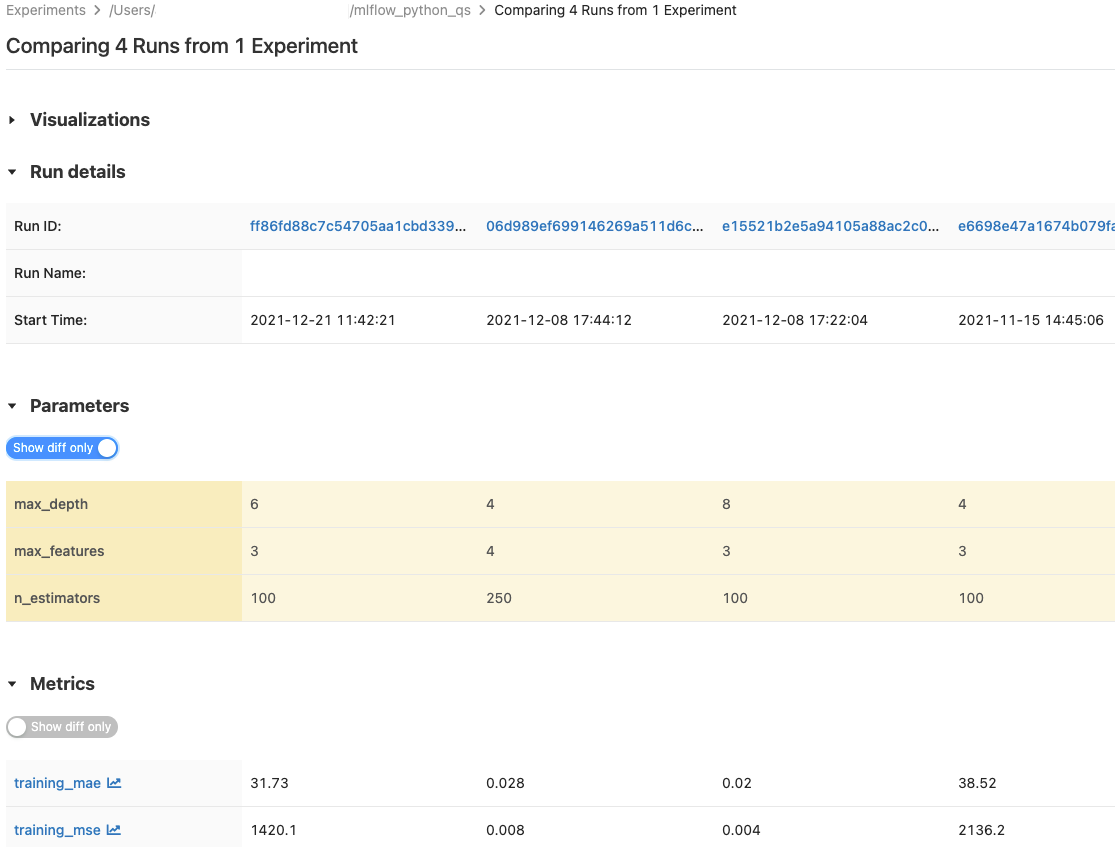
Porównanie przebiegów z jednego eksperymentu
- Na stronie szczegółów eksperymentu wybierz co najmniej dwa przebiegi, klikając pole wyboru po lewej stronie każdego z nich, lub zaznacz wszystkie przebiegi, zaznaczając pole wyboru na górze kolumny.
- Kliknij pozycję Porównaj. Zostanie wyświetlony ekran porównania przebiegów
<N>.
Porównanie przebiegów z wielu eksperymentów
- Na stronie Eksperymenty wybierz eksperymenty, które chcesz porównać, klikając pole po lewej stronie nazwy eksperymentu.
- Kliknij pozycję Porównaj (n) (n to liczba wybranych eksperymentów). Zostanie wyświetlony ekran przedstawiający wszystkie przebiegi z wybranych eksperymentów.
- Zaznacz co najmniej dwa procesy, klikając pole zaznaczenia po lewej stronie procesu lub zaznacz wszystkie procesy, zaznaczając pole na górze kolumny.
- Kliknij pozycję Porównaj. Pojawi się ekran porównywania
<N>przebiegów.
Porównywanie przebiegów przy użyciu tabel systemowych
Metadane MLflow dla eksperymentów i przebiegów są również dostępne w tabelach systemowych, w których można korzystać z Databricks SQL i wszystkich narzędzi oferowanych przez Databricks Lakehouse do analizowania danych eksperymentu. Aby uzyskać więcej informacji, zobacz dokumentację tabel systemowych MLflow.
Kopiowanie przebiegów między obszarami roboczymi
Aby zaimportować lub wyeksportować przebiegi MLflow do lub z obszaru roboczego usługi Databricks, możesz użyć projektu rozwijanego przez społeczność open source MLflow Export-Import.