Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ostrzeżenie
Usługa Image Analysis 4.0 w zestawie narzędzi Foundry Tools w usłudze Azure Vision jest przestarzała i zostanie zakończona 25 września 2028 r., po czym wywołania wykonane do usługi zakończą się niepowodzeniem. Zalecamy przejście na jedną z dostępnych alternatyw opisanych w przewodniku migracji.
Usługa Azure Vision w narzędziu Foundry Tools Image Analysis umożliwia wyodrębnianie różnych funkcji wizualnych z obrazów. Na przykład może określić, czy obraz zawiera zawartość dla dorosłych, znaleźć określone marki lub obiekty, czy też znaleźć ludzkie twarze.
Najnowsza wersja usługi Image Analysis, 4.0, która jest teraz ogólnie dostępna, ma nowe funkcje, takie jak synchroniczne wykrywanie OCR i osoby.
Analizy obrazów można używać za pomocą zestawu SDK biblioteki klienta lub bezpośrednio wywołując interfejs API REST. Postępuj zgodnie z szybkim przewodnikiem, aby rozpocząć.
Ta dokumentacja zawiera następujące typy artykułów:
- Przewodniki Szybkiego Startu to instrukcje krok po kroku, które umożliwiają wywoływać usługę i otrzymywać wyniki w krótkim czasie.
- Przewodniki z instrukcjami zawierają instrukcje dotyczące korzystania z usługi w bardziej szczegółowy lub dostosowany sposób.
- Artykuły koncepcyjne zawierają szczegółowe wyjaśnienia dotyczące funkcjonalności i możliwości usługi.
Aby uzyskać bardziej ustrukturyzowane podejście, postępuj zgodnie z modułem szkoleniowym dotyczącym analizy obrazów.
Wersje analizy obrazu
Important
Wybierz wersję interfejsu API analizy obrazów, która najlepiej odpowiada Twoim wymaganiom.
| Version | Dostępne funkcje | Recommendation |
|---|---|---|
| wersja 4.0 | Odczytywanie tekstu, podpisy, zagęszczone podpisy, tagi, wykrywanie obiektów, osoby, inteligentne kadrowanie | Lepsze modele; użyj wersji 4.0, jeśli obsługuje twój przypadek użycia. |
| wersja 3.2 | Tagi, obiekty, opisy, marki, twarze, typ obrazu, schemat kolorów, punkty orientacyjne, gwiazdy, zawartość dla dorosłych, inteligentne przycinanie | Szerszy zakres funkcji; użyj wersji 3.2, jeśli twój przypadek użycia nie jest jeszcze obsługiwany w wersji 4.0 |
Zalecamy użycie interfejsu API Analizy obrazu 4.0, jeśli obsługuje twój przypadek użycia. Użyj wersji 3.2, jeśli twój przypadek użycia nie jest jeszcze obsługiwany przez 4.0.
Musisz również użyć wersji 3.2, jeśli chcesz wykonać podpisy obrazów, a zasób usługi Vision znajduje się poza obsługiwanymi regionami świadczenia usługi Azure. Funkcja podpisów obrazów w usłudze Image Analysis 4.0 jest obsługiwana tylko w niektórych regionach świadczenia usługi Azure. Podpisy obrazów w wersji 3.2 są dostępne we wszystkich regionach usługi Azure Vision. Zobacz Dostępność regionów.
analizowanie obrazów
Możesz analizować obrazy, aby uzyskać szczegółowe informacje o ich cechach wizualnych i charakterystykach. Interfejs API analizowania obrazu udostępnia wszystkie funkcje w tej tabeli. Aby rozpocząć pracę, postępuj zgodnie z przewodnikiem Szybki Start.
| Name | Description | Strona koncepcji |
|---|---|---|
| Dostosowywanie modelu (tylko wersja zapoznawcza 4.0) (przestarzałe) | Tworzenie i trenowanie modeli niestandardowych na potrzeby klasyfikacji obrazów lub wykrywania obiektów. Użyj własnych obrazów, oznacz je za pomocą niestandardowych tagów, a analiza obrazu wytrenuje model dostosowany do twojego przypadku użycia. | Dostosowywanie modelu |
| Odczytywanie tekstu z obrazów (tylko wersja 4.0) | Wersja 4.0 w wersji zapoznawczej analizy obrazów umożliwia wyodrębnianie czytelnego tekstu z obrazów. W porównaniu z asynchronicznym interfejsem API Przetwarzania Obrazów 3.2 Odczytu, nowa wersja oferuje znany mechanizm OCR w ujednoliconym interfejsie API synchronicznym o zwiększonej wydajności, który ułatwia uzyskiwanie wyników OCR wraz z innymi danymi w jednym wywołaniu interfejsu API. | OCR dla obrazów |
| Wykrywanie osób na obrazach (tylko wersja 4.0) | Wersja 4.0 analizy obrazów umożliwia wykrywanie osób pojawiających się na obrazach. Interfejs API zwraca współrzędne pola ograniczenia dla każdej wykrytej osoby wraz z oceną ufności. | Wykrywanie osób |
| Generowanie podpisów do obrazów | Wygeneruj podpis obrazu w języku czytelnym dla człowieka, używając pełnych zdań. Algorytmy wizji komputerowej generują podpisy na podstawie obiektów zidentyfikowanych na obrazie. Model transkrywowania obrazów w wersji 4.0 jest bardziej zaawansowaną implementacją i współpracuje z szerszym zakresem obrazów wejściowych. Jest ona dostępna tylko w niektórych regionach geograficznych. Zobacz Dostępność regionów. Wersja 4.0 umożliwia również używanie gęstych podpisów, które generuje szczegółowe podpisy dla poszczególnych obiektów znajdujących się na obrazie. Interfejs API zwraca współrzędne pola ograniczenia (w pikselach) każdego obiektu znalezionego na obrazie oraz podpis. Za pomocą tej funkcji można wygenerować opisy oddzielnych części obrazu. 
|
Generowanie podpisów obrazów (wersja 3.2) (v4.0) |
| Wykrywanie obiektów | Wykrywanie obiektów jest podobne do tagowania, ale interfejs API zwraca współrzędne pola ograniczenia dla każdego zastosowanego tagu. Jeśli na przykład obraz zawiera psa, kota i osobę, operacja Detect wyświetla listę tych obiektów wraz ze współrzędnymi na obrazie. Ta funkcja umożliwia przetwarzanie dalszych relacji między obiektami na obrazie. Ponadto w odpowiednich przypadkach informuje, że obraz zawiera wiele wystąpień tego samego tagu. 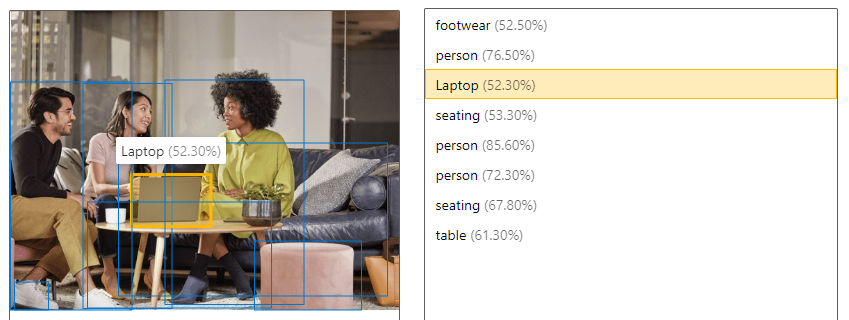
|
Wykrywanie obiektów (wersja 3.2) (v4.0) |
| Tagowanie funkcji wizualnych | Identyfikowanie i tagowanie elementów wizualnych na obrazie w oparciu o zestaw tysięcy rozpoznawalnych obiektów, istot żywych, scenerii i akcji. Gdy tagi są niejednoznaczne lub nie są powszechnie używane, odpowiedź interfejsu API zawiera wskazówki umożliwiające wyjaśnienie kontekstu tagu. Tagowanie nie jest ograniczone do głównego tematu, na przykład do osoby na pierwszym planie, ale uwzględnia także otoczenie (wewnątrz lub na zewnątrz), meble, narzędzia, rośliny, zwierzęta, akcesoria, gadżety itd.
|
Funkcje wizualizacji tagów (wersja 3.2) (v4.0) |
| Pobierz obszar zainteresowania / inteligentne kadrowanie | Przeanalizuj zawartość obrazu, aby zwrócić współrzędne obszaru zainteresowania zgodnego z określonym współczynnikiem proporcji. Wizja Komputerowa zwraca współrzędne ramki ograniczającej regionu, dzięki czemu aplikacja wywołująca może zmodyfikować oryginalny obraz według uznania. Model inteligentnego przycinania w wersji 4.0 jest bardziej zaawansowaną implementacją i współpracuje z szerszym zakresem obrazów wejściowych. Jest ona dostępna tylko w niektórych regionach geograficznych. Zobacz Dostępność regionów. |
Generowanie miniatury (wersja 3.2) (wersja zapoznawcza 4.0) |
| Wykrywanie marek (tylko wersja 3.2) | Identyfikuj marki handlowe na obrazach lub filmach przy użyciu bazy danych zawierającej tysiące logotypów z całego świata. Za pomocą tej funkcji można na przykład ustalać, które marki są najpopularniejsze w mediach społecznościowych lub najpowszechniej promowane za pomocą lokowania produktów w mediach. | Wykrywanie marek |
| Kategoryzowanie obrazu (tylko wersja 3.2) | Identyfikowanie i kategoryzowanie całego obrazu za pomocą taksonomii kategorii z użyciem dziedzicznych hierarchii obiektów nadrzędnych i podrzędnych. Kategorii można używać oddzielnie lub z naszymi nowymi modelami tagowania. Obecnie jedynym obsługiwanym językiem tagowania i kategoryzowania obrazów jest angielski. |
Kategoryzowanie obrazu |
| Wykrywanie twarzy (tylko wersja 3.2) | Wykrywanie twarzy na obrazie i dostarczanie informacji o każdej wykrytej twarzy. Usługa Azure Vision zwraca współrzędne, prostokąt, płeć i wiek dla każdej wykrytej twarzy. Do tych celów można również użyć dedykowanego interfejsu API rozpoznawania twarzy. Zapewnia bardziej szczegółową analizę, taką jak identyfikacja twarzy i wykrywanie pozy. |
Wykrywanie twarzy |
| Wykrywanie typów obrazów (tylko wersja 3.2) | Wykrywaj właściwości obrazu, na przykład czy obraz jest rysunkiem liniowym lub czy jest grafiką clipart. | Wykrywanie typów obrazu |
| Wykrywanie zawartości specyficznej dla domeny (tylko wersja 3.2) | Wykrywanie i identyfikowanie zawartości obrazu specyficznej dla domeny, takiej jak osobistości i charakterystyczne elementy krajobrazu, przy użyciu modeli domeny. Jeśli na przykład obraz zawiera osoby, usługa Azure Vision może użyć modelu domeny dla osobistości, aby określić, czy osoby wykryte na obrazie są znane osobistości. | Wykrywanie zawartości specyficznej dla domeny |
| Wykrywanie schematu kolorów (tylko wersja 3.2) | Analizowanie użycia kolorów na obrazie. Usługa Azure Vision może określić, czy obraz jest czarno-biały czy kolorowy oraz, w przypadku obrazów kolorowych, zidentyfikować kolory dominujące i wyróżniające. | Wykrywanie schematu kolorów |
| Moderowanie zawartości na obrazach (tylko wersja 3.2) | Usługa Azure Vision umożliwia wykrywanie zawartości dla dorosłych na obrazie i zwracanie wyników ufności dla różnych klasyfikacji. Próg flagowania zawartości można ustawić na przesuwanej skali, aby dostosować się do preferencji. | Wykrywanie zawartości dla dorosłych |
Rozpoznawanie produktów (tylko wersja zapoznawcza 4.0) (przestarzałe)
Important
Ta funkcja jest teraz wycofana. 31 marca 2025 r. wycofano interfejs API niestandardowej klasyfikacji obrazów, niestandardowego wykrywania obiektów i rozpoznawania produktów w wersji zapoznawczej usługi Azure AI Image Analysis 4.0. Wywołania interfejsu API do tych usług zakończą się niepowodzeniem.
Przejście do usługi Niestandardowa wizja platformy Azure AI, która jest ogólnie dostępna. Usługa Custom Vision oferuje podobne funkcje do tych wycofywanych funkcji.
Interfejsy API rozpoznawania produktów umożliwiają analizowanie zdjęć półek w sklepie detalicznym. Możesz wykryć obecność lub brak produktów i uzyskać ich współrzędne ramki ograniczającej. Użyj go w połączeniu z dostosowywaniem modelu, aby wytrenować model w celu zidentyfikowania określonych produktów. Możesz również porównać wyniki rozpoznawania produktów z dokumentem planogramu sklepu.
Osadzanie wielomodalne (tylko wersja 4.0)
Interfejsy API wielomodalnych osadzeń umożliwiają wektoryzację obrazów i zapytań tekstowych. Konwertują obrazy na współrzędne w przestrzeni wektorów wielowymiarowych. Następnie można przekonwertować przychodzące zapytania tekstowe na wektory i dopasować obrazy do tekstu na podstawie bliskości semantycznej. Ta funkcja umożliwia wyszukiwanie zestawu obrazów przy użyciu tekstu bez konieczności używania tagów obrazów lub innych metadanych. Bliskość semantyczna często daje lepsze wyniki w wyszukiwaniu.
Interfejs 2024-02-01 API zawiera wielojęzyczny model, który obsługuje wyszukiwanie tekstu w 102 językach. Oryginalny model tylko w języku angielskim jest nadal dostępny, ale nie można go połączyć z nowym modelem w tym samym indeksie wyszukiwania. W przypadku wektoryzowanego tekstu i obrazów przy użyciu modelu tylko w języku angielskim te wektory nie są zgodne z wielojęzycznymi wektorami tekstu i obrazów.
Te interfejsy API są dostępne tylko w niektórych regionach geograficznych. Zobacz Dostępność regionów.
Usuwanie tła (tylko wersja zapoznawcza 4.0)
Important
Ta funkcja jest teraz wycofana. 31 marca 2025 r. wycofano interfejs API analizy obrazów Azure AI 4.0 Segmentation oraz usługa usuwania tła. Wywołania interfejsu API do tych usług zakończą się niepowodzeniem.
Funkcja segmentacji modelu open source Florence 2 może spełniać Twoje potrzeby. Zwraca mapę alfa oznaczającą różnicę między pierwszym planem a tłem, ale nie edytuje oryginalnego obrazu w celu usunięcia tła. Zainstaluj model Florence 2 i wypróbuj funkcję segmentacji Region to.
Aby usunąć w pełni funkcjonalne tło, rozważ użycie narzędzia innej firmy, takiego jak BiRefNet.
Limity usług
Wymagania dotyczące danych wejściowych
Analiza obrazu działa w przypadku obrazów, które spełniają następujące wymagania:
- Obraz musi być w formacie JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF lub MPO
- Rozmiar pliku obrazu musi być mniejszy niż 20 megabajtów (MB)
- Wymiary obrazu muszą być większe niż 50 x 50 pikseli i mniejsze niż 16 000 x 16 000 pikseli
Tip
Wymagania wejściowe dotyczące osadzania wielomodalnego są różne i są wyświetlane w wielomodalnych osadzaniach.
Obsługa języków
Różne funkcje analizy obrazów są dostępne w różnych językach. Zobacz stronę dotyczącą obsługi języka.
Dostępność regionu
Aby korzystać z interfejsów API analizy obrazów, musisz utworzyć zasób Azure Vision w ramach narzędzi Foundry Tools w obsługiwanym regionie. Funkcje analizy obrazów są dostępne w następujących regionach:
| Region | analizowanie obrazów (minus 4.0 Podpisy) |
analizowanie obrazów (w tym 4.0 Napisy) |
Rozpoznawanie produktów | Osadzanie wielomodalne |
|---|---|---|---|---|
| Wschodnie stany USA | ✅ | ✅ | ✅ | ✅ |
| Zachodnie stany USA | ✅ | ✅ | ✅ | |
| Zachodnie stany USA 2 | ✅ | ✅ | ✅ | |
| Francja Środkowa | ✅ | ✅ | ✅ | |
| Europa Północna | ✅ | ✅ | ✅ | |
| Europa Zachodnia | ✅ | ✅ | ✅ | |
| Szwecja Środkowa | ✅ | ✅ | ||
| Szwajcaria Północna | ✅ | ✅ | ||
| Australia Wschodnia | ✅ | ✅ | ||
| Azja Południowo-Wschodnia | ✅ | ✅ | ✅ | |
| Azja Wschodnia | ✅ | ✅ | ||
| Korea Środkowa | ✅ | ✅ | ✅ | |
| Japonia Wschodnia | ✅ | ✅ |
Prywatność i zabezpieczenia danych
Podobnie jak we wszystkich narzędziach Foundry, deweloperzy korzystający z usługi Azure Vision powinni pamiętać o zasadach firmy Microsoft dotyczących danych klientów. Aby dowiedzieć się więcej, zobacz stronę Narzędzi Foundry w Centrum zaufania firmy Microsoft.
Dalsze kroki
Rozpocznij pracę z usługą Image Analysis, postępując zgodnie z przewodnikiem Szybki start w preferowanym języku programowania i wersji interfejsu API: