Korzystanie z widoku programu Hive narzędzia Apache Ambari z usługą Apache Hadoop w usłudze HDInsight
Dowiedz się, jak uruchamiać zapytania Hive przy użyciu widoku programu Apache Ambari Hive. Widok Hive umożliwia tworzenie, optymalizowanie i uruchamianie zapytań hive z przeglądarki internetowej.
Wymagania wstępne
Klaster Hadoop w usłudze HDInsight. Zobacz Wprowadzenie do usługi HDInsight w systemie Linux.
Uruchomienie zapytania programu Hive
W witrynie Azure Portal wybierz klaster. Aby uzyskać instrukcje, zobacz Wyświetlanie listy i pokazywanie klastrów . Klaster jest otwierany w nowym widoku portalu.
W obszarze Pulpity nawigacyjne klastra wybierz pozycję Widoki systemu Ambari. Po wyświetleniu monitu o uwierzytelnienie użyj nazwy konta i hasła konta klastra podanego
adminpodczas tworzenia klastra. Możesz również przejść dohttps://CLUSTERNAME.azurehdinsight.net/#/main/viewswitryny w przeglądarce, w którejCLUSTERNAMEznajduje się nazwa klastra.Z listy widoków wybierz pozycję Widok programu Hive.
Strona widoku hive jest podobna do poniższej ilustracji:
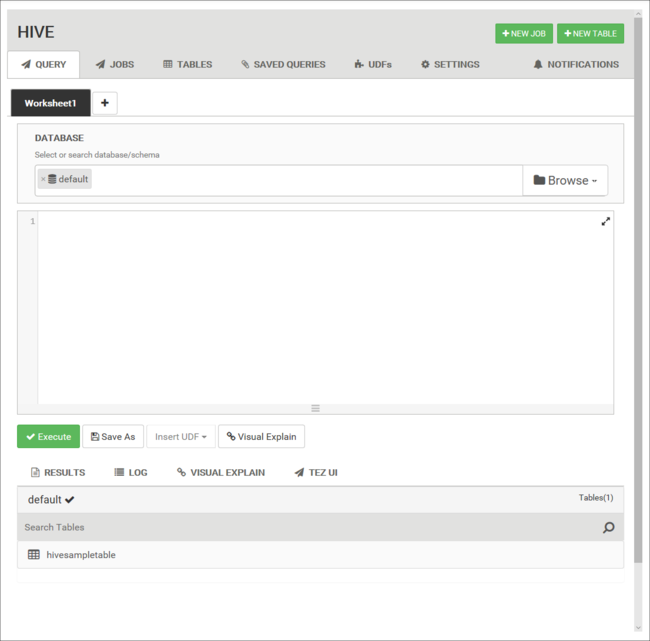
Na karcie Zapytanie wklej następujące instrukcje HiveQL do arkusza:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Te instrukcje wykonują następujące czynności:
Oświadczenie opis DROP TABLE Usuwa tabelę i plik danych, jeśli tabela już istnieje. TWORZENIE TABELI ZEWNĘTRZNEJ Tworzy nową tabelę "zewnętrzną" w programie Hive. Tabele zewnętrzne przechowują tylko definicję tabeli w programie Hive. Dane pozostają w oryginalnej lokalizacji. FORMAT WIERSZA Pokazuje sposób formatowania danych. W takim przypadku pola w każdym dzienniku są oddzielone spacją. PRZECHOWYWANA JAKO LOKALIZACJA PLIKU TEKSTOWEGO Pokazuje, gdzie są przechowywane dane i czy są przechowywane jako tekst. SELECT Wybiera liczbę wszystkich wierszy, w których kolumna t4 zawiera wartość [ERROR]. Ważne
Pozostaw opcję Domyślna opcja Baza danych. Przykłady w tym dokumencie używają domyślnej bazy danych dołączonej do usługi HDInsight.
Aby uruchomić zapytanie, wybierz pozycję Wykonaj poniżej arkusza. Przycisk zmieni kolor pomarańczowy, a tekst zmieni się na Zatrzymaj.
Po zakończeniu zapytania na karcie Wyniki zostaną wyświetlone wyniki operacji. Poniższy tekst jest wynikiem zapytania:
loglevel count [ERROR] 3Możesz użyć karty DZIENNIK, aby wyświetlić informacje rejestrowania utworzone przez zadanie.
Napiwek
Pobierz lub zapisz wyniki z okna dialogowego listy rozwijanej Akcje na karcie Wyniki .
Objaśnia wizualizacja
Aby wyświetlić wizualizację planu zapytania, wybierz kartę Objaśnienia wizualne poniżej arkusza.
Widok Objaśnienia wizualne zapytania może być przydatny w zrozumieniu przepływu złożonych zapytań.
Interfejs użytkownika aplikacji Tez
Aby wyświetlić interfejs użytkownika tez dla zapytania, wybierz kartę Tez UI poniżej arkusza.
Ważne
Tez nie jest używany do rozwiązywania wszystkich zapytań. Wiele zapytań można rozwiązać bez użycia narzędzia Tez.
Wyświetlanie historii zadań
Na karcie Zadania jest wyświetlana historia zapytań Hive.

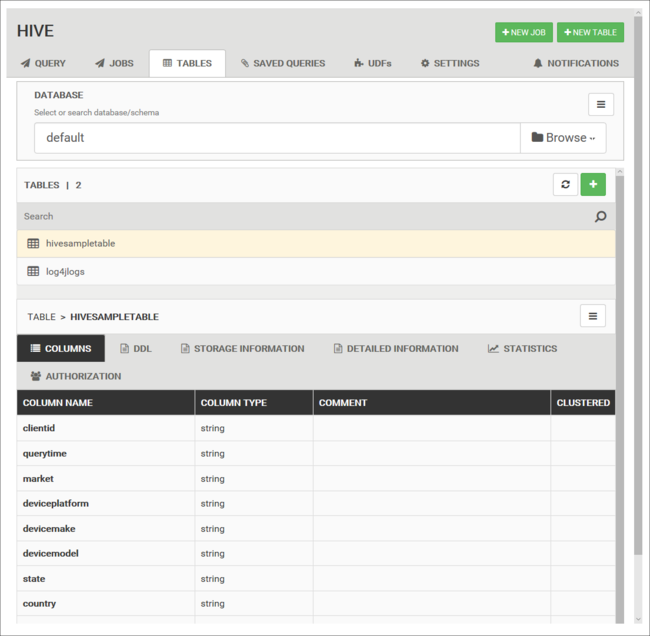
Tabele bazy danych
Za pomocą karty Tabele można pracować z tabelami w bazie danych Programu Hive.
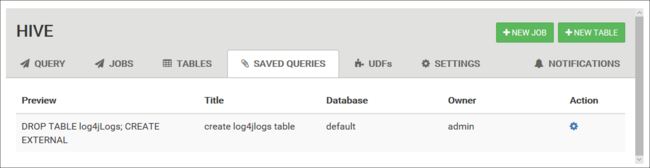
Zapisane zapytania
Na karcie Zapytanie możesz opcjonalnie zapisywać zapytania. Po zapisaniu zapytania można użyć go ponownie na karcie Zapisane zapytania .
Napiwek
Zapisane zapytania są przechowywane w domyślnym magazynie klastra. Zapisane zapytania można znaleźć w ścieżce /user/<username>/hive/scripts. Są one przechowywane jako pliki zwykłego tekstu .hql .
Jeśli usuniesz klaster, ale zachowasz magazyn, możesz użyć narzędzia, takiego jak Eksplorator usługi Azure Storage lub Data Lake Eksplorator usługi Storage (z witryny Azure Portal), aby pobrać zapytania.
Funkcje zdefiniowane przez użytkownika
Usługę Hive można rozszerzyć za pomocą funkcji zdefiniowanych przez użytkownika (UDF). Użyj funkcji zdefiniowanej przez użytkownika, aby zaimplementować funkcje lub logikę, która nie jest łatwo modelowana w języku HiveQL.
Zadeklaruj i zapisz zestaw funkcji zdefiniowanych przez użytkownika przy użyciu karty UDF w górnej części widoku programu Hive. Te funkcje zdefiniowane przez użytkownika mogą być używane z Edytor Power Query.
Przycisk Wstaw udofs jest wyświetlany w dolnej części Edytor Power Query. Ten wpis wyświetla listę rozwijaną zdefiniowanych w widoku hive zdefiniowanych przez użytkownika. Wybranie funkcji zdefiniowanej przez użytkownika powoduje dodanie instrukcji HiveQL do zapytania w celu włączenia funkcji zdefiniowanej przez użytkownika.
Jeśli na przykład zdefiniowano funkcję zdefiniowanej przez użytkownika z następującymi właściwościami:
Nazwa zasobu: myudfs
Ścieżka zasobu: /myudfs.jar
Nazwa funkcji zdefiniowanej przez użytkownika: myawesomeudf
Nazwa klasy UDF: com.myudfs.Awesome
Za pomocą przycisku Wstaw udofs zostanie wyświetlony wpis o nazwie myudfs z inną listą rozwijaną dla każdego zdefiniowanego dla tego zasobu funkcji zdefiniowanej przez użytkownika. W tym przypadku jest to myawesomeudf. Wybranie tego wpisu powoduje dodanie następującego elementu na początku zapytania:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Następnie możesz użyć funkcji zdefiniowanej przez użytkownika w zapytaniu. Na przykład SELECT myawesomeudf(name) FROM people;.
Aby uzyskać więcej informacji na temat używania funkcji zdefiniowanych przez użytkownika z programem Hive w usłudze HDInsight, zobacz następujące artykuły:
- Używanie języka Python z usługami Apache Hive i Apache Pig w usłudze HDInsight
- Używanie funkcji zdefiniowanej przez użytkownika języka Java z usługą Apache Hive w usłudze HDInsight
Ustawienia programu Hive
Możesz zmienić różne ustawienia programu Hive, takie jak zmiana aparatu wykonywania programu Hive z usługi Tez (ustawienie domyślne) na MapReduce.
Następne kroki
Aby uzyskać ogólne informacje na temat programu Hive w usłudze HDInsight: