Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Tłumaczenia nieanglojęzyczne są dostępne tylko dla wygody. Aby zapoznać się z wiążącą wersją, sprawdź EN-US wersję tego dokumentu.
Ten artykuł zawiera szczegółowe informacje dotyczące sposobu przetwarzania, używania i przechowywania danych dostarczonych przez Ciebie w usłudze Azure AI Speech do przetwarzania mowy na tekst. Jako ważne przypomnienie, użytkownik jest odpowiedzialny za korzystanie z tej technologii i jest zobowiązany do uzyskania wszystkich niezbędnych uprawnień, w tym, jeśli ma to zastosowanie, od talentów głosowych i awatarów (i, jeśli ma to zastosowanie, użytkowników integracji głosu osobistego) do przetwarzania ich głosu, obrazu, podobieństwa i/lub innych danych w celu opracowania syntetycznych głosów i/lub awatarów.
Użytkownik jest również odpowiedzialny za uzyskanie wszelkich licencji, uprawnień lub innych praw niezbędnych do wprowadzania zawartości do usługi zamiany tekstu na mowę w celu wygenerowania danych wyjściowych dźwięku, obrazu i/lub wideo. Niektóre jurysdykcje mogą nakładać specjalne wymagania prawne dotyczące zbierania, przetwarzania i przechowywania niektórych kategorii danych, takich jak dane biometryczne, oraz nakazuje ujawnianie użytkownikom syntetycznych głosów, obrazów i/lub filmów wideo. Przed użyciem tekstu do mowy w celu przetwarzania i przechowywania danych dowolnego rodzaju oraz, jeśli ma to zastosowanie, do tworzenia niestandardowego neuronowego głosu, osobistego głosu lub niestandardowych modeli awatarów, musisz upewnić się, że spełniasz wszystkie wymagania prawne, które mogą mieć zastosowanie do Ciebie.
Jakie dane przetwarzają usługi zamiany tekstu na mowę?
Wstępnie utworzony neuronowy głos i wstępnie utworzony awatar przetwarzają następujące typy danych:
- Wprowadzanie tekstu na potrzeby syntezy mowy. Jest to tekst wybierany i wysyłany do usługi zamiany tekstu na mowę w celu wygenerowania dźwiękowego wyjścia przy użyciu zestawu przygotowanych głosów neuronowych lub wygenerowania gotowego awatara, który wymawia dźwięk generowany na podstawie przygotowanych lub niestandardowych głosów neuronowych.
Nagrany plik z oświadczeniem uznania talentu lektora. Klienci muszą załadować określone nagrane oświadczenie wypowiedziane przez talent głosowy, w którym uznają, że ich głos będzie używany do tworzenia syntetycznych głosów.
Uwaga / Notatka
Podczas przygotowywania skryptu nagrywania upewnij się, że dołączysz wymaganą formułę potwierdzenia, którą ma nagrać talent głosowy. Instrukcję można znaleźć w wielu językach tutaj. Język oświadczenia uznania musi być taki sam jak język danych szkoleniowych nagrania dźwięku.
Dane szkoleniowe (w tym pliki audio i powiązane transkrypcje tekstowe). Obejmuje to nagrania audio z talentów głosowych, które zgodziły się używać swojego głosu do trenowania modelu i powiązanych transkrypcji tekstu. W niestandardowym projekcie neuronowego głosu możesz udostępnić własne transkrypcje tekstu audio lub użyć funkcji automatycznego rozpoznawania mowy dostępnej w usłudze Speech Studio, aby wygenerować transkrypcję tekstu dźwięku. Zarówno nagrania audio, jak i pliki transkrypcji tekstu będą używane jako dane trenowania modelu głosu. W ramach niestandardowego projektu opartego na lekkim algorytmie neuralnego głosu zostaniesz poproszony o nagranie głosu według skryptu określonego przez Microsoft w usłudze Speech Studio. Transkrypcje tekstowe nie są wymagane w przypadku osobistych funkcji głosowych.
Tekst jako skrypt testowy. Możesz przekazać własne skrypty oparte na tekście, aby ocenić i przetestować jakość niestandardowego neuronowego modelu głosu, generując syntezowane próbki dźwięku. Nie dotyczy to osobistych funkcji głosowych.
Wprowadzanie tekstu na potrzeby syntezy mowy. Jest to tekst wybierany i wysyłany do usługi zamiany tekstu na mowę w celu generowania dźwięku przy użyciu niestandardowego głosu neuronowego.
Jak usługa zamiany tekstu na mowę przetwarza dane?
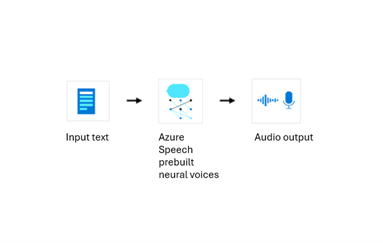
Wstępnie utworzony głos neuronowy
Na poniższym diagramie przedstawiono sposób przetwarzania danych na potrzeby syntezy za pomocą wstępnie utworzonego neuronowego głosu. Dane wejściowe to tekst, a dane wyjściowe to dźwięk. Należy pamiętać, że w dziennikach firmy Microsoft nie będzie przechowywany tekst wejściowy ani wyjściowa zawartość audio.
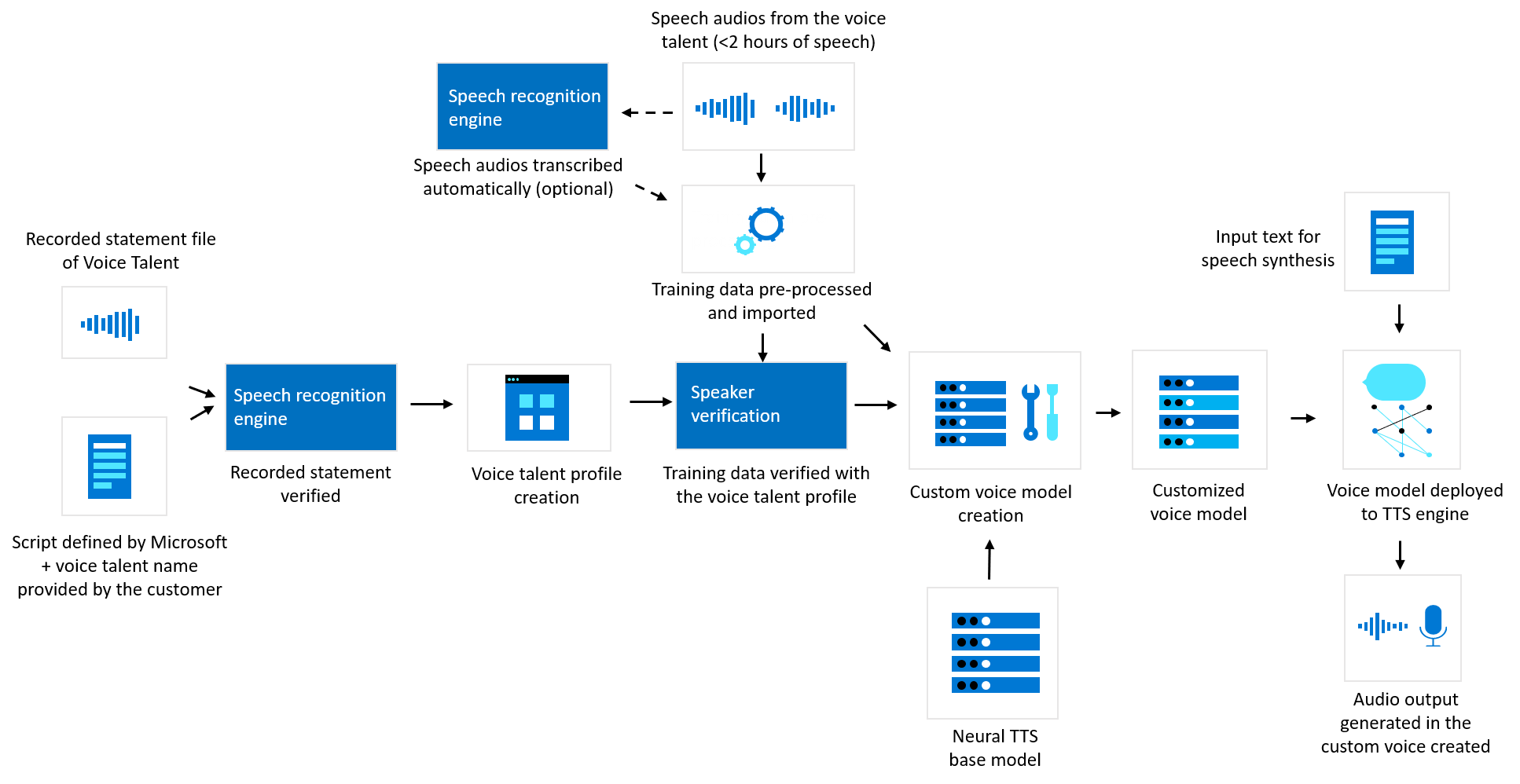
Niestandardowy neuronowy głos
Na poniższym diagramie zilustrowano, w jaki sposób przetwarzane są dane dla niestandardowego głosu neuronowego. Ten diagram obejmuje trzy różne typy przetwarzania: sposób, w jaki firma Microsoft weryfikuje zarejestrowane pliki z oświadczeniami potwierdzenia talentów głosowych przed trenowaniem niestandardowego modelu neuronowego głosu, jak firma Microsoft tworzy niestandardowy model neuronowego głosu z danymi treningowymi oraz jak proces tekst na mowę przetwarza wprowadzony tekst w celu generowania zawartości audio.
Awatar sztucznej mowy
Na poniższym diagramie przedstawiono sposób przetwarzania danych na potrzeby syntezy za pomocą wstępnie utworzonego tekstu do awatara mowy. Istnieją trzy składniki przepływu pracy generowania zawartości awatara: analizator tekstu, syntetyzator audio TTS i syntetyzator wideo awatara TTS. Aby wygenerować wideo awatara, tekst jest najpierw wprowadzany do analizatora tekstu, który przekształca go w sekwencję fonemów. Następnie syntetyzator dźwięku TTS przewiduje funkcje akustyczne tekstu wejściowego i syntetyzuje głos. Te dwie części są dostarczane przez modele głosu przekształcające tekst na mowę. Następnie neuronowy model tekstu na mowę Avatar przewiduje obraz synchronizacji ruchu warg z cechami akustycznymi, dzięki czemu generowane jest syntetyczne wideo.
Diagram przepływu danych przetwarzania tekstu na mowę awatara.
Tłumaczenie wideo (wersja zapoznawcza)
Na poniższym diagramie przedstawiono sposób przetwarzania danych za pomocą tłumaczenia wideo. Klient przesyła wideo jako dane wejściowe do tłumaczenia, z którego wyodrębniany jest dźwięk dialogowy, a funkcja zamiany mowy na tekst transkrybuje dźwięk na tekst. Następnie zawartość tekstowa zostanie przetłumaczona na zawartość języka docelowego i, korzystając z funkcji zamiany tekstu na mowę, przetłumaczony dźwięk zostanie scalony z oryginalną zawartością wideo jako danymi wyjściowymi wideo.

Zarejestrowano weryfikację potwierdzenia
Firma Microsoft wymaga, aby klienci przekazali plik audio do usługi Speech Studio z nagranym oświadczeniem talentu głosowego, uznając, że klient użyje swojego głosu do utworzenia syntetycznego głosu. Firma Microsoft może używać technologii rozpoznawania mowy i przekształcania mowy na tekst firmy Microsoft do przekształcenia tego zarejestrowanego oświadczenia potwierdzenia na tekst oraz aby zweryfikować, czy zawartość nagrania jest zgodna z wstępnie zdefiniowanym skryptem dostarczonym przez firmę Microsoft. To oświadczenie uznania, wraz z informacjami o talentach, które podajesz razem z nagraniem dźwiękowym, służy do tworzenia profilu lektora. Podczas inicjowania niestandardowego trenowania głosu za pomocą sieci neuronowej należy skojarzyć dane szkoleniowe z odpowiednim profilem zdolności głosowych.
Firma Microsoft może również przetwarzać biometryczne podpisy głosowe z zarejestrowanego pliku oświadczenia potwierdzenia głosu oraz z losowych nagrań dźwiękowych z zestawów danych szkoleniowych w celu potwierdzenia, że podpis głosowy w nagraniu oświadczenia potwierdzenia i nagraniach danych szkoleniowych są zgodne z rozsądnym poziomem pewności przy użyciu Azure AI Weryfikacji Osoby Mówiącej. Podpis głosowy może być również nazywany "szablonem głosu" lub "odciskiem głosu" i jest wektorem liczbowym, który reprezentuje cechy głosu osoby wyodrębnione z nagrań dźwiękowych osoby mówiącej. Ta ochrona techniczna ma na celu zapobieganie niewłaściwemu używaniu niestandardowego neuronowego głosu, na przykład uniemożliwieniu klientom trenowania modeli głosowych przy użyciu nagrań audio i używania modeli do fałszowania głosu osoby bez ich wiedzy lub zgody.
Podpisy głosowe są używane przez firmę Microsoft wyłącznie do celów weryfikacji osoby mówiącej lub w inny sposób niezbędne do zbadania nieprawidłowego użycia usług.
Dodatek do ochrony danych produktów i usług firmy Microsoft ("DPA") określa obowiązki klientów i firmy Microsoft w odniesieniu do przetwarzania i bezpieczeństwa danych klienta i danych osobowych w związku z platformą Azure i jest uwzględniany przez odniesienie do umowy enterprise agreement klientów na potrzeby usług platformy Azure. Przetwarzanie danych firmy Microsoft w tej sekcji podlega sekcji Uzasadnione interesy operacji biznesowych Aneksu do ochrony danych.
Trenowanie niestandardowego modelu neuronowego głosu
Dane szkoleniowe (dźwięk mowy) przesyłane do usługi Speech Studio są wstępnie przetwarzane przy użyciu zautomatyzowanych narzędzi do sprawdzania jakości, w tym sprawdzania formatu danych, oceniania wymowy, wykrywania szumów, mapowania skryptów itp. Dane szkoleniowe są następnie importowane do składnika trenowania modelu niestandardowej platformy głosowej. Podczas procesu trenowania dane szkoleniowe (zarówno audio głosowe, jak i transkrypcje tekstu) są rozłożone na szczegółowe mapowania akustyki głosowej i tekstu, takie jak sekwencja fonezy. Dzięki dalszemu złożonemu modelowaniu opartemu na maszynach usługa tworzy model głosu, który następnie może służyć do generowania dźwięku, który brzmi podobnie do talentów głosowych, a nawet może być generowany w różnych językach od rejestrowania danych treningowych. Model głosu to komputerowy model zamiany tekstu na mowę, który może naśladować unikatowe cechy wokalne określonego mówcy. Reprezentuje zestaw parametrów w formacie binarnym, który nie jest czytelny dla człowieka i nie zawiera nagrań audio.
Dane treningowe klienta są używane tylko do opracowywania niestandardowych modeli głosowych klienta i nie są używane przez firmę Microsoft do trenowania ani ulepszania żadnego modelu głosowego w technologii tekst-na-mowę.
Generowanie syntezy mowy/zawartości audio
Po utworzeniu modelu głosu można go użyć do tworzenia treści audio za pomocą usługi zamiany tekstu na mowę, korzystając z dwóch różnych opcji.
W przypadku syntezy mowy w czasie rzeczywistym tekst wejściowy jest wysyłany do usługi zamiany mowy na tekst za pośrednictwem zestawu SDK TTS lub interfejsu API RESTful. Zamiana tekstu na mowę przetwarza tekst wejściowy i zwraca wyjściowe pliki zawartości audio w czasie rzeczywistym do aplikacji, która złożyła żądanie.
W przypadku asynchronicznej syntezy długich nagrań audio (syntezy wsadowej) przesyłasz pliki tekstowe do usługi wsadowej zamiany tekstu na mowę za pośrednictwem interfejsu API Long Audio w celu asynchronicznego tworzenia nagrań dłuższych niż 10 minut (na przykład książek audio lub wykładów). W przeciwieństwie do syntezy wykonywanej przy użyciu interfejsu API zamiany tekstu na mowę, odpowiedzi nie są zwracane w czasie rzeczywistym za pomocą interfejsu API Long Audio. Dźwięk jest tworzony asynchronicznie i można uzyskiwać dostęp do syntetyzowanych plików dźwiękowych i pobierać je po udostępnieniu ich z usługi syntezy wsadowej.
Możesz również użyć niestandardowego modelu głosu, aby wygenerować treści dźwiękowe za pośrednictwem narzędzia do tworzenia treści audio bez konieczności kodowania, a następnie zapisać tekst wejściowy lub wynikowy plik audio w usłudze Azure Storage.
Przetwarzanie danych dla neuronowego głosu na zamówienie: wersja lekka (wersja zapoznawcza)
Niestandardowy głos neuronowy lite to typ projektu w publicznej wersji próbnej, który umożliwia rejestrowanie 20-50 próbek głosowych w usłudze Speech Studio i tworzenie lekkiego niestandardowego modelu neuronowego głosu do celów demonstracji i oceny. Zarówno skrypt nagrywania, jak i skrypt testowania są wstępnie zdefiniowane przez firmę Microsoft. Syntetyczny model głosu, który tworzysz przy użyciu niestandardowego neuronowego głosu lite, może zostać wdrożony i używany w szerszym zakresie tylko wtedy, gdy ubiegasz się i otrzymasz pełny dostęp do niestandardowego neuronowego głosu (z zastrzeżeniem odpowiednich warunków).
Syntetyczny głos i powiązane nagranie audio przesyłane za pośrednictwem usługi Speech Studio zostaną automatycznie usunięte w ciągu 90 dni, chyba że uzyskasz pełny dostęp do niestandardowego neuronowego głosu i wybierzesz wdrożenie syntetycznego głosu, w którym przypadku będziesz kontrolować czas przechowywania. Jeśli talent głosowy chciałby mieć syntetyczny głos i powiązane nagrania audio usunięte przed 90 dni, mogą je usunąć bezpośrednio w portalu lub skontaktować się z przedsiębiorstwem, aby to zrobić.
Ponadto, zanim będzie można wdrożyć dowolny syntetyczny model głosu utworzony przy użyciu niestandardowego projektu neuronowego głosowego Lite, aktor głosowy musi dostarczyć dodatkowe nagranie, w którym potwierdza, że syntetyczny głos będzie używany do dodatkowych celów wykraczających poza demonstrację i ocenę.
Przetwarzanie danych dla osobistego głosowego API (wersja próbna)
Osobisty głos umożliwia klientom tworzenie syntetycznego głosu przy użyciu krótkiej próbki głosu ludzkiego. Plik instrukcji potwierdzenia słownego opisany powyżej jest wymagany od każdego użytkownika, który korzysta z integracji w aplikacji. Firma Microsoft może przetwarzać biometryczne podpisy głosowe z zarejestrowanego pliku oświadczenia głosowego każdego użytkownika i zarejestrowanej próbki szkoleniowej (tj. monitu), aby potwierdzić, że podpis głosowy w nagraniu oświadczenia potwierdzającego i nagraniu danych treningowych jest zgodny z wystarczającą pewnością przy użyciu Azure AI weryfikacji mówcy.
Przykład trenowania zostanie użyty do utworzenia modelu głosu. Model głosowy może następnie służyć do generowania mowy z danymi wejściowymi tekstowymi dostarczonymi do usługi za pośrednictwem interfejsu API bez dodatkowego wdrożenia.
Przechowywanie i przechowywanie danych
Wszystkie usługi zamiany tekstu na mowę
Wprowadzanie tekstu na potrzeby syntezy mowy: Firma Microsoft nie zachowuje ani nie przechowuje tekstu, który dostarczasz za pomocą interfejsu API syntezy w czasie rzeczywistym. Skrypty udostępniane za pośrednictwem interfejsu API Long Audio na potrzeby zamiany tekstu na mowę lub za pośrednictwem interfejsu API wsadowego awatara mowy na tekst są przechowywane w usłudze Azure Storage w celu przetworzenia żądania syntezy wsadowej. Tekst wejściowy można usunąć za pośrednictwem interfejsu API usuwania w dowolnym momencie.
Wyjściowa zawartość audio i wideo: Firma Microsoft nie przechowuje zawartości audio ani wideo wygenerowanej za pomocą interfejsu API syntezy w czasie rzeczywistym. Jeśli używasz tłumaczenia wideo lub Long Audio API do wsadowego zamieniania tekstu na mowę, zawartość wyjściowa audio lub wideo jest przechowywana w usłudze przechowywania Azure. Te audio lub wideo można usunąć w dowolnym momencie za pośrednictwem operacji usuwania .
Zarejestrowane oświadczenie potwierdzenia i dane weryfikacji osoby mówiącej: Podpisy głosowe są używane przez firmę Microsoft wyłącznie do celów weryfikacji osoby mówiącej lub w inny sposób niezbędne do zbadania nieprawidłowego użycia usług. Podpisy głosowe będą przechowywane tylko przez czas niezbędny do przeprowadzenia weryfikacji osoby mówiącej, co może wystąpić od czasu do czasu. Firma Microsoft może wymagać tej weryfikacji przed umożliwieniem trenowania lub ponownego trenowania niestandardowych modeli neuronowych głosowych w usłudze Speech Studio lub w razie potrzeby. Firma Microsoft zachowa zarejestrowany plik oświadczenia potwierdzenia i dane profilów talentów głosowych tak długo, jak to konieczne, aby zachować bezpieczeństwo i integralność usługi Azure AI Speech.
Niestandardowe modele neuronowych głosów: chociaż utrzymujesz wyłączne prawa użytkowania do niestandardowego neuronowego modelu głosu, firma Microsoft może niezależnie przechowywać kopię niestandardowych modeli neuronowych głosów tak długo, jak to konieczne. Firma Microsoft może używać niestandardowego neuronowego modelu głosu wyłącznie w celu ochrony zabezpieczeń i integralności usług sztucznej inteligencji platformy Microsoft Azure.
Firma Microsoft będzie zabezpieczać i przechowywać kopie zarejestrowanych oświadczeń potwierdzających poszczególnych lektorów i niestandardowych modeli neuronowych głosów z tymi samymi zabezpieczeniami wysokiego poziomu, które są używane dla innych usług Azure. Dowiedz się więcej w Centrum zaufania Microsoft.
Dane szkoleniowe: Przesyłasz dane dotyczące trenowania głosowego talentów głosowych w celu generowania modeli głosowych za pośrednictwem usługi Speech Studio, które będą przechowywane i przechowywane domyślnie w usłudze Azure Storage (zobacz Szyfrowanie usługi Azure Storage dla danych w usłudze REST , aby uzyskać szczegółowe informacje). Dostęp do dowolnego z danych szkoleniowych używanych do tworzenia modeli głosowych można uzyskać i usunąć za pośrednictwem usługi Speech Studio.
Magazyn danych szkoleniowych można zarządzać za pomocą rozwiązania BYOS (Bring Your Own Storage). W przypadku tej metody przechowywania dane szkoleniowe mogą być dostępne tylko na potrzeby trenowania modelu głosu i w przeciwnym razie będą przechowywane za pośrednictwem systemu BYOS.
Uwaga / Notatka
Osobisty Głos nie obsługuje funkcji BYOS. Dane będą przechowywane w usłudze Azure Storage zarządzanej przez firmę Microsoft. Możesz uzyskać dostęp do dowolnego z danych treningowych (dźwięku monitu) używanego do tworzenia modeli głosowych za pośrednictwem interfejsu API i usuwać je. Firma Microsoft może niezależnie przechowywać kopię osobistych modeli głosowych tak długo, jak to konieczne. Firma Microsoft może używać osobistego modelu głosu wyłącznie w celu ochrony zabezpieczeń i integralności usług sztucznej inteligencji platformy Microsoft Azure.