Wysyłanie danych wyjściowych usługi Azure Stream Analytics do usługi Azure Cosmos DB
Usługa Azure Stream Analytics może przesyłać dane wyjściowe w formacie JSON do usługi Azure Cosmos DB. Umożliwia ona archiwizowanie danych i zapytania o małe opóźnienia w przypadku danych JSON bez struktury. W tym artykule opisano niektóre najlepsze rozwiązania dotyczące implementowania tej konfiguracji (usługa Stream Analytics do usługi Cosmos DB). Jeśli nie znasz usługi Azure Cosmos DB, zapoznaj się z dokumentacją usługi Azure Cosmos DB, aby rozpocząć pracę.
Uwaga
- Obecnie usługa Stream Analytics obsługuje połączenie z usługą Azure Cosmos DB tylko za pośrednictwem interfejsu API SQL. Inne interfejsy API usługi Azure Cosmos DB nie są jeszcze obsługiwane. Jeśli wskażesz usługę Stream Analytics na konta usługi Azure Cosmos DB utworzone za pomocą innych interfejsów API, dane mogą nie być prawidłowo przechowywane.
- Zalecamy ustawienie zadania na poziom zgodności 1.2 podczas korzystania z usługi Azure Cosmos DB jako danych wyjściowych.
Podstawy usługi Azure Cosmos DB jako element docelowy danych wyjściowych
Dane wyjściowe usługi Azure Cosmos DB w usłudze Stream Analytics umożliwiają zapisywanie wyników przetwarzania strumieniowego jako danych wyjściowych JSON do kontenerów usługi Azure Cosmos DB. Usługa Stream Analytics nie tworzy kontenerów w bazie danych. Zamiast tego wymaga wcześniejszego utworzenia ich. Następnie możesz kontrolować koszty rozliczeń kontenerów usługi Azure Cosmos DB. Możesz również dostosować wydajność, spójność i pojemność kontenerów bezpośrednio przy użyciu interfejsów API usługi Azure Cosmos DB. W poniższych sekcjach opisano niektóre opcje kontenera dla usługi Azure Cosmos DB.
Dostrajanie spójności, dostępności i opóźnień
Aby dopasować wymagania aplikacji, usługa Azure Cosmos DB umożliwia dostosowanie bazy danych i kontenerów oraz kompromis między spójnością, dostępnością, opóźnieniami i przepływnością.
W zależności od tego, jakie poziomy spójności odczytu wymaga scenariusz z opóźnieniem odczytu i zapisu, możesz wybrać poziom spójności na koncie bazy danych. Przepływność można zwiększyć, skalując w górę jednostki żądań (RU) w kontenerze. Domyślnie usługa Azure Cosmos DB umożliwia synchroniczne indeksowanie dla każdej operacji CRUD w kontenerze. Ta opcja jest inna przydatna do kontrolowania wydajności zapisu/odczytu w usłudze Azure Cosmos DB. Aby uzyskać więcej informacji, zapoznaj się z artykułem Zmienianie bazy danych i poziomów spójności zapytań.
Upserts from Stream Analytics
Integracja usługi Stream Analytics z usługą Azure Cosmos DB umożliwia wstawianie lub aktualizowanie rekordów w kontenerze na podstawie danej kolumny Identyfikator dokumentu. Ta operacja jest również nazywana operacją upsert. Usługa Stream Analytics używa optymistycznego podejścia upsert. Aktualizacje są wykonywane tylko wtedy, gdy wstawianie kończy się niepowodzeniem z powodu konfliktu identyfikatora dokumentu.
W przypadku poziomu zgodności 1.0 usługa Stream Analytics wykonuje tę aktualizację jako operację PATCH, dzięki czemu umożliwia częściowe aktualizacje dokumentu. Usługa Stream Analytics dodaje nowe właściwości lub zastępuje istniejącą właściwość przyrostowo. Jednak zmiany w wartościach właściwości tablicy w dokumencie JSON powodują zastąpienie całej tablicy. Oznacza to, że tablica nie jest scalona.
W wersji 1.2 zachowanie operacji upsert jest modyfikowane w celu wstawiania lub zastępowania dokumentu. W dalszej sekcji dotyczącej poziomu zgodności 1.2 opisano to zachowanie.
Jeśli przychodzący dokument JSON ma istniejące pole identyfikatora, to pole jest automatycznie używane jako kolumna Identyfikator dokumentu w usłudze Azure Cosmos DB. Wszelkie kolejne zapisy są obsługiwane w taki sposób, co prowadzi do jednej z następujących sytuacji:
- Unikatowe identyfikatory prowadzą do wstawienia.
- Zduplikowane identyfikatory i identyfikatory dokumentu ustawione na identyfikator prowadzą do operacji upsert.
- Zduplikowane identyfikatory i identyfikatory dokumentu nie ustawiają błędu po pierwszym dokumencie.
Jeśli chcesz zapisać wszystkie dokumenty, w tym te, które mają zduplikowany identyfikator, zmień nazwę pola identyfikatora w zapytaniu (przy użyciu słowa kluczowego AS ). Pozwól usłudze Azure Cosmos DB utworzyć pole identyfikatora lub zastąpić identyfikator wartością innej kolumny (przy użyciu słowa kluczowego AS lub przy użyciu ustawienia Identyfikator dokumentu).
Partycjonowanie danych w usłudze Azure Cosmos DB
Usługa Azure Cosmos DB automatycznie skaluje partycje na podstawie obciążenia. Dlatego zalecamy używanie nieograniczonych kontenerów do partycjonowania danych. Gdy usługa Stream Analytics zapisuje w nieograniczonych kontenerach, używa tak wielu równoległych składników zapisywania, jak poprzedni krok zapytania lub schemat partycjonowania danych wejściowych.
Uwaga
Usługa Azure Stream Analytics obsługuje tylko nieograniczone kontenery z kluczami partycji na najwyższym poziomie. Na przykład /region jest obsługiwany. Zagnieżdżone klucze partycji (na przykład /region/name) nie są obsługiwane.
W zależności od wybranego klucza partycji może zostać wyświetlone następujące ostrzeżenie:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Ważne jest, aby wybrać właściwość klucza partycji, która ma wiele odrębnych wartości, i umożliwia równomierne rozłożenie obciążenia między te wartości. Jako naturalny artefakt partycjonowania żądania, które obejmują ten sam klucz partycji, są ograniczone przez maksymalną przepływność pojedynczej partycji.
Rozmiar magazynu dokumentów należących do tej samej wartości klucza partycji jest ograniczony do 20 GB ( limit rozmiaru partycji fizycznej wynosi 50 GB). Idealnym kluczem partycji jest ten, który jest często wyświetlany jako filtr w zapytaniach i ma wystarczającą kardynalność, aby upewnić się, że rozwiązanie jest skalowalne.
Klucze partycji używane na potrzeby zapytań usługi Stream Analytics i usługi Azure Cosmos DB nie muszą być identyczne. Topologie w pełni równoległe zalecają używanie klucza partycji wejściowej , jako klucza partycji zapytania usługi Stream Analytics, PartitionIdale może to nie być zalecany wybór klucza partycji kontenera usługi Azure Cosmos DB.
Klucz partycji jest również granicą transakcji w procedurach składowanych i wyzwalaczach dla usługi Azure Cosmos DB. Należy wybrać klucz partycji, aby dokumenty występujące razem w transakcjach miały tę samą wartość klucza partycji. Artykuł Partycjonowanie w usłudze Azure Cosmos DB zawiera więcej szczegółów na temat wybierania klucza partycji.
W przypadku stałych kontenerów usługi Azure Cosmos DB usługa Stream Analytics nie umożliwia skalowania w górę lub w poziomie po ich pełnym uruchomieniu. Mają górny limit przepływności 10 GB i 10 000 RU/s. Aby przeprowadzić migrację danych z stałego kontenera do nieograniczonego kontenera (na przykład jednego z co najmniej 1000 RU/s i klucza partycji), użyj narzędzia do migracji danych lub biblioteki zestawienia zmian.
Możliwość zapisu w wielu stałych kontenerach jest przestarzała. Nie zalecamy skalowania zadania usługi Stream Analytics w górę.
Ulepszona przepływność z poziomem zgodności 1.2
Z poziomem zgodności 1.2 usługa Stream Analytics obsługuje integrację natywną w celu zbiorczego zapisu w usłudze Azure Cosmos DB. Ta integracja umożliwia efektywne zapisywanie w usłudze Azure Cosmos DB przy jednoczesnym maksymalizacji przepływności i wydajnej obsłudze żądań ograniczania przepustowości.
Ulepszony mechanizm zapisu jest dostępny na nowym poziomie zgodności z powodu różnicy w zachowaniu upsert. W przypadku poziomów wcześniejszych niż 1.2 zachowanie operacji upsert polega na wstawieniu lub scaleniu dokumentu. W wersji 1.2 zachowanie operacji upsert jest modyfikowane w celu wstawiania lub zastępowania dokumentu.
W przypadku poziomów wcześniejszych niż 1.2 usługa Stream Analytics używa niestandardowej procedury składowanej do zbiorczego przetwarzania zbiorczego dokumentów upsert na klucz partycji w usłudze Azure Cosmos DB. W tym miejscu partia jest zapisywana jako transakcja. Nawet jeśli pojedynczy rekord osiągnie błąd przejściowy (ograniczanie przepustowości), cała partia musi zostać ponowiona. To zachowanie sprawia, że scenariusze z nawet rozsądnym ograniczaniem jest stosunkowo powolne.
W poniższym przykładzie przedstawiono dwa identyczne zadania usługi Stream Analytics odczytujące z tych samych danych wejściowych usługi Azure Event Hubs. Oba zadania usługi Stream Analytics są w pełni partycjonowane za pomocą zapytania przekazującego i zapisu w identycznych kontenerach usługi Azure Cosmos DB. Metryki po lewej stronie pochodzą z zadania skonfigurowanego z poziomem zgodności 1.0. Metryki po prawej stronie są konfigurowane przy użyciu wersji 1.2. Klucz partycji kontenera usługi Azure Cosmos DB jest unikatowym identyfikatorem GUID pochodzącym ze zdarzenia wejściowego.
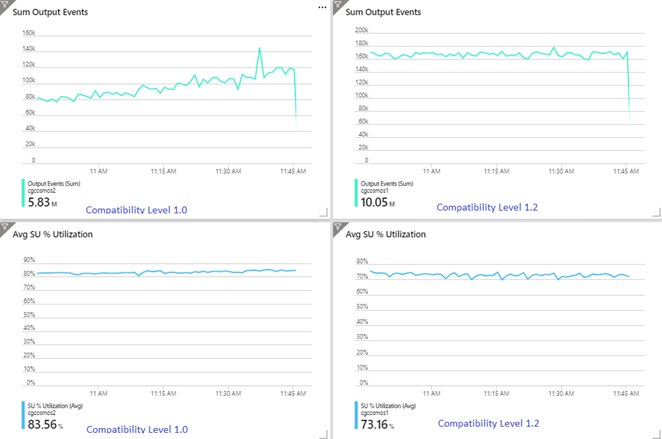
Szybkość zdarzeń przychodzących w usłudze Event Hubs jest dwa razy wyższa niż kontenery usługi Azure Cosmos DB (20 000 jednostek RU) są skonfigurowane do użycia, więc ograniczanie jest oczekiwane w usłudze Azure Cosmos DB. Jednak zadanie o wartości 1.2 stale zapisuje się w wyższej przepływności (zdarzenia wyjściowe na minutę) i przy niższym średnim wykorzystaniu jednostek SU%. W twoim środowisku ta różnica zależy od kilku dodatkowych czynników. Te czynniki obejmują wybór formatu zdarzeń, rozmiaru zdarzenia wejściowego/komunikatu, kluczy partycji i zapytania.
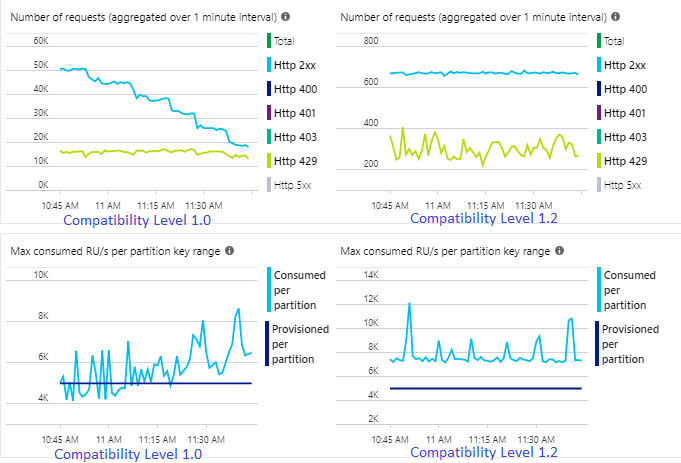
W wersji 1.2 usługa Stream Analytics jest bardziej inteligentna w wykorzystaniu 100 procent dostępnej przepływności w usłudze Azure Cosmos DB z kilkoma ponownymi danymi z ograniczania przepustowości lub ograniczania szybkości. To zachowanie zapewnia lepsze środowisko dla innych obciążeń, takich jak zapytania uruchomione w kontenerze w tym samym czasie. Jeśli chcesz zobaczyć, jak usługa Stream Analytics skaluje się w poziomie z usługą Azure Cosmos DB jako ujściem dla 10 000 do 10 000 komunikatów na sekundę, wypróbuj ten przykładowy projekt platformy Azure.
Przepływność danych wyjściowych usługi Azure Cosmos DB jest identyczna z wersjami 1.0 i 1.1. Zdecydowanie zalecamy używanie poziomu zgodności 1.2 w usłudze Stream Analytics z usługą Azure Cosmos DB.
Ustawienia usługi Azure Cosmos DB dla danych wyjściowych JSON
Użycie usługi Azure Cosmos DB jako danych wyjściowych w usłudze Stream Analytics generuje następujący monit o podanie informacji.
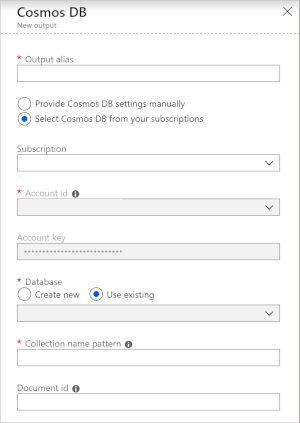
| Pole | opis |
|---|---|
| Alias danych wyjściowych | Alias do odwoływania się do tych danych wyjściowych w zapytaniu usługi Stream Analytics. |
| Subskrypcja | Subskrypcja platformy Azure. |
| Identyfikator konta | Nazwa lub identyfikator URI punktu końcowego konta usługi Azure Cosmos DB. |
| Klucz konta | Klucz dostępu współużytkowanego dla konta usługi Azure Cosmos DB. |
| baza danych | Nazwa bazy danych usługi Azure Cosmos DB. |
| Nazwa kontenera | Nazwa kontenera, taka jak MyContainer. Jeden kontener o nazwie MyContainer musi istnieć. |
| Identyfikator dokumentu | Opcjonalny. Nazwa kolumny w zdarzeniach wyjściowych używana jako unikatowy klucz, na którym muszą być oparte operacje wstawiania lub aktualizacji. Jeśli pozostawisz je puste, wszystkie zdarzenia zostaną wstawione bez opcji aktualizacji. |
Po skonfigurowaniu danych wyjściowych usługi Azure Cosmos DB można go użyć w zapytaniu jako obiektu docelowego instrukcji INTO. Jeśli używasz danych wyjściowych usługi Azure Cosmos DB w ten sposób, należy jawnie ustawić klucz partycji.
Rekord wyjściowy musi zawierać kolumnę z uwzględnieniem wielkości liter o nazwie po kluczu partycji w usłudze Azure Cosmos DB. Aby osiągnąć większą równoległizację, instrukcja może wymagać klauzuli PARTITION BY, która używa tej samej kolumny.
Oto przykładowe zapytanie:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Obsługa błędów oraz wykonywanie ponownych prób
Jeśli wystąpi przejściowy błąd, niedostępność usługi lub ograniczanie przepustowości, gdy usługa Stream Analytics wysyła zdarzenia do usługi Azure Cosmos DB, usługa Stream Analytics ponawia próbę na czas nieokreślony, aby zakończyć operację pomyślnie. Nie próbuje jednak ponawiać prób dla następujących błędów:
- Brak autoryzacji (kod błędu HTTP 401)
- NotFound (kod błędu HTTP 404)
- Zabronione (kod błędu HTTP 403)
- BadRequest (kod błędu HTTP 400)
Typowe problemy
Ograniczenie indeksu unikatowego jest dodawane do kolekcji, a dane wyjściowe z usługi Stream Analytics naruszają to ograniczenie. Upewnij się, że dane wyjściowe z usługi Stream Analytics nie naruszają unikatowych ograniczeń ani nie usuwają ograniczeń. Aby uzyskać więcej informacji, zobacz Unikatowe ograniczenia klucza w usłudze Azure Cosmos DB.
Kolumna
PartitionKeynie istnieje.Kolumna
Idnie istnieje.