Federacja z wieloma lokacjami i wieloma regionami
Wiele zaawansowanych rozwiązań wymaga udostępnienia tych samych strumieni zdarzeń do użycia w wielu lokalizacjach lub wymagają zbierania strumieni zdarzeń w wielu lokalizacjach, a następnie konsolidowania w określonej lokalizacji do użycia. Często istnieje również potrzeba wzbogacania lub zmniejszania strumieni zdarzeń lub konwersji formatu zdarzeń, również w jednym regionie i rozwiązaniu.
Praktycznie oznacza to, że rozwiązanie będzie obsługiwać wiele centrów zdarzeń, często w różnych regionach i przestrzeniach nazw usługi Event Hubs, a następnie replikować zdarzenia między nimi. Możesz również wymieniać zdarzenia ze źródłami i miejscami docelowymi, takimi jak Azure Service Bus, Azure IoT Hub lub Apache Kafka.
Obsługa wielu aktywnych centrów zdarzeń w różnych regionach umożliwia również klientom wybieranie i przełączanie się między nimi, jeśli ich zawartość jest scalona, co sprawia, że ogólny system jest bardziej odporny na problemy z dostępnością regionalną.
W tym rozdziale "Federacja" opisano wzorce federacji i sposób realizacji tych wzorców przy użyciu bezserwerowej usługi Azure Stream Analytics lub środowiska uruchomieniowego usługi Azure Functions z opcją posiadania własnego przekształcenia lub kodu wzbogacania bezpośrednio w ścieżce przepływu zdarzeń.
Wzorce federacji
Istnieje wiele potencjalnych powodów, dla których warto przenosić zdarzenia między różnymi usługami Event Hubs lub innymi źródłami i miejscami docelowymi, a także wyliczamy najważniejsze wzorce w tej sekcji, a także link do bardziej szczegółowych wskazówek dotyczących odpowiedniego wzorca.
- Odporność na zdarzenia dostępności regionalnej
- Optymalizacja opóźnienia
- Walidacja, redukcja i wzbogacanie
- Integracja z usługami analitycznymi
- Konsolidacja i normalizacja strumieni zdarzeń
- Dzielenie i routing strumieni zdarzeń
- Projekcje dzienników
Odporność na zdarzenia dostępności regionalnej
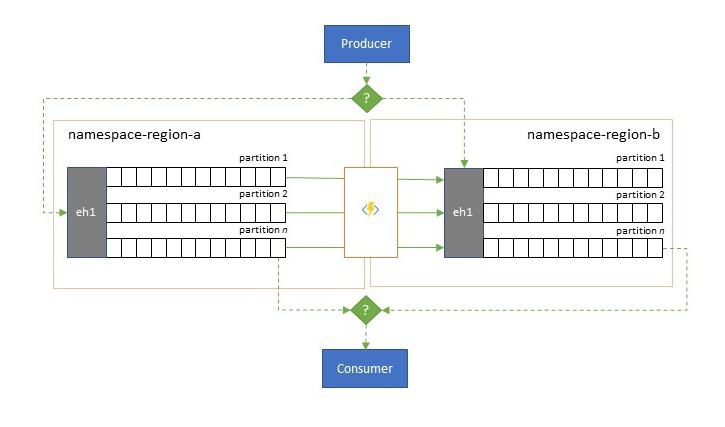
Chociaż maksymalna dostępność i niezawodność są głównymi priorytetami operacyjnymi usługi Event Hubs, istnieje jednak wiele sposobów, w jaki producent lub konsument może uniemożliwić rozmowę z przypisaną "podstawową" usługą Event Hubs z powodu problemów z siecią lub rozpoznawaniem nazw albo gdy usługa Event Hubs może rzeczywiście tymczasowo nie odpowiadać lub zwracać błędy.
Takie warunki nie są "katastrofalne", takie jak całkowite porzucenie wdrożenia regionalnego, ponieważ można to zrobić w sytuacji odzyskiwania po awarii, ale scenariusz biznesowy niektórych aplikacji może już mieć wpływ na zdarzenia dostępności, które trwają nie dłużej niż kilka minut, a nawet sekund.
Istnieją dwa podstawowe wzorce do rozwiązania takich scenariuszy:
- Wzorzec replikacji polega na replikowaniu zawartości podstawowej usługi Event Hubs do pomocniczej usługi Event Hubs, gdzie podstawowe centrum zdarzeń jest zwykle używane przez aplikację do tworzenia i używania zdarzeń, a pomocnicza służy jako opcja rezerwowa w przypadku, gdy podstawowe usługi Event Hubs stają się niedostępne. Ponieważ replikacja jest jednokierunkowa, od podstawowej do pomocniczej, przełączenie zarówno producentów, jak i konsumentów z niedostępnego podstawowego do pomocniczego spowoduje, że stary podstawowy nie będzie już otrzymywać nowych zdarzeń i w związku z tym nie będzie już obecny. W związku z tym replikacja czysta jest odpowiednia tylko dla scenariuszy trybu failover jednokierunkowego. Po zakończeniu pracy w trybie failover stary element podstawowy zostanie porzucony i należy utworzyć nową pomocniczą usługę Event Hubs w innym regionie docelowym.
- Wzorzec scalania rozszerza wzorzec replikacji, wykonując ciągłe scalanie zawartości co najmniej dwóch centrów zdarzeń. Każde zdarzenie pierwotnie utworzone w jednym z centrów zdarzeń zawartych w schemacie jest replikowane do innych usługi Event Hubs. W miarę replikowania zdarzeń są one oznaczone adnotacjami, tak aby były następnie ignorowane przez proces replikacji obiektu docelowego replikacji. Wyniki korzystania ze wzorca scalania to co najmniej dwa centra zdarzeń, które będą zawierać ten sam zestaw zdarzeń w sposób ostatecznie spójny.
W obu przypadkach zawartość usługi Event Hubs nie będzie identyczna. Zdarzenia z dowolnego producenta i pogrupowane według tego samego klucza partycji będą wyświetlane w tej samej kolejności względnej co pierwotnie przesłane, ale bezwzględna kolejność zdarzeń może się różnić. Dotyczy to szczególnie scenariuszy, w których liczba partycji źródłowych i docelowych centrów zdarzeń różni się, co jest pożądane w przypadku kilku wzorców rozszerzonych opisanych tutaj. Rozdzielacz lub router mogą uzyskać wycinkę znacznie większej usługi Event Hubs z setkami partycji i lejkiem do mniejszej usługi Event Hubs z zaledwie kilkoma partycjami, bardziej odpowiednie do obsługi podzestawu z ograniczonymi zasobami przetwarzania. Z drugiej strony konsolidacja może lejkować dane z kilku mniejszych centrów zdarzeń do jednego, większego usługi Event Hubs z większą większa liczba partycji w celu radzenia sobie ze skonsolidowanymi potrzebami w zakresie przepływności i przetwarzania.
Kryterium przechowywania zdarzeń razem jest klucz partycji, a nie oryginalny identyfikator partycji. Dalsze zagadnienia dotyczące kolejności względnej i sposobu przechodzenia w tryb failover z jednego usługi Event Hubs do następnego bez polegania na tym samym zakresie przesunięć strumienia zostały omówione w opisie wzorca replikacji .
Wskazówki:
Optymalizacja opóźnienia
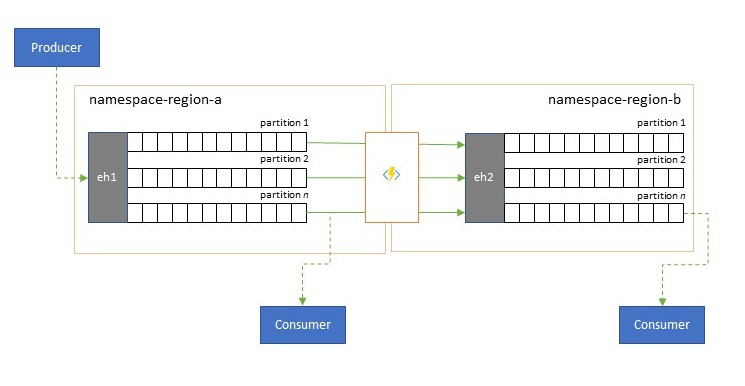
Strumienie zdarzeń są zapisywane raz przez producentów, ale mogą być odczytywane dowolną liczbę razy przez odbiorców zdarzeń. W przypadku scenariuszy, w których strumień zdarzeń w regionie jest współużytkowany przez wielu odbiorców i musi być uzyskiwany wielokrotnie podczas przetwarzania analiz znajdującego się w innym regionie lub w przypadku różnych żądań, które zachwiałyby równoczesnych odbiorców, korzystne może być umieszczenie kopii strumienia zdarzeń w pobliżu procesora analitycznego w celu zmniejszenia opóźnienia dwukierunkowego.
Dobrymi przykładami, gdy replikacja powinna być preferowana w przypadku zdalnego korzystania z zdarzeń z różnych regionów, są szczególnie te, w których regiony są bardzo odległe, na przykład Europa i Australia są prawie antypodami, opóźnienia geograficzne i sieciowe mogą łatwo przekroczyć 250 ms dla każdej podróży okrężnej. Nie można przyspieszyć szybkości światła, ale można zmniejszyć liczbę rund o dużym opóźnieniu, aby wchodzić w interakcje z danymi.
Wskazówki:
Walidacja, redukcja i wzbogacanie
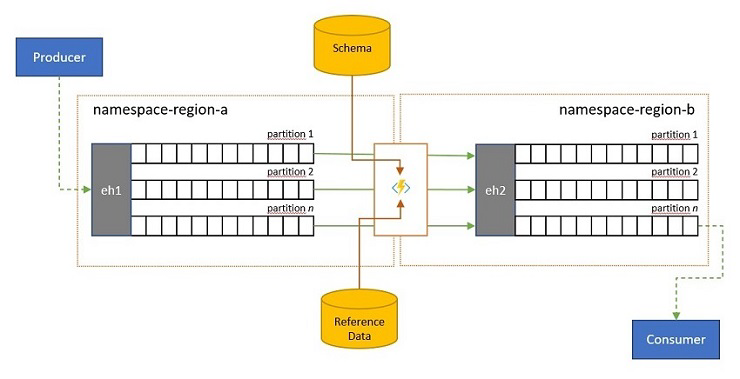
Strumienie zdarzeń mogą być przesyłane do usługi Event Hubs przez klientów spoza własnego rozwiązania. Takie strumienie zdarzeń mogą wymagać, aby zdarzenia przesłane zewnętrznie mogły być sprawdzane pod kątem zgodności z danym schematem i czy zdarzenia niezgodne mają zostać porzucone.
W scenariuszach, w których klienci są ograniczone bardzo przepustowości, ponieważ w wielu scenariuszach "Internetu rzeczy" z mierzoną przepustowością lub gdy zdarzenia są pierwotnie wysyłane za pośrednictwem sieci innych niż IP z ograniczonymi rozmiarami pakietów, zdarzenia mogą być wzbogacone danymi referencyjnymi, aby dodać dodatkowy kontekst do wykorzystania przez podrzędne procesory zdarzeń.
W innych przypadkach, zwłaszcza gdy strumienie są konsolidowane, dane zdarzenia mogą być musiały zostać zmniejszone w złożoności lub pominięcia niektórych szczegółów.
Każda z tych operacji może wystąpić w ramach replikacji, konsolidacji lub scalania przepływów.
Wskazówki:
Integracja z usługami analitycznymi
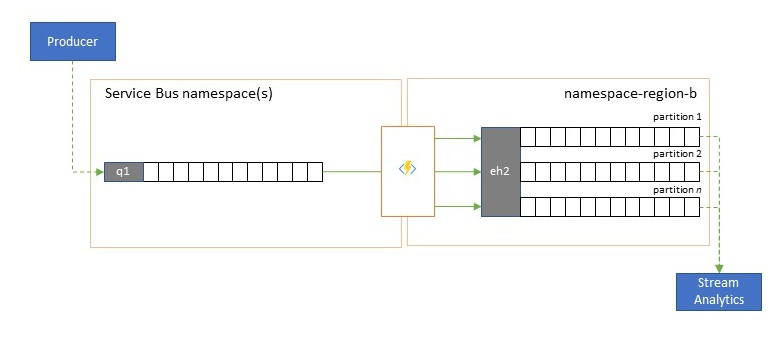
Kilka usług analitycznych natywnych dla chmury platformy Azure, takich jak Azure Stream Analytics lub Azure Synapse, najlepiej współdziała ze strumieniowymi lub wstępnie wsadowymi danymi obsługiwanymi z usługi Azure Event Hubs, a usługa Azure Event Hubs umożliwia również integrację z kilkoma pakietami analitycznymi typu open source, takimi jak Apache Samza, Apache Flink, Apache Spark i Apache Storm.
Jeśli twoje rozwiązanie korzysta głównie z usługi Service Bus lub Event Grid, możesz łatwo udostępnić te zdarzenia takim systemom analitycznym, a także archiwizować za pomocą funkcji przechwytywania usługi Event Hubs, jeśli są one lejkowe do usługi Event Hubs. Usługa Event Grid może to zrobić natywnie z integracją usługi Event Hubs dla usługi Service Bus zgodnie ze wskazówkami dotyczącymi replikacji usługi Service Bus.
Usługa Azure Stream Analytics integruje się bezpośrednio z usługą Event Hubs.
Wskazówki:
Konsolidacja i normalizacja strumieni zdarzeń
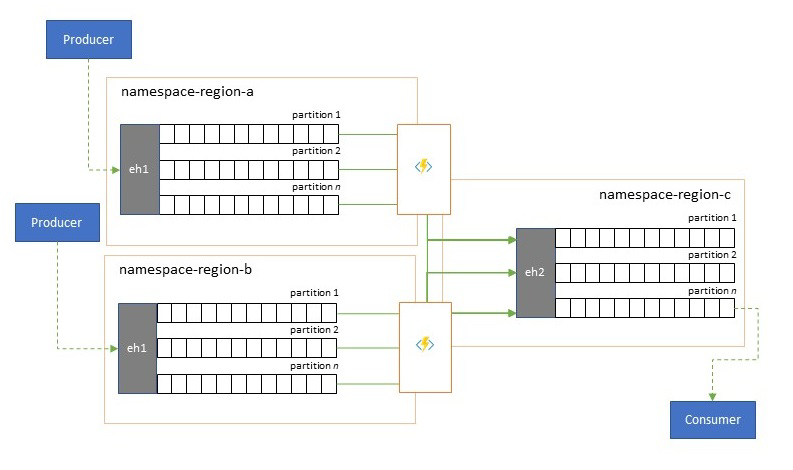
Globalne rozwiązania często składają się z regionalnych śladów, które są w dużej mierze niezależne, w tym z ich własnych możliwości analitycznych, ale perspektywy analizy regionalnej i globalnej będą wymagały zintegrowanej perspektywy i dlatego centralna konsolidacja tych samych strumieni zdarzeń, które są oceniane w odpowiednich regionalnych śladach dla lokalnej perspektywy.
Normalizacja to odmiana scenariusza konsolidacji, w którym co najmniej dwa przychodzące strumienie zdarzeń niosą ten sam rodzaj zdarzeń, ale z różnymi strukturami lub różnymi kodowaniem, a zdarzenia, które najczęściej są transkodowane lub przekształcane przed ich użyciem.
Normalizacja może również obejmować działanie kryptograficzne, takie jak odszyfrowywanie kompleksowych zaszyfrowanych ładunków i ponowne szyfrowanie go przy użyciu różnych kluczy i algorytmów dla odbiorców podrzędnych.
Wskazówki:
Dzielenie i routing strumieni zdarzeń
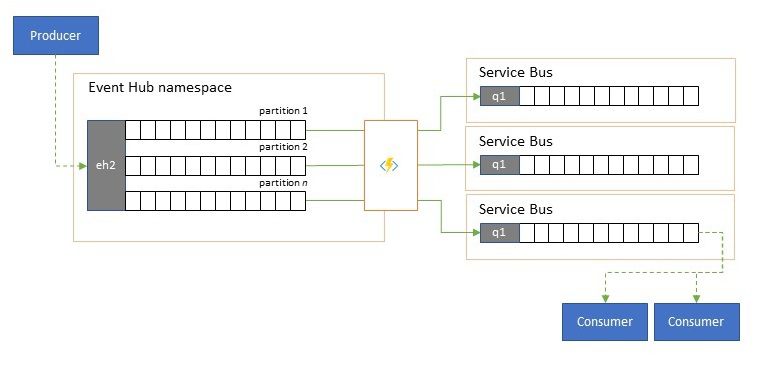
Usługa Azure Event Hubs jest sporadycznie używana w scenariuszach typu "publish-subscribe", w których przychodzący potok pozyskanych zdarzeń znacznie przekracza pojemność usługi Azure Service Bus lub Azure Event Grid, z których oba mają natywne funkcje filtrowania i dystrybucji publikowania i subskrybowania oraz są preferowane dla tego wzorca.
Chociaż prawdziwa funkcja "publish-subscribe" pozostawia subskrybentom możliwość wybierania żądanych zdarzeń, wzorzec dzielenia ma zdarzenia mapowania producenta na partycje według wstępnie określonego modelu dystrybucji i wyznaczonych odbiorców, a następnie ściągnąć wyłącznie z "ich" partycji. Gdy usługa Event Hubs buforuje ogólny ruch, zawartość określonej partycji, reprezentując ułamek oryginalnego woluminu przepływności, może następnie zostać zreplikowana do kolejki w celu zapewnienia niezawodnego, transakcyjnego, konkurencyjnego zużycia odbiorców.
Wiele scenariuszy, w których usługa Event Hubs jest używana głównie do przenoszenia zdarzeń w aplikacji w regionie, ma kilka przypadków, w których wybrane zdarzenia, być może tylko z jednej partycji, również muszą być udostępniane w innym miejscu. Ten scenariusz jest podobny do scenariusza dzielenia, ale może użyć skalowalnego routera, który uwzględnia wszystkie komunikaty przychodzące w usłudze Event Hubs i wybiera tylko kilka dla routingu do wewnątrz i może rozróżniać cele routingu według metadanych zdarzeń lub zawartości.
Wskazówki:
Projekcje dzienników
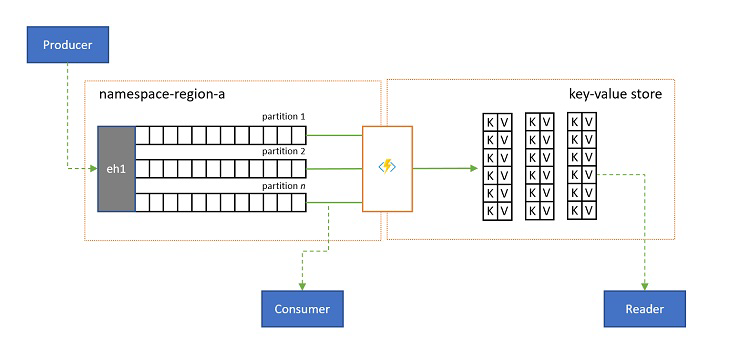
W niektórych scenariuszach chcesz mieć dostęp do najnowszej wartości wysłanej dla dowolnego podstreamu zdarzenia i często rozróżniany przez klucz partycji. W systemie Apache Kafka jest to często osiągane przez włączenie "kompaktowania dzienników" w temacie, który odrzuca wszystkie, ale najnowsze zdarzenie oznaczone dowolnym unikatowym kluczem. Podejście kompaktowania dzienników ma trzy wady złożone:
- Kompaktowanie wymaga ciągłej reorganizacji dziennika, która jest zbyt kosztowną operacją dla brokera zoptymalizowanego pod kątem obciążeń tylko do dołączania.
- Kompaktowanie jest destrukcyjne i nie pozwala na kompaktowanie i niezwarte perspektywy tego samego strumienia.
- Zwarty strumień nadal ma model dostępu sekwencyjnego, co oznacza, że znalezienie żądanej wartości w dzienniku wymaga odczytania całego dziennika w najgorszym przypadku, co zwykle prowadzi do optymalizacji implementujących dokładny wzorzec przedstawiony tutaj: projekcję zawartości dziennika w bazie danych lub pamięci podręcznej.
Ostatecznie zwarty dziennik jest magazynem klucz-wartość i w związku z tym jest to najgorsza możliwa opcja implementacji dla takiego magazynu. Wyszukiwanie i zapytania są znacznie bardziej wydajne w przypadku tworzenia i używania stałego projekcji dziennika do odpowiedniego magazynu klucz-wartość lub innej bazy danych.
Ponieważ zdarzenia są niezmienne, a kolejność jest zawsze zachowywana w dzienniku, każda projekcja dziennika w magazynie klucz-wartość zawsze będzie identyczna dla tego samego zakresu zdarzeń, co oznacza, że projekcja, która jest aktualizowana, zawsze zapewnia autorytatywny widok i nigdy nie ma żadnego dobrego powodu, aby ponownie skompilować je z zawartości dziennika.
Wskazówki:
Technologie aplikacji replikacji
Zaimplementowanie powyższych wzorców wymaga skalowalnego i niezawodnego środowiska wykonywania dla zadań replikacji, które chcesz skonfigurować i uruchomić. Na platformie Azure środowiska uruchomieniowe, które najlepiej nadają się do takich zadań, to zadania bezstanowe to usługa Azure Stream Analytics na potrzeby zadań replikacji strumienia stanowego i usługi Azure Functions w przypadku zadań replikacji bezstanowej.
Aplikacje replikacji stanowej w usłudze Azure Stream Analytics
W przypadku aplikacji replikacji stanowej, które muszą uwzględniać relacje między zdarzeniami, tworzyć zdarzenia złożone, wzbogacać zdarzenia lub zmniejszać zdarzenia, tworzyć agregacje danych i przekształcać ładunki zdarzeń, usługa Azure Stream Analytics jest najlepszą opcją implementacji.
W usłudze Azure Stream Analytics tworzysz zadania integrujące dane wejściowe i wyjściowe oraz integrujące dane z danych wejściowych za pośrednictwem zapytań, które dają wynik, który jest następnie udostępniany w danych wyjściowych.
Zapytania są oparte na języku zapytań SQL i mogą służyć do łatwego filtrowania, sortowania, agregowania i łączenia danych przesyłanych strumieniowo w danym okresie. Możesz również rozszerzyć ten język SQL przy użyciu języka JavaScript i funkcji zdefiniowanych przez użytkownika (UDF) języka C#. Opcje porządkowania zdarzeń i przedziały czasu można łatwo dostosować podczas wykonywania operacji agregacji za pomocą prostych konstrukcji językowych i/lub konfiguracji.
Każde zadanie zawiera jedno lub kilka danych wyjściowych dla przekształconych danych i możesz kontrolować, co dzieje się w odpowiedzi na przeanalizowane informacje. Można na przykład:
- Wysyłaj dane do usług, takich jak Azure Functions, Tematy usługi Service Bus lub kolejki, aby wyzwolić komunikację lub niestandardowe przepływy pracy podrzędne.
- Wysyłanie danych do pulpitu nawigacyjnego usługi Power BI na potrzeby pulpitu nawigacyjnego w czasie rzeczywistym.
- Przechowywanie danych w innych usługach usługi Azure Storage (na przykład Azure Data Lake, Azure Synapse Analytics itp.) w celu wykonywania analiz wsadowych lub trenowania modeli uczenia maszynowego na podstawie bardzo dużych, indeksowanych pul danych historycznych.
- Przechowuj projekcje (nazywane również "zmaterializowanymi widokami") w bazach danych (SQL Database, Azure Cosmos DB).
Aplikacje replikacji bezstanowej w usłudze Azure Functions
W przypadku bezstanowych zadań replikacji, w których chcesz przekazywać zdarzenia bez uwzględniania ich ładunków lub procesów, bez konieczności uwzględniania relacji zdarzeń (z wyjątkiem ich względnej kolejności), możesz użyć usługi Azure Functions, która zapewnia ogromną elastyczność.
Usługa Azure Functions ma wstępnie utworzone, skalowalne wyzwalacze i powiązania wyjściowe dla usług Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid i Azure Queue Storage, a także niestandardowe rozszerzenia dla oprogramowania RabbitMQ i Apache Kafka. Większość wyzwalaczy dynamicznie dostosowuje się do potrzeb przepływności, skalując liczbę współbieżnych wystąpień w górę i w dół na podstawie udokumentowanych metryk.
W przypadku tworzenia projekcji dzienników usługa Azure Functions obsługuje powiązania wyjściowe dla usług Azure Cosmos DB i Azure Table Storage.
Usługa Azure Functions może działać w ramach tożsamości zarządzanej platformy Azure. Dzięki niej można przechowywać wartości konfiguracji poświadczeń w ściśle kontrolowanym magazynie wewnątrz usługi Azure Key Vault.
Ponadto usługa Azure Functions umożliwia bezpośrednie integrowanie zadań replikacji z sieciami wirtualnymi i punktami końcowymi usługi platformy Azure dla wszystkich usług obsługi komunikatów platformy Azure i jest łatwo zintegrowana z usługą Azure Monitor.
Dzięki planowi zużycia usługi Azure Functions wstępnie utworzone wyzwalacze mogą nawet być skalowane w dół do zera, gdy nie są dostępne żadne komunikaty na potrzeby replikacji, co oznacza, że nie ponosisz żadnych kosztów związanych z przechowywaniem konfiguracji gotowej do skalowania kopii zapasowej w górę; Kluczową wadą korzystania z planu zużycia jest to, że opóźnienie zadań replikacji "budzące się" z tego stanu jest znacznie wyższe niż w przypadku planów hostingu, w których infrastruktura jest nadal uruchomiona.
W przeciwieństwie do tego wszystkiego najczęściej używane aparaty replikacji do obsługi komunikatów i zdarzeń, takie jak MirrorMaker platformy Apache Kafka, wymagają samodzielnego udostępnienia środowiska hostingu i skalowania aparatu replikacji. Obejmuje to konfigurowanie i integrowanie funkcji zabezpieczeń i sieci oraz ułatwianie przepływu danych monitorowania, a następnie nadal nie masz możliwości wstrzykiwania niestandardowych zadań replikacji do przepływu.
Wybieranie między usługami Azure Functions i Azure Stream Analytics
Usługa Azure Stream Analytics (ASA) jest najlepszą opcją zawsze, gdy trzeba przetworzyć ładunek zdarzeń podczas ich replikowania. Usługa ASA może kopiować zdarzenia pojedynczo lub tworzyć agregacje, które kondensują informacje o strumieniach zdarzeń przed przekazaniem. Można łatwo polegać na uzupełnieniu danych referencyjnych przechowywanych w usłudze Azure Blob Storage lub Usłudze Azure SQL Database bez konieczności importowania takich danych do strumienia.
Usługa ASA umożliwia łatwe tworzenie trwałych, zmaterializowanych widoków strumieni w bazach danych hiperskalowania. Jest to znacznie lepsze podejście do modelu "kompaktowania dzienników" platformy Apache Kafka i nietrwałych projekcji tabeli po stronie klienta platformy Kafka Strumienie.
Usługa ASA może łatwo przetwarzać zdarzenia, które mają ładunki zakodowane w formatach CSV, JSON i Apache Avro, a także można podłączyć niestandardowe deserializatory dla dowolnego innego formatu.
W przypadku wszystkich zadań replikacji, w których chcesz skopiować strumienie zdarzeń "as-is" i bez dotykania ładunków, lub jeśli musisz zaimplementować router, wykonać pracę kryptograficzną, zmienić kodowanie ładunków lub jeśli w inny sposób potrzebujesz pełnej kontroli nad zawartością strumienia danych, usługa Azure Functions jest najlepszą opcją.
Następne kroki
W tym artykule omówiliśmy szereg wzorców federacji i wyjaśniliśmy rolę usługi Azure Functions jako środowiska uruchomieniowego replikacji zdarzeń i komunikatów na platformie Azure.
Następnie możesz przeczytać, jak skonfigurować aplikację replikatora za pomocą usługi Azure Stream Analytics lub Azure Functions, a następnie jak replikować przepływy zdarzeń między usługą Event Hubs i różnymi innymi systemami obsługi zdarzeń i komunikatów:
- Wzorce zadań replikacji zdarzeń
- Przetwarzanie danych za pomocą usługi Azure Stream Analytics
- Aplikacje replikatora zdarzeń w usłudze Azure Functions
- Replikowanie zdarzeń między usługą Event Hubs
- Replikowanie zdarzeń do usługi Azure Service Bus
- Używanie narzędzia Apache Kafka MirrorMaker z usługą Event Hubs
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla